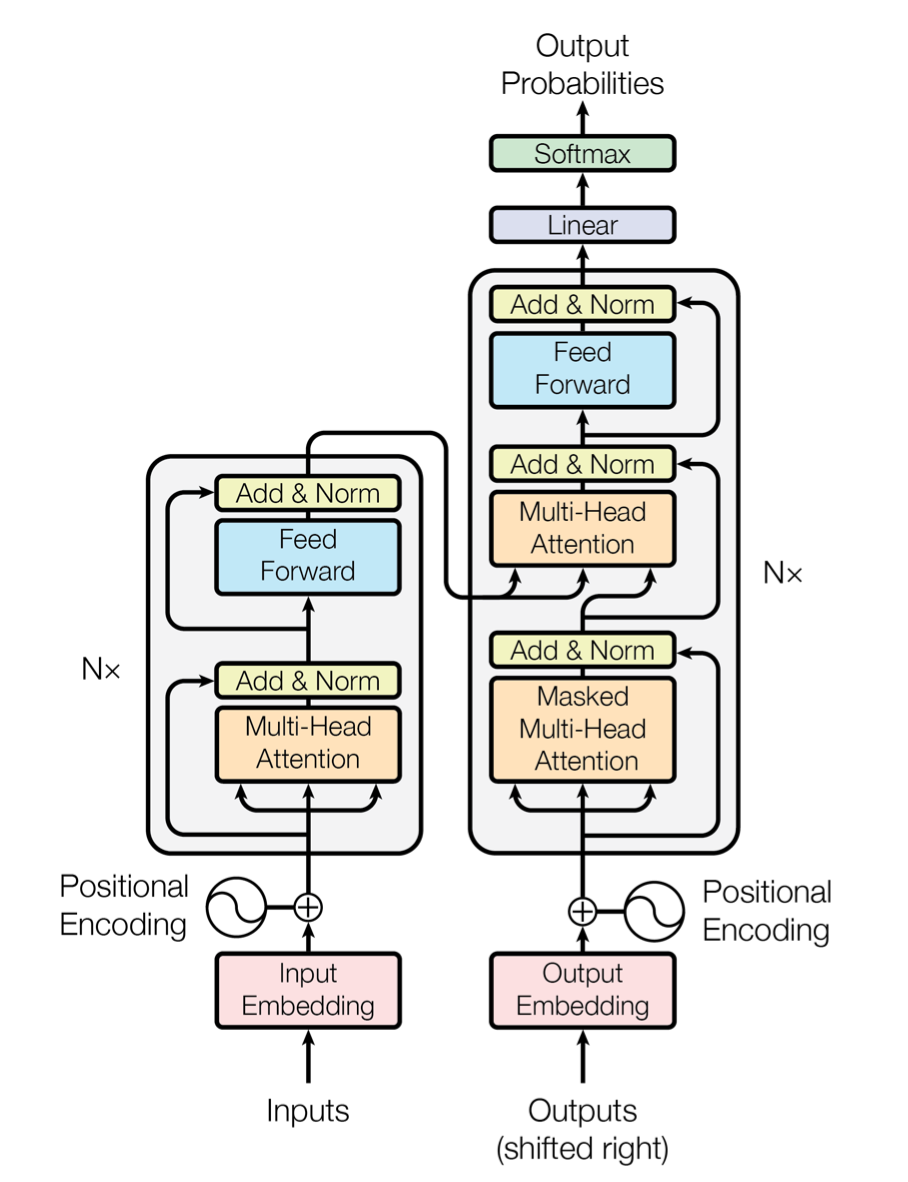
Transformer的模型架构实际上非常简单,Self-Attention 和 Cross-Attention 仅仅是在
k,v上有所不同(这里不讨论 mask)。论文原文:Attention Is All You Need
我们可以使用同一个 Attention 类来实现 Self-Attention 和 Cross-Attention。实际上,在 Transformer 的源代码中就是如此。抛开花哨的可视化所赋予的意义,下面是一个 Attention 的实现:
import torch
import torch.nn as nn
import math
# 单头,无 mask 的 Attention 实现(如果你不知道这里说的是什么,就不用在意)
class Attention(nn.Module):
def __init__(self, d_model):
super(Attention, self).__init__()
# 定义查询、键和值的线性变换
self.w_q = nn.Linear(d_model, d_model)
self.w_k = nn.Linear(d_model, d_model)
self.w_v = nn.Linear(d_model, d_model)
self.softmax = nn.Softmax(dim=-1)
def forward(self, q, k, v):
# 计算查询、键和值的投影
q = self.w_q(q)
k = self.w_k(k)
v = self.w_v(v)
# 计算注意力得分
attention_scores = torch.matmul(q, k.transpose(-2, -1)) / math.sqrt(q.size(-1))
attention_weights = self.softmax(attention_scores)
# 加权求和得到输出
attention_output = torch.matmul(attention_weights, v)
return attention_output
这里 d_model 指的是输入的维度,可以看到
W
q
W_q
Wq,
W
k
W_k
Wk,
W
v
W_v
Wv 实际上就是一个简单的线性层nn.Linear(d_model, d_model),没有任何多余的操作。而这个 Attention() 所接受的输入q, k, v,就是我们将讨论的 self-Attention 和 cross-attention 的主要区别所在。
什么是Self-Attention?
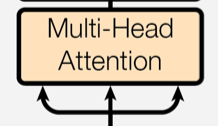
Self-attention,也叫intra-attention,是指序列中的每个元素通过与该序列的其他元素进行关联,来捕捉上下文信息。其关键在于,查询(query)、键(key)和值(value)都来自同一序列(看图可以发现,线条一分为三),通过这种机制,模型能够在不同位置上计算特征的相关性,获取全局信息。
Self-Attention的计算过程:
- 对输入进行线性变换生成
q,k,v(即查询、键和值)。- 计算查询和键之间的相似性(注意力得分)。
- 用softmax归一化注意力得分,生成注意力权重。
- 使用注意力权重对值
v进行加权求和,生成最终的输出。
# 示例输入数据:q, k, v 来自相同序列
q = k = v = torch.randn(2, 10, 64) # batch_size=2, 序列长度=10, d_model=64
# 初始化Attention层
attention = Attention(d_model=64)
# 执行前向传播
output = attention(q, k, v)
print(output.shape) # 输出形状为 (2, 10, 64)
代码说明:
- Self-Attention 中
q,k,v均来自同一个输入序列,所以在这里直接将它们设置为相同的张量。在其他仓库的实现中,你可能会看到attention(x, x, x)。
什么是Cross-Attention?
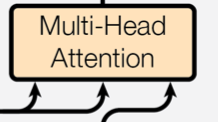
Cross-attention的查询(query)来自一个序列,而键(key)和值(value)来自另一个序列。
它的目的是让模型能够结合来自两个不同输入的信息,在跨模态任务或翻译任务中,cross-attention非常有用,例如在解码阶段将目标语言与源语言关联。
Cross-Attention的计算过程:
与self-attention一致,主要区别在于
q和k,v来自不同的输入序列。
# 示例输入数据:q与k, v来自不同序列
q = torch.randn(2, 10, 64) # batch_size=2, 序列长度=10, d_model=64 (Query序列)
k = v = torch.randn(2, 15, 64) # batch_size=2, 序列长度=15, d_model=64 (Key/Value序列)
# 执行前向传播
output = attention(q, k, v)
print(output.shape) # 输出形状为 (2, 10, 64)
代码说明:
- 通常
q是解码器(decoder)的输入,k和v来自编码器(encoder)。
总结
- 输入来源:Self-Attention中,
q,k,v都来自同一序列;Cross-Attention中,q来自一个序列,k和v来自另一个序列。 - 应用场景:Self-Attention 通常用于理解同一序列中的上下文关系,如文本分析、机器翻译的编码阶段;Cross-Attention 用于两个不同序列间的关联,如机器翻译的解码阶段。
下面是 Transformer 完整的模型架构图: