本文字数:13885;估计阅读时间:35 分钟
作者:ClickHouse Team
本文在公众号【ClickHouseInc】首发
时间飞逝,又到了新版本发布的时刻!
发布概要
本次ClickHouse 24.8 版本包含了19个新功能🎁、18项性能优化🛷、65个bug修复🐛
这个版本是长期支持 (LTS) 版本,发布后将获得长达 12 个月的支持。如果你想了解稳定版本和 LTS 版本的区别,可以查阅文档。
本次更新包括全新升级的 JSON 类型、针对时间序列数据的表引擎、Kafka 消息的精准一次性处理,当然也少不了对表连接操作的优化!
新贡献者
一如既往,我们热烈欢迎 24.9 版本中的所有新贡献者!ClickHouse 能有今天的流行,离不开社区的辛勤付出。看到这个社区日益壮大,真的让人倍感自豪。
以下是新贡献者名单:
Graham Campbell, Halersson Paris, Jacob Reckhard, Lennard Eijsackers, Miсhael Stetsyuk, Peter Nguyen, Ruihang Xia, Samuele Guerrini, Sasha Sheikin, Vladimir Varankin, Zhukova, Maria, heguangnan, khodyrevyurii, sakulali, shiyer7474, xc0derx, zoomxi
JSON 数据类型
由 Pavel Kruglov 贡献
本次发布中,我们实验性地引入了全新的 JSON 数据类型。这个功能开发已久,之前版本的发布中,我们也提到过它依赖的几种类型——Variable 和 Dynamic。
JSON 数据类型专为存储半结构化数据而设计,适用于每行数据结构可能不同或不希望将其拆分为单独列的情况。
我们将使用 StatsBomb 提供的足球数据集来试验这个功能。数据集包括比赛、阵容和事件信息。
对于此次实验,最有趣的数据是事件信息。事件可能包括传球、解围、封堵等比赛中发生的各种行为。虽然相同类型的事件具有相同的结构,但不同类型事件的字段却不尽相同。
如果你希望亲自操作,可以通过运行以下命令下载数据集:
wget https://github.com/statsbomb/open-data/archive/refs/heads/master.zip接下来,快速查看我们将要处理的数据。我们会使用 JsonAsObject (对象化 JSON) 格式读取数据,这样 ClickHouse 就不会尝试推断 JSON 中各属性的类型。
SELECT
replaceRegexpAll(splitByRegexp('/', _file)[-1], '.json', '') AS matchId,
json
FROM file('master.zip :: **/data/events/*.json', JSONAsObject)
LIMIT 1
FORMAT Vertical
Row 1:
──────
matchId: 15946
json: {"duration":0,"id":"9f6e2ecf-6685-45df-a62e-c2db3090f6c1","index":"1","minute":"0","period":"1","play_pattern":{"id":"1","name":"Regular Play"},"possession":"1","possession_team":{"id":"217","name":"Barcelona"},"second":"0","tactics":{"formation":"442","lineup":[{"jersey_number":"1","player":{"id":"20055","name":"Marc-André ter Stegen"},"position":{"id":"1","name":"Goalkeeper"}},{"jersey_number":"2","player":{"id":"6374","name":"Nélson Cabral Semedo"},"position":{"id":"2","name":"Right Back"}},{"jersey_number":"3","player":{"id":"5213","name":"Gerard Piqué Bernabéu"},"position":{"id":"3","name":"Right Center Back"}},{"jersey_number":"23","player":{"id":"5492","name":"Samuel Yves Umtiti"},"position":{"id":"5","name":"Left Center Back"}},{"jersey_number":"18","player":{"id":"5211","name":"Jordi Alba Ramos"},"position":{"id":"6","name":"Left Back"}},{"jersey_number":"5","player":{"id":"5203","name":"Sergio Busquets i Burgos"},"position":{"id":"9","name":"Right Defensive Midfield"}},{"jersey_number":"4","player":{"id":"5470","name":"Ivan Rakitić"},"position":{"id":"11","name":"Left Defensive Midfield"}},{"jersey_number":"20","player":{"id":"6379","name":"Sergi Roberto Carnicer"},"position":{"id":"12","name":"Right Midfield"}},{"jersey_number":"11","player":{"id":"5477","name":"Ousmane Dembélé"},"position":{"id":"16","name":"Left Midfield"}},{"jersey_number":"9","player":{"id":"5246","name":"Luis Alberto Suárez Díaz"},"position":{"id":"22","name":"Right Center Forward"}},{"jersey_number":"10","player":{"id":"5503","name":"Lionel Andrés Messi Cuccittini"},"position":{"id":"24","name":"Left Center Forward"}}]},"team":{"id":"217","name":"Barcelona"},"timestamp":"00:00:00.000","type":{"id":"35","name":"Starting XI"}}这行数据代表了一场比赛的首发阵容事件,但数据集中还包含数百种其他事件类型。接下来我们看看如何将这些数据加载到 ClickHouse 中。
要使用 JSON 数据类型,需要启用以下配置:
SET allow_experimental_json_type=1;接着,我们将创建一个事件表。该表包含一个存储事件 JSON 数据的 `json` 列,以及一个 matchId 列,用于存储从文件名中提取的比赛 ID。
在创建 ClickHouse 表时,我们需要定义一个排序键,它决定数据在磁盘上的排序方式。此处我们使用 possession_team.id 作为排序键。
目前尚不支持将嵌套字段作为排序键,不过该功能已计划在未来版本中推出。暂时,我们可以创建一个 MATERIALIZED 列,从 JSON 列中提取相应的值,并将其用作排序键。以下是创建表的查询语句:
CREATE TABLE events
(
matchId String,
json JSON,
possession_team_id String MATERIALIZED getSubcolumn(json, 'possession_team.id')
)
ENGINE = MergeTree
ORDER BY possession_team_id;接下来,我们可以复制之前的 SELECT 查询,并在其前面添加 INSERT INTO events 语句来加载数据:
INSERT INTO events
SELECT
replaceRegexpAll(splitByRegexp('/', _file)[-1], '.json', '') AS matchId,
json
FROM file('master.zip :: **/data/events/*.json', JSONAsObject)
0 rows in set. Elapsed: 72.967 sec. Processed 12.08 million rows, 10.39 GB (165.60 thousand rows/s., 142.42 MB/s.)
Peak memory usage: 3.52 GiB.加载 1200 万条事件数据大约需要一分钟时间。之后,我们可以编写一个使用 JSON 点语法的查询来找出最常见的事件类型:
SELECT
json.type.name,
count() AS count
FROM events
GROUP BY ALL
ORDER BY count DESC
LIMIT 10
┌─json.type.name─┬───count─┐
│ Pass │ 3358652 │
│ Ball Receipt* │ 3142664 │
│ Carry │ 2609610 │
│ Pressure │ 1102075 │
│ Ball Recovery │ 363161 │
│ Duel │ 255791 │
│ Clearance │ 157713 │
│ Block │ 130858 │
│ Dribble │ 121105 │
│ Goal Keeper │ 105390 │
└────────────────┴─────────┘点语法在读取字面值时非常方便,但它并不适用于读取子对象。例如,下面的查询尝试统计最常见的 possession_team:
SELECT
json.possession_team AS team,
count()
FROM events
GROUP BY team
ORDER BY count() DESC
LIMIT 10
┌─team─┬──count()─┐
│ ᴺᵁᴸᴸ │ 12083338 │
└──────┴──────────┘结果显示,所有值都为 null!
点语法由于性能原因,不会读取嵌套对象。数据存储方式使得通过路径读取字面值非常高效,但如果要读取所有子对象,数据量会增加,速度可能变慢。
如果我们需要返回一个对象,则需要使用 .^ 语法。这种特殊语法专用于从 JSON 数据类型字段中读取嵌套对象:
SELECT
json.^possession_team AS team,
count()
FROM events
GROUP BY team
ORDER BY count() DESC
LIMIT 10
┌─team──────────────────────────────────────┬─count()─┐
│ {"id":"217","name":"Barcelona"} │ 1326515 │
│ {"id":"131","name":"Paris Saint-Germain"} │ 239930 │
│ {"id":"1","name":"Arsenal"} │ 154789 │
│ {"id":"904","name":"Bayer Leverkusen"} │ 147473 │
│ {"id":"220","name":"Real Madrid"} │ 135421 │
│ {"id":"968","name":"Arsenal WFC"} │ 131637 │
│ {"id":"746","name":"Manchester City WFC"} │ 131017 │
│ {"id":"971","name":"Chelsea FCW"} │ 115761 │
│ {"id":"212","name":"Atlético Madrid"} │ 110893 │
│ {"id":"169","name":"Bayern Munich"} │ 104804 │
└───────────────────────────────────────────┴─────────┘在读取多层嵌套的子对象时,若只想返回某个子对象,只需在路径中的第一个对象使用 .^ 语法。例如:
select json.^pass.body_part AS x, toTypeName(x)
FROM events
LIMIT 1;
┌─x───────────────────────────────┬─toTypeName(x)─┐
│ {"id":"40","name":"Right Foot"} │ JSON │
└─────────────────────────────────┴───────────────┘这种语法仅限于返回对象。如果试图使用它返回字面值,将得到一个空的 JSON 对象:
SELECT
json.^possession_team.name AS team, toTypeName(team),
count()
FROM events
GROUP BY team
ORDER BY count() DESC
LIMIT 10;
┌─team─┬─toTypeName(team)─┬──count()─┐
│ {} │ JSON │ 12083338 │
└──────┴──────────────────┴──────────┘我们计划添加一个新操作符 .^$,它可以同时返回字面值和子对象,作为单一子列。
当返回字面值时,它们的类型将为 Dynamic。可以使用 dynamicType 函数来确定每个值的实际底层类型:
SELECT
json.possession_team.name AS team,
dynamicType(team) AS teamType,
json.duration AS duration,
dynamicType(duration) AS durationType
FROM events
LIMIT 1
┌─team────┬─teamType─┬─duration─┬─durationType─┐
│ Arsenal │ String │ 0.657763 │ Float64 │
└─────────┴──────────┴──────────┴──────────────┘我们还可以使用 .:后缀来假定数据类型,并使用::进行类型转换。
SELECT
json.possession_team.name AS team,
toTypeName(team),
json.possession_team.name.:String AS teamAssume,
toTypeName(teamAssume) AS assumeType,
json.possession_team.name::String AS teamCast,
toTypeName(teamCast) AS castType
FROM events
LIMIT 1;
┌─team────┬─toTypeName(team)─┬─teamAssume─┬─assumeType───────┬─teamCast─┬─castType─┐
│ Arsenal │ Dynamic │ Arsenal │ Nullable(String) │ Arsenal │ String │
└─────────┴──────────────────┴────────────┴──────────────────┴──────────┴──────────┘最后要注意的是,JSON 数据类型的列可以进一步配置。例如,如果希望排除存储中的某些 JSON 对象部分,可以通过在 JSON 路径中使用 SKIP 和 SKIP REGEXP 跳过特定路径。
例如,以下创建表的语句跳过了 pass.body.part 路径以及任何以字母 t 开头的路径:
CREATE TABLE events2
(
matchId String,
json JSON(
SKIP pass.body_part,
SKIP REGEXP 't.*'
),
possession_team_id String MATERIALIZED getSubcolumn(json, 'possession_team.id')
)
ENGINE = MergeTree
ORDER BY possession_team_id;在将数据导入带有额外设置的 JSON 列的表时,ClickHouse 不会自动将传入的数据转换为正确的类型,不过这一问题将在未来的版本中得到修复。目前,我们需要在导入查询中显式定义 JSON 列的类型:
INSERT INTO events2
SELECT
replaceRegexpAll(splitByRegexp('/', _file)[-1], '.json', '') AS matchId,
json
FROM file(
'master.zip :: **/data/events/*.json',
JSONAsObject,
'`json` JSON(SKIP `pass.body_part`, SKIP REGEXP \'t.*\')'
);
0 rows in set. Elapsed: 75.122 sec. Processed 12.08 million rows, 10.39 GB (160.85 thousand rows/s., 138.33 MB/s.)
Peak memory usage: 3.52 GiB.如果我们查询 events2 表,会发现这些子路径已经不再存在:
SELECT json.^pass AS pass
FROM events3
WHERE empty(pass) != true
LIMIT 3
FORMAT Vertical;
Row 1:
──────
pass: {"angle":-3.1127546,"end_location":[49.6,39.7],"height":{"id":"1","name":"Ground Pass"},"length":10.404326,"recipient":{"id":"401732","name":"Jaclyn Katrina Demis Sawicki"},"type":{"id":"65","name":"Kick Off"}}
Row 2:
──────
pass: {"angle":2.9699645,"end_location":[28,44.2],"height":{"id":"1","name":"Ground Pass"},"length":22.835499,"recipient":{"id":"401737","name":"Hali Moriah Candido Long"}}
Row 3:
──────
pass: {"angle":-1.7185218,"end_location":[27.1,27.1],"height":{"id":"1","name":"Ground Pass"},"length":16.984993,"recipient":{"id":"389446","name":"Jessika Rebecca Macayan Cowart"}}我们还可以为路径提供类型注释:
CREATE TABLE events3
(
matchId String,
json JSON(
pass.height.name String,
pass.height.id Int64
),
possession_team_id String MATERIALIZED getSubcolumn(json, 'possession_team.id')
)
ENGINE = MergeTree
ORDER BY possession_team_id;此外,还有一些额外设置,如 max_dynamic_paths 和 max_dynamic_types。这些设置用于控制数据在磁盘上的存储方式。你可以在 JSON 数据类型的文档中了解更多详细信息【https://clickhouse.com/docs/en/sql-reference/data-types/newjson】。
合并期间投影的控制
由 ShiChao Jin 贡献
在 ClickHouse 中,表格可以有“投影”,即原始表的隐藏副本,并保持同步。投影通常会使用不同的主键(因此行的顺序也不同),并且可以在其中逐步预计算聚合值。
当用户执行查询时,ClickHouse 会决定是从原始表读取数据,还是从投影中读取。如下图所示:
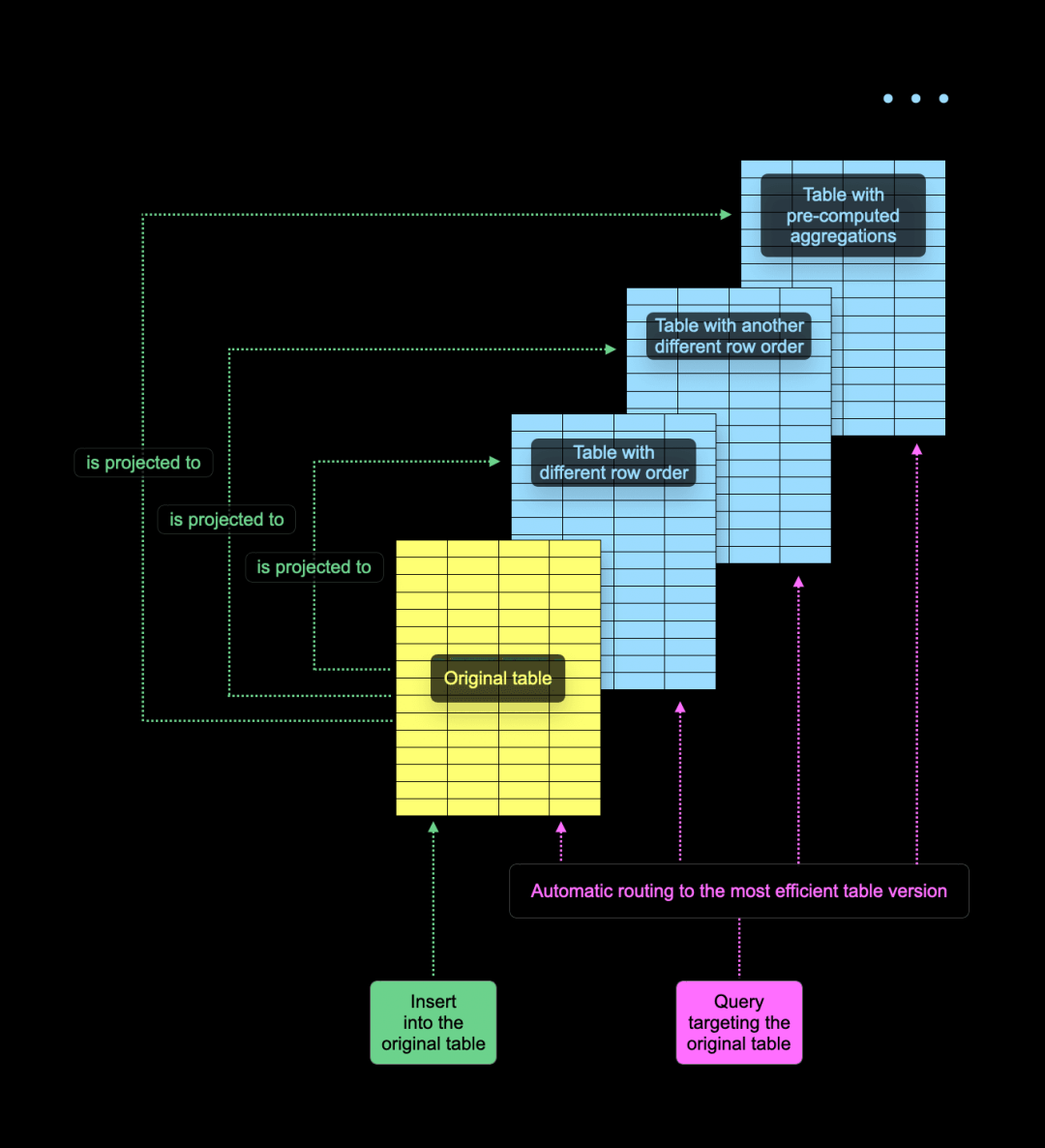
ClickHouse 会为每个表部分单独做出读取原始表还是投影的选择。通常,ClickHouse 会尽量减少数据读取量,并采用一些技巧,例如对部分主键进行采样,以确定最佳读取部分。在某些情况下,源表部分可能没有对应的投影部分。这可能是因为在 SQL 中创建表的投影时默认是“惰性”的——即它只会影响新插入的数据,而不会更改现有部分。
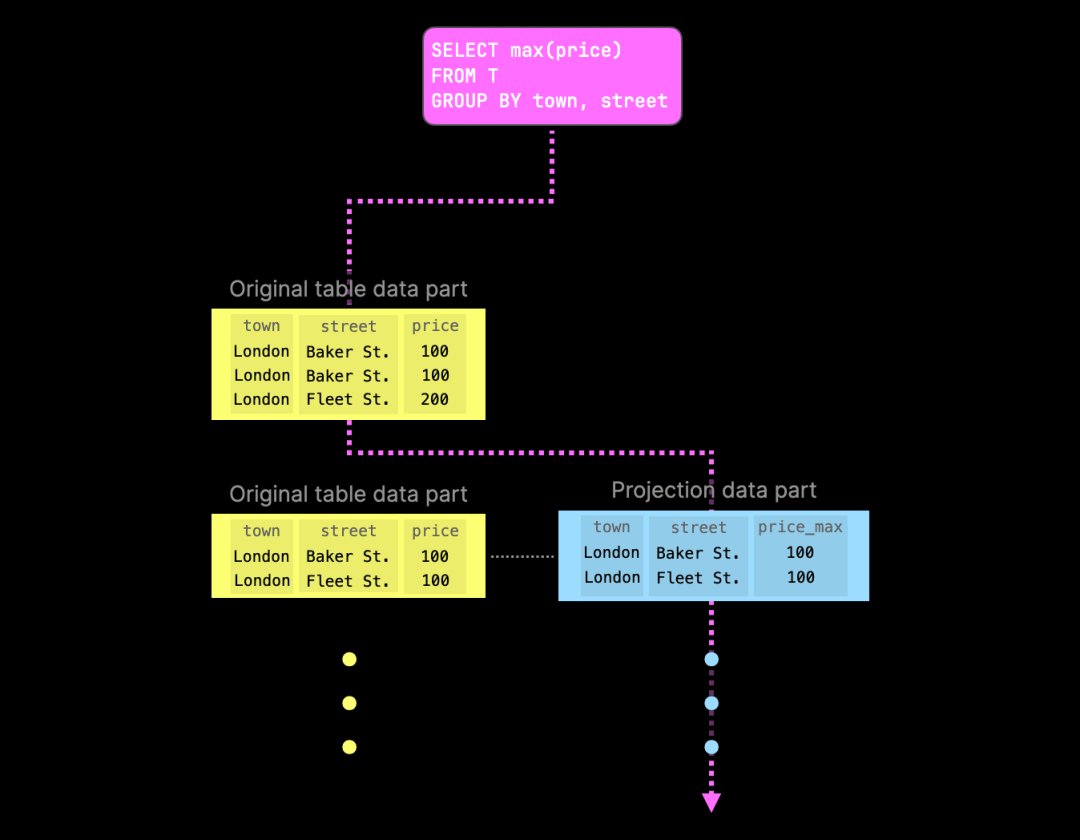
下图展示了一个更具体的例子,即计算英国售出物业按城镇和街道分组的最高价格的查询:
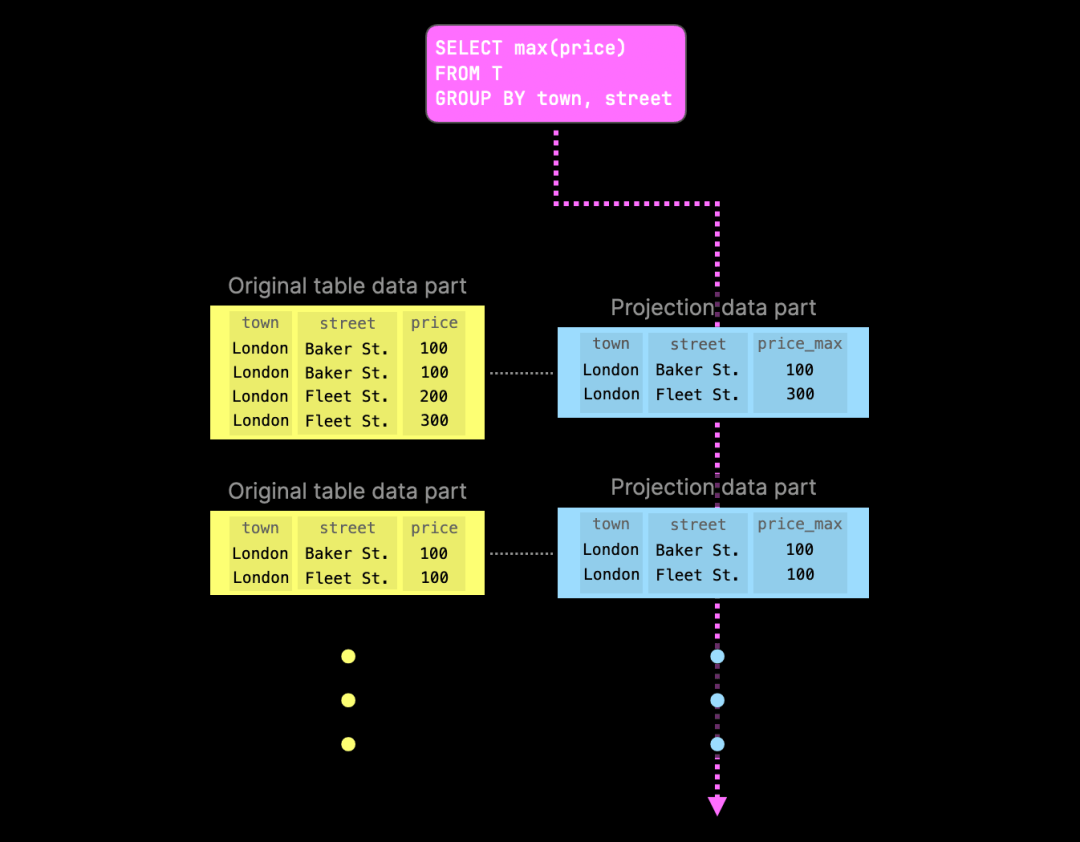
由于其中一个投影已经包含了预先计算的聚合值,ClickHouse 会尝试从相应的投影部分读取数据,以避免在查询时再次执行聚合。如果某一部分缺少对应的投影部分,查询将回退到原始数据部分。
但是,如果原始表中的数据由于复杂的数据部分后台合并发生了显著变化,该怎么办呢?
例如,假设表是使用 ClickHouse 的 ReplacingMergeTree 表引擎存储的。如果在合并过程中检测到同一行出现在多个输入部分中,系统只会保留最新的行版本(即最近插入的部分),并丢弃所有旧版本。
同样,如果表是使用 AggregatingMergeTree 表引擎存储的,合并操作可能会将基于主键值的相同行合并为一行,以更新部分聚合状态。
在 ClickHouse v24.8 之前,投影部分可能会默默地与主数据不同步,或者某些操作(如更新和删除)根本无法执行,因为数据库在表中存在投影时会自动抛出异常。
从 v24.8 开始,新的表级别设置 deduplicate_merge_projection_mode 控制原始表部分中复杂后台合并操作的行为。
删除变异是另一种部分合并操作的例子,它会删除原始表部分中的行。自 v24.7 起,我们还有一个设置来控制轻量删除所触发的删除变异行为:lightweight_mutation_projection_mode。
deduplicate_merge_projection_mode 和 lightweight_mutation_projection_mode 都有以下几种可能的取值:
-
throw: 抛出异常,防止投影部分不同步。
-
drop: 删除受影响的投影表部分,查询将回退到原始表部分替代这些投影部分。
-
rebuild: 重建受影响的投影部分,以确保与原始表部分的数据保持一致。
我们通过两个图示来演示 drop 模式的行为。第一个图示显示,通过运行变异合并操作,原始表数据部分中的一行被删除。为了防止投影部分数据不同步,相关联的投影表数据部分也会被删除:
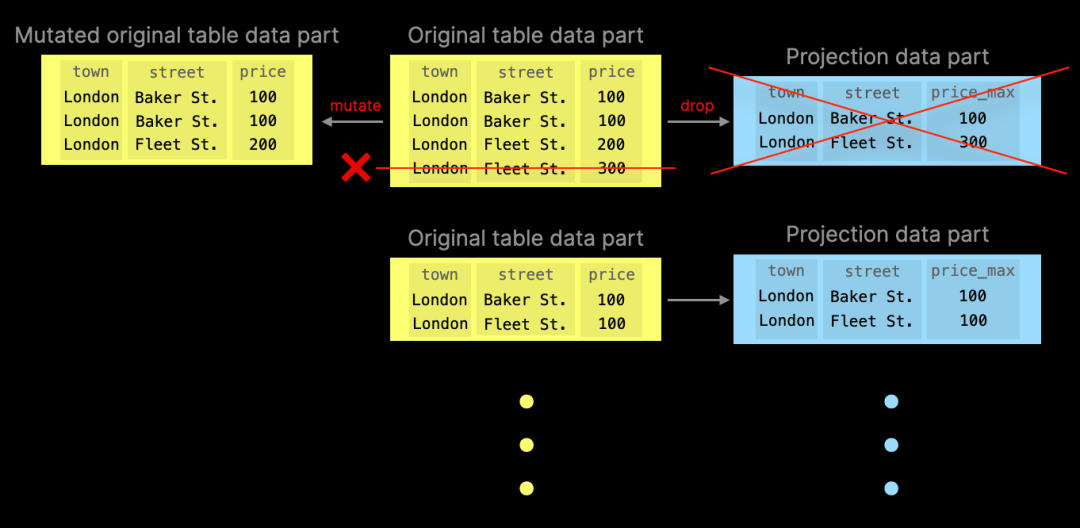
尽管速度稍慢,示例中的聚合查询仍然能够执行——如果找不到投影部分,查询会自动回退至原始表部分。然而,如果投影部分仍然存在,查询执行会优先使用投影部分而非原始表部分:
如果将 deduplicate_merge_projection_mode 设置为 rebuild,ClickHouse 会重建与修改后的原始表数据部分相关联的投影表数据部分:
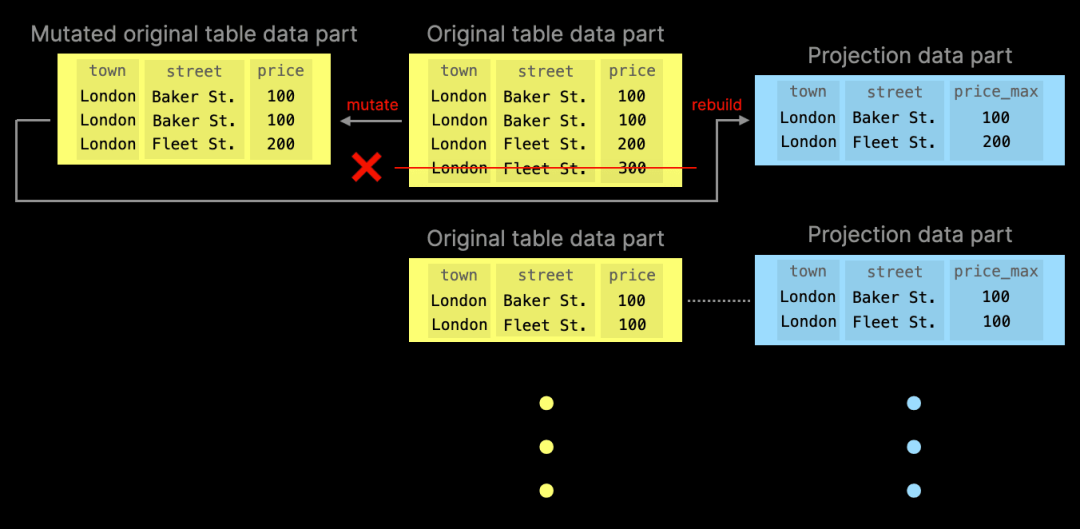
需要注意的是,这种行为相对于增量物化视图(incremental materialized views)有明显的优势。虽然增量物化视图与投影类似,但它仅在原始表中插入数据时进行同步。而在原始表数据发生更新、删除或替换时,物化视图会悄然失去同步。
时序表引擎
由 Vitaly Baranov 贡献
此版本引入了时序表引擎 (TimeSeries)。这个表引擎支持使用 ClickHouse 作为 Prometheus 的存储,通过远程写入协议 (remote-write) 进行数据存储。此外,Prometheus 还可以通过远程读取协议 (remote-read) 从 ClickHouse 中查询数据,如下图所示:

时序表引擎目前属于实验性功能,因此需要在服务器配置文件中启用 allow_experimental_time_series_table 属性:
config.d/allow_experimental_time_series.xml
<clickhouse>
<profiles>
<default>
<allow_experimental_time_series_table>1</allow_experimental_time_series_table>
</default>
</profiles>
</clickhouse>同时,还需要配置 ClickHouse 的远程写入和远程读取端点,以支持 Prometheus 连接:
config.d/prometheus.xml
<clickhouse>
<prometheus>
<port>9092</port>
<handlers>
<my_rule_1>
<url>/write</url>
<handler>
<type>remote_write</type>
<table>default.prometheus</table>
</handler>
</my_rule_1>
<my_rule_2>
<url>/read</url>
<handler>
<type>remote_read</type>
<table>default.prometheus</table>
</handler>
</my_rule_2>
</handlers>
</prometheus>
</clickhouse>启动 ClickHouse 后,日志中会显示如下内容:
2024.08.27 15:41:19.970465 [ 14489686 ] {} <Information> Application: Listening for Prometheus: http://[::1]:9092
...
2024.08.27 15:41:19.970523 [ 14489686 ] {} <Information> Application: Listening for Prometheus: http://127.0.0.1:9092接下来,使用 ClickHouse 客户端连接服务器并运行以下查询:
CREATE TABLE prometheus ENGINE=TimeSeries;运行该查询将会创建三个目标数据表:
-
data 表:用于存储与某个标识符关联的时间序列数据。
-
tags 表:存储每个指标名称与标签组合生成的标识符。
-
metrics 表:包含已收集的指标信息,包括类型和描述。
你可以通过以下查询查看这些表的名称:
SHOW TABLES
┌─name───────────────────────────────────────────────────┐
│ .inner_id.data.bcd5b4e6-01d3-45d1-ab27-bbe9de2bc74b │
│ .inner_id.metrics.bcd5b4e6-01d3-45d1-ab27-bbe9de2bc74b │
│ .inner_id.tags.bcd5b4e6-01d3-45d1-ab27-bbe9de2bc74b │
│ prometheus │
└────────────────────────────────────────────────────────┘接下来,我们将启动 Prometheus,并让其以自引用的方式收集自身的数据。配置文件如下:
prometheus.yml
global:
scrape_interval: 15s
external_labels:
monitor: 'codelab-monitor'
scrape_configs:
- job_name: 'prometheus'
scrape_interval: 5s
static_configs:
- targets: ['localhost:9090']
remote_write:
- url: "http://localhost:9092/write"
remote_read:
- url: "http://localhost:9092/read"需要重点关注的是 remote_write 和 remote_read 配置项,它们指向在 ClickHouse 服务器上运行的 HTTP 端点。下载并解压 Prometheus 后,运行以下命令即可:
./prometheus-2.54.0.darwin-amd64/prometheus --config prometheus.yml之后,你可以在 Prometheus 中查看这些指标,或使用 ClickHouse 的表函数进行查询。这些函数以 timeSeries 为前缀,并接受 TimeSeries 表名作为参数。第一个函数是 timeSeriesMetrics,用于列出所有指标:
SELECT *
FROM timeSeriesMetrics(prometheus)
LIMIT 3
FORMAT Vertical
Query id: 07f4cce2-ad47-45e1-b0e3-6903e474d76c
Row 1:
──────
metric_family_name: go_gc_cycles_automatic_gc_cycles_total
type: counter
unit:
help: Count of completed GC cycles generated by the Go runtime.
Row 2:
──────
metric_family_name: go_gc_cycles_forced_gc_cycles_total
type: counter
unit:
help: Count of completed GC cycles forced by the application.
Row 3:
──────
metric_family_name: go_gc_cycles_total_gc_cycles_total
type: counter
unit:
help: Count of all completed GC cycles.此外,还可以使用 timeSeriesData 和 timeSeriesTags,建议将这两个函数一起查询:
SELECT *
FROM timeSeriesData(prometheus) AS data
INNER JOIN timeSeriesTags(prometheus) AS tags ON tags.id = data.id
WHERE metric_name = 'prometheus_tsdb_head_chunks_created_total'
LIMIT 1
FORMAT Vertical
Row 1:
──────
id: a869dbe8-ba86-1416-47d3-c51cda7334b1
timestamp: 2024-08-27 15:54:46.655
value: 8935
tags.id: a869dbe8-ba86-1416-47d3-c51cda7334b1
metric_name: prometheus_tsdb_head_chunks_created_total
tags: {'instance':'localhost:9090','job':'prometheus','monitor':'codelab-monitor'}
min_time: 2024-08-27 13:46:05.725
max_time: 2024-08-27 16:00:26.649在未来的版本中,我们将实现 /query 端点,允许你直接在 ClickHouse 中执行 Prometheus 风格的查询。
连接功能的改进
每个 ClickHouse 版本都会包含连接功能的改进,ClickHouse v24.8 也不例外,提供了更多增强功能。
更多支持不等条件的连接类型
由 Lgbo-USTC 贡献
ClickHouse v24.5 版本中已引入 ON 子句中非相等条件的实验性支持。本次更新中,更多的连接类型(如 LEFT/RIGHT SEMI/ANTI/ANY JOIN)可以使用左表和右表列的不等条件。
对连接表执行 OPTIMIZE 查询,降低内存占用
由 Duc Canh Le 贡献
使用 Join 表引擎的 ClickHouse 表,通常会在内存中预先计算一个哈希表,以便在连接操作时直接使用右表数据。
在 ClickHouse v24.8 中,你可以对连接表运行 OPTIMIZE TABLE 语句,通过优化数据打包减少内存使用,最多可减少 30% 的内存占用。
全新的 Kafka 引擎
由 János Benjamin Antal 贡献
我们还引入了一个新的实验性 Kafka 引擎,该版本实现了 Kafka 消息的精准处理。
在现有引擎中,Kafka 偏移量同时存储在 Kafka 和 ClickHouse 中,因非原子提交导致重试时可能出现重复数据。
新版本中,偏移量由 ClickHouse Keeper 处理。如果插入失败,无论是网络问题还是服务器故障,都会重新插入同一数据块,确保数据一致性。
你可以通过以下设置启用新引擎:
CREATE TABLE ... ENGINE = Kafka(
'localhost:19092', 'topic', 'consumer', 'JSONEachRow')
SETTINGS
kafka_keeper_path = '/clickhouse/{database}/kafka',
kafka_replica_name = 'r1';征稿启示
面向社区长期正文,文章内容包括但不限于关于 ClickHouse 的技术研究、项目实践和创新做法等。建议行文风格干货输出&图文并茂。质量合格的文章将会发布在本公众号,优秀者也有机会推荐到 ClickHouse 官网。请将文章稿件的 WORD 版本发邮件至:Tracy.Wang@clickhouse.com

联系我们
手机号:13910395701
邮箱:Tracy.Wang@clickhouse.com
满足您所有的在线分析列式数据库管理需求