CurrentHashMap在jdk1.8之前使用的是分段锁,在jdk1.8中使用"CAS和synchronized"来保证线程安全。
jdk1.8之前的底层实现
CurrentHashMap在jdk1.8之前,通过Segment段来实现线程安全。
Segment 段
ConcurrentHashMap 和 HashMap 思路是差不多的,但是因为它支持并发操作,所以要复杂一些。在jdk1.8之前,整个 ConcurrentHashMap 由一个个 Segment 组成,Segment 是“部分”或 “分段”的意思,所以很多地方都会将其描述为分段锁。本文中我们就用“槽”来代表一个segment。Segment类是线程安全的(Segment类继承 ReentrantLock,具有加锁功能) ,通过继承ReentrantLock,使用ReentrantLock的lock方法来实现加锁。
static class Segment<K,V> extends ReentrantLock implements Serializable {
}简单理解就是,ConcurrentHashMap 是一个 Segment 数组,Segment 通过继承ReentrantLock 来进行加锁,所以每次加锁的操作锁住的是一个 Segment,每个Segment 内部维护一个小的哈希表,并且每个Segment 有自己的锁。操作只需锁住相关的段,从而提高并发度,只要保证每个 Segment 是线程安全的,也就实现了全局的线程安全。
每个 Segment 内部维护一个与 Hashtable 类似的数据结构(HashEntry<K,V>[] 数组),通常是一个数组+链表(在 JDK 1.8 之前)。当发生哈希冲突时,元素会以链表的形式存储在数组的同一个位置。
当线程需要删除或修改 Segment 中的数据时,ConcurrentHashMap首先需要获取该 Segment 的锁,即调用lock方法,这样可以确保同一时间只有一个线程能够修改 Segment 中的数据,对该 Segment 的数据操作是线程安全的,防止数据不一致的情况发生。
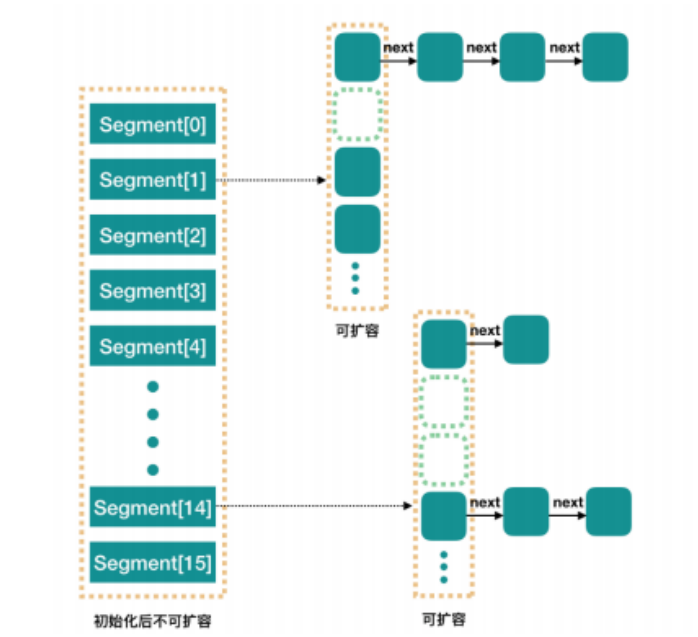
并行度(默认16)
concurrencyLevel:并行度,并行级别,并发数,Segment 数,默认是 16。
实际上我们可以在构造 ConcurrentHashMap 时通过构造函数参数自定义并行度。 例如 new ConcurrentHashMap<>(initialCapacity, loadFactor, concurrencyLevel) 中的 concurrencyLevel 参数。 默认情况下我们可以说 ConcurrentHashMap 有 16 个 Segment,所以理论上ConcurrentHashMap 默认最多可以同时支持 16 个线程并发写。这个并行度可以在初始化的时候设置为其他值,但是一旦初始化以后,它是不可以扩容的。再具体到每个Segment内部,其实每个 Segment 很像HashMap,不过它要保证线程安全,所以处理起来要麻烦些。
如何加锁
在 JDK 1.8 之前的 ConcurrentHashMap 中,每个 Segment 继承了 ReentrantLock,通过 lock() 和 unlock() 方法实现了对 Segment 的锁定和解锁。
static final class Segment<K,V> extends ReentrantLock implements Serializable {
// 存储在本Segment中的哈希表
transient volatile HashEntry<K,V>[] table;
// 获取键对应的值
V get(Object key, int hash) {
if (count != 0) { // 读取volatile变量
HashEntry<K,V> e = getFirst(hash);
while (e != null) {
if (e.hash == hash && key.equals(e.key)) {
return e.value;
}
e = e.next;
}
}
return null;
}
// 插入键值对
V put(K key, int hash, V value, boolean onlyIfAbsent) {
lock(); // 锁定Segment
try {
HashEntry<K,V>[] tab = table;
int index = (tab.length - 1) & hash;
HashEntry<K,V> first = tab[index];
for (HashEntry<K,V> e = first; e != null; e = e.next) {
K k;
if ((k = e.key) == key || (e.hash == hash && key.equals(k))) {
V oldValue = e.value;
if (!onlyIfAbsent) {
e.value = value;
}
return oldValue;
}
}
// 将新值作为第一个条目添加
tab[index] = new HashEntry<K,V>(hash, key, value, first);
return null;
} finally {
unlock(); // 解锁Segment
}
}
}jdk1.8的底层实现
在jdk1.8中,ConcurrentHashMap 采用“CAS+synchronized”的机制来保证线程安全。
CAS的具体使用细节
- 当某个桶(结点)为空时,使用CAS操作往桶(结点)中插入新值。
- 当桶数组(table)还没有初始化时,会使用 CAS 操作来保证只有一个线程能够成功地初始化这个数组
synchronized的具体使用细节
当桶(结点)不为空,存在元素时,即桶(结点)为链表或者红黑树时,就会给桶加synchronized锁,保证同时只有一个线程来操作桶。这些操作包括添加、修改或者删除桶中的元素
put方法源码
/**
* Maps the specified key to the specified value in this table.
* Neither the key nor the value can be null.
*
* <p>The value can be retrieved by calling the {@code get} method
* with a key that is equal to the original key.
*
* @param key key with which the specified value is to be associated
* @param value value to be associated with the specified key
* @return the previous value associated with {@code key}, or
* {@code null} if there was no mapping for {@code key}
* @throws NullPointerException if the specified key or value is null
*/
public V put(K key, V value) {
return putVal(key, value, false);
}
final V putVal(K key, V value, boolean onlyIfAbsent) {
// 如果 key 或 value 为 null,则抛出空指针异常
if (key == null || value == null) throw new NullPointerException();
// 计算 key 的 hash 值,并通过 spread 函数进行高位混合,减少冲突
int hash = spread(key.hashCode());
// 记录链表或树的节点数
int binCount = 0;
// 无限循环,用于处理并发下的重试逻辑
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
// 如果 table 还未初始化,则初始化它
if (tab == null || (n = tab.length) == 0)
tab = initTable();
// 如果计算出的桶位为空(即当前桶没有节点),则通过 CAS 操作直接插入新节点
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
if (casTabAt(tab, i, null, new Node<K,V>(hash, key, value, null)))
break; // 无需锁定即可插入到空的桶中,插入成功后跳出循环
}
// 如果该桶正在进行扩容操作(MOVED 表示桶正在被转移),则协助扩容
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
else {
V oldVal = null;
// 如果上述条件都不满足,则桶中已经有节点,需要进行锁定以确保线程安全
synchronized (f) {
// 再次检查桶是否与预期一致,确保在获取锁前桶未被修改
if (tabAt(tab, i) == f) {
// 如果桶中的节点是普通链表节点
if (fh >= 0) {
binCount = 1;
// 遍历链表
for (Node<K,V> e = f;; ++binCount) {
K ek;
// 如果找到 key 相同的节点,则更新值
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value; // 更新节点的值
break;
}
Node<K,V> pred = e;
// 如果到达链表末尾,则插入新节点
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key, value, null);
break;
}
}
}
// 如果桶中的节点是红黑树
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
// 在红黑树中插入新节点或更新已有节点的值
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key, value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
// 如果链表或树中已有节点数超过阈值,则转换为红黑树
if (binCount != 0) {
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
// 如果找到了旧值,则返回该值
if (oldVal != null)
return oldVal;
break; // 插入新节点后跳出循环
}
}
}
// 更新计数并检查是否需要触发扩容
addCount(1L, binCount);
return null;
}remove方法源码
public V remove(Object key) {
return replaceNode(key, null, null);
}
/* Implementation for the four public remove/replace methods: Replaces node value * with v, conditional upon match of cv if non-null. If resulting value is null, * delete.
*/
final V replaceNode(Object key, V value, Object cv) {
// 计算键的哈希值并扩展哈希值,以减少哈希冲突
int hash = spread(key.hashCode());
// 无限循环,用于重试机制,以应对并发修改等情况
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
// 如果哈希表为空,或哈希表的长度为0,或计算的槽位为空
if (tab == null || (n = tab.length) == 0 ||
(f = tabAt(tab, i = (n - 1) & hash)) == null)
break; // 直接退出,无需替换
else if ((fh = f.hash) == MOVED)
// 如果当前槽位正在进行转移操作,则协助数据迁移
tab = helpTransfer(tab, f);
else {
V oldVal = null;
boolean validated = false;
// 对当前槽位的头节点加锁,防止其他线程修改
synchronized (f) {
// 再次确认当前槽位的头节点是否与之前获取的节点相同
if (tabAt(tab, i) == f) {
if (fh >= 0) { // 如果是普通链表节点
validated = true;
// 遍历链表查找对应的键
for (Node<K,V> e = f, pred = null;;) {
K ek;
// 找到匹配的键
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
V ev = e.val;
// 如果当前值匹配预期值(cv),则替换或删除
if (cv == null || cv == ev ||
(ev != null && cv.equals(ev))) {
oldVal = ev;
if (value != null) // 替换值
e.val = value;
else if (pred != null) // 删除节点
pred.next = e.next;
else
setTabAt(tab, i, e.next); // 删除头节点
}
break;
}
pred = e; // 更新前驱节点
if ((e = e.next) == null) // 遍历到链表末尾
break;
}
}
else if (f instanceof TreeBin) { // 如果是红黑树节点
validated = true;
TreeBin<K,V> t = (TreeBin<K,V>)f;
TreeNode<K,V> r, p;
// 查找红黑树中的节点
if ((r = t.root) != null &&
(p = r.findTreeNode(hash, key, null)) != null) {
V pv = p.val;
// 如果当前值匹配预期值(cv),则替换或删除
if (cv == null || cv == pv ||
(pv != null && cv.equals(pv))) {
oldVal = pv;
if (value != null) // 替换值
p.val = value;
else if (t.removeTreeNode(p)) // 删除节点
setTabAt(tab, i, untreeify(t.first)); // 取消树化
}
}
}
}
}
// 如果操作已经成功验证(节点锁定成功)
if (validated) {
if (oldVal != null) { // 如果找到并修改了节点
if (value == null) // 如果是删除操作
addCount(-1L, -1); // 更新大小计数器
return oldVal; // 返回旧值
}
break; // 如果未找到对应的节点或未修改,退出循环
}
}
}
return null; // 未找到或替换的节点
}












![[000-01-008].第05节:OpenFeign高级特性-超时控制](https://i-blog.csdnimg.cn/blog_migrate/b0a2200350d4a6bae96c50b2038c2c21.png)




