微信公众号:EW Frontier QQ交流群:554073254

摘要
一种基于高阶广义奇异值分解的多声源方位估计方法本文提出了一种有效的宽带声源波达方向(DOA)估计方法。所提出的框架提供了一种有效的方法来构建一个宽带互相关矩阵从多个窄带互相关矩阵的所有频率箱。此外,该方法还受到相干信号子空间技术的启发,进一步改进了线性变换过程,利用接收信号与其自身在不同频率上的互相关矩阵,沿着对该互相关矩阵进行高阶广义奇异值分解,不再需要任何DOA初步估计过程。宽带DOA估计采用任何基于子空间的技术估计窄带DOA,但使用建议的宽带相关性,而不是窄带相关矩阵。这意味着,该框架使最近的窄带子空间方法的前沿研究直接估计宽带源的DOA,从而降低计算复杂度,并促进估计算法。最后通过实例验证了该方法的适用性和有效性,结果表明,在一定信噪比范围内,融合方法的性能优于其他方法,且传感器数目较少,适合于实际应用。
引言
一种基于高阶广义奇异值分解的多声源方位估计方法本文提出了一种有效的宽带声源波达方向(DOA)估计方法。所提出的框架提供了一种有效的方法来构建一个宽带互相关矩阵从多个窄带互相关矩阵的所有频率箱。此外,该框架受到相干信号子空间技术的启发,进一步改进了线性变换过程,新过程不再需要任何波达方向初步估计过程,而是利用接收信号与其自身在不同频率上的唯一互相关矩阵,沿着该唯一矩阵阵列的高阶广义奇异值分解。宽带DOA估计采用任何基于子空间的技术估计窄带DOA,但使用建议的宽带相关性,而不是窄带相关矩阵。这意味着,该框架使最近的窄带子空间方法的前沿研究直接估计宽带源的DOA,从而降低计算复杂度,并促进估计算法。最后通过实例验证了该方法的适用性和有效性,结果表明,在一定信噪比范围内,融合方法的性能优于其他方法,且传感器数目较少,适合于实际应用。在过去的几十年中,声源定位的基本能力受到了广泛的关注,并已成为导航系统的重要组成部分[1,2]。波达方向(DOA)估计尤其在导航系统中起着关键作用,用于广泛应用中的源探测,包括声学信号处理[3-8]。已经提出了几种方法作为估计DOA的潜在方式。例如,基于到达时间差的DOA估计是最常用的方法之一,其被广泛称为广义互相关相位变换(GCC-PHAT)[9]。除了这种方法,一个低的计算要求,使它有吸引力的实际应用,然而,主要的缺点是它的低鲁棒性在噪声和多径环境。另一种相关方法是采用盲源分离中的独立分量分析(伊卡)[10,11]。伊卡通过测量与高斯分布的偏差来搜索独立分量,例如负熵或峰度的最大化。通过使用针对所有频率仓的分离的分量来容易地估计DOA,但是应当注意的是,这种方法的估计精度对非高斯性度量高度敏感。
在估计窄带DOA的替代方法中,已经提出了子空间方法以努力提高估计性能。最突出的方法观察信号和噪声子空间以获得更鲁棒的结果,例如多信号分类(MUSIC)[12]、通过旋转不变技术(ESPRIT)[13]估计信号参数以及传播算子方法[14,15],这些方法经常用于一维(1D)DOA估计,沿着传感器的均匀线性阵列。在二维(2D)DOA估计的情况下,需要传感器阵列的新的几何结构,并且先前发现L形阵列的结构对于估计2D DOA是相当有效的[16]。此外,L形阵列允许简单的实施,因为它由在每个天线的一端正交连接的两个ULA组成。由于这些原因,L形阵列被广泛应用于二维DOA估计方法[17-26],并且可以在过去的研究中找到其实际应用[27,28]。虽然窄带子空间方法可能无法直接估计宽带DOA,但解决这个问题的一种可能的方法是在每个时间频率集中使用窄带子空间方法,然后通过将窄带DOA结果插值到所有频点来估计宽带DOA结果[29,30]。应再次注意,上述解决方案中遇到的密集计算成本可能受到实际考虑的限制。
提出了几种方法来解决估计宽带DOA的问题,例如,非相干MUSIC(IMUSIC)是估计宽带DOA的最简单方法之一[31]。IMUSIC算法分为两个步骤:首先,在每个时间频率上构造噪声子空间模型.然后,通过最小化导向矢量与所有频率点的噪声子空间之间的正交关系的范数来获得宽带DOA。虽然IMUSIC的精度性能被证明是一种有效的方法来估计多个宽带信号的DOA在高信噪比(SNR)区域,在任何频率的噪声子空间的一个小的失真可以影响整个DOA的结果。最近人们做了许多尝试来克服这个问题。例如,提出了频率子空间正交性(TOFS)测试来克服这一困难[32],但由小失真引起的性能下降仍然具有挑战性。另一个相关的方法被称为投影子空间正交性测试(TOPS)[33]。TOPS算法通过构造一个参考频率的信号子空间,然后在所有频率点上测量前一个参考频率的信号子空间与噪声子空间的正交性来估计DOA。仿真结果表明,在中等信噪比范围内,TOPS算法能够获得比IMUSIC算法更高的估计精度,但仍存在不希望出现的伪峰。最近提出了TOPS的修订和大幅改进版本,以减少这些假峰[34,35]。显然,与经典TOPS相比,计算复杂度显著增加。
宽带DOA估计的另一个值得注意的方法是相干信号子空间方法(CSS)[36,37]。CSS具体地通过线性变换过程将每个时间频率的接收信号的相关矩阵聚焦为与一个聚焦频率相关联的单个矩阵,该单个矩阵被称为通用相关。宽带波达方向估计通过应用任何窄带子空间方法的通用相关矩阵上的一个单一的计划。除了CSS [38-40]的变换过程之外,在估计宽带波达方向之前还需要进行波达方向初步估计的过程。因此,一个共同的缺点是清楚地认识到作为DOA初步估计的要求,这意味着任何劣质的启动可能会导致有偏的估计。根据文献[31- 33,41],CSS表现出比TOPS等其他方法性能不足;这是因为CSS中的变换过程的解决方案仅关注时间频率和聚焦频率之间的子空间;据作者所知,这意味着跨越所有频率仓的变换矩阵的基本分量可以表现出不同的核心分量,当某个频率下的窄带波达方向结果与真实波达方向不够接近时,这一点就很明显了。单个分量的失真会影响整个波达方向的估计结果。因此,即使在该频率处接收到的信号中存在的功率非常弱,解也必须表现出精确的分量;换句话说,必须在所有频率仓而不是不同频率对上聚焦。
因此,本文的目的是研究一种更有效的方法来估计宽带二维DOA。我们认为宽带源的声源,如人类的语音和音乐的声音。为了估计宽带波达方向,我们解决了将多个窄带互相关矩阵转换为宽带互相关矩阵的问题。此外,我们的研究受到CSS计算模型的启发,进一步改进了线性变换过程[36 - 40]。由于CSS的变换过程只集中在当前和参考频率之间的子空间,如前所述,我们提出了一个新的变换过程,同时和有效地集中所有频率箱。高阶广义奇异值分解(HOGSVD)首先用于解决这个重要问题[42]。通过采用新的独特的互相关矩阵的阵列的HOGSVD,其中在行和列位置中的元素是在两个不同的频率上的接收信号与其自身之间的样本互相关矩阵,新的变换过程不再需要任何DOA初步估计的过程。最后,宽带互相关矩阵的构造通过所提出的变换过程,和宽带DOA估计可以采用任何基于子空间的技术来估计窄带DOA,但使用该宽带相关矩阵代替窄带相关矩阵。因此,该框架使前沿研究在最近的窄带子空间方法直接估计宽带源的DOA,这导致减少计算复杂度和促进估计算法。通过二维MUSIC和L形阵ESPRIT等实际算例,验证了该方法的适用性和有效性。
本文其余部分的组织结构如下。第2节介绍了阵列信号模型、基本假设和问题公式,用于将所有频率点的窄带样本互相关矩阵转换为单个矩阵,该矩阵被称为宽带互相关矩阵。第3.1节介绍了新变换过程的描述,第3.2节介绍了通过HOGSVD的有效解。第3.3节描述了通过将所提出的变换过程沿着在最近的窄带子空间方法中估计DOA的方案相结合来估计宽带DOA的所提出的框架,并且在第3.3.1节和第3.3.2节中给出了其实际示例。将仿真结果和试验结果与第4、5节中的几种现有方法进行了比较。最后,第六章对本文进行了总结。
系统模型

仿真验证
在本节中,使用所提出的框架的融合方法的性能在以下四种类型的场景中被证明:(1)所选择的方法和所提出的方法相对于源类型的性能,(2)相对于麦克风元件的数量的性能,(3)考虑x和z子阵列角度的自动配对的性能,(4)混响环境下的性能。场景1、场景2和场景4必须通过使用等式(2)中的数据模型来分别找到x和z子阵列角度的DOA。而场景3必须通过使用等式(1)中的数据模型在考虑自动配对的情况下同时找到x和z子阵列角度的DOA。我们提供了与以下方法相比所提出方法的模拟测试:IMUSIC [31],TOFS [32],TOPS [33],Squared-TOPS [34],WS-TOPS [35]。请注意,在这些测试中排除了基于CSS的方法;这是因为DOA初步估计过程引起的非预期偏差应考虑到文献[31- 33,41]中讨论的其他候选方法。
场景1:关于源类型的性能

图2和图3显示了所选方法和所提出的方法在SNR范围内的RMSE和SD方面的性能比较。所提出的方法是等式(45)中的修改的MUSIC和等式(50)-(52)中的ESPRIT。每个子阵列的麦克风元件的数量是六个,并且三个不相关的源角度(φk,θk)被放置在(41.41 °,60 °)、(60 °,45 °)和(75.52 °,30 °)处。在图2a和图3a中,源是人类语音。图2b和3b中的源是在钢琴上记录的声音,包括各种单色音符并且包含高达48 kHz的采样频率范围。请注意,并非所有信号源都是平稳信号。图2和图3中的结果表明,与具有可接受的SNR范围的其他候选方法相比,所提出的具有ESPRIT的方法可以有效地处理这两种源类型。随后,仔细观察图2和图3中的40 dB SNR是有趣的,其中IMUSIC、TOFS、所提出的具有MUSIC和ESPRIT的方法显示出非常低的RMSE,这可以证明良好的DOA估计。当SNR降低到25 dB时,IMUSIC和TOFS开始表现出更差的RMSE质量,这比所提出的方法高得多,并且可以清楚地看到,当SNR降低到10 dB时,所有测试的方法都显著占优势,但是与使用其他方法相比,所提出的具有ESPRIT的方法仍然与更令人满意的结果相关联。应该提到的是,IMUSIC和TOFS要求传感器元件的数量远高于源的数量,以获得相当好的结果[31- 33,41]。因此,图2和图3中的仿真结果能够提供证据,表明当入射源是宽带和非平稳信号时,所提出的方法在估计方面比其他候选方法表现得更好。虽然MUSIC方法的性能也受噪声的影响,但总体性能仍优于其他方法。
场景2:相对于麦克风元件数量的性能
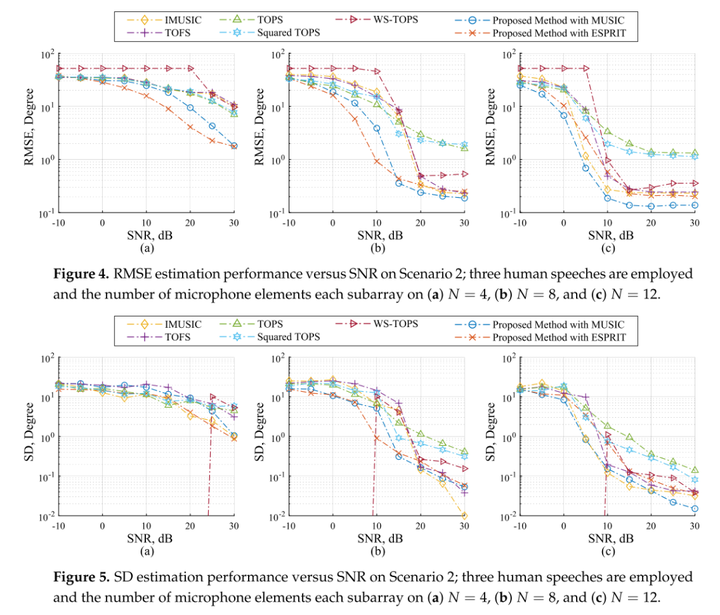
图4和图5示出了所选择的方法和所提出的方法在SNR范围内的RMSE和SD方面的性能比较。三个不相关的源角度是人类的语音,并且如先前使用的那样放置。首先,让我们从图4c和图5c中的十二个麦克风的情况开始。IMUSIC、TOFS和WS-TOPS在15至30 dB的SNR范围内表现出非常低的RMSE水平;这是因为它们的性能显著依赖于传感器元件的数量,而不是源的数量[31- 33,41]。同样,所提出的方法与MUSIC和ESPRIT也表现出非常低的RMSE,这可能意味着所提出的方法,IMUSIC,TOFS和WS-TOPS的性能是特别有效的宽带DOA估计。然而,为了提供更实际的应用,应当考虑麦克风元件的数量少。在每个子阵列中有八个麦克风的情况下,所选方法的性能由麦克风元件的数量决定,如图4 b和图5 b所示。此外,当采用如图4a和图5a所示的四个麦克风时,所选方法的性能显著降低。相关的原因是所选方法的空间谱中出现了不希望的假峰,这是由噪声的扰动引起的;当噪声在某个频率处的功率高于或大于源功率时,在该频率处噪声子空间和搜索空间之间的正交性可能不足以防止假警报峰值[41]。相反,所提出的方法的RMSE性能也占主导地位,但低于其他方法,通过展示子空间的所有频率箱同时如第3节所示。因此,所提出的方法提供了比其他方法更好的RMSE性能,这意味着可以放松麦克风元件和源的数量之间的依赖性。这种实质性的能力对于许多实际应用更有意义。
场景3:考虑自动配对的性能
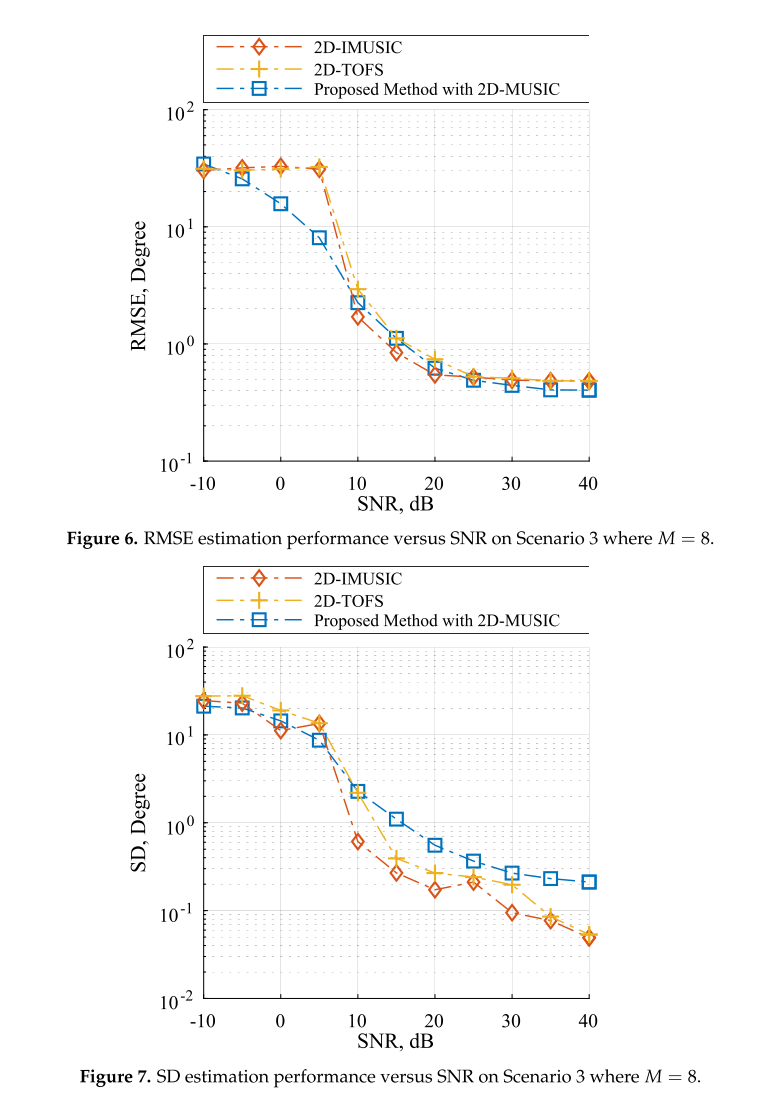
该场景同时估计x和z子阵列角度的DOA,同时考虑自动配对并遵循等式(1)中的数据模型。如图1所示的由两个ULA组成的L形阵列结构,一些研究工作通过对每个子阵执行1D DOA估计来分别估计x和z子阵角度的DOA [17-26]。当利用一个以上的源,这些算法需要一个额外的角度对匹配过程来映射两个独立的子阵列角度之间的关系。例如,通过在样本互协方差矩阵[52]中重新排列ax(φk,f)与z子阵列的阵列流形的固定右侧的对齐来找到相应的角度对。应当注意,配对过程可能导致由配对错误引起的性能降级。为了在没有配对过程的情况下实现自动配对,我们选择等式(44)中的修改的2D-MUSIC作为在这种情况下提出的方法。此外,TOPS、Squared-TOPS、WS-TOPS在这些测试中被排除,因为这些方法仅支持RISK模型。注意,在2D-IMUSIC、2D-TOFS和2D-TOFS上采用了2D峰值查找算法。所提出的方法。图6和图7示出了2D-IMUSIC、2D-TOFS和所提出的方法在SNR范围内的RMSE和SD方面的性能比较,其中包括所有子阵列的麦克风元件的数量为8个,三个不相关的源角度是人类语音,并且如先前使用的那样放置。图6表明,当SNR增加到10 dB以上时,所提出的2D-MUSIC方法表现出与2D-IMUSIC和2D-TOFS非常相似的总体性能;然而,所提出的方法的计算负担可以显著低于其他方法,第4.5节将进一步揭示这一点。
场景4:混响环境下的性能
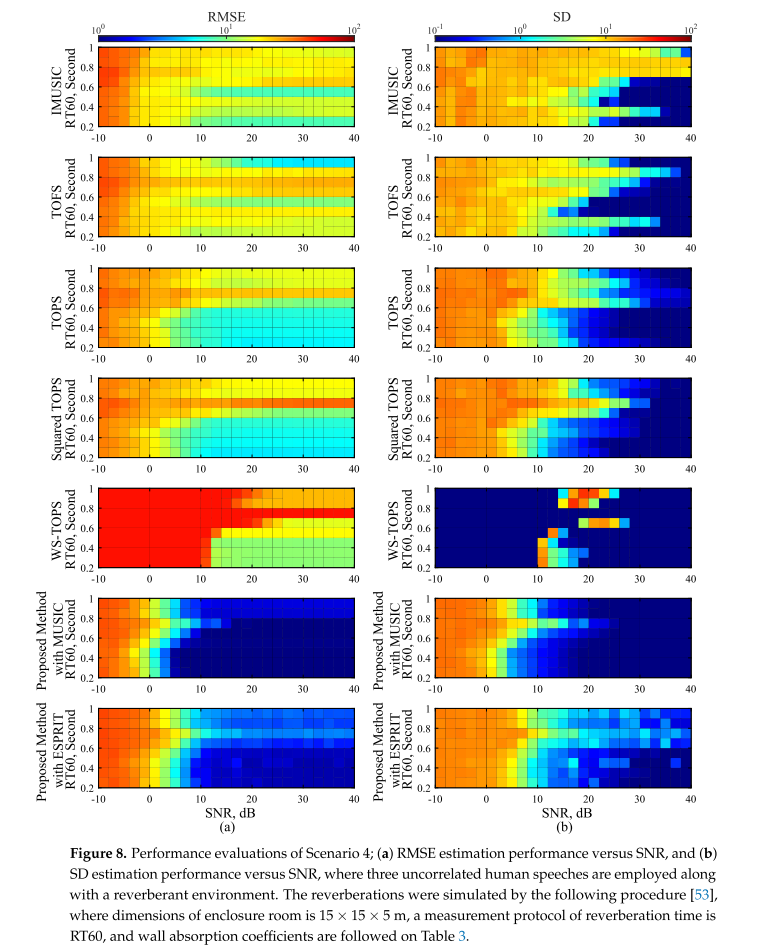
在这种情况下,我们比较了所提出的方法的RMSE和SD性能的混响时间方面的其他方法。该场景通过使用等式(2)中的数据模型来分别估计x和z子阵列角度的DOA,而不考虑自动配对。在这种情况下提出的方法是等式(45)中的修改的MUSIC和等式(50)-(52)上的ESPRIT。通过以下程序[53]模拟混响,其模拟壁吸收系数如表3所示,其中封闭室的尺寸为15 × 15 × 5 m,混响时间的测量协议为RT 60,混响时间为200至1000 ms。以与先前使用的相同方式使用三个不相关的源角度,并且每个子阵列中的麦克风元件的数量是12个。图8示出了所选择的方法和所提出的方法的性能比较,其中图8a上的曲线图的颜色表示RMSE,而图8b上的曲线图的颜色表示SD估计性能。垂直轴表示为混响时间,水平轴表示为SNR的范围。图8中的仿真结果表明,混响对所选择的方法和所提出的方法的RMSE和SD性能都有很大的影响,并且在高噪声水平和长混响时间下性能下降得更明显。由于混响时间正在减少,所有选定的方法开始证明低RMSE。这意味着在实际应用中应该深入考虑混响鲁棒性和信噪比之间的权衡,例如,应用混响抵消技术或噪声抵消技术来提供更可靠的RMSE和SD估计性能。然而,所提出的方法,在很大程度上优于其他方法的混响时间指数和SNR水平范围在10和40 dB之间,而不考虑权衡。这可以支持所提出的方法的性能可以特别有效地用于混响环境下的宽带DOA估计。
计算复杂度
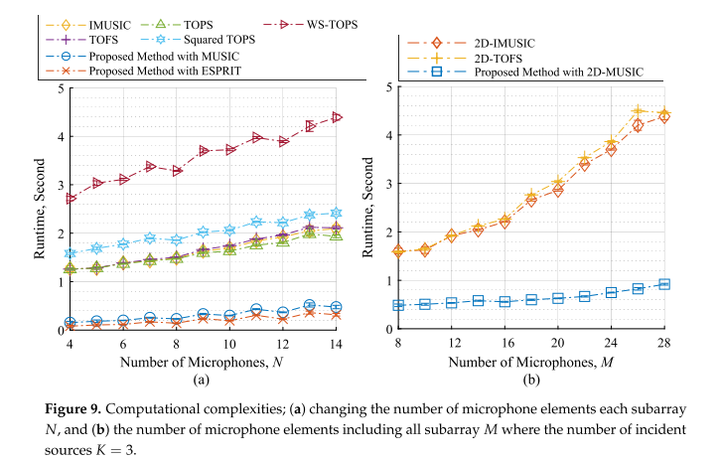
所提出的方法的计算复杂度进行了评估,在一个稳定的环境下使用的执行时间测量。我们提供了与以下情况相比的计算复杂度:(1)分别计算x和z子阵列角度的波达方向,如图9a所示,以及(2)同时计算两个子阵列角度的波达方向,如图9 b所示。注意,峰值搜索算法的计算负担在本研究中是相关的,其中每个子阵列中的搜索角度的数量是180。从图9中可以明显看出,其他方法的计算时间呈现出比所提出的方法更高的增长率。这是因为峰值搜索算法执行时间可能很高,并且几乎所有选择的方法都需要通过测试所有频率仓的窄带样本互相关矩阵的子空间和搜索空间的正交性来进行密集计算,这导致高计算成本。相反,所提出的方法将跨所有频率仓的所有窄带样本互相关矩阵变换成如等式(33)-(35)所示的单个矩阵,并且该矩阵包含跨所有频率仓的源互相关矩阵的有用信息,如1 P ∑ Pi =1 S{ fi,fi};换句话说,子空间和搜索空间的正交性测试可以通过使用等式(33)-(35)中的宽带互相关矩阵而不是所有频率仓的窄带样本互相关矩阵来完成。因此,所提出的方法的计算复杂度显著低于其他方法,这由图9中的测试结果证实。
实验结论
在本节中,进行了实验以检验所提出的方法的性能。实验参数的选择与前面的模拟相同,除了以下内容:我们使用人类说话者作为具有随机句子的原始语音的源。连续记录20次,每次记录信号长度约为1 min,被分割为3 s的时段。传声器的结构如图1和图10所示,传声器及其录音装置的规格如表4所示。实验在室内会议室进行,其尺寸如图11所示,正常情况下会议室声压级为46.6dBA,根据RT60估算的混响时间为219ms。
考虑了两种情况:(1)分别估计x和z子阵角度的DOA,以及(2)在考虑自动配对的情况下同时估计x和z子阵角度的DOA。在实验1的情况下,所提出的方法是公式(45)中的修改的MUSIC和公式(50)-(52)中的ESPRIT,与以下方法进行比较:IMUSIC [31],TOFS [32],TOPS [33],Squared-TOPS [34],WS-TOPS [35]。在实验2的情况下,与2D-IMUSIC [31]和2D-TOFS [32]相比,所提出的方法是等式(44)中的修改的2D-MUSIC。

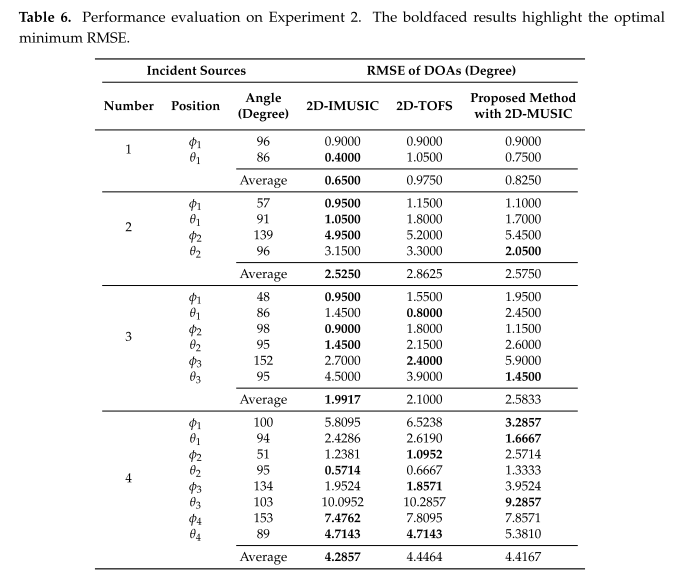
表5和6显示了所选方法和所提出的方法在源数目范围内的RMSE方面的性能比较,其中表5是针对实验1,表6是针对实验2。粗体结果突出显示每个问题中的最优最小RMSE。如表5所示,当使用单个源时,IMUSIC的性能表现出最低的RMSE,但包括所提出的方法在内的其他方法的性能在可接受的误差范围内也表现出类似的低RMSE。当执行两个源时,TOPS,Squared-TOPS和WS-TOPS的性能直接占主导地位,而IMUSIC,TOFS和所提出的方法略占主导地位,但仍然保持足够好的性能。当入射源增加到三个时,我们清楚地看到,IMUSIC、TOFS、TOPS、Squared-TOPS和WS-TOPS的性能显著地受入射源的数量支配,因为这些方法需要传感器元件的数量远远高于源的数量以实现合理的良好结果,这可以通过参考第4节和图4和图5中的仿真结果来验证。然而,所提出的方法能够有效地估计三个源的DOA,并且优于所选择的方法。原因是所提出的方法同时关注所有频率仓上的子空间,而不是单独关注每个频带,这在第3.2节中陈述。在表6中的实验2的情况下,实验结果表明,所提出的具有2D-MUSIC的方法表现出与2D-IMUSIC和2D-TOFS极其相似的总体性能。如在第4.5节中已经陈述的,所提出的方法的计算复杂度肯定低于2D-IMUSIC和2D-TOFS,因为这些方法检查子空间的正交性和针对所有频点的窄带样本互相关矩阵的搜索空间,导致非常高的计算要求。所提出的方法通过使用等式(33)中的宽带样本互相关矩阵而不是使用用于所有频率仓的窄带样本互相关矩阵的子空间来测试子空间和搜索空间的正交性,但是它足以表现出显著的效果以及使用用于所有频率仓的窄带样本互相关矩阵的子空间。最后,从表5和表6的实验结果能够提供证据,所提出的方法具有更好的估计性能比其他方法的事件源的数量。
总结
提出了一种有效的宽带声源DOA估计方法。通过同时关注所有频率仓的信号子空间而不是如基于CSS的方法所做的时间和参考频率的配对,成功地解决了将用于所有频率仓的多个窄带互相关矩阵变换成宽带互相关矩阵的问题。通过对新的互相关矩阵阵列进行HOGSVD,给出了这个问题的一种新的解决方案,其中行和列位置中的元素是接收信号与其自身在两个不同频率上的样本互相关矩阵。理论分析表明,该变换方法在适当的约束条件下可获得最优解,且无需进行DOA初步估计。随后,我们提供了一种替代方案来构建宽带互相关矩阵通过所提出的变换过程,和宽带波达方向估计很容易使用这个宽带矩阵沿着与单一的方案估计波达方向在任何窄带子空间方法。本文的一个主要贡献是,所提出的框架,使前沿研究在最近的窄带子空间方法直接估计的宽带源的DOA,这导致在降低计算复杂度和方便的估计算法。我们还进行了几个例子,使用所提出的框架,如2D-MUSIC,MUSIC,和ESPRIT方法集成的L形麦克风阵列。此外,仿真和实验结果表明,使用该框架的融合方法具有良好的融合效果与其它宽带DOA估计方法相比,该方法在信噪比范围内,在传感器数量少、噪声和混响条件下,具有更好的估计性能。我们相信,该方法是一种有效的宽带DOA估计方法,不仅可以提高宽带DOA估计的声学信号处理,而且可以在其他可能的相关领域。










![[linux 驱动]i2c总线设备驱动详解与实战](https://img-blog.csdnimg.cn/img_convert/8a8d0aa018cb0aa360615a54448e9300.png)