小罗碎碎念
这篇文章于2024-09-09发表于Nature Machine Intelligence,目前IF=18.8。
这篇文章介绍了一种名为VirtualMultiplexer的AI工具,能够通过生成式对抗网络从苏木精-伊红染色图像合成多种抗体标记的虚拟多重免疫组化图像,以加速病理组织学工作流程并提高临床预测的准确性。
作为真正处于科研一线的同志,我十分清楚大家关心的问题——能否将该篇论文的成果应用到自己的课题中 OR 我能否完成类似的工作。
要解决这个问题,作者就需要先看看作者的配置——NVIDIA Tesla A100➕NVIDIA Tesla P100。当然了,如果作者的硬件条件不符合,那么借鉴一下思路,或者直接引用作者的模型也是可以的。

| 作者 | 单位 | 单位中文翻译 | 简介 |
|---|---|---|---|
| Pushpak Pati | ETH Zurich, Zürich, Switzerland | 苏黎世联邦理工学院,苏黎世,瑞士 | 第一作者,专注于生成式人工智能在病理学中的应用研究。 |
| Marianna Kruithof-de Julio | Translational Organoid Resource, Department for Biomedical Research, University of Bern, Bern, Switzerland | 伯尔尼大学转化器官资源部,生物医学研究部,伯尔尼,瑞士 | 通讯作者,专注于病理学和生物信息学交叉领域的研究。 |
一作
作者从作者的谷歌学术可以发现,24年发表的论文大部分都与病理相关。
感兴趣的同学也可以查看作者的GitHub主页,里面有他的简历。

文献速览
这篇文章介绍了一种名为VirtualMultiplexer的生成式人工智能工具包,它能够从单一的苏木精和伊红(H&E)图像中合成多种免疫组化(IHC)标记的虚拟多重染色图像。
该工具包能够快速、稳健且精确地生成高染色质量的虚拟多重成像数据集,这些数据集与实际数据无法区分。通过使用这些虚拟多重图像,研究人员能够训练图变换器,从而同时学习多个蛋白质的联合空间分布,以预测临床相关终点。
-
背景与动机:
- 肿瘤异质性的理解:理解肿瘤的空间异质性及其与疾病起始和发展的关系是癌症生物学的基础。
- 传统组织病理学工作流程的局限性:目前的组织病理学工作流程依赖于繁琐的连续组织切片和免疫组化染色,导致非对齐的组织图像和组织耗竭。
- 虚拟多重染色的需求:现有的多重成像技术虽然能够同时定量多个标记物,但成本高、实验过程繁琐、组织破坏性强且需要专用设备,限制了其在临床上的应用。
-
VirtualMultiplexer工具包:
- 工具包的概述:VirtualMultiplexer是一种生成式AI工具包,能够将H&E图像转换为匹配的IHC图像,适用于多种标记物。
- 技术原理:该工具包基于对比性非配对翻译(CUT)方法,通过最大化源域和目标域之间的互信息来实现内容保留。
- 训练与评估:在前列腺癌组织微阵列(TMA)上训练,评估生成的图像质量,并通过专家病理评估和视觉图灵测试验证其临床相关性。
-
性能评估:
- 定量评估:使用FréchetInception距离(FID)评分评估生成的IHC图像与真实图像的分布差异,结果显示VirtualMultiplexer在所有标记物上均表现优异。
- 定性评估:通过专家病理评估和视觉图灵测试,验证了生成的虚拟IHC图像的可区分性和临床相关性。
- 迁移学习:成功将模型应用于不同的组织图像尺度和患者队列,证明了其跨组织类型的潜力。
-
临床应用:
- 图变换器的训练与应用:利用虚拟多重图像训练图变换器(GT),以预测临床相关终点,如Gleason分级和疾病进展。
- 独立患者队列和癌症类型的数据增强:在两个独立的前列腺癌患者队列和一个胰腺导管腺癌(PDAC)队列中验证模型的泛化能力。
- 不同癌症类型的数据增强:将VirtualMultiplexer应用于乳腺癌和结直肠癌的数据集,进一步展示了其在不同组织类型中的潜力。
-
结果与讨论:
- 虚拟多重染色图像的质量:生成的虚拟IHC图像在细胞水平上捕捉到现实的外观和染色模式,且在染色特异性方面表现出高一致性。
- 图变换器在临床预测中的应用:虚拟多重图像显著提高了临床预测的准确性,特别是在Gleason分级和疾病进展的预测中。
- 未来工作方向:尽管取得了显著成果,但仍需解决背景噪声、瓦片拼接伪影和染色特异性不一致等问题,并在真实世界环境中进行验证。
总的来说,VirtualMultiplexer展示了人工智能辅助多重肿瘤成像的临床相关性,加速了组织病理学工作流程和癌症生物学研究。
一、绪论
组织是空间上有序的生态系统,其中不同表型、形态和分子特征的细胞与非细胞化合物共存并相互作用,以维持内环境稳定[1]。
多种组织染色技术被用于探究这一复杂组织结构,其中,苏木精-伊红(H&E)染色是无可争议的主力,常用于在组织形态学工作中评估与疾病相关的异常[2]。
癌症是一个显著的例子,H&E染色可揭示异常细胞增殖、淋巴血管侵犯和免疫细胞浸润等情况。与H&E提供的形态学信息相辅相成,免疫组化(IHC)技术可以检测和量化特定标记在细胞组分内的分布和定位,这对于肿瘤亚型分类、预后判断和个性化治疗选择至关重要[3]。
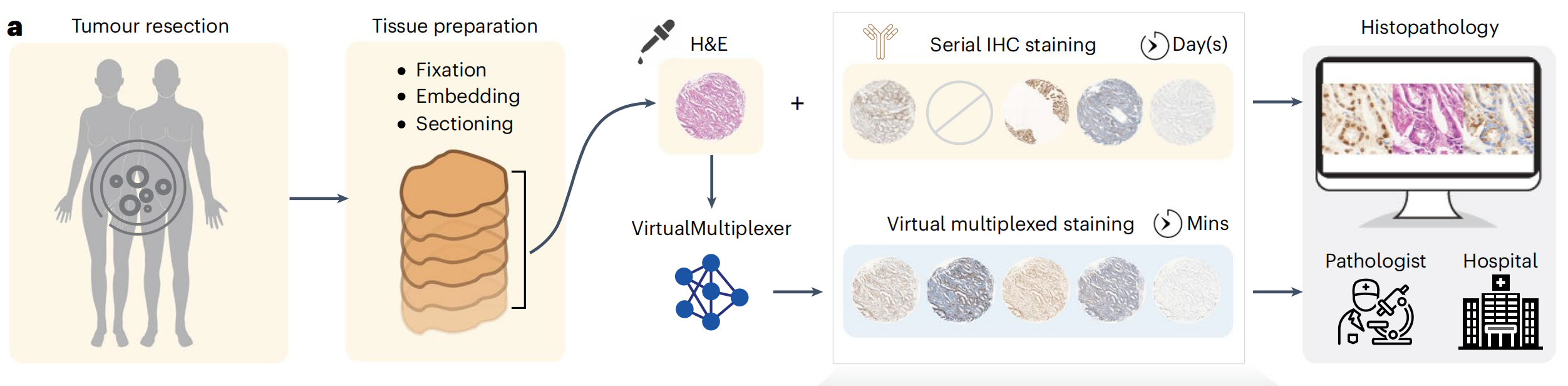
然而,传统IHC的重新染色受限,需要对不同抗体进行重复连续切片染色,以深入进行肿瘤分析,这一过程耗时且耗尽组织,对于组织量有限的情况是禁止的。此外,连续IHC染色产生的图像不匹配、非多重化,且由于人工制品,偶尔质量不佳,组织不可用可能导致缺失染色(图1a)。
近期,多重成像技术[4–6]实现了在同一组织上同时量化数十个标记,从而革新了空间生物学[7]。
然而,其高昂的成本、繁琐的实验过程、破坏组织的本质以及需要专用设备,严重限制了临床应用。
虚拟染色,即使用生成式人工智能(AI)对组织图像进行人工染色,作为一种有前景的、成本效益高、易获取且快速的选择,解决了上述限制[8,9]。
虚拟染色模型在源图像和目标图像集上训练,并学习源到目标的外观映射[10,11],以模拟在源图像上的目标染色,最终在推理时生成虚拟目标图像。
最初的虚拟染色模型基于不同版本的生成对抗网络(GANs),在配对设置下运行:即,它们依赖于精确对齐的源图像和目标图像,从而直接优化虚拟图像和真实图像之间的像素级损失[12]。成功的配对模型示例包括将无标签显微镜转换为H&E和特定染色[13–16],H&E转换为特殊染色[17,18],H&E转换为IHC[19,20]和IHC转换为多重免疫荧光[21]。
然而,由于组织重新染色并非常规操作,配对模型依赖于通过图像配准对组织切片进行对齐,这一过程耗时且容易出错,在实践中往往不可行,因为即使是连续切片之间也存在重大差异。此外,由于组织结构在第一张切片后大幅改变,事后添加新标记是不可能的。
为克服这些限制,近期出现了无配对染色到染色(S2S)翻译模型,早期应用包括从H&E到IHC[22–26]和特殊染色[27,28]的转换,以及从冷冻切片到福尔马林固定石蜡包埋(FFPE)切片[29]的转换。
绝大多数无配对模型受到CycleGAN[30]的启发,它们依赖于对抗性损失以保留源内容,并依赖于循环一致性损失以保留目标风格。一些模型采用额外的约束,例如,域不变内容和域变异风格[22],感知嵌入[24]或结构相似性[25]。
CycleGAN-based模型的一个重要限制是循环一致性假设源和目标域之间存在双射映射[30],这在许多S2S翻译任务中并不成立。因此,一个持续的问题是染色不可靠性,表现为域之间的错误映射:例如,源域的正信号映射到目标域的负信号。
为考虑染色的不可靠性,近期的工作通过专家注释引导翻译。
参考文献26通过H&E图像上的阳性转移和阴性区域专家注释将H&E转换为细胞角蛋白染色的IHC,参考文献25利用H&E和IHC图像上的癌症和正常区域注释将H&E转换为Ki67染色的IHC。
尽管这些方法在特定翻译任务上显示出有希望的结果,但在翻译到多个IHC标记时获取此类注释是不切实际的,即使对于经验丰富的病理学家来说,进行专业任务(例如,在H&E图像中识别p53+细胞)也是不可能的。
为克服注释挑战,参考文献31最近引入了半监督方法,但该方法仍然依赖于图像配准。因此,迫切需要无需连续组织切片、图像配准或源域大量注释即可保持染色一致性的无配对S2S翻译模型。
无论底层建模假设如何,S2S翻译方法的另一个重要限制在于评估。
由于真实图像和虚拟生成的图像不是像素级对齐的,S2S翻译质量通常使用基于inception的评分在高特征级别进行量化[32]。然而,这些评分并不能保证复杂且有生物学意义的模式的准确保留[9]。
为缓解这些担忧,一些研究通过病理学家对虚拟图像的定性评估来进行[22,24]。然而,一个持续关注的问题是虚拟图像中可能出现的幻觉,这些幻觉即使对经验丰富的病理学家来说也可能看似真实。
最终,为确保虚拟图像不仅在视觉上看起来逼真,而且从临床角度来看也有用,将它们作为预测临床终点的下游模型的输入可能提供无偏见的、令人信服的验证[9]。
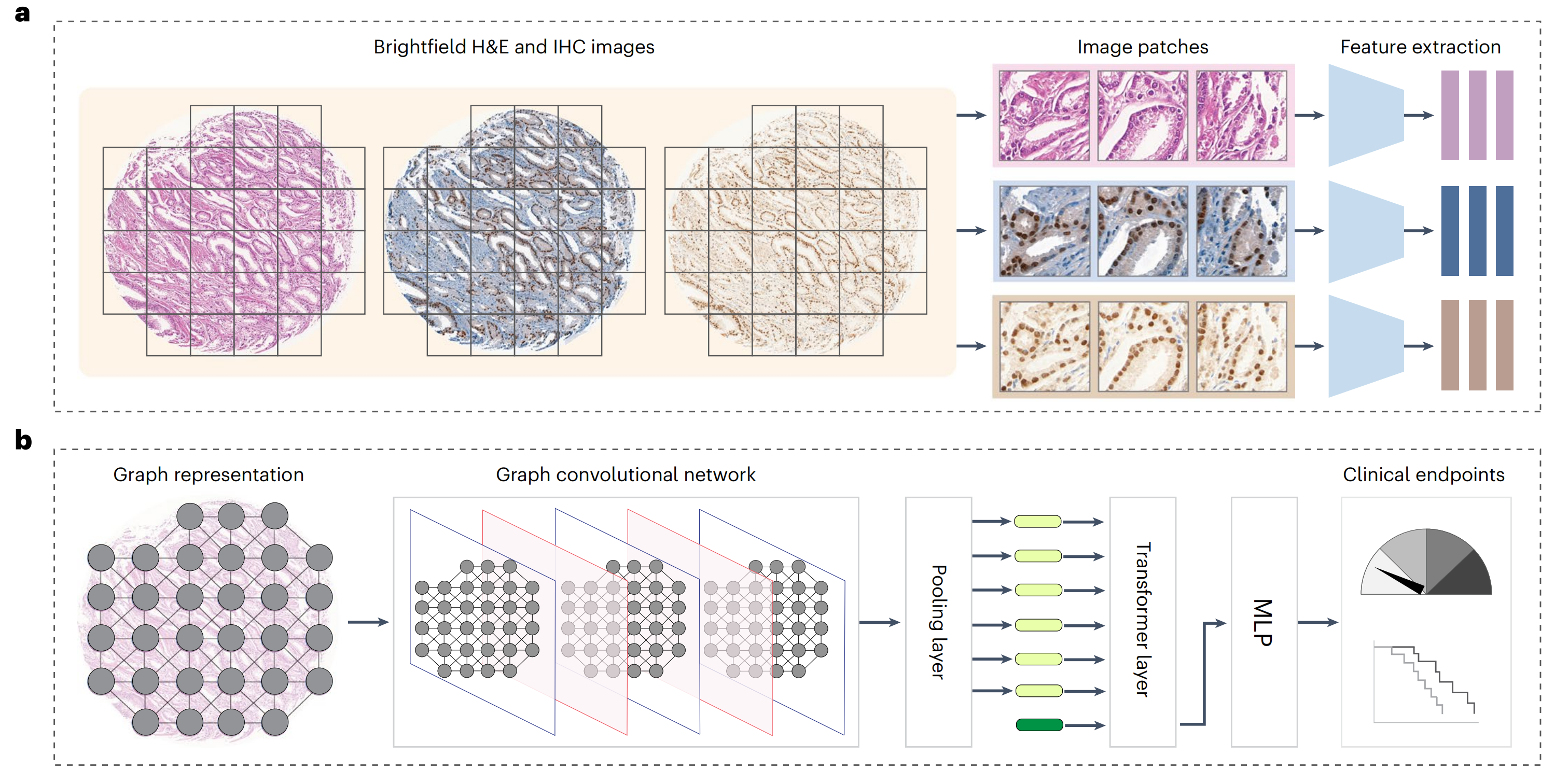
在此,作者提出了VirtualMultiplexer,这是一个生成式工具包,能够将H&E图像转换为匹配的IHC图像,适用于多种标记(一次一个IHC标记)(图1a,b)。
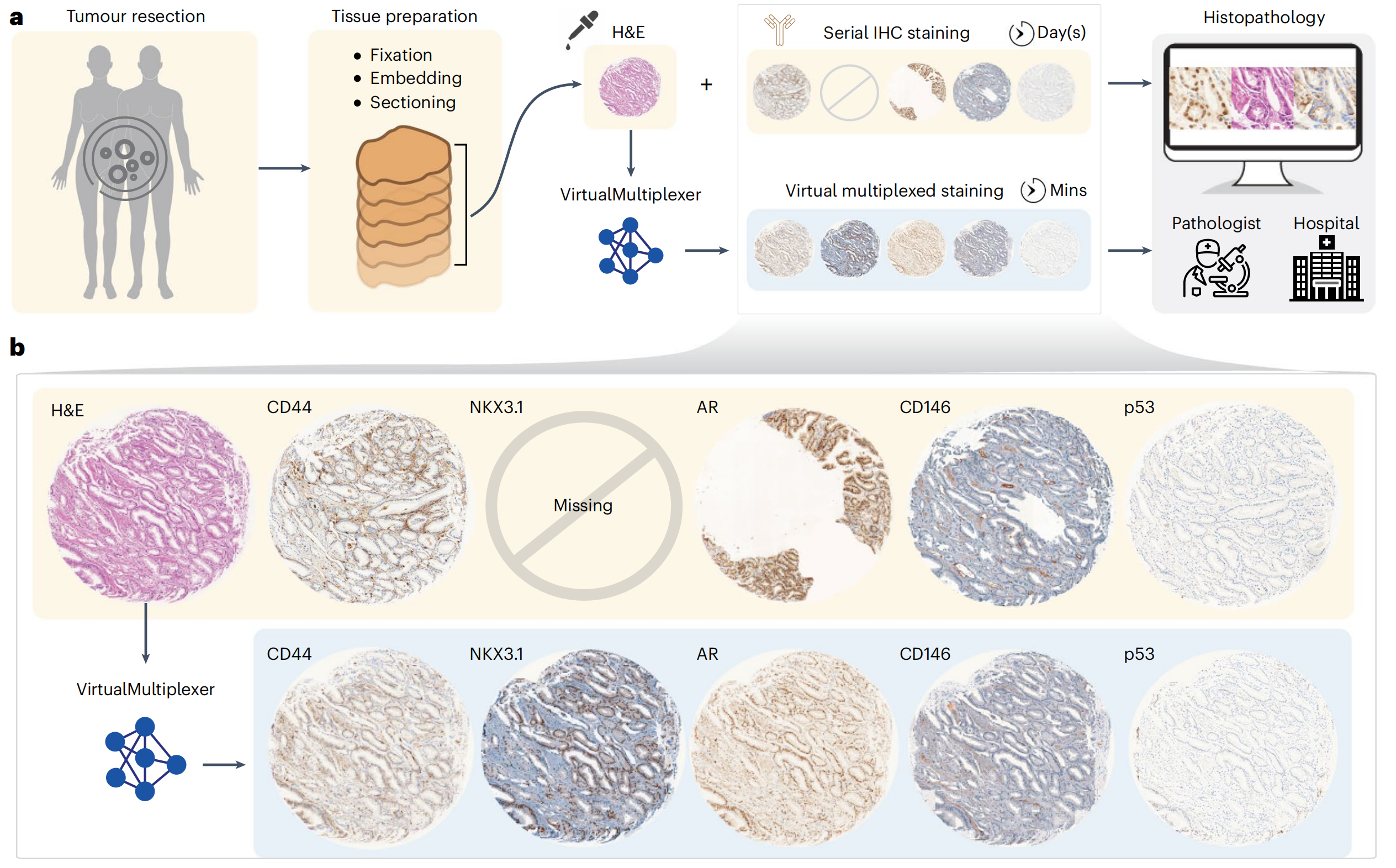
VirtualMultiplexer受到对比式无配对翻译(CUT)[34]的启发,CUT是CycleGAN的一种吸引人的替代方法,通过最大化目标域与源域之间的互信息来实现内容保留。
该模型不需要像素级对齐的H&E和IHC图像,与现有方法相比,仅在IHC域上需要极少的专家注释。
为确保生物学一致性,VirtualMultiplexer引入了一个在单细胞、细胞邻域和整个图像级别具有多尺度约束的架构,该架构紧密模仿人类专家评估。
作者使用包含六个临床相关核、细胞质和膜靶向标记的未配对H&E和IHC图像的前列腺癌组织微阵列(TMA)对VirtualMultiplexer进行了训练。
作者使用定量忠诚度指标、专家病理评估和视觉图灵测试对生成的图像进行了评估,并通过预测临床终点来评估其临床相关性(图1c)。
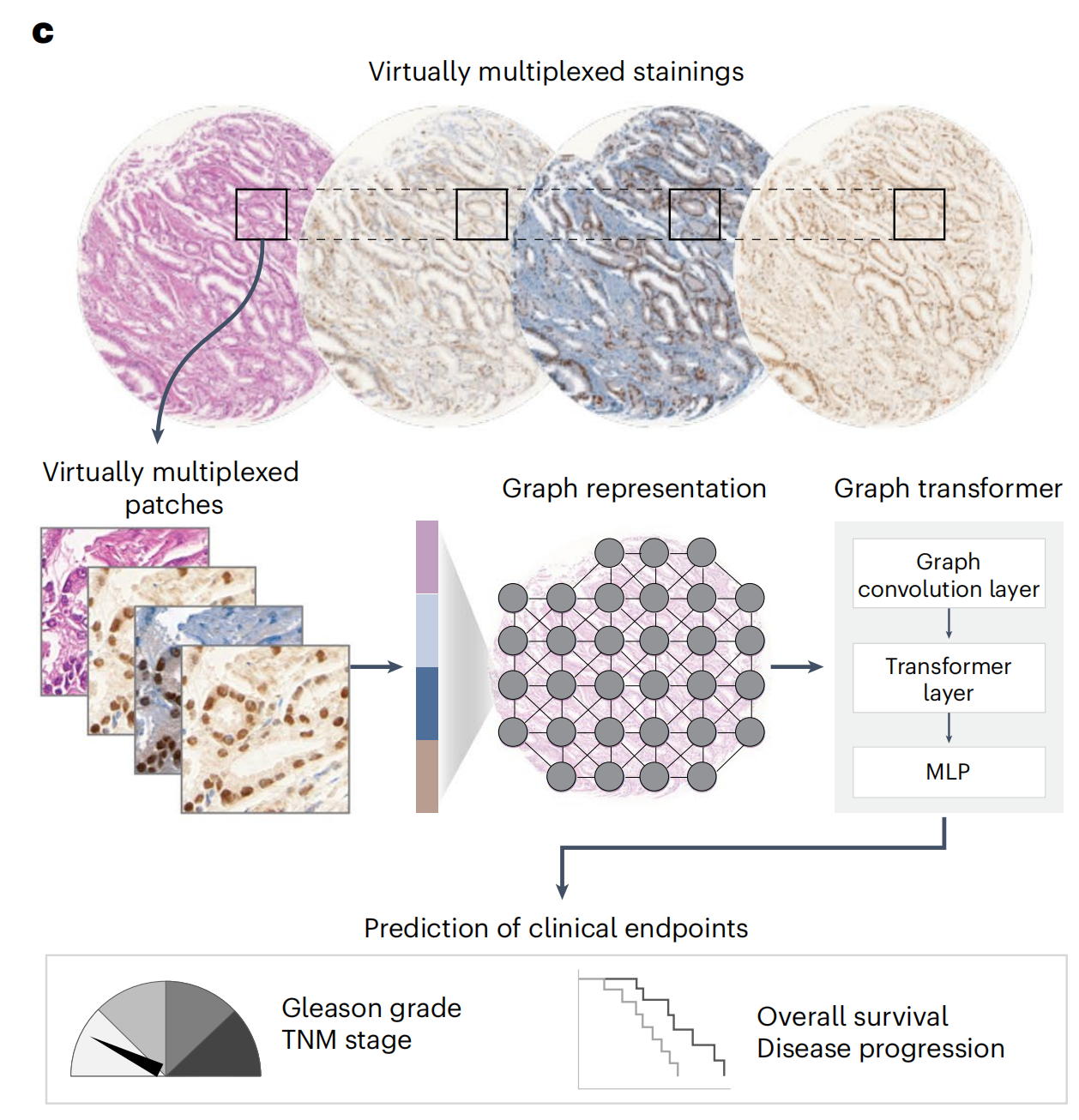
作者成功地将模型转移到了不同的组织图像尺度以及分布外的患者队列,并展示了其跨组织类型转移的潜力(图1d)。
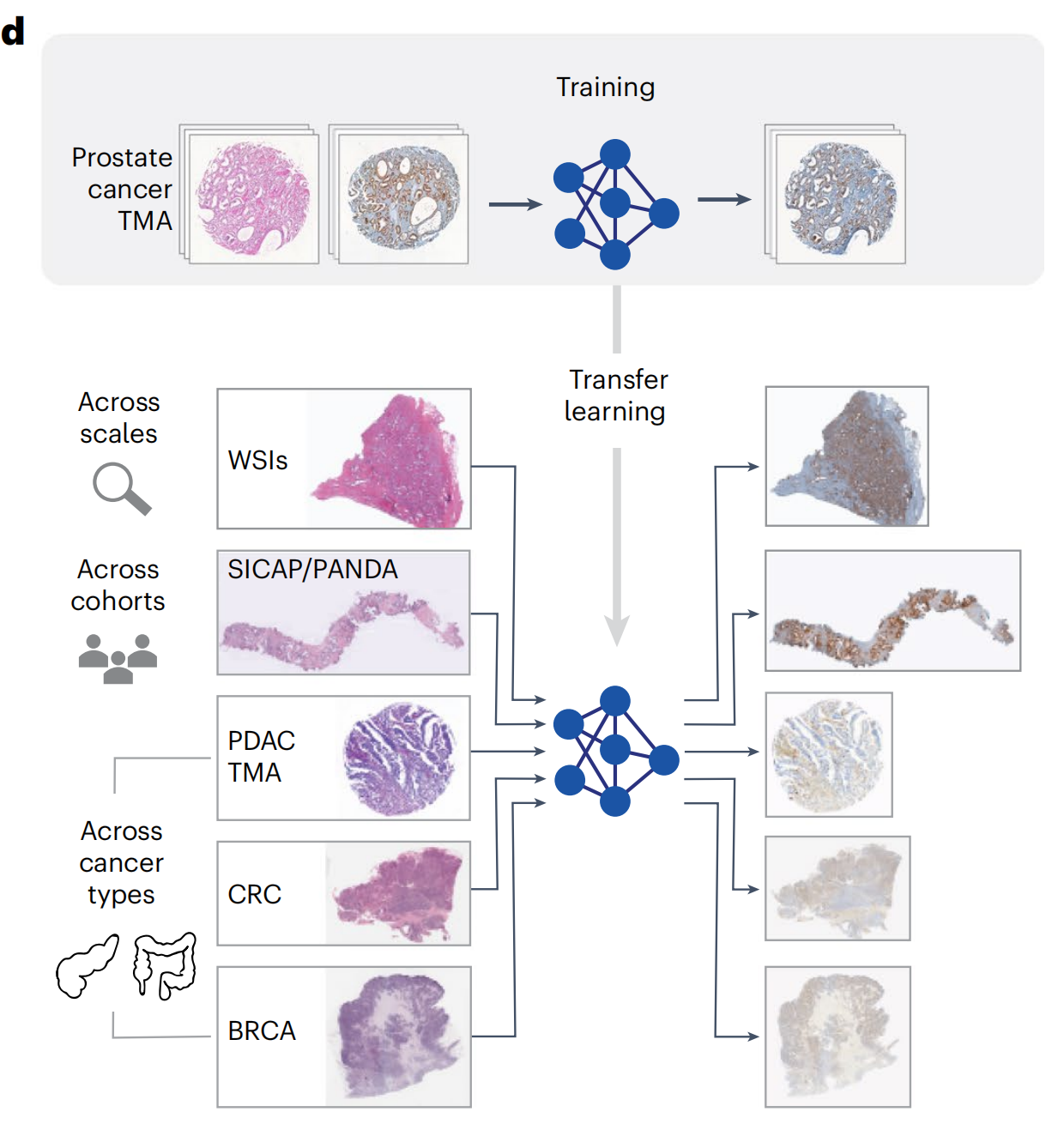
作者的结果表明,VirtualMultiplexer生成了逼真的、与真实无异的、高质量的多重IHC图像,优于现有方法。使用虚拟多重数据集不仅提高了训练队列中临床终点的预测,而且在两个独立的前列腺癌患者队列和一个胰腺导管腺癌(PDAC)队列中也提高了预测,这对组织病理学具有重要意义。
二、结果
2-1:VirtualMultiplexer是一种虚拟多重染色工具包
VirtualMultiplexer是一个用于无配对S2S翻译的生成式工具包,训练于无配对的实际H&E(源)和IHC(目标)图像(图2;详细描述见方法部分)。
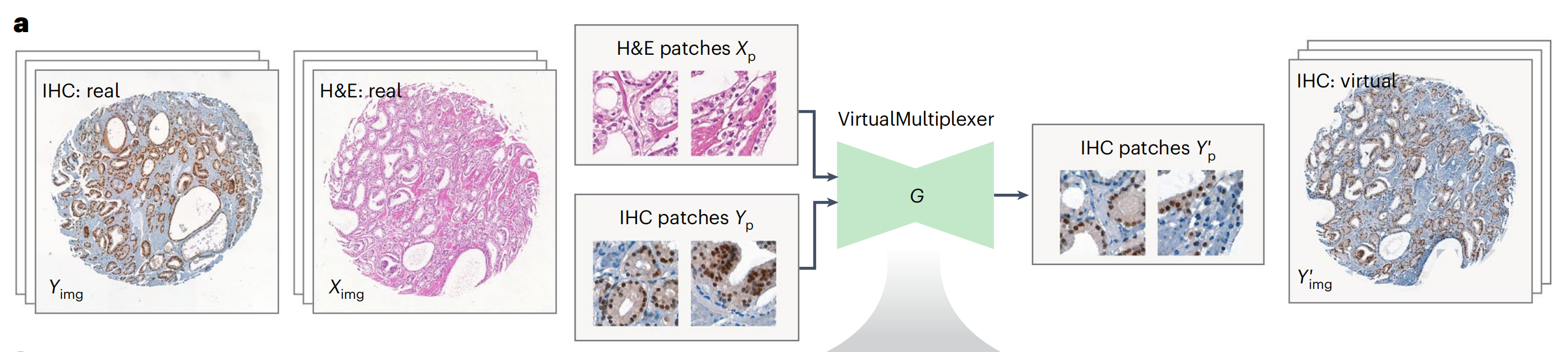
在训练过程中,每个图像被分割成小块,输入到生成器网络G中,该网络以输入的H&E和IHC为条件,学习将IHC捕获的染色模式转移到H&E捕获的组织形态中。生成的IHC小块被拼接在一起,形成虚拟IHC图像(图2a)。
作者为每次一个IHC标记训练独立的VirtualMultiplexer模型。
为确保染色可靠性,作者提出了一种多尺度方法,旨在精确学习单细胞水平上的染色特异性,以及在细胞邻域和整个图像水平上的内容和风格保留,这涉及同时优化三个不同的损失函数(图2b)。
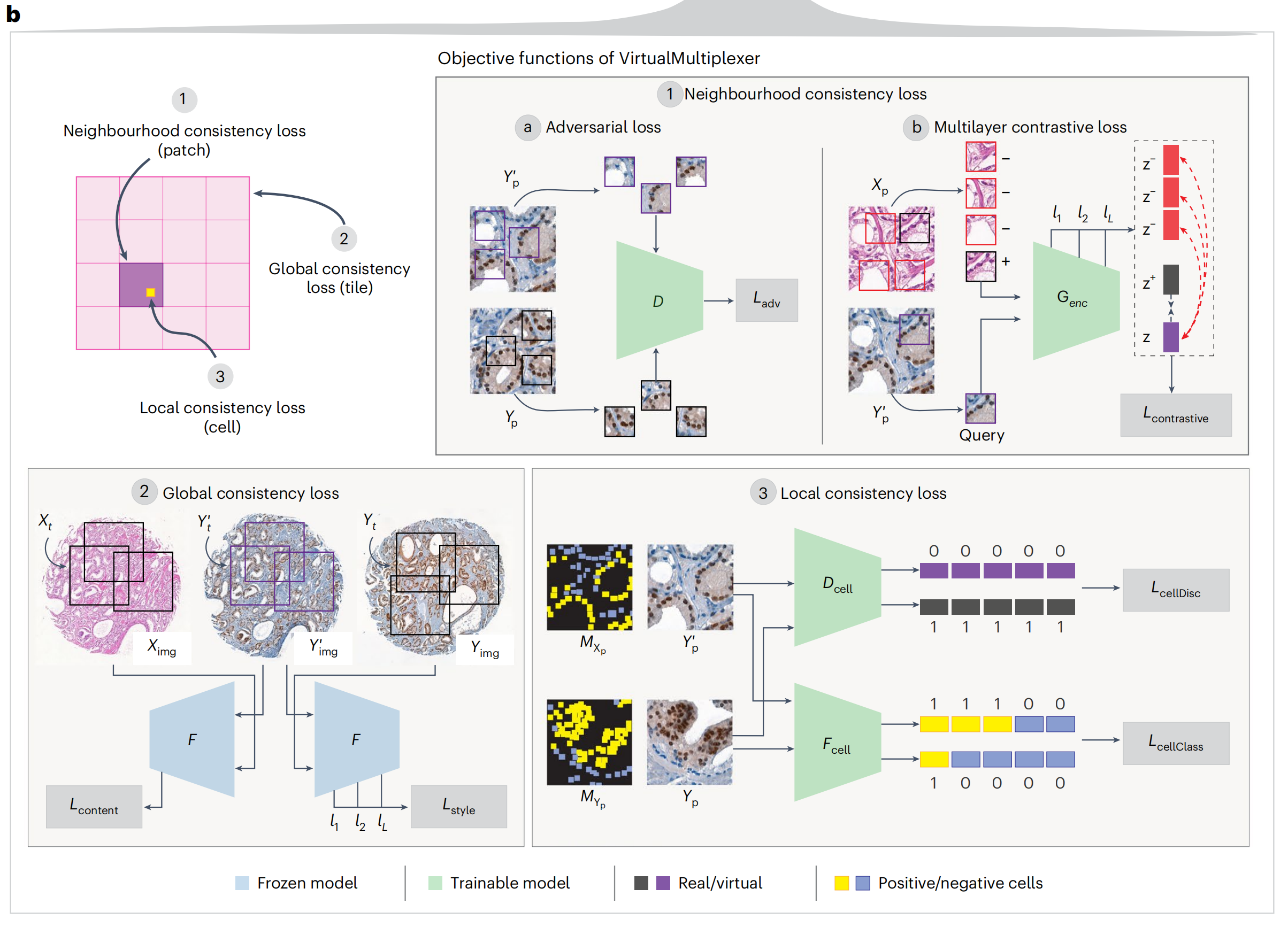
邻域损失(1)确保生成的IHC小块与真实IHC小块无法区分,包括对抗性损失和多层对比损失(图2b),源自CUT34。对抗性损失ℒadv(1a)是一个标准的GAN损失35,其中真实和虚拟IHC小块作为输入传递给小块鉴别器D,尝试将它们分类为真实或虚拟,消除风格差异。多层对比损失(1b)基于小块级别的噪声对比估计(NCE)损失34 ℒcontrastive,确保对应真实H&E和虚拟IHC小块的内容在Genc的多个层次上得到保留。
VirtualMultiplexer引入了全局一致性损失和局部一致性损失(图2b)。全局一致性损失(2)使用特征提取器F,并在F的多个层次上强制实施真实H&E和虚拟IHC图像之间的内容一致性(ℒcontent)以及真实和虚拟IHC图像之间的风格一致性(ℒstyle)。
局部一致性损失(3)使模型能够在细胞水平上捕捉真实的外观和染色模式,同时减轻多子域映射问题。这是通过利用专家注释的染色状态先验知识和训练两个独立的网络实现的:
- 细胞鉴别器Dcell消除真实和虚拟细胞风格差异(ℒcellDisc)
- 细胞分类器Fcell预测染色状态,从而在细胞水平上强制实施染色一致性(ℒcellClass)
2-2:VirtualMultiplexer的性能评估
作者在来自欧洲多中心前列腺癌临床与转化研究组(EMPaCT)TMA36–38的前列腺癌队列上训练了VirtualMultiplexer(方法部分)。
该队列包含了210名患者的无配对H&E和IHC图像,每位患者有四个核心,针对六个临床相关标记:
- 雄激素受体(AR)
- NK3同源框1(NKX3.1)
- CD44
- CD146
- p53
- ERG
VirtualMultiplexer生成的虚拟IHC图像保留了真实H&E图像的组织形态和真实IHC图像的染色模式(图3a–c;附加示例见扩展数据图1)。
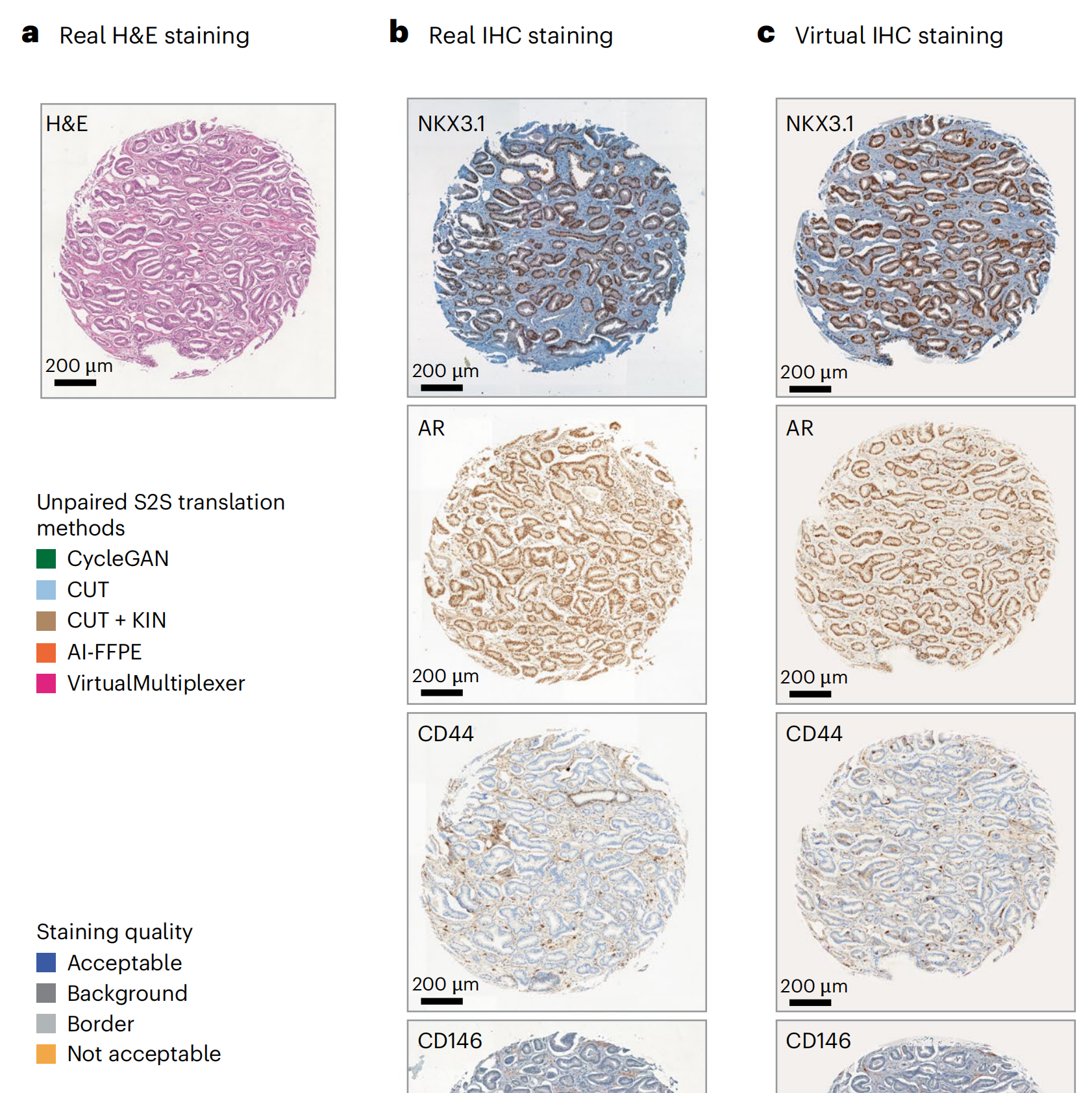
作者使用四种最先进的无配对S2S翻译方法CycleGAN30、CUT34、带核实例标准化(KIN)的CUT39和AI-FFPE29作为基准,使用Fréchet初始距离(FID)这一衡量AI生成图像质量的公认指标(方法部分)。
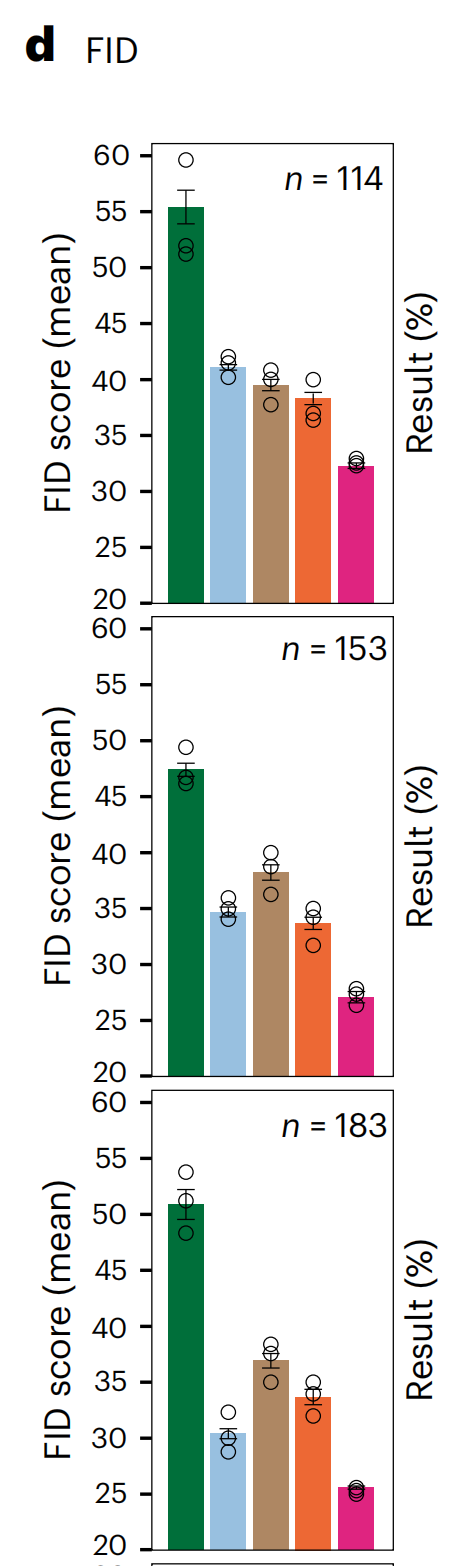
VirtualMultiplexer在所有标记上均获得了最低的FID分数(图3d),平均值为29.2(±3),始终低于CycleGAN(49 ± 6)、CUT(35.8 ± 4.5)、带KIN的CUT(37.8 ± 2.3)和AI-FFPE(35.9 ± 2.6)。
作者还使用了对比-结构相似性分数,这是结构相似性分数的一个变体,用于计算对比和结构保留25,VirtualMultiplexer在性能上再次超越了所有其他模型(补充表1)。这些结果表明,VirtualMultiplexer生成的虚拟图像在分布上比任何竞争方法都更接近真实图像。
为进一步量化真实和虚拟图像的无法区分性,作者进行了一次视觉图灵测试:三位前列腺组织病理学专家和一位认证病理学家被展示了每个标记100个随机选择的小块,其中50个来自真实IHC图像,50个来自虚拟IHC图像,并要求他们分类每个小块为虚拟或真实。
作者的模型能够欺骗专家,因为他们对所有标记的平均敏感性为52.1%,特异性为54.1%(图3e)。
最后,作者进行了染色质量评估:作者给病理学家提供了每个标记50个真实和50个虚拟图像,揭示哪些是真实或虚拟;病理学家对染色进行了定性评估,包括总体表达水平、背景、染色模式、细胞类型特异性和亚细胞定位(图3f;详细注释见补充数据1)。
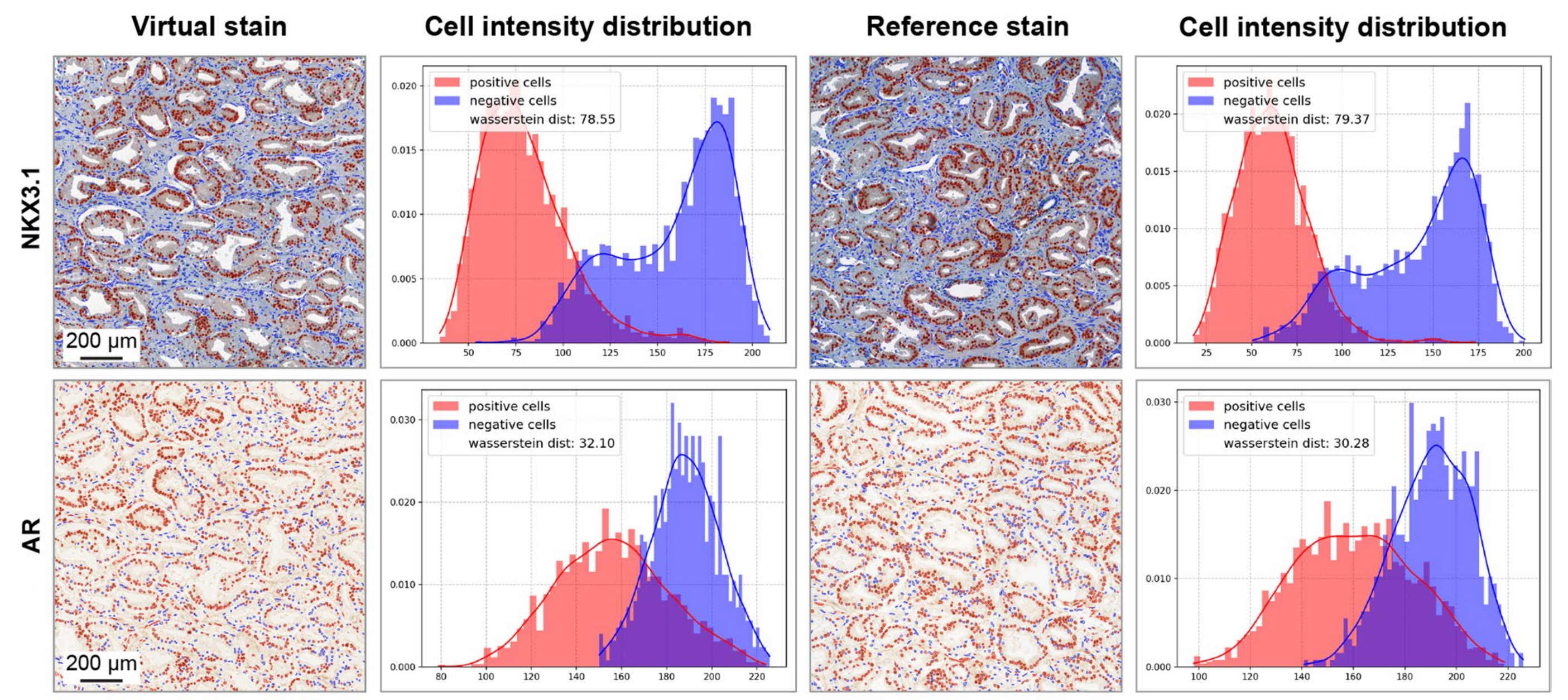
在所有标记上,平均有70.7%的虚拟图像达到了可接受的染色质量,而真实图像为78.3%。结果根据标记的不同而有所变化,其中虚拟NKX3.1和CD146图像达到了最高质量,达到96%,甚至超过了真实图像。相反,虚拟AR图像的得分最低,为46%,另有10%的图像虽然染色准确但背景较高,剩余42%的图像由于染色不均或假阴性细胞而被拒绝。
背景问题也出现在CD44和p53的虚拟图像中;后者还受到边界人工产物的影响,即仅在核心边界出现异常高度染色的细胞,这种情况偶尔也出现在真实图像中。ERG在虚拟图像中的染色质量高于真实图像,但两者都经常面临背景问题。
作者得出结论,对于大多数标记,虚拟与真实图像的染色质量得分和带有染色人工产物的核心数量相当。
在这些观察之后,作者仔细检查了虚拟图像是否捕获了准确的染色模式。
总体而言,对于所有标记,作者观察到了相似的图案、正确的细胞类型和亚细胞分布(扩展数据图2a)。
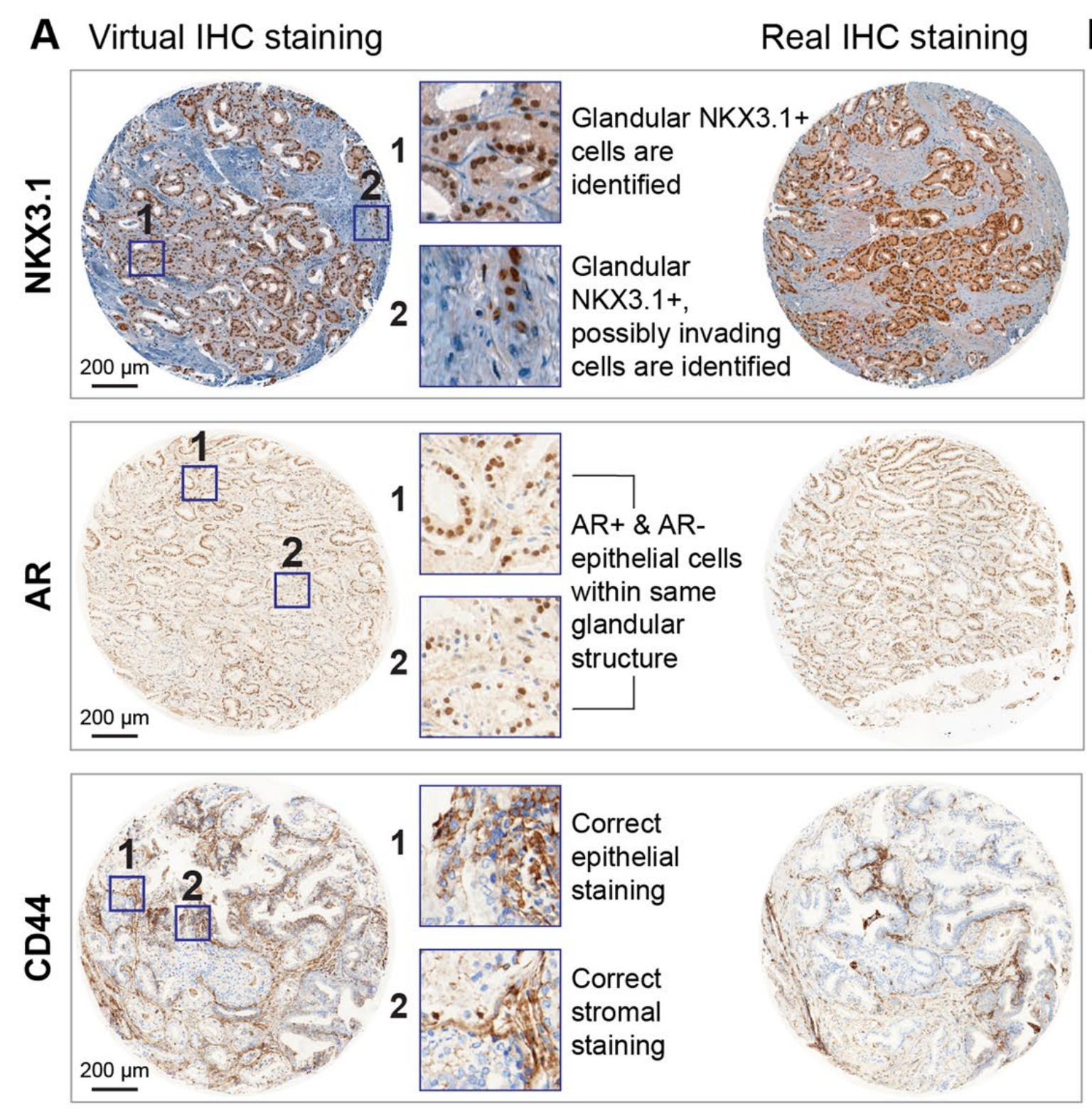
也发现了一些差异,例如系统性地未能识别CD146+血管结构(扩展数据图2b)。然而,对于诊断应用至关重要的更具病理学意义的模式被正确重建。
作者还比较了阳性细胞和阴性细胞的染色强度,并观察到真实和虚拟图像在细胞类别强度分布和可分离性方面的高度一致性,证实虚拟图像忠实地捕获了两种细胞类别的染色强度(扩展数据图3)。
最后,作者进行了一项消融研究,展示了VirtualMultiplexer损失不同组成部分的效果(扩展数据图4)。
仅施加邻域一致性(竞争方法的主要目标)会导致明显的染色不可靠性:例如,阳性细胞和阴性细胞之间的染色模式互换。作者的全局一致性明显缓解了这一问题,作者的局部一致性进一步优化了细胞水平的虚拟染色。
2-3:VirtualMultiplexer模型的跨尺度迁移能力评估
为了评估模型在不同成像尺度上的迁移能力,研究者使用了在TMA上训练的VirtualMultiplexer,将其应用于五张来自前列腺全切片图像(WSI)的H&E染色图像,并生成了NKX3.1、AR和CD146的虚拟IHC图像。
然后,研究者对直接连续切片进行了IHC染色,生成了真实IHC图像,从而生成了真实和可直接比较的WSI图像,以视觉验证模型的预测(方法部分)。
对于NKX3.1(图4),虚拟图像很大程度上捕捉了真实图像的染色外观,无论是特定腺泡腔细胞的识别(阳性信号)(图4和扩展数据图5中的示例1和2),还是准确的非注释性对间质或血管结构的染色(无信号)(图4和扩展数据图5中的示例3)。
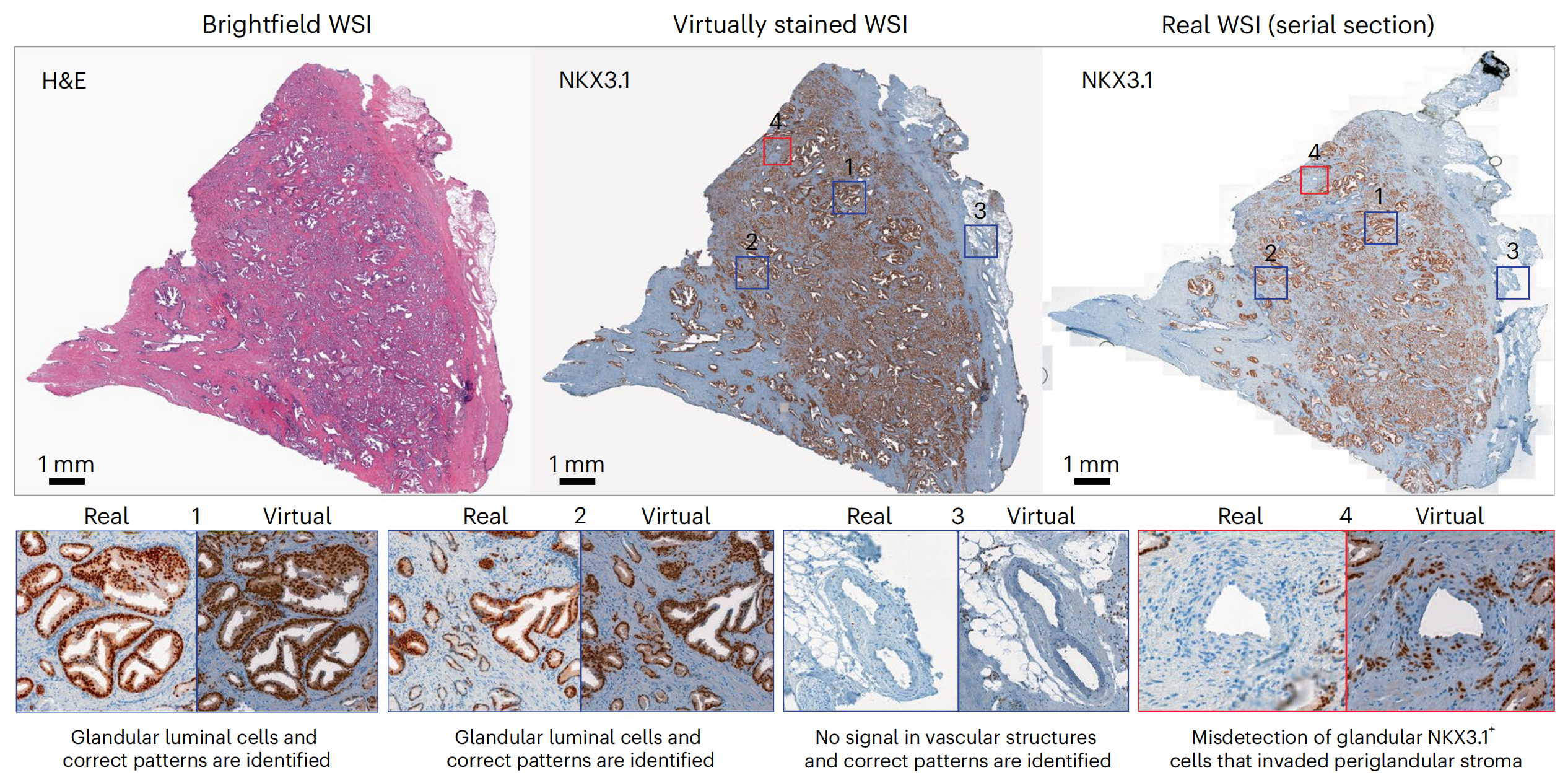
在少数情况下,虚拟图像没有突出显示罕见的不属于腺泡的NKX3.1+细胞群体,而是在腺泡周围的间质中(图4和扩展数据图5中的示例4)。
对于CD146和AR,研究者观察到虚拟和真实图像之间的染色强度差异,尤其是CD146,其中虚拟图像的整体信号强度和背景高于真实图像(图4和扩展数据图5)。
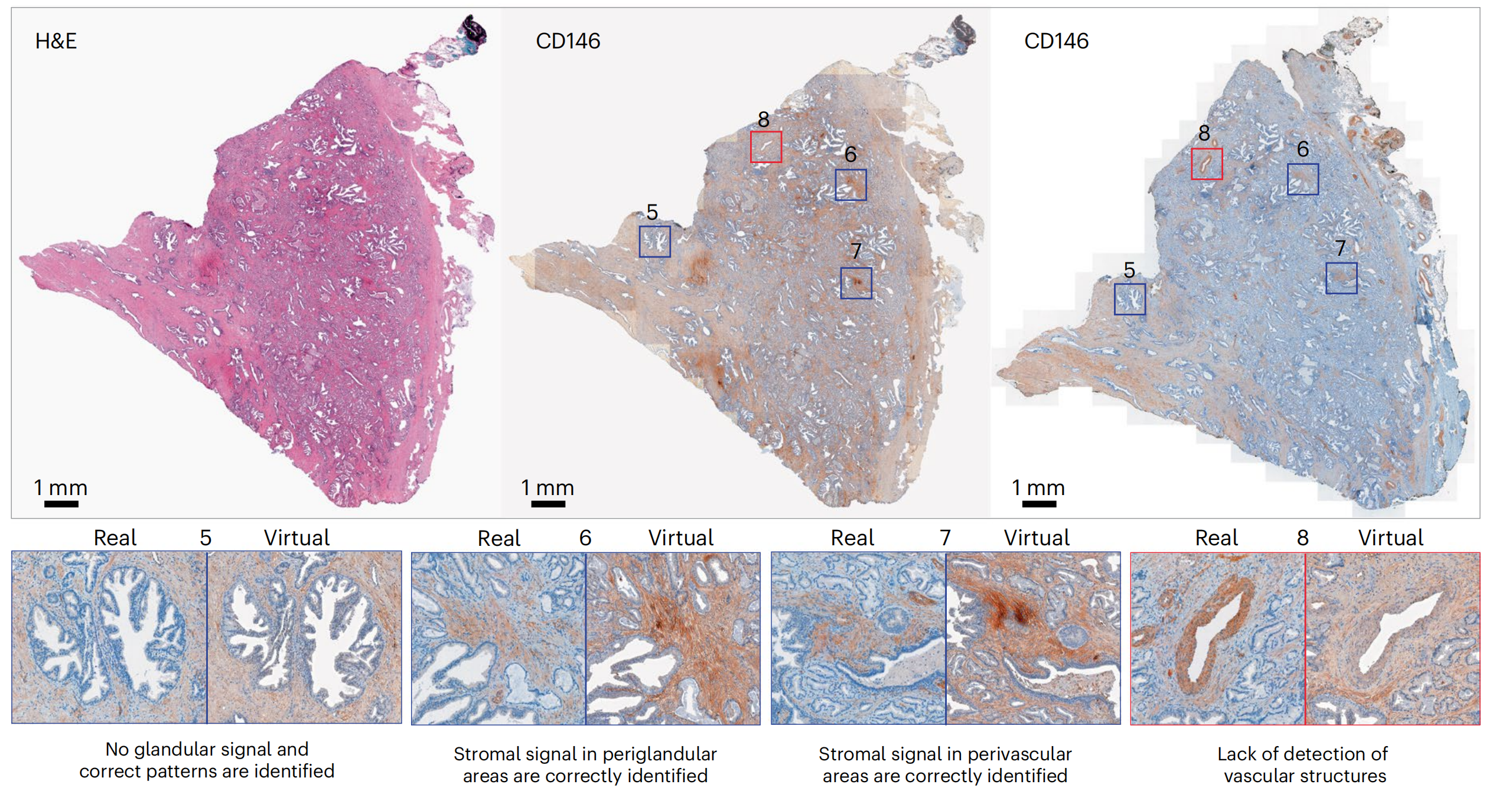
这些差异可以归因于训练集TMA图像的染色分布与WSI不同。尽管这可能导致对标记表达水平的首次观察产生误读,但在更高倍数下评估时,匹配的真实和虚拟区域中的染色模式被有效地正确重建:例如,无腺泡信号(图4中的示例5)和CD146在间质中的适当定位(图4中的示例6和7),以及AR在腺泡腔上皮细胞中的核定位(扩展数据图5中的示例5)。CD146对血管结构的检测缺失在TMA核心和WSI中均很明显(图4中的示例8)。
2-4:VirtualMultiplexer在临床预测中的改进
然后,研究者评估了生成的染色图像在增强AI模型预测临床相关终点方面的实用性。具体来说,研究者将真实的H&E、真实的IHC或虚拟的IHC图像编码为组织图表示,并使用图变换器(GT)41将表示映射到下游类别标签(图5a,b和方法)。
研究者分别在三种设置下训练了GT模型(图5c):
(1)单模态设置,其中为每个H&E和IHC标记独立训练了GT模型;
(2)多模态晚期融合设置,其中独立GT模型的输出在最后的嵌入阶段融合;
(3)多模态早期融合设置,其中将补丁特征在组织图的早期结合,并输入到GT模型中。
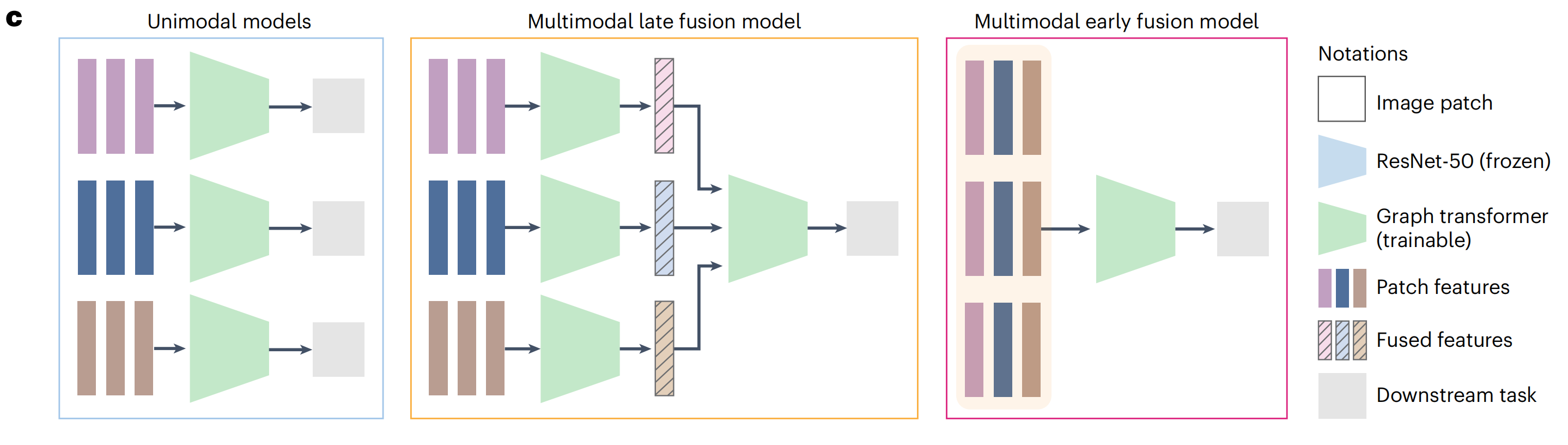
尽管早期融合设置只适用于虚拟图像,研究者还是在真实和虚拟图像作为输入的情况下测试了所有三种设置,共产生了五种不同的组合(图5d,图例)。
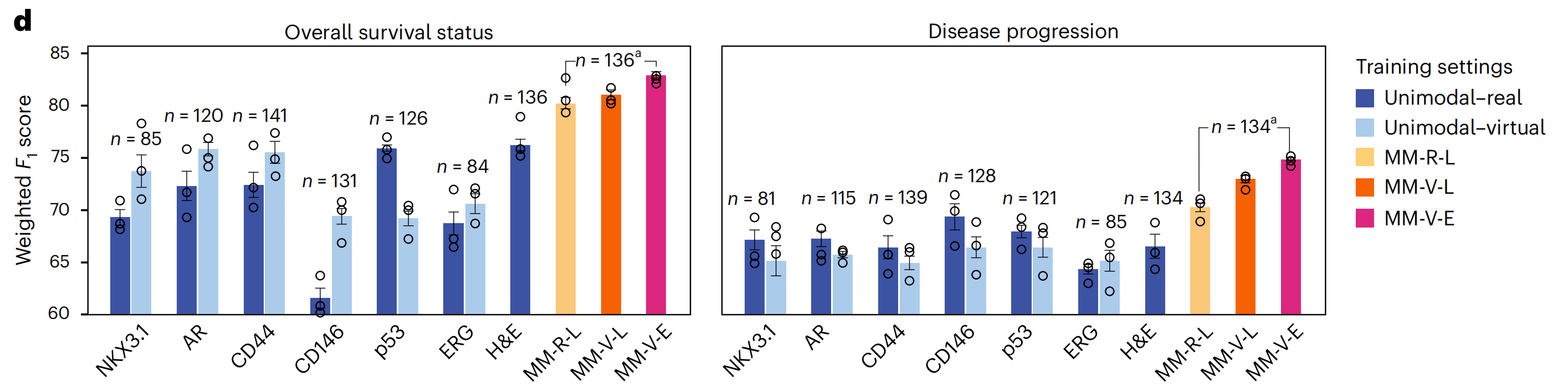
研究者将这些设置应用于EMPaCT数据集,以预测患者的总体生存状态和疾病进展(图5d和方法)。
由于真实IHC图像的数量存在一些差异,研究者将虚拟IHC图像的数量与可用真实IHC图像的数量匹配,以确保真实和虚拟单模态模型之间的公平比较(图5d中的深蓝色和浅蓝色条形图)。
由于H&E图像始终可用,仅在H&E上训练的单模态模型在使用的样本数量方面比所有其他模型略占优势。为了比较所有多模态模型,研究者再次将虚拟图像的数量与可用真实数据匹配,因此图5d中的最后三个条形图也是直接可比的。
研究者观察到,单模态-虚拟设置与单模态-真实设置在两项任务上相当,预测性能取决于标记。
当预测总体生存状态时,CD146和p53有两个有趣的例外:对于CD146,单模态-虚拟设置优于单模态-真实设置,这与之前的观察一致,即虚拟CD146图像的染色质量评分高于真实图像(图3f)。
对于p53,情况则相反:虚拟p53图像的质量低于真实p53图像,相应的单模态-虚拟设置的性能低于单模态-真实设置。然而,这些观察结果并未在疾病进展预测中得到重复,这似乎是一个更难的任务。
在两项任务中,所有多模态设置都优于单模态设置,包括H&E,表明结合互补标记的信息是有用的。此外,使用虚拟图像训练的多模态早期融合模型在总体生存状态和疾病进展方面分别达到了最佳的加权F1分数(82.9%和74.8%)。
研究者还进行了标记级别的可解释性分析,指出与单模态高和低加权F1分数相关的标记的重要性(扩展数据图6)。
总体而言,作者的结果确立了虚拟多重图像在增强AI模型预测临床终点方面的潜力。
2-5:跨患者队列和癌症类型的迁移能力评估
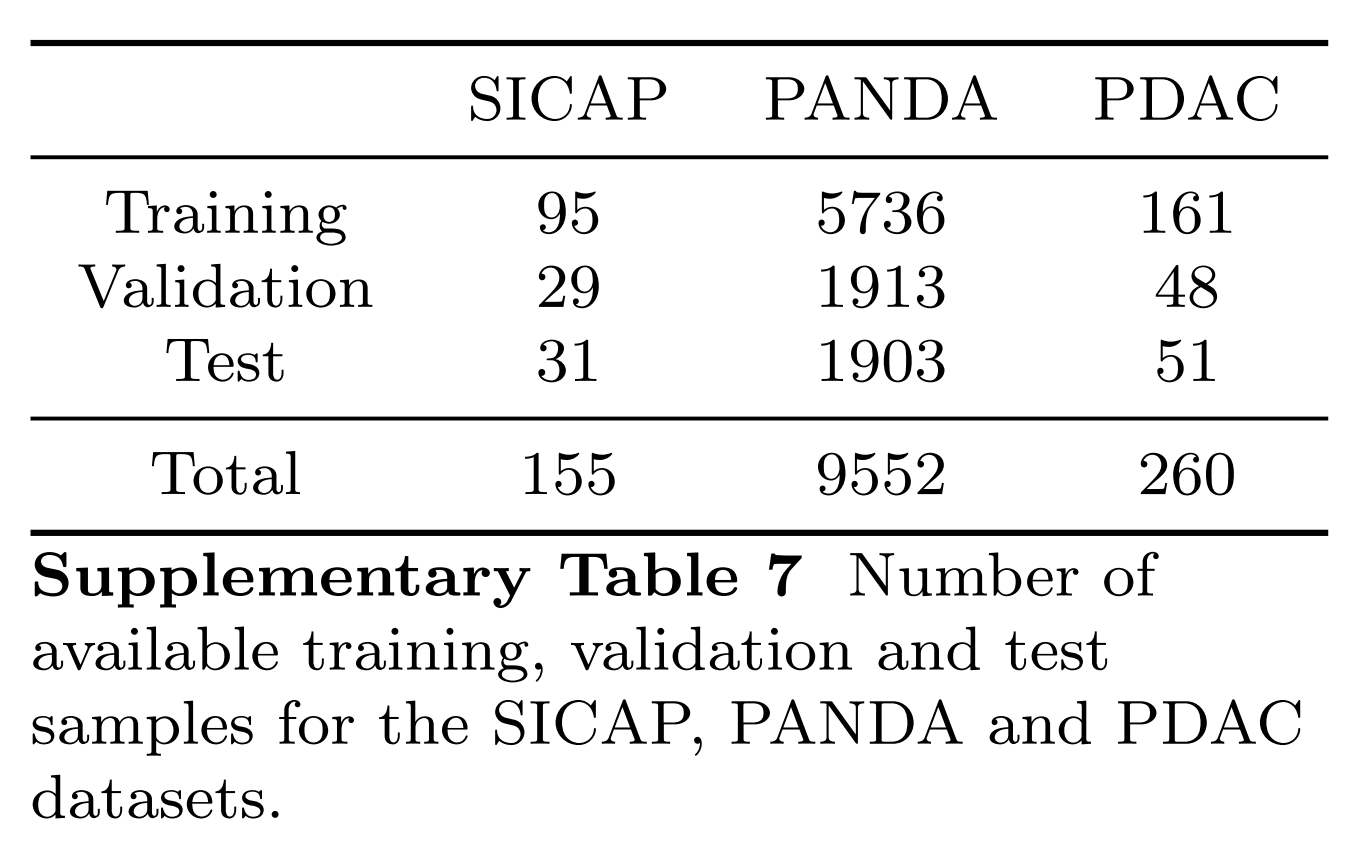
然后,研究者评估了模型将通用化到分布外的数据的能力,使用两个独立的前列腺癌队列,SICAP42和前列腺癌分级评估(PANDA)43,包含与Gleason评分相关的H&E染色针吸活检(方法部分)。
研究者使用了预训练的VirtualMultiplexer来生成四个与Gleason评分预测相关的标记的IHC图像:NKX3.1、CD146、AR和ERG(图6a;扩展数据图7中的附加示例)。
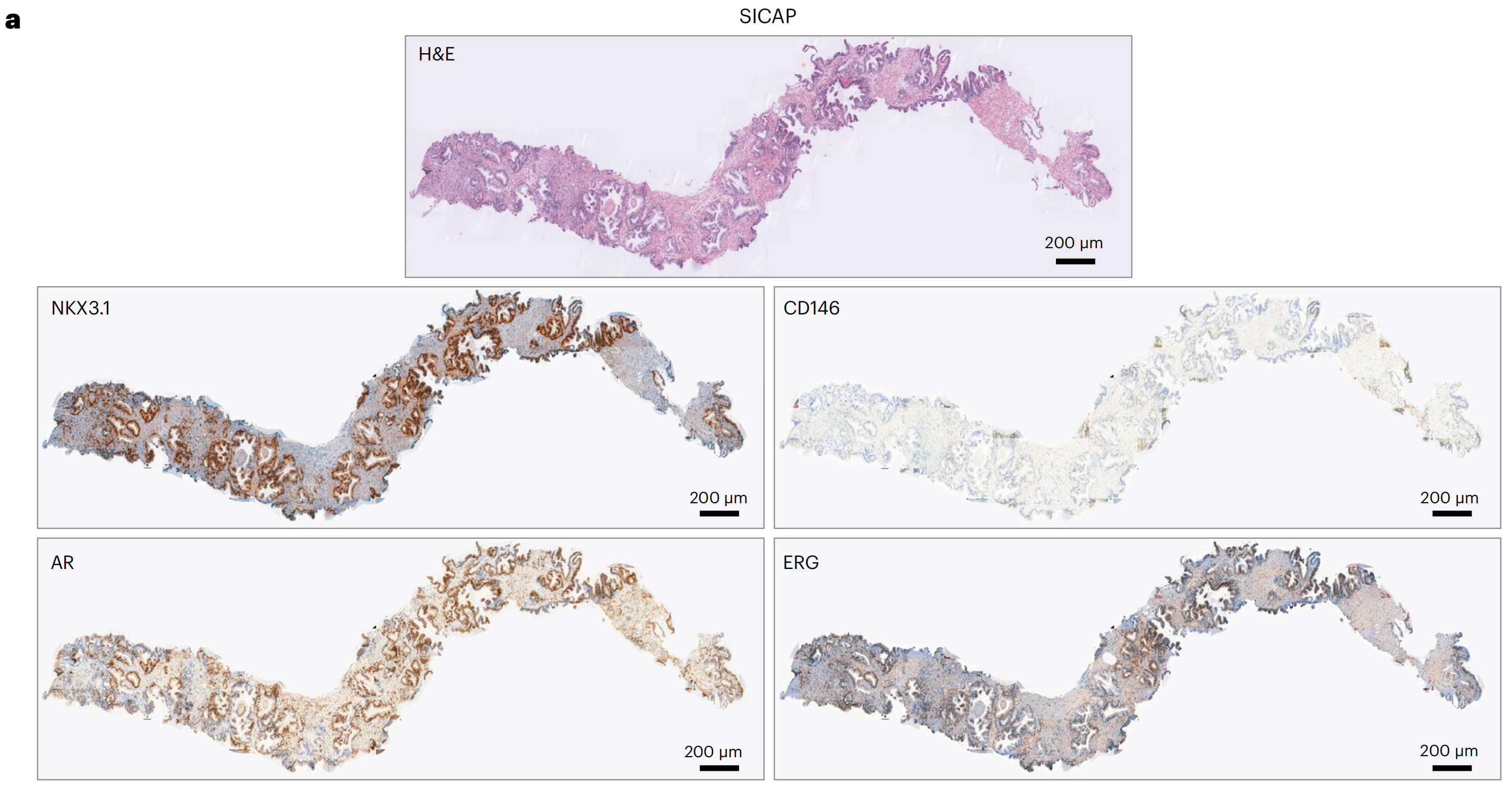
研究者观察到,IHC标记的虚拟染色模式在细胞类型和亚细胞定位方面总体上是正确和特定的,唯一的例外是在细胞外基质区域偶尔出现非特异性AR信号。
其他不一致之处包括CD146对间质组织的弱染色和ERG对腺体的异质染色。研究者还观察到了与EMPaCT TMA(图3)中相同的一些持续问题:背景(例如,NKX3.1和ERG中偶尔出现的间质背景)和边界和拼接人工产物(例如,CD146)。
随后,研究者按照之前的设置训练了GT模型来预测Gleason评分(图6b,c)。
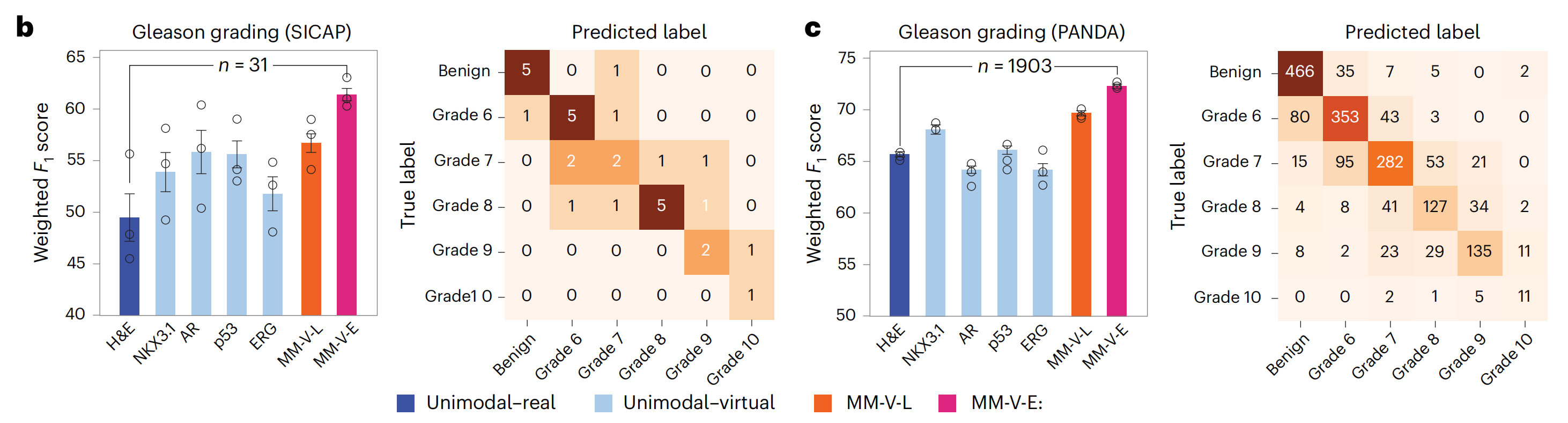
研究者观察到,单模态-虚拟设置的预测性能与仅使用独立H&E图像的模型相当或更优,多模态-虚拟设置的性能进一步提高,早期融合模型达到了最高的加权F1分数(SICAP,61.4%;PANDA,72.3%),这不仅超过了H&E单模态对应模型,而且超过了WholeSIGHT44,这是在这些数据集上以前表现最佳的模型,其加权F1分数分别为58.6%和67.9%。
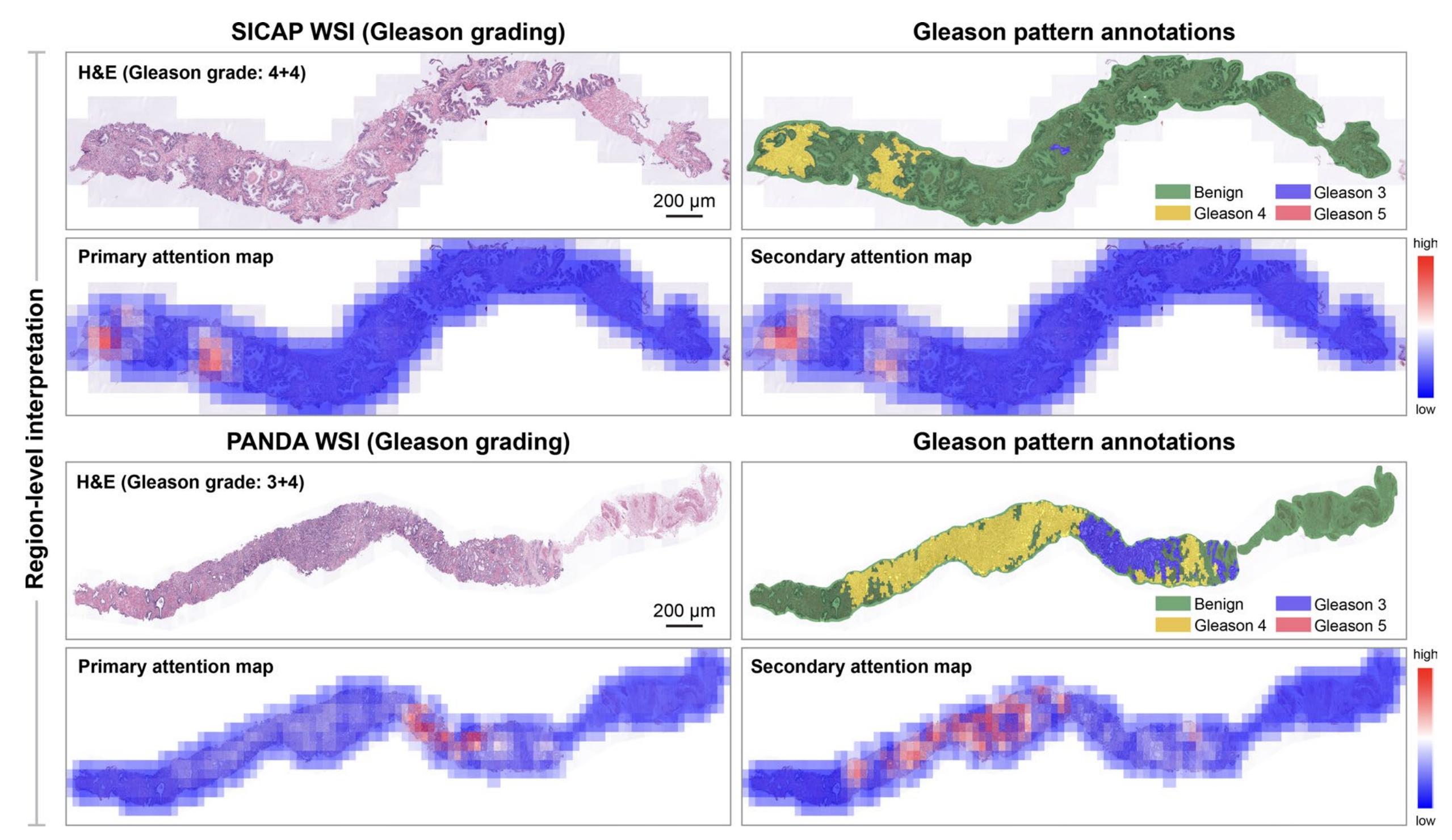
最后,对于SICAP和PANDA,存在真实的区域级Gleason评分注释,研究者进行了基于区域的解释性分析,并观察到模型预测中起关键作用的显著组织区域与真实注释相一致(扩展数据图8)。
最后,研究者评估了VirtualMultiplexer模型在其他癌症类型上的泛化能力。研究者将EMPaCT预训练的VirtualMultiplexer应用于PDAC TMA,并为CD44、CD146和p53生成了虚拟IHC染色(图6d),这三个标记在胰腺组织中预计会有表达。
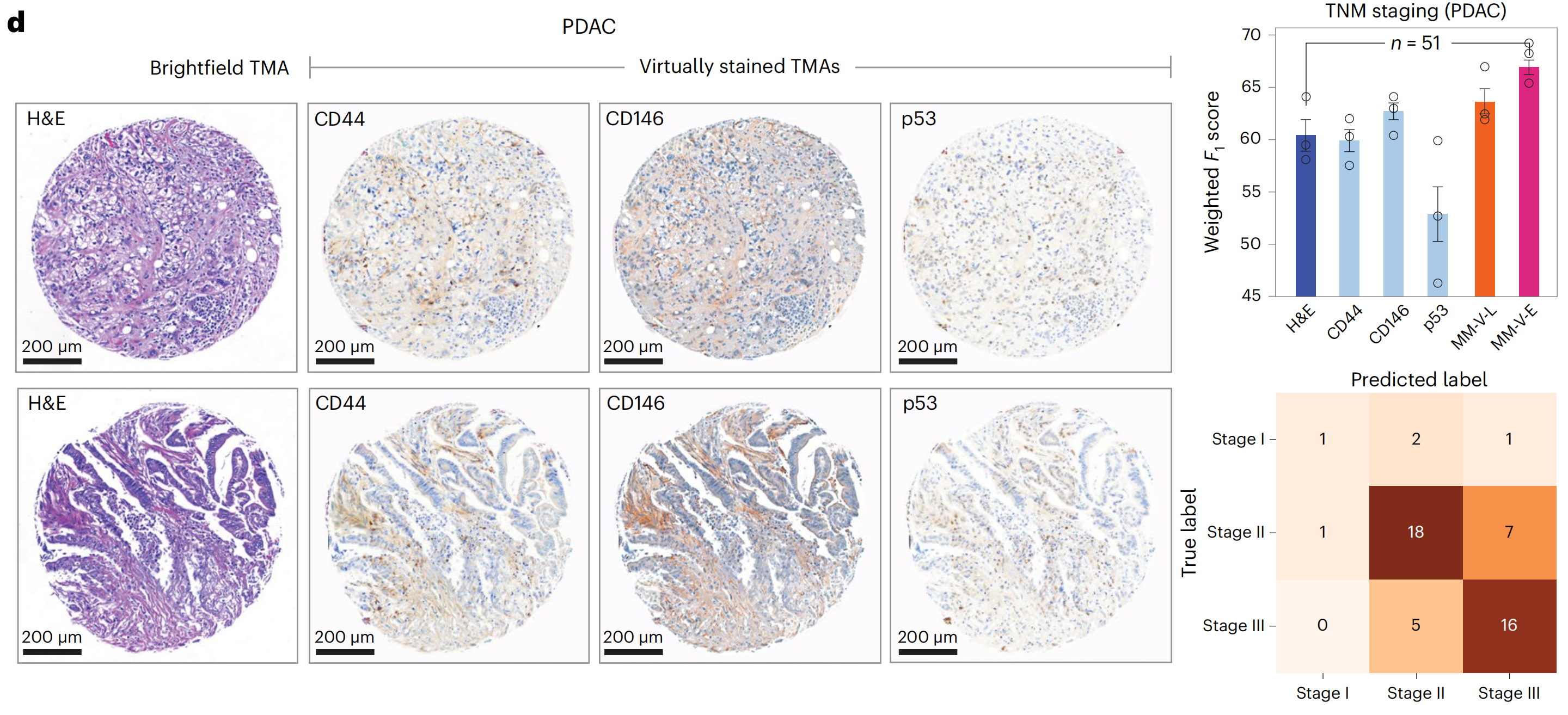
生成的图像整体上看起来逼真,无法区分它们是虚拟还是实际染色的。
研究者观察到,CD44和CD146的染色模式在虚拟图像中被分配到展示组织斑点的细胞外基质中,而没有在表皮组织部分主要染色。对于p53,研究者再次观察到总体上正确分配到上皮细胞核中的染色,其分布符合预期,而没有对其他部分进行主要染色。
为了量化虚拟染色对下游应用的实用性,研究者遵循之前的流程来预测PDAC肿瘤、淋巴结和转移(TNM)分期,结果再次显示,使用虚拟多重数据集训练的模型性能有所提高,得出结论,虚拟多重数据集为预测模型提供了性能优势。
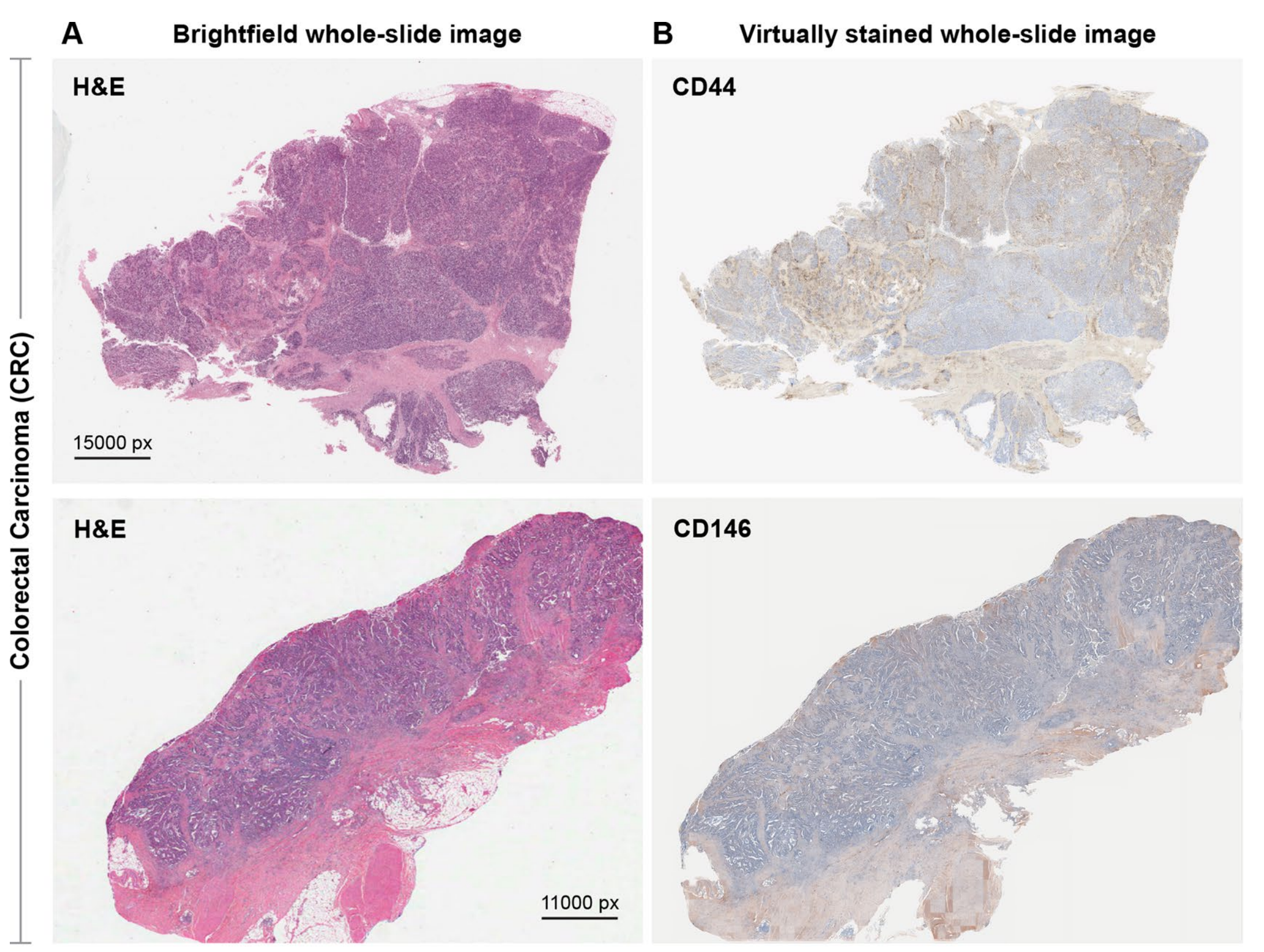
研究者还将预训练的VirtualMultiplexer应用于生成CD44和CD146的虚拟IHC图像,这些图像来自www.cancer.gov/tcga上的The Cancer Genome Atlas(TCGA)的结直肠癌和乳腺癌H&E染色WSI。尽管缺乏正常组织限制了研究者对生成的图像中染色质量的评估能力,但研究者再次观察到了整体逼真的虚拟染色(扩展数据图9)。
最后,研究者对框架的运行时间进行了估计(扩展数据图10),并得出结论,与典型的IHC染色相比,这大大加快了病理学工作流程。
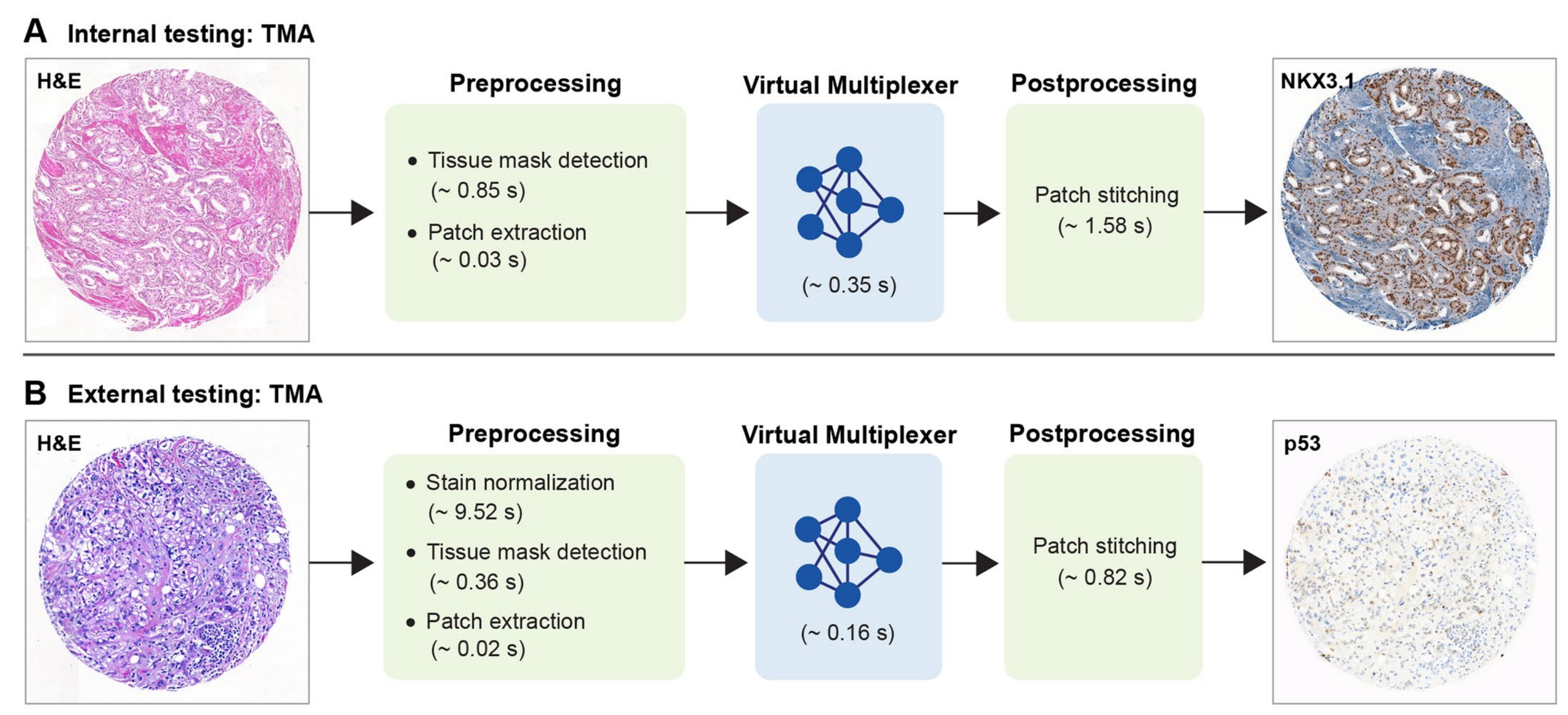
三、讨论
作者提出了VirtualMultiplexer,一个生成模型,它使用多尺度架构和生物先验知识,将H&E转换为多个IHC标记,从而在细胞、邻域和全局整个图像尺度上确保生物一致性,而不需要图像配准或大量注释。
VirtualMultiplexer在图像忠实度评分方面持续优于最先进的方法。
详细评估表明,虚拟IHC图像对于专家眼睛来说与真实图像无法区分,其染色质量与真实图像相当,甚至超越,尽管偶尔出现的染色人工产物与三个标记中的六个标记相比大体可比较。
彻底的消融研究证明,作者的多尺度损失缓解了染色不可靠性,这与仅使用对抗性和对比性目标的竞争方法相反。作者还发现,该模型很好地推广到了未见的数据集,不同的图像尺度,无需任何微调。
尽管作者的结果清楚地展示了潜在的优势,但仍然存在一些局限性,需要在未来的扩展中解决。
首先,作者偶尔观察到背景升高,尤其是对于染色较弱的标记。当转移到前列腺癌WSI时,背景更为显著,这是预期的,因为考虑到这个数据集是在不同机构使用不同的染色协议生成的。
其次,补丁处理偶尔在核心边缘产生了更为明显的拼接人工产物,这是S2S翻译方法的已知局限性24,39,47,48。一种可能的潜在原因是在训练期间,模型只看到了包含完整组织的补丁,当它接收到包含少量组织的补丁作为输入时,损失“迫使”它以更高的强度染色,以匹配完整补丁的分布。
以前尝试解决拼接人工产物的方法24,39被认为会导致翻译效率降低。在作者的情况下,拼接人工产物仅限于边缘情况,一个简单的解决方案是丢弃围绕组织的窄边缘,正如在实际IHC中出现边缘人工产物时所做的那样。
另一种可能更复杂的方法是利用参考文献48中提出的双向特征融合GAN。第三,有时观察到染色特异性方面的差异(例如,未能染色CD146+血管结构和侵入间质区的腺体NKX3.1+细胞),因为这些模式在训练图像中很少出现,可以通过确保在训练集中包含足够的代表性示例来减轻。
重要的是,尽管存在局限性,生成的图像仍能够用于训练早期融合GT模型,这些模型在两个预测任务中的训练数据集以及两个分布外的前列腺癌队列和PDAC TMA队列中均持续改善了临床终点的预测。
在作者的实验中,作者确保多模态早期融合模型不会在数值上优于使用真实数据的模型,并且与晚期融合模型相比,参数空间要小得多,这表明改进的性能不是仅仅由于更高的样本量或模型复杂度。
观察到的改进的可能解释是虚拟图像不受真实图像中偶尔出现的伪影的影响,这得到了以下事实的支持:对于虚拟图像质量高于真实的标记,相应的单模态-虚拟模型优于单模态-真实模型,反之亦然。
另一种可能的解释是多模态早期融合模型能够学习多个标记在同一组织上的联合空间分布,从而能够捕捉单细胞多模态空间关系,模拟由先进的多元成像技术生成的数据。
这得到了以下事实的支持:在早期融合的情况下,单个GT模型比几个同等强度的模型的集成具有更多的学习能力。然而,使用虚拟数据训练的模型的优越性能可能与生成的图像质量的潜在提高无关,而可能是由于VirtualMultiplexer可能捕捉到最一致的模式,并消除了数据中的大量噪声和伪影,使预测任务变得更容易。
这得到了其他工作所报告的竞争力的性能支持,这些工作使用从组织图像中提取的其他空间特征来训练模型50,51。
总的来说,这项工作确立了虚拟多重染色的潜力,对AI辅助病理学具有重要意义。
例如,VirtualMultiplexer可以直接用于数据修复——即填充图像中的缺失区域——或样本插补——即从零开始生成缺失样本。
由于IHC标记面板在实验室之间没有标准化,通过虚拟多重处理填充空白,可以协调研究实验室内部或之间的数据集,特别是在样本可用性有限的情况下52,53。这可能导致生成协调一致和全面的病人队列,进一步用于临床相关的预测。
作者工作的另一个重要应用涉及预病理实验设计:在虚拟环境中生成大量IHC染色,并训练AI模型,以支持实际实验的标记选择,从而降低成本并保留宝贵的组织。
为了实现其全部潜力,未来的工作需要在真实世界环境中验证VirtualMultiplexer。
从技术角度来看,虚拟多重染色可以增强现有数据集,并使IHC的基础模型的发展成为可能,为多模态组织表征铺平了道路。
有趣的是,虚拟多重染色可以作为生物学条件下的数据增强,以提高基础模型在病理学中的开发和预测性能。作者在PDAC和TCGA图像上的初步结果表明,作者的模型具有推广到不同来源组织的潜力。然而,为了巩固这些鼓舞人心的初步结果,需要进行更全面的评估。
最后,由于作者的方法是染料无关的,因此,可以简单地适应S2S翻译,以减少通过抗体面板优化来降低成本。作者的愿景是,未来对作者工作的扩展可能会导致一个不断增长且易于获得的虚拟染色剂词典,超越最先进的多元成像技术,加速空间生物学。
四、方法
4-1:GT架构
GT架构,由参考文献[41]提出,将图神经网络(Graph Neural Network,GNN)和视觉变换器(Vision Transformer,ViT)融合以处理病理学图像。
GNN在病理学图像的图结构表示上操作,其中图的节点和边表示补丁和补丁间的空间连接性,节点编码来自预训练的ResNet-50网络提取的补丁特征。图表示通过图卷积进行上下文化,以适应局部组织邻域的节点特征。
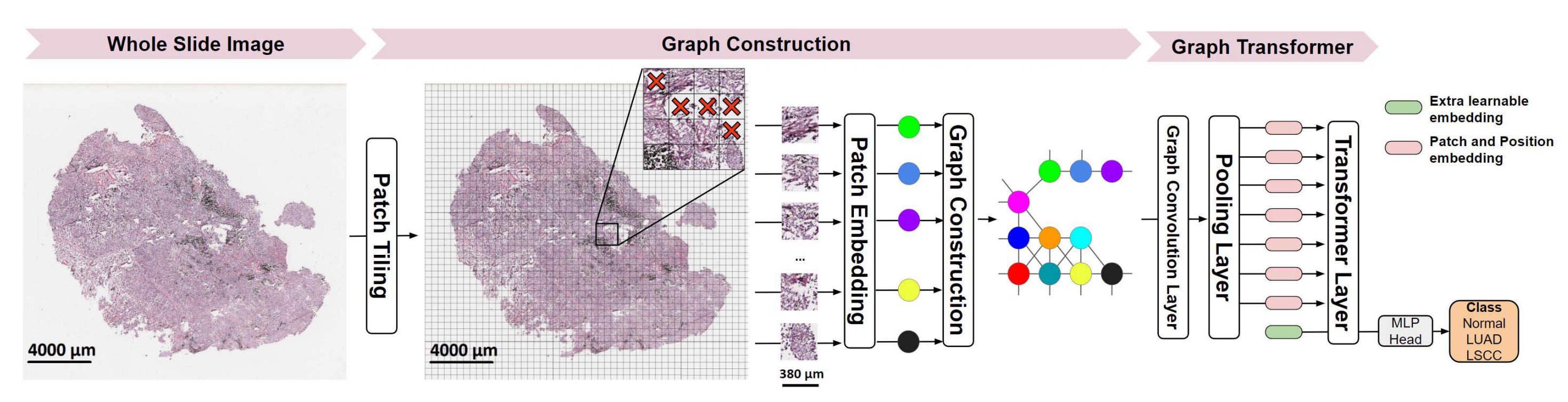
具体来说,GT使用图卷积层69来学习上下文化的节点嵌入,通过传播和聚合邻域节点的信息。随后,ViT层对上下文化的节点特征进行操作,利用自注意力机制权衡节点的重要性,并聚合节点信息以生成图像级特征表示。最后,一个多层感知机(MLP)将图像级特征映射到下游的图像标签。
需要注意的是,病理学图像具有不同的空间维度,因此它们的图表示可以具有不同数量的节点。当操作 gigapixel 级别的 WSI 时,节点的数量可能非常高。这两个因素可能会阻碍将图卷积层整合到 ViT 层中。
为了解决这些挑战,GT引入了一个mincut池化层70,它将节点的数量减少到固定数量的令牌,同时保留节点的局部邻域信息。
4-2:实现和训练细节
GT架构遵循在GitHub上的官方实现(https://github.com/vkola-lab/tmi2022)。
每个输入图像都被裁剪成256 x 256的非重叠补丁,在×10放大倍数下创建。背景补丁中非组织区域大于10%的补丁被丢弃。补丁使用在ImageNet数据集上预训练的ResNet-5064模型进行编码。使用具有八节点连接模式的补丁构建图表示。
GT网络包含一个图卷积层,ViT层的配置如下:ViT块数量=3,MLP大小=128,每个补丁的嵌入维度=32,多头注意力的数量=8。
模型的超参数设置如下:mincut池化中的聚类数量={50, 100},使用Adam优化器,初始学习率={0.0001, 0.00001},采用余弦退火方案进行调度,批量大小为8。
GT模型进行了400个周期的训练,并采用了早期停止。
4-3:数据预处理
对于所有使用的数据集,作者遵循了组织区域检测和补丁提取的预处理程序。
具体来说,使用HistoCartography库74中的预处理工具对组织区域进行分割。
对于每个下采样的输入图像,通过迭代应用高斯平滑和Otsu阈值,计算二值组织掩码,表示组织和非组织区域,直到非组织像素的平均值低于一个阈值。
然后,根据面积过滤估计的组织轮廓和组织的空腔,生成最终的分割掩码。随后,从×10放大倍数下,使用分割轮廓提取非重叠的256×256大小补丁。
EMPaCT数据集中的提取的H&E和IHC补丁用于VirtualMultiplexer的训练和内部验证。
对于未见的数据集(前列腺癌WSI、SICAP、PANDA、PDAC、TCGA),首先对图像进行染色标准化,以减轻与EMPaCT TMAs的染色外观变异,然后提取H&E补丁。
具体来说,对于SICAP、PANDA和PDAC数据集,作者使用HistoCartography库74中的Vahadane染色标准化方法75对整个图像进行处理。作者通过在Lab颜色空间上应用阈值来遮挡空白区域,并仅使用组织区域计算染色密度图。
之后,将目标染色密度图与参考颜色外观矩阵结合,产生标准化图像,这是Vahadane方法所提出的。
补充图1展示了基于参考EMPaCT TMA的PANDA数据集中一个未标准化WSI的相应染色标准化WSI的示例。
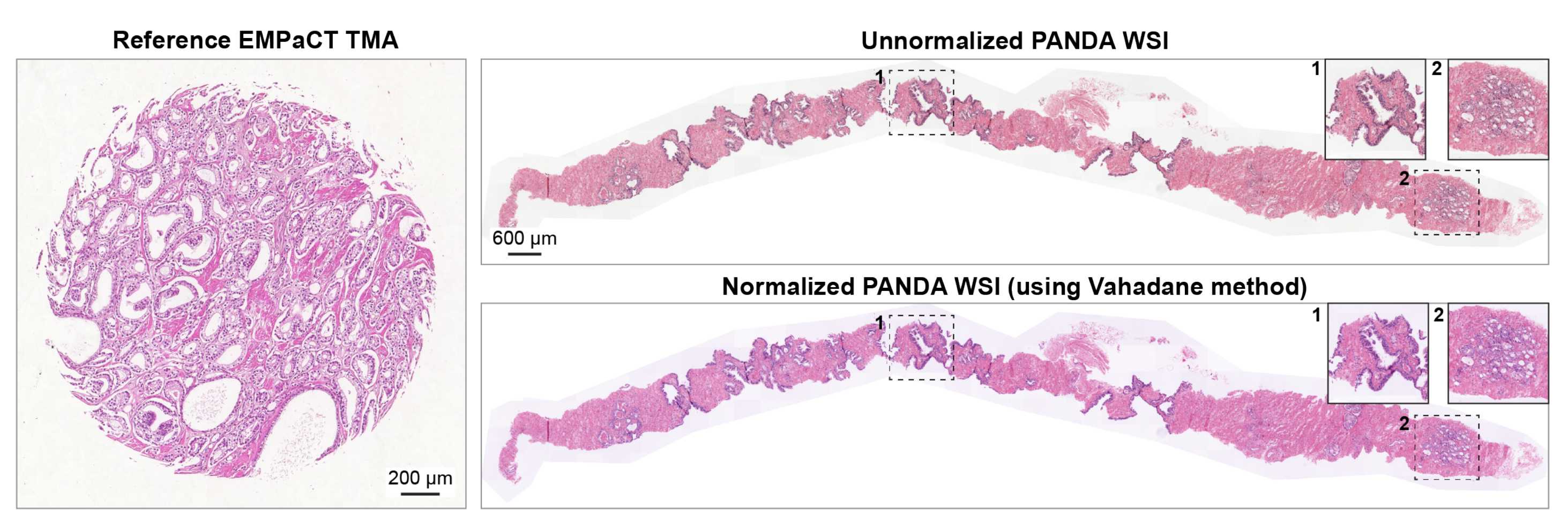
对于前列腺癌和TCGA WSI,作者遵循相同的程序,但使用从较低放大倍数(×2.5)提取的染色密度图以提高计算效率。需要注意的是,VirtualMultiplexer与染色标准化方法无关,可以使用其他高级染色标准化算法(例如,基于深度学习的方法76)对H&E图像进行训练。
4-4:图像级评估
作者使用一系列下游分类任务来评估EMPaCT、SICAP、PANDA和PDAC数据集中虚拟染色的IHC图像的区分能力。
作者进一步使用这些任务来描述利用虚拟多重染色与仅使用独立真实H&E、真实IHC和虚拟IHC染色的实用性。具体来说,提供上述图像,作者按照GT架构部分所述构建图表示。
随后,在单模态和多模态设置下,使用真实和虚拟染色图像训练GTs,并在保留的独立测试数据集上进行评估。最终分类分数报告为加权F1指标,其中较高的分数表示更好的分类性能,从而提高了所使用图像的区分能力。
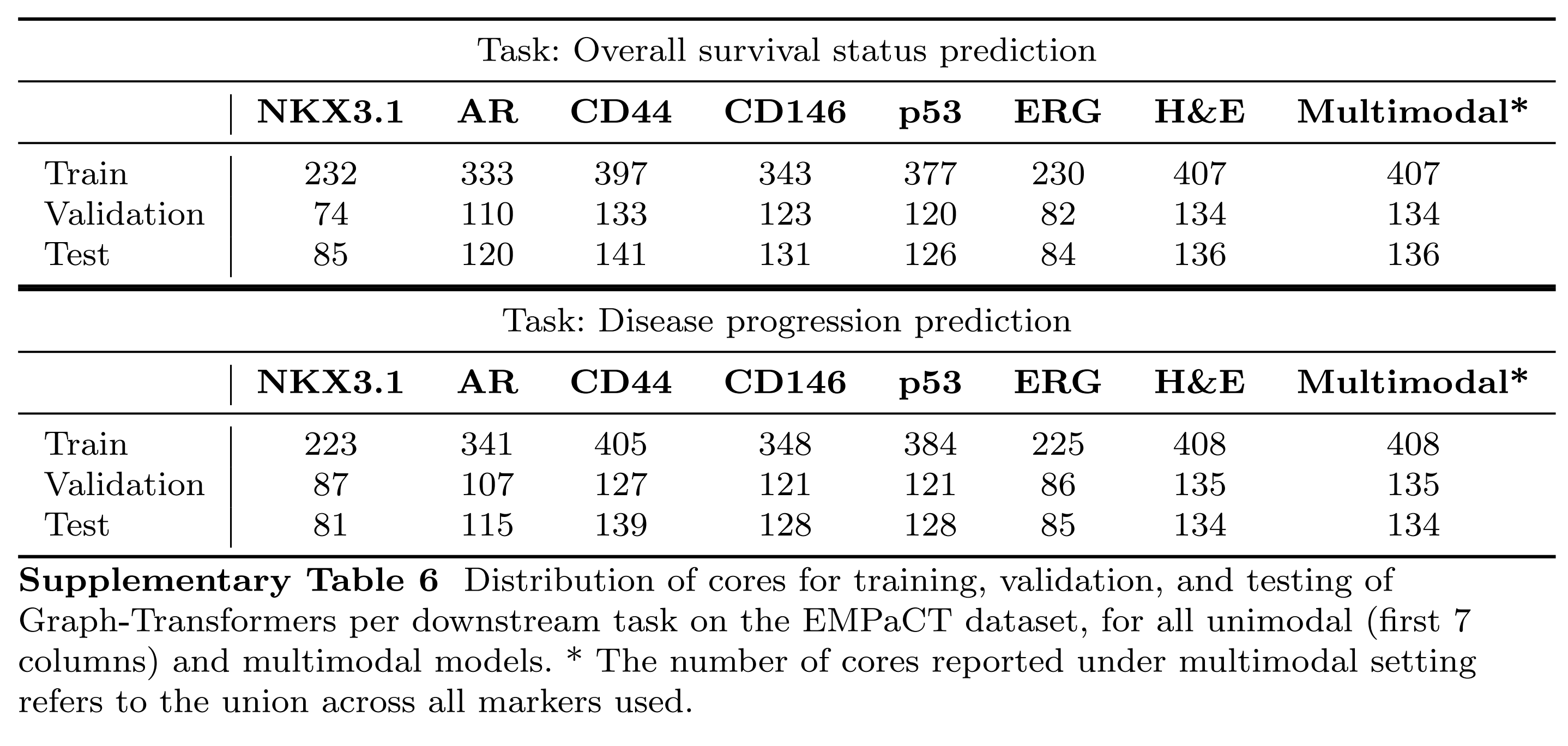
如前所述,作者对每个模型运行三次,每次独立初始化,并计算每个模型的平均值和标准差(图5和6中的条形图高度和误差条)。在所有情况下,作者使用60%:20%:20%的比例将数据分为训练、验证和测试集。EMPaCT数据集中每个任务、标记和训练设置的训练、验证和测试样本数量在补充表6中给出。
对于SICAP、PANDA和PDAC数据集,图6中所有单模态和多模态模型的训练、验证和测试分割中使用的样本数量完全一致,并在补充表7中报告。