前言:最近需要将模型移植到瑞芯微rv1106上运行,相比于rv1126 NPU的2.0T算力,它的算力更小,只支持0.5T的算力,而且rv1106目前只支持int8量化,为了保证模型推理在满足精度要求的情况下,保证时间尽可能短,不得不上轻量化模型。
文章目录
- 1、轻量级模型概述
- 2、SqueezeNet
- 3、MobileNet系列
- 4、ShuffleNet系列
- 5、EfficientNet系列
- 6、GhostNet系列
- 7、基于神经网络架构搜索系列
- 8、轻量transformer系列
1、轻量级模型概述
常见的CNN,从2012年发展至今,可从两方面做出归类,一个是速度提升,一个是精度提升;前者注重减小模型参数量,减小模型推理时的flops数量,改进操作的有效性,后者注重整个网络结构改进,或增加网络层深度,或增加网络宽度,或提出更先进的block等,两者均同等重要,思想可相互借鉴。提升模型推理速度,是有效结合实际应用的,因为训练的模型终归是要部署起来的,部署在服务器端,由于算力足够,或许不会对模型有轻量化要求,但若模型需要部署在边缘端,则需要对模型有轻量化要求。
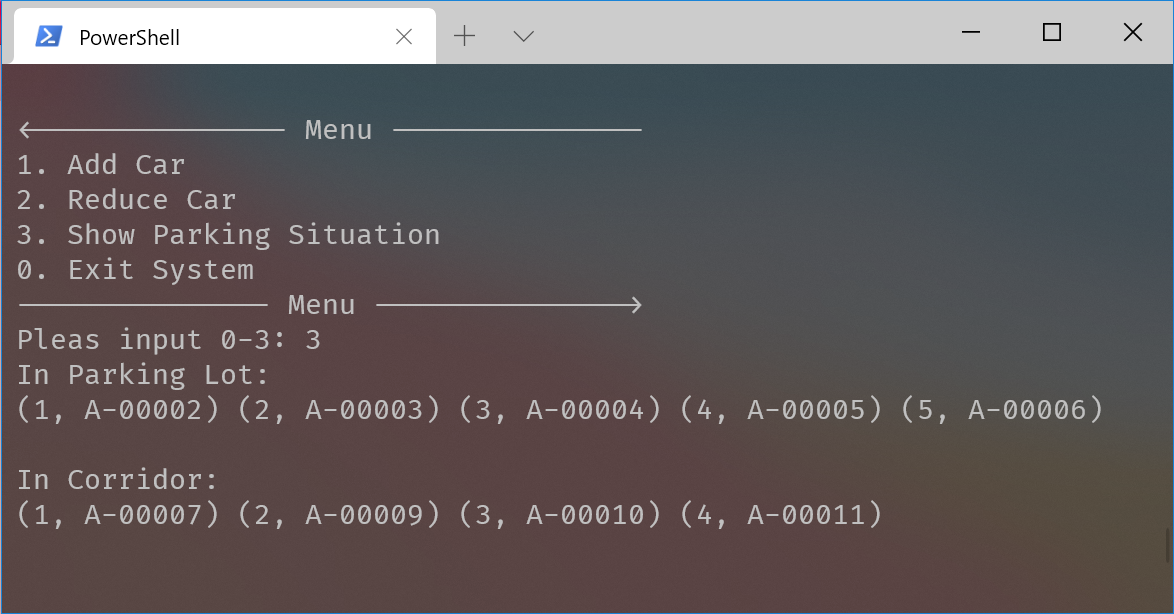
常见对模型进行轻量化操作有:模型裁剪(分为结构化裁剪和非结构化裁剪)、模型蒸馏、模型量化等手段,除了以上列的方法,还可以在模型训练时直接采用轻量化网络结构。自2016年SqueezeNet发布以来,更多研究者在设计网络结构时开始关注资源受限场景中网络结构运算时的效率问题,涌现出大量的轻量级模型,例如:Google的MobileNet系列,EfficientNet Lite系列,旷世的ShuffleNet系列,华为的GhostNet等,最近还涌现出一些轻量transformer的模型。下面放上一张经多篇论文汇总的参数量、计算量及ImageNet数据集top1准确率对比表,方便对比模型性能。

下面按照年份、模型系列对算法进行简要解析。
2、SqueezeNet
2016年提出,算是首次在保证模型精度的情况下关注如何减小模型参数量的设计,为了达到这个目的,作者实施了如下三个策略:
1、将3x3卷积核替换成了1x1卷积核
2、将3x3卷积核的输入通道减小
3、在网络的后期进行下采样,使卷积层有较大尺寸的激活图(保证精度)
具体详细解读见 轻量级模型解读——SqueezeNet
3、MobileNet系列
MobileNet由谷歌针对模型在移动/嵌入式设备上能实现部署而提出,系列到现在2024年,已经出到了第四个版本,分别如下:
2017年MobileNetv1——>2018年MobileNetv2——>2019年MobileNetv3——>2024年MobileNetv4,其主要贡献是提出了深度可分离卷积和倒置残差瓶颈,详细解读见博客轻量级模型解读——MobileNet系列
4、ShuffleNet系列
shuffleNet由旷视科技提出,在应用分组卷积时,考虑通道之间没有信息“交流”会阻碍模型的特征表达,于是考虑在分组卷积之前将通道打乱(shuffle),实验证明,这一改进有助提升模型性能,shuffleNetv2在改进模型结构的同时考虑模型的实际推理延时而不是通过flops去衡量,有一定的实际工程应用,详细解读见博客轻量级模型解读——ShuffleNet系列
5、EfficientNet系列
EfficientNet自2019年谷歌提出以来,经历了三个版本,2019EfficientNet ——> 2020EfficientNet-Lite——> 2021EfficientNetv2,严格来说,我们现在讨论的轻量级模型,只有EfficientNet-b0/b1/b2/b3,EfficientNetv2-b0/b1/b3/S以及专门针对移动端改进的EfficientNet-Lite属于轻量级模型这个标准。详细解读见博客轻量级模型解读——EfficientNet系列
6、GhostNet系列
GhostNet由华为诺亚方舟实验室于2019年11月底提出,投稿于cvpr2020,后面2022年,2024年相继提出更新版本GhostNetv2和GhostNetv3。GhostNetv1改进点不大,但出发点比较新颖,大多数研究者设计轻量模型,都是想去掉模型的冗余特征,但作者提出冗余特征对模型性能保证是必要的,作者的出发点是尽量用简单的线性操作精简生成这些冗余特征,最终的效果等效于将模型加深。v2版本是加入DFC注意力机制提升模型性能,v3是一些工程实际方面的改进,比如重参数化、蒸馏、学习策略、数据增强等。
具体详细解读见博客轻量化模型解读——GhostNet系列
7、基于神经网络架构搜索系列
基于神经网络架构搜索比较经典的轻量型模型主要有谷歌大脑在2017年提出的NASNet、2018年的MnasNet和2019提出的MixConv,当然还有其他系列的轻量型模型也是通过架构搜索得到,比如:MobileNetv3和MobileNetv4,EfficientNet-B0,GhostNetv3等,这里不再赘述。
这些基于神经网络架构搜索的方法,它们都基于谷歌大脑在2016年发布的神经网络架构搜索(Neural Architecture Search,NAS)论文发展而来,基于NAS的方法重点关注搜索空间(search space)和controller的更新策略。具体详细解读见博客轻量化模型解读——基于神经网络架构搜索(NAS)系列
8、轻量transformer系列
Transformer是2017谷歌提出的一篇论文,最早应用于NLP领域的机器翻译工作,但随着2020年DETR和ViT的出现,其在视觉领域的应用也如雨后春笋般渐渐出现,其特有的全局注意力机制给图像识别领域带来了重要参考。但是transformer参数量大,训练/推理耗时也是它的一大特点,NLP领域中,一个模型的参数量基本都是十亿量级。如何将transformer应用在图像领域并且轻量化是本篇博客的重点。我收集了近期4篇论文,DeiT(2020),ConViT(2021),Mobile-Former(2021)和MobileViT(2021)。详细解读见博客轻量化模型解读——轻量transformer系列