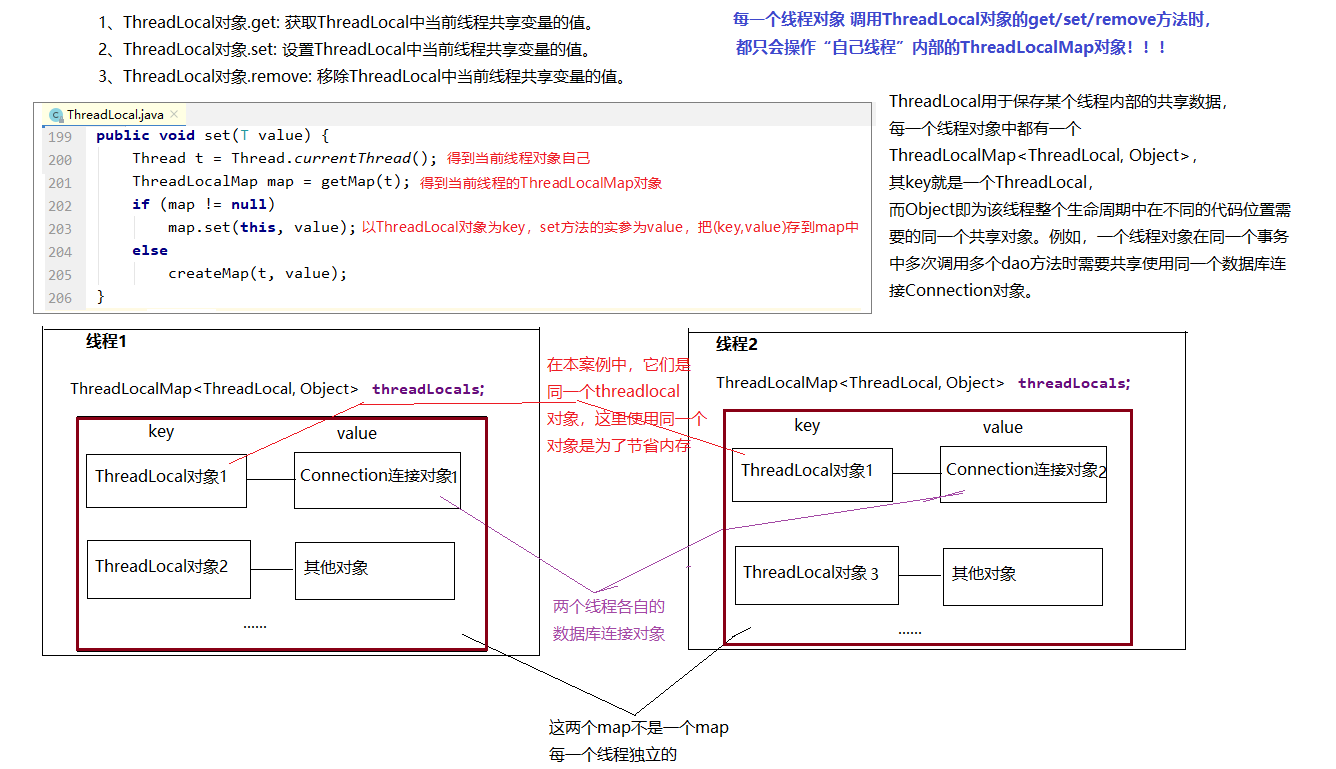
- 动手学习RAG: 向量模型
- 动手学习RAG:迟交互模型colbert微调实践 bge-m3
1. 环境准备
pip install open-retrievals
2. 使用M3E模型
from retrievals import AutoModelForEmbedding
embedder = AutoModelForEmbedding.from_pretrained('moka-ai/m3e-base', pooling_method='mean')
embedder

sentences = [
'* Moka 此文本嵌入模型由 MokaAI 训练并开源,训练脚本使用 uniem',
'* Massive 此文本嵌入模型通过**千万级**的中文句对数据集进行训练',
'* Mixed 此文本嵌入模型支持中英双语的同质文本相似度计算,异质文本检索等功能,未来还会支持代码检索,ALL in one'
]
embeddings = embedder.encode(sentences)
for sentence, embedding in zip(sentences, embeddings):
print("Sentence:", sentence)
print("Embedding:", embedding)
print("")

3. deepspeed 微调m3e模型
数据仍然采用之前介绍的t2-ranking数据集
- deepspeed配置保存为
ds_zero2_no_offload.json. 不过虽然设置了zero2,这里我只用了一张卡.- 关于deepspeed的分布式设置,可参考Tranformer分布式特辑
{
"fp16": {
"enabled": "auto",
"loss_scale": 0,
"loss_scale_window": 100,
"initial_scale_power": 16,
"hysteresis": 2,
"min_loss_scale": 1e-10
},
"zero_optimization": {
"stage": 2,
"allgather_partitions": true,
"allgather_bucket_size": 1e8,
"overlap_comm": true,
"reduce_scatter": true,
"reduce_bucket_size": 1e8,
"contiguous_gradients": true
},
"gradient_accumulation_steps": "auto",
"gradient_clipping": "auto",
"steps_per_print": 2000,
"train_batch_size": "auto",
"train_micro_batch_size_per_gpu": "auto",
"wall_clock_breakdown": false
}
这里稍微修改了open-retrievals这里的代码,主要是修改了导入为包的导入,而不是相对引用。保存文件为embed.py
"""Embedding fine tune pipeline"""
import logging
import os
import pickle
from dataclasses import dataclass, field
from pathlib import Path
from typing import List, Optional
import torch
from torch.utils.data import DataLoader
from transformers import AutoTokenizer, HfArgumentParser, TrainingArguments, set_seed
from retrievals import (
EncodeCollator,
EncodeDataset,
PairCollator,
RetrievalTrainDataset,
TripletCollator,
)
from retrievals.losses import AutoLoss, InfoNCE, SimCSE, TripletLoss
from retrievals.models.embedding_auto import AutoModelForEmbedding
from retrievals.trainer import RetrievalTrainer
# os.environ["WANDB_LOG_MODEL"] = "false"
logger = logging.getLogger(__name__)
@dataclass
class ModelArguments:
model_name_or_path: str = field(
metadata={"help": "Path to pretrained model or model identifier from huggingface.co/models"}
)
config_name: Optional[str] = field(
default=None, metadata={"help": "Pretrained config name or path if not the same as model_name"}
)
tokenizer_name: Optional[str] = field(
default=None, metadata={"help": "Pretrained tokenizer name or path if not the same as model_name"}
)
cache_dir: Optional[str] = field(
default=None, metadata={"help": "Where do you want to store the pretrained models downloaded from s3"}
)
causal_lm: bool = field(default=False, metadata={'help': "Whether the model is a causal lm or not"})
lora_path: Optional[str] = field(default=None, metadata={'help': "Lora adapter save path"})
@dataclass
class DataArguments:
data_name_or_path: str = field(default=None, metadata={"help": "Path to train data"})
train_group_size: int = field(default=2)
unfold_each_positive: bool = field(default=False)
query_max_length: int = field(
default=32,
metadata={
"help": "The maximum total input sequence length after tokenization for passage. Sequences longer "
"than this will be truncated, sequences shorter will be padded."
},
)
document_max_length: int = field(
default=128,
metadata={
"help": "The maximum total input sequence length after tokenization for passage. Sequences longer "
"than this will be truncated, sequences shorter will be padded."
},
)
query_instruction: str = field(default=None, metadata={"help": "instruction for query"})
document_instruction: str = field(default=None, metadata={"help": "instruction for document"})
query_key: str = field(default=None)
positive_key: str = field(default='positive')
negative_key: str = field(default='negative')
is_query: bool = field(default=False)
encoding_save_file: str = field(default='embed.pkl')
def __post_init__(self):
# self.data_name_or_path = 'json'
self.dataset_split = 'train'
self.dataset_language = 'default'
if self.data_name_or_path is not None:
if not os.path.isfile(self.data_name_or_path) and not os.path.isdir(self.data_name_or_path):
info = self.data_name_or_path.split('/')
self.dataset_split = info[-1] if len(info) == 3 else 'train'
self.data_name_or_path = "/".join(info[:-1]) if len(info) == 3 else '/'.join(info)
self.dataset_language = 'default'
if ':' in self.data_name_or_path:
self.data_name_or_path, self.dataset_language = self.data_name_or_path.split(':')
@dataclass
class RetrieverTrainingArguments(TrainingArguments):
train_type: str = field(default='pairwise', metadata={'help': "train type of point, pair, or list"})
negatives_cross_device: bool = field(default=False, metadata={"help": "share negatives across devices"})
temperature: Optional[float] = field(default=0.02)
fix_position_embedding: bool = field(
default=False, metadata={"help": "Freeze the parameters of position embeddings"}
)
pooling_method: str = field(default='cls', metadata={"help": "the pooling method, should be cls or mean"})
normalized: bool = field(default=True)
loss_fn: str = field(default='infonce')
use_inbatch_negative: bool = field(default=True, metadata={"help": "use documents in the same batch as negatives"})
remove_unused_columns: bool = field(default=False)
use_lora: bool = field(default=False)
use_bnb_config: bool = field(default=False)
do_encode: bool = field(default=False, metadata={"help": "run the encoding loop"})
report_to: Optional[List[str]] = field(
default="none", metadata={"help": "The list of integrations to report the results and logs to."}
)
def main():
parser = HfArgumentParser((ModelArguments, DataArguments, RetrieverTrainingArguments))
model_args, data_args, training_args = parser.parse_args_into_dataclasses()
model_args: ModelArguments
data_args: DataArguments
training_args: TrainingArguments
if (
os.path.exists(training_args.output_dir)
and os.listdir(training_args.output_dir)
and training_args.do_train
and not training_args.overwrite_output_dir
):
raise ValueError(
f"Output directory ({training_args.output_dir}) already exists and is not empty. "
"Use --overwrite_output_dir to overcome."
)
logging.basicConfig(
format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
datefmt="%m/%d/%Y %H:%M:%S",
level=logging.INFO if training_args.local_rank in [-1, 0] else logging.WARN,
)
logger.warning(
"Process rank: %s, device: %s, n_gpu: %s, distributed training: %s, 16-bits training: %s",
training_args.local_rank,
training_args.device,
training_args.n_gpu,
bool(training_args.local_rank != -1),
training_args.fp16,
)
logger.info("Training/evaluation parameters %s", training_args)
logger.info("Model parameters %s", model_args)
logger.info("Data parameters %s", data_args)
set_seed(training_args.seed)
tokenizer = AutoTokenizer.from_pretrained(
model_args.tokenizer_name if model_args.tokenizer_name else model_args.model_name_or_path,
cache_dir=model_args.cache_dir,
use_fast=False,
)
if training_args.use_bnb_config:
from transformers import BitsAndBytesConfig
logger.info('Use quantization bnb config')
quantization_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16,
)
else:
quantization_config = None
if training_args.do_train:
model = AutoModelForEmbedding.from_pretrained(
model_name_or_path=model_args.model_name_or_path,
pooling_method=training_args.pooling_method,
use_lora=training_args.use_lora,
quantization_config=quantization_config,
)
loss_fn = AutoLoss(
loss_name=training_args.loss_fn,
loss_kwargs={
'use_inbatch_negative': training_args.use_inbatch_negative,
'temperature': training_args.temperature,
},
)
model = model.set_train_type(
"pairwise",
loss_fn=loss_fn,
)
train_dataset = RetrievalTrainDataset(
args=data_args,
tokenizer=tokenizer,
positive_key=data_args.positive_key,
negative_key=data_args.negative_key,
)
logger.info(f"Total training examples: {len(train_dataset)}")
trainer = RetrievalTrainer(
model=model,
args=training_args,
train_dataset=train_dataset,
data_collator=TripletCollator(
tokenizer,
query_max_length=data_args.query_max_length,
document_max_length=data_args.document_max_length,
positive_key=data_args.positive_key,
negative_key=data_args.negative_key,
),
)
Path(training_args.output_dir).mkdir(parents=True, exist_ok=True)
trainer.train()
# trainer.save_model(training_args.output_dir)
model.save_pretrained(training_args.output_dir)
if trainer.is_world_process_zero():
tokenizer.save_pretrained(training_args.output_dir)
if training_args.do_encode:
model = AutoModelForEmbedding.from_pretrained(
model_name_or_path=model_args.model_name_or_path,
pooling_method=training_args.pooling_method,
use_lora=training_args.use_lora,
quantization_config=quantization_config,
lora_path=model_args.lora_path,
)
max_length = data_args.query_max_length if data_args.is_query else data_args.document_max_length
logger.info(f'Encoding will be saved in {training_args.output_dir}')
encode_dataset = EncodeDataset(args=data_args, tokenizer=tokenizer, max_length=max_length, text_key='text')
logger.info(f"Number of train samples: {len(encode_dataset)}, max_length: {max_length}")
encode_loader = DataLoader(
encode_dataset,
batch_size=training_args.per_device_eval_batch_size,
collate_fn=EncodeCollator(tokenizer, max_length=max_length, padding='max_length'),
shuffle=False,
drop_last=False,
num_workers=training_args.dataloader_num_workers,
)
embeddings = model.encode(encode_loader, show_progress_bar=True, convert_to_numpy=True)
lookup_indices = list(range(len(encode_dataset)))
with open(os.path.join(training_args.output_dir, data_args.encoding_save_file), 'wb') as f:
pickle.dump((embeddings, lookup_indices), f)
if __name__ == "__main__":
main()
- 最终调用文件
shell run.sh
MODEL_NAME="moka-ai/m3e-base"
TRAIN_DATA="/root/kag101/src/open-retrievals/t2/t2_ranking.jsonl"
OUTPUT_DIR="/root/kag101/src/open-retrievals/t2/ft_out"
# loss_fn: infonce, simcse
deepspeed -m --include localhost:0 embed.py \
--deepspeed ds_zero2_no_offload.json \
--output_dir $OUTPUT_DIR \
--overwrite_output_dir \
--model_name_or_path $MODEL_NAME \
--do_train \
--data_name_or_path $TRAIN_DATA \
--positive_key positive \
--negative_key negative \
--pooling_method mean \
--loss_fn infonce \
--use_lora False \
--query_instruction "" \
--document_instruction "" \
--learning_rate 3e-5 \
--fp16 \
--num_train_epochs 5 \
--per_device_train_batch_size 32 \
--dataloader_drop_last True \
--query_max_length 64 \
--document_max_length 256 \
--train_group_size 4 \
--logging_steps 100 \
--temperature 0.02 \
--save_total_limit 1 \
--use_inbatch_negative false

4. 测试
微调前性能 c-mteb t2-ranking score

微调后性能

采用infoNCE损失函数,没有加in-batch negative,而关注的是困难负样本,经过微调map从0.654提升至0.692,mrr从0.754提升至0.805
对比一下非deepspeed而是直接torchrun的微调
- map略低,mrr略高。猜测是因为deepspeed中设置的一些auto会和直接跑并不完全一样

欢迎关注最新的更新https://github.com/LongxingTan/open-retrievals









![[基于 Vue CLI 5 + Vue 3 + Ant Design Vue 4 搭建项目] 02 配置 nodejs 淘宝镜像仓库](https://i-blog.csdnimg.cn/direct/2042382230b241148885c84c0b6f5f4d.png#pic_center)



![[000-01-008].第05节:OpenFeign特性-重试机制](https://i-blog.csdnimg.cn/direct/0782f831944e4fad88f42dea10fe6348.png)