我们在先前的一篇文章中已经总结了直接把Transformer应用到时间序列数据存在的问题,其中序列平稳化是transformer也是其他很多模型都未解决好的一个不足。实际上,序列平稳和非平稳是矛盾的存在,这篇文章探索了:原始数据-->平稳化-->建模-->去平稳化-->输出结果的方式。期望通过改进Attention计算,在两者之间达到平衡。
什么是序列平稳/非平稳性?
首先,让我们简要说明一下什么是平稳和非平稳序列,这是两种不同的数据模式。
平稳序列(Stationary Series)
-
常态不变性(Stationarity):其统计特性如均值、方差和自相关性等统计特性在不同时间段内保持不变。具体来说,平稳序列在时间上不会显示出趋势、季节性或周期性等变化。这种序列的特点是其统计性质不随时间变化而改变。
-
平稳性质的重要性:平稳序列的分析更加可靠,因为它的统计性质不随时间变化而改变,使得模型的预测和分析更加准确和可靠。
非平稳序列(Non-stationary Series)
-
统计特性随时间变化:非平稳序列是指其统计特性在时间上发生变化。这种序列可能具有趋势(随着时间变化的整体增长或减少)、季节性(周期性变化)或者其他随机的不规则变化。
-
处理的挑战:非平稳序列的分析更加复杂,因为它们的统计特性随时间变化而改变,需要在建模和分析中采取相应的措施来处理趋势、季节性或其他非平稳性,以确保模型的准确性。
带来的问题
如前所述,非平稳数据难以预测,而平稳序列序列统计性质稳定,许多时间序列模型都首先对数据进行normalization等转换,以使其变得平稳,然后再建模进行分析和预测。
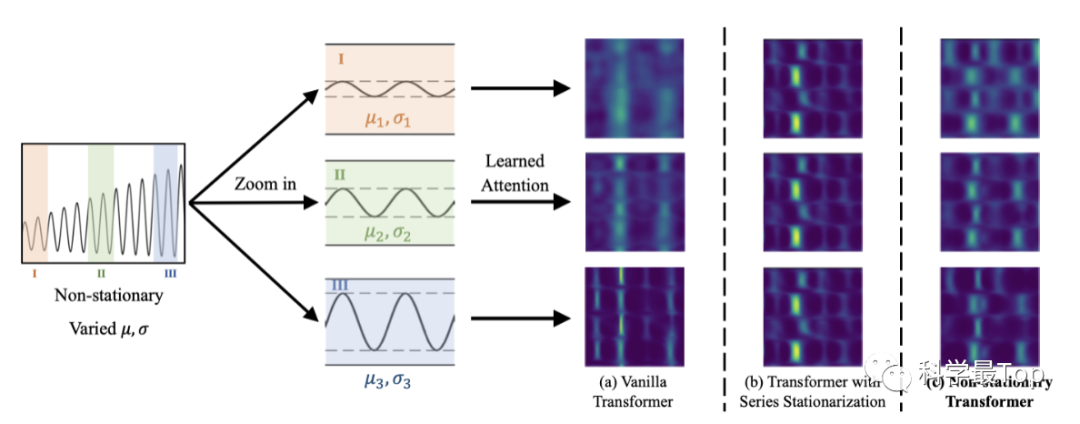
但是,经过平稳化处理后,序列会丧失很多固有的特征,如子图b中,虽然左侧attention权重更明显,但右侧很多特征直接就被丢掉,对于真实世界中的突发事件预测可能不够有指导性。这个问题在这篇论文中被称为"过度平稳化"。
Non-stationary Transformers的改进做法
为了兼顾序列可预测性(平稳)和模型能力(非平稳),作者提出Non-stationary Transformer框架,包含两个核心模块:(a)序列平稳化和(b)去平稳化模块。是的没错,先进行Normalization平稳化,然后去平稳化恢复统计特性,使其转换为更具有可预测性的特征表示。
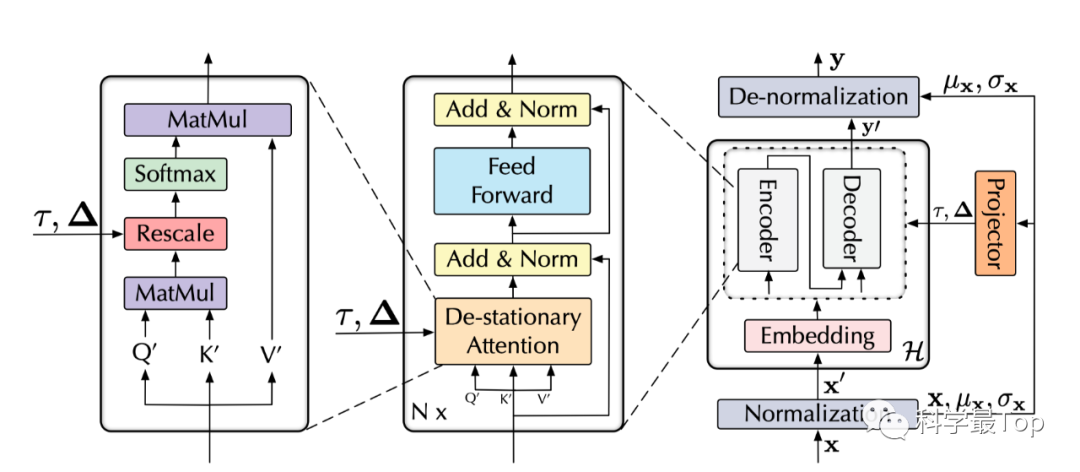
序列平稳化
序列平稳化过程没有需要特别讲解的,就是图中的Normalization,假设原序列为 ,则按照如下公式处理后的平稳化序列计作 , 同时 为均值, 为方差。
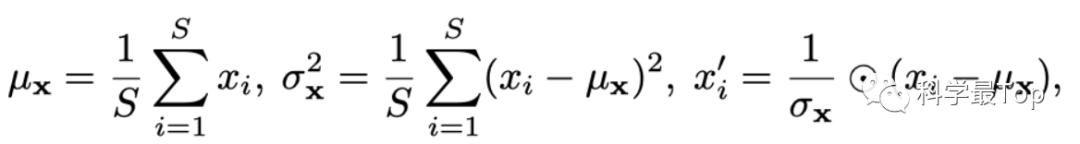
序列去平稳化(重点)
序列去平稳化则有两部分,第一是:对上述平稳化统计指标 均值, 方差的回加。
-
配合以下公式和模型图看,我们发现是利用原始数据的统计信息( 和 )对模型输出进行De-normalization。
-
首先,我们看图中最右侧部分,记encoder和decoder所有的处理过程为 ,那么把平稳化后的序列计作 , 经过 运算的输出是 。
-
然后,将模型输出 加上 (平均值),然后乘以 (标准差)得到最终的预测结果 ŷ。
-
通过以上步骤,能够部分的将经过平稳化处理的模型输出,还原为原始数据的预测结果。
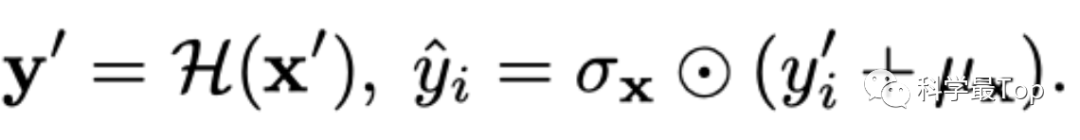
但是,仅通过以上步骤显然并不能完全恢复原始序列的非平稳性。举例来说,不同的时间序列是可以生成相同的平稳化输入 。然后,模型会得到相同的注意力权重,这样就无法捕捉与非平稳性纠缠在一起的重要时间依赖关系。换句话说,由过度平稳化引起的削弱效应发生在深度模型内部,特别是在注意力计算中。
这就到了本篇文章最核心的部分,去平稳注意力机制(De-stationary Attention),我手工推导了整个过程。而要理解这个过程,你首先得知道transformer的注意力机制是如何计算的,如下公式所示。
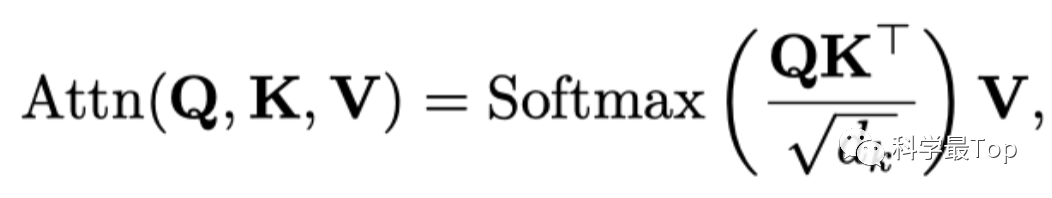
-
还记得transformer中的Q,K,V是怎么来的吗?在Transformer模型中,Q(Query)、K(Key)、V(Value)是通过对输入 进行线性变换获得的,以Q为例,是输入向量 乘以一个权重 得到的,这个过程可记作 。
-
此时,我们把序列 的平稳化过程的公式1,代入注意力查询向量Q的计算过程公式2,并进行整理,就能得到红框中的结果, 就表示平稳化后的查询向量。本质上,是通过公式1,建立了平稳化前和平稳化后的联系。同理,我们也能得到K的前后关联。
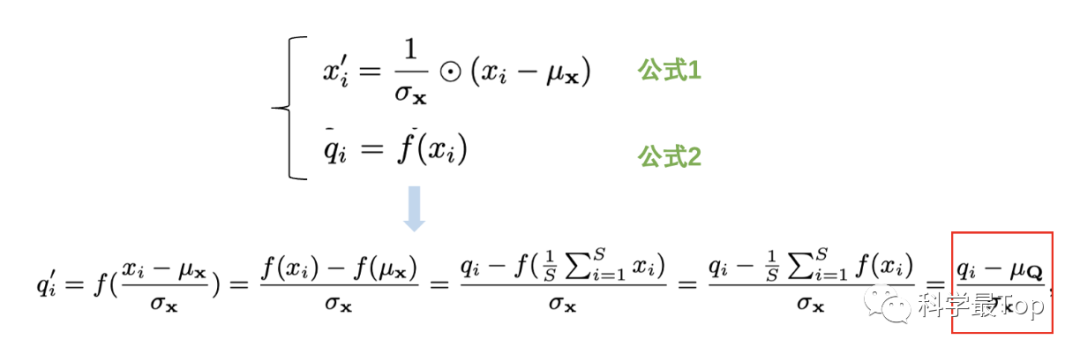
-
有了 和 的表示,两者相乘就到了公式3,注意公式三是同时具有平稳化前后的Q 和K的,于是经过简单的移项,我们就可以把来自公式3的 代入公式4。
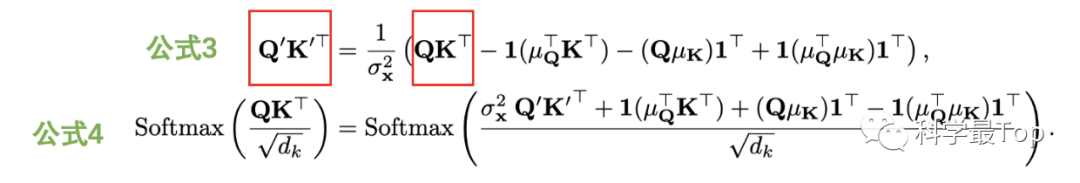
-
公式4的分子后两项中,最后都乘了1向量的转置(1^T),也就是元素全为1的行向量,而前面的东西是个列向量,乘以这个1^T就相当于列向量复制,所以加上后两项,就等价于对矩阵的每行元素加上相同的值。因此,公式4简化为下面公式:
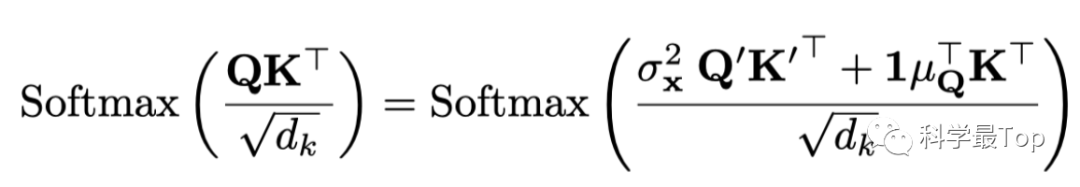
-
到这一步,我们期望利用平稳化后的 来恢复平稳化前的 和 ,观察上面的公式, 和 两项是重点。于是,文章又用多层感知机,从未经过平稳化的 的统计数据 和 中分别学习去平稳因子 和 。
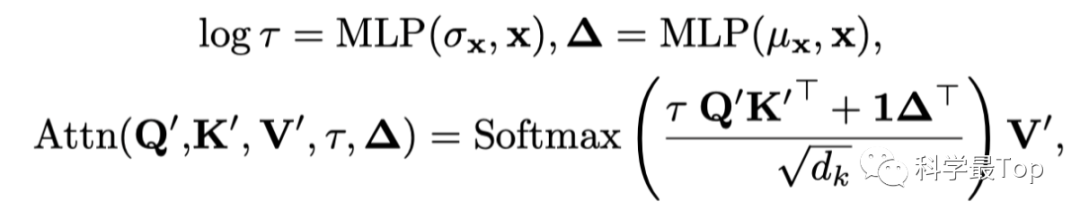
至此,就全部推理结束了,这篇文章我看了几遍,以上是我的笔记,有错误请大家指正。
欢迎大家关注我的公众号【科学最top】,回复‘论文2024’可获取,2024年ICLR、ICML、KDD、WWW、IJCAI五个顶会的时间序列论文整理列表和原文。