论文地址:Real-Time Single Image and Video Super-Resolution Using an Efficient Sub-Pixel Convolutional Neural Network
相关知识点总结:
- 许多SR技术的一个关键假设是,大部分高频数据是冗余的,因此可以从低频分量中准确重建
论文标题可以简单翻译为使用高效的亚像素卷积神经网络实现实时单图像和视频超分辨率。
亚像素(sub-pixel)是指在传统像素概念下,图像的最小可分辨单位。在相机成像的过程中,由于感光元件的能力限制,每个像素通常只代表其附近的颜色。然而,在两个物理像素之间,理论上还存在着更细微的图像信息,这些信息被称为“亚像素”。实际上,亚像素是存在的,但因为硬件传感器的限制,我们无法直接检测到它们,通常需要通过软件算法来近似计算它们的位置和颜色值。
亚像素精度是指相邻两像素之间细分的程度。例如,如果将每个像素在横向和纵向上细分为四个更小的单元,这就意味着实现了四分之一的亚像素精度。通过这种细分,可以提高图像的分辨率,因为每个像素点可以表示更多的信息。这种技术在图像超分辨率、图像锐化、图像配准和机器视觉等领域有着广泛的应用。
在图像处理中,亚像素技术可以用来提高测量精度,例如在边缘检测、特征点定位等方面。通过亚像素级的处理,可以使得图像分析的结果更为精确,从而达到更高的性能要求。常用的亚像素算法包括几何方法、矩估计方法和插值法等,这些方法通过不同的数学模型和计算方式来实现对图像中细微特征的精确定位。
总的来说,亚像素技术是图像处理领域中用于提高图像分辨率和分析精度的重要技术之一。通过在软件层面对图像进行亚像素级的处理,可以在不增加硬件成本的情况下,提升图像的质量和应用效果。
本文的主要工作是亚像素的卷积神经网络。亚像素卷积神经网络(Sub-Pixel Convolutional Neural Network,简称ESPCN)是一种用于图像超分辨率的深度学习模型。它通过在神经网络中引入一种高效的亚像素卷积层来实现图像的上采样,从而提高图像的分辨率。
在传统的图像上采样方法中,如双线性插值或双三次插值,通常会在卷积神经网络处理之前对低分辨率(LR)图像进行放大,这样做会增加计算复杂度和内存成本。ESPCN的核心思想是将上采样步骤放在网络的最后一层进行,这意味着网络直接处理较小尺寸的LR图像,从而减少了计算量。
亚像素卷积层的工作原理是通过卷积操作生成一个通道数为 upscale_factor^2 的特征图,其中 upscale_factor 是图像放大的倍数。然后,通过一种称为 PixelShuffle 的操作,将这些通道重新排列成高分辨率(HR)图像。PixelShuffle 实际上是将每个像素的位置扩展为 upscale_factor × upscale_factor 的块,从而实现图像的放大。
ESPCN的优势在于它能够以较少的计算量实现高质量的图像超分辨率,这使得它在实时超分辨率应用中非常有用。此外,由于它在网络末端进行上采样,因此可以更有效地学习从LR到HR的映射。
在实际应用中,ESPCN通常包含几个卷积层来提取图像特征,最后一个卷积层的输出通道数为 upscale_factor^2,然后通过 PixelShuffle 操作来恢复图像的高分辨率。这种结构简单而有效,已经被广泛应用于图像和视频的超分辨率任务中。
总结来说,亚像素卷积神经网络通过在网络末端引入亚像素卷积层和 PixelShuffle 操作,以较小的计算成本实现了图像的高质量上采样,是图像超分辨率领域的一个重要进展。
这篇论文是由twitter做的工作。下面我们具体看一下paper的细节。
摘要
最近,几个基于深度神经网络的模型在单图像超分辨率的重建精度和计算性能方面都取得了巨大的成功。在这些方法中,低分辨率(LR)输入图像在重建之前使用单个滤波器(通常是双三次插值)放大到高分辨率(HR)空间。这意味着超分辨率(SR)操作是在HR空间中执行的。我们证明这是次优的,并增加了计算复杂度。在本文中,我们提出了第一个能够在单个K2 GPU上实时SR 1080p视频的卷积神经网络(CNN)。为了实现这一点,我们提出了一种新颖的CNN架构,其中特征图是在LR空间中提取的。此外,我们引入了一个高效的亚像素卷积层,该层学习一组上采样滤波器,将最终的LR特征图上采样到HR输出。通过这样做,我们有效地用专门针对每个特征图训练的更复杂的上采样滤波器替换了SR流程中的手工制作双三次滤波器,同时也减少了整个SR操作的计算复杂度。我们使用公开可用数据集的图像和视频评估了所提出的方法,并表明它比以前基于CNN的方法表现得更好(图像上+0.15dB,视频上+0.39dB),并且快了一个数量级。
NVIDIA GRID K2 是由 NVIDIA 推出的一款专业级图形处理卡,专为虚拟化环境设计,用于加速图形在虚拟远程工作站和虚拟桌面环境中的性能。它基于 NVIDIA 的 Kepler 架构,配备了两颗高性能的 GK104 GPU,每颗 GPU 拥有 1536 个 CUDA 核心,核心频率为 745 MHz。GRID K2 具有 8 GB 的 GDDR5 显存(每颗 GPU 4 GB),通过 256 位的内存接口连接,显存频率为 1250 MHz(有效 5 Gbps),提供 160.0 GB/s 的内存带宽。
以下是 NVIDIA GRID K2 和 NVIDIA A100 GPU 的一些关键规格比较:
| 特性 | NVIDIA GRID K2 | NVIDIA A100 |
|---|---|---|
| 架构 | Kepler (GK104) | Ampere (GA100) |
| CUDA 核心数量 | 1536 个(每个 GPU)x 2 = 3072 个 | 6912 个 |
| 内存类型 | GDDR5 | HBM2 |
| 内存容量 | 4 GB(每个 GPU)x 2 = 8 GB | 40 GB / 80 GB |
| 内存带宽 | 160.0 GB/s | 1.6 TB/s (40 GB 版本) / 2 TB/s (80 GB 版本) |
| 核心频率 | 745 MHz | 1.41 GHz(最高 Boost 频率) |
| 热设计功耗 (TDP) | 225 瓦特 | 250 瓦特(40 GB 版本)/ 400 瓦特(80 GB 版本) |
| 发布年份 | 2013 | 2020 |
| 价格 | 5199 美元(发布时价格) | 9999 美元起(40 GB 版本,发布时价格) |
| 适用领域 | 虚拟化图形处理 | AI、数据分析、高性能计算 |
| 显存位宽 | 256 位 | 2,048 位 |
| 支持的 Tensor Core 代数 | 无 | 第三代 |
| 支持的 NVLink 代数 | 无 | 第三代 |
| 多实例 GPU (MIG) 支持 | 无 | 支持,最多 7 个实例 |
相比A100,K2弱的不是一星半点。
在图像和视频处理领域,分贝(dB)是一个用来表示信号强度或质量相对变化的单位。它是一个对数单位,用于描述两个数值之间的比例关系。在图像和视频质量评估中,分贝通常用来量化图像或视频超分辨率算法的性能提升。
具体来说,当使用分贝(dB)来衡量图像或视频质量时,它通常是基于峰值信噪比(PSNR)来计算的。PSNR 是一种衡量图像或视频重建质量的指标,它计算原始信号与重建信号之间的均方误差(MSE)。PSNR 的计算结果通常以分贝为单位表示,因为 PSNR 的计算涉及到误差的平方,使用分贝可以将其转换为更直观的对数尺度。
1.介绍
从数字图像处理的角度来看,从低分辨率(LR)图像或视频恢复高分辨率(HR)图像或视频是一个极具兴趣的课题。这项任务被称为超分辨率(SR),它在许多领域都有直接应用,如高清电视(HDTV)、医学成像、卫星成像、面部识别和监控。通常SR问题假设LR数据是HR数据的低通滤波(模糊)、下采样和噪声版本。由于在不可逆的低通滤波和下采样操作过程中丢失了高频信息,这是一个高度不适定的问题。此外,SR操作实际上是从LR到HR空间的一个多对一映射,可能有多解,其中确定正确解并非易事。许多SR技术的一个关键假设是,大部分高频数据是冗余的,因此可以从低频分量中准确重建。因此,SR是一个推断问题,因此依赖于我们对所讨论图像统计模型的了解。
许多方法假设有多幅图像作为同一场景的不同视角的LR实例,即具有独特的先验仿射变换。这些可以归类为多图像SR方法,并利用通过额外信息约束不适定问题并尝试逆转下采样过程的显式冗余。然而,这些方法通常需要计算复杂的图像配准和融合阶段,其准确性直接影响结果的质量。另一种方法是单图像超分辨率(SISR)技术。这些技术寻求学习自然数据中存在的隐含冗余,以从单个LR实例中恢复缺失的HR信息。这通常以图像的局部空间相关性和视频中的额外时间相关性的形式出现。在这种情况下,需要以重建约束的形式提供先验信息,以限制重建的解空间。
1.1 相关工作
单图像超分辨率(SISR)方法的目标是从单个低分辨率(LR)输入图像恢复高分辨率(HR)图像。最近流行的SISR方法可以分为基于边缘的方法、基于图像统计的方法和基于块的方法。最近在解决SISR问题上取得进展的一种方法是基于稀疏性技术。稀疏编码是一种有效的机制,它假设任何自然图像都可以在变换域中稀疏表示。这个变换域通常是图像原子的字典,可以通过训练过程学习得到,该过程试图发现LR和HR块之间的对应关系。这个字典能够嵌入必要的先验知识,以约束超分辨率未见数据的不适定问题。基于稀疏性技术的一个缺点是,通过非线性重建引入稀疏性约束通常计算成本较高。
通过神经网络得到的图像表示最近在单图像超分辨率(SISR)领域展现出了巨大的潜力。这些方法利用反向传播算法在大型图像数据库如ImageNet上进行训练,以学习低分辨率(LR)和高分辨率(HR)图像块之间的非线性映射。例如,堆叠协作局部自编码器(Stacked collaborative local auto-encoders)被用于逐层超分辨率LR图像。Osendorfer等人提出了一种基于预测性卷积稀疏编码框架的SISR方法。受稀疏编码方法启发,提出了一种多层卷积神经网络(CNN)。Chen等人提出使用多阶段可训练的非线性反应扩散(multi-stage trainable nonlinear reaction diffusion,TNRD)作为CNN的替代方案,其中权重和非线性是可训练的。Wang等人训练了一个从端到端的级联稀疏编码网络,灵感来自LISTA(Learning iterative shrinkage and thresholding algorithm)算法,以充分利用图像的自然稀疏性。网络结构不仅限于神经网络,例如,随机森林也已成功用于SISR。
1.2 动机和贡献
随着卷积神经网络(CNN)的发展,算法的效率,尤其是它们的计算和内存成本,变得越来越重要。深度网络模型的灵活性在于学习非线性关系,已被证明在重建精度上优于以往的手工制作模型。为了将低分辨率(LR)图像超分辨率(SR)到高分辨率(HR)空间,有必要在某个点上提高LR图像的分辨率以匹配HR图像。
在Osendorfer等人的研究中,图像分辨率在网络中间逐步提高。另一种流行的方法是在网络的第一层之前或在第一层提高分辨率。然而,这种方法存在一些缺点。首先,在图像增强步骤之前提高LR图像的分辨率会增加计算复杂性。这对于卷积网络尤其成问题,因为处理速度直接取决于输入图像的分辨率。其次,通常用于完成此任务的插值方法,如双三次插值,并没有为解决不适定的重建问题带来额外的信息。
在Dong等人的研究中,简要地提出了学习上采样滤波器的建议。然而,将其作为SR操作的一部分集成到CNN中的重要性并没有得到充分认识,这个做法也没有被探索。此外,正如Dong等人所指出的,没有有效的实现卷积层其输出大小大于输入大小的实现,并且像convnet这样的良好优化实现的网络结构,并不简单地支持这种操作。
在本文中,与以往的工作相反,我们提议只在网络的最后提高从LR到HR的分辨率,并从LR特征图超分辨率HR数据。这消除了在远大于HR分辨率下执行大部分SR操作的必要性。为此,我们提出了一个高效的亚像素卷积层来学习图像和视频超分辨率的上采样操作。
这些贡献的优势有两个方面:首先,通过在网络的最后阶段进行分辨率提升,可以减少在更高分辨率下处理图像所需的计算量;其次,通过学习特定的上采样滤波器,可以更有效地利用网络学习到的特征,从而提高超分辨率图像的质量。这种方法不仅提高了计算效率,还有助于生成视觉上更令人满意的高分辨率图像。
本文的主要贡献总结为以下两点:
• 在我们的网络中,上采样由网络的最后一层处理。这意味着每张低分辨率(LR)图像都直接输入到网络中,并通过LR空间中的非线性卷积进行特征提取。由于输入分辨率的降低,我们可以有效地使用更小的滤波器尺寸来整合相同的信息,同时保持给定的上下文区域。分辨率和滤波器尺寸的减少大大降低了计算和内存复杂性,足以允许高清(HD)视频实时超分辨率。
• 对于一个有L层的网络,我们为nL-1个特征图学习nL-1个上采样滤波器,而不是为输入图像学习一个上采样滤波器。此外,不使用显式插值滤波器意味着网络隐式地学习了SR所需的处理。因此,与第一层的单一固定滤波器上采样相比,网络能够学习更好、更复杂的LR到HR映射。这导致模型的重建精度得到额外提高。
我们使用公开可用的基准数据集的图像和视频来验证所提出的方法,并将我们的性能与先前工作进行了比较。我们展示了所提出的模型实现了最先进的性能,并且在图像和视频上的速度几乎比之前发布的方法快了一个数量级。
2. 实现方法
SISR任务的目标是根据给定的低分辨率(LR)图像I_LR估计相应的高分辨率(HR)图像I_SR。LR图像I_LR是从相应的原始HR图像I_HR下采样得到的。下采样操作是确定性的并且已知的:为了从I_HR产生I_LR,我们首先使用高斯滤波器对I_HR进行卷积——从而模拟相机的点扩散函数——然后以r的因子对图像进行下采样。我们将r称为上采样比率。通常,I_LR和I_HR都可以有C个颜色通道,因此它们分别被表示为大小为H×W×C和rH×rW×C的实值张量。
相机的点扩散函数(Point Spread Function,简称PSF)是一个光学系统对一个点光源响应的描述。在图像处理和摄影领域,PSF用来模拟相机镜头对单个像素点或微小物体的成像效果。当光线通过相机镜头时,由于光学系统的不完美(例如透镜的色差、球差、衍射等),一个理想的点光源在成像平面上并不是被记录为一个完美的点,而是被散布成一个模糊的光斑,这个光斑的形状和大小就是PSF。
PSF的特性对于理解图像的模糊程度和质量至关重要。在理想情况下,如果一个相机的PSF是完美的,那么它能够将每个点光源完美地聚焦成一个点,从而产生无限锐利的图像。然而,在现实世界中,由于光学限制和物理因素,PSF通常具有一定的模糊性,这会导致成像时的分辨率降低和图像细节丢失。
在图像去模糊、超分辨率和其他图像恢复任务中,PSF是一个重要的参数,因为它提供了从低质量图像重建高质量图像所需的信息。通过估计或测量相机的PSF,可以设计算法来逆转模糊效果,从而恢复更接近原始场景的图像。在这些应用中,PSF通常通过实验测量或从相机的光学特性中计算得出。
为了解决SISR问题,之前的工作SRCNN先将I_LR进行上采样和插值,然后使用处理后的图像恢复图像,而不是直接从I_LR恢复。为了恢复I_SR,使用了3层卷积网络。在本节中,我们提出了一种新颖的网络架构,如Figure 1所示,以避免在将I_LR输入网络之前对其进行上采样。在我们的架构中,我们首先直接对LR图像应用l层卷积神经网络,然后应用一个亚像素卷积层,将LR特征图上采样以产生I_SR。
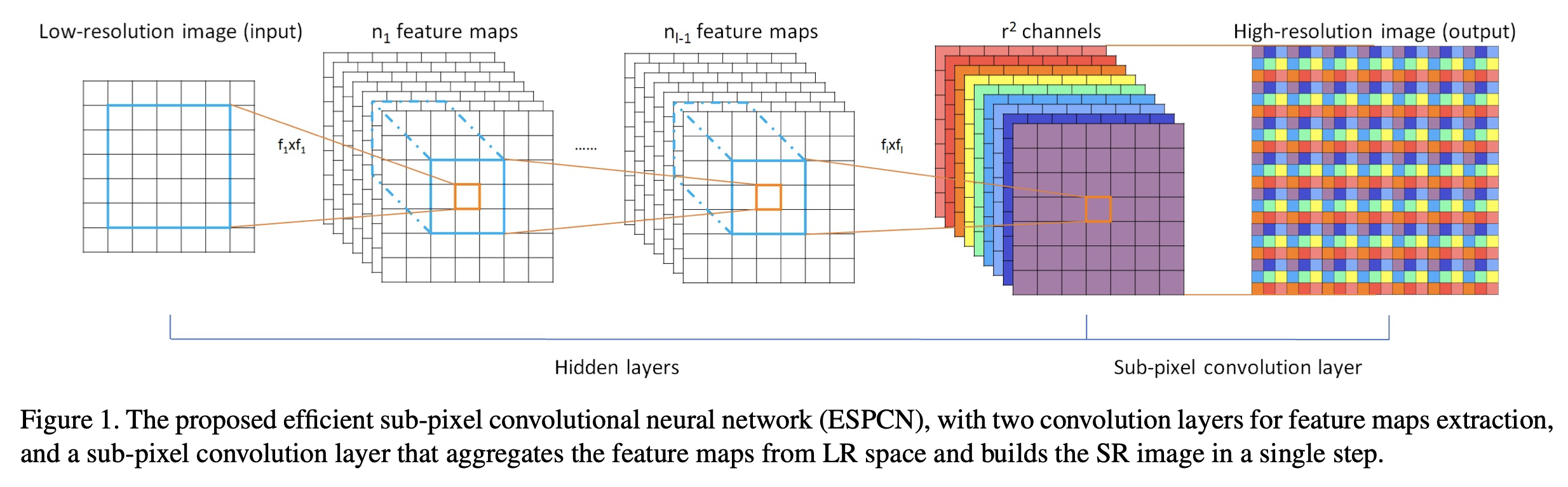
对于一个由L层组成的网络,前L-1层可以描述如下:

Wl、bl,l ∈ (1, L − 1)分别是可学习的网络权重和偏置。Wl是一个大小为n_(l−1) × nl × kl × kl的二维卷积张量,其中nl是第l层的特征数量,n0 = C(C为输入图像的通道数),kl是第l层的滤波器尺寸。偏置bl是长度为nl的向量。非线性函数(或激活函数)φ逐元素应用,并且是固定的。最后一层fL必须将低分辨率(LR)特征图转换为高分辨率(HR)图像I_SR。
2.1 反卷积层
添加反卷积层是恢复最大池化和其他图像下采样层分辨率的流行选择。这种方法已成功用于可视化激活层,并用于使用网络中的高级特征生成语义分割。很容易证明,SRCNN中使用的双三次插值是反卷积层的一个特例。反卷积层可以看作是将每个输入像素与滤波器元素逐点相乘,并在结果输出窗口上进行求和,也被称为反向卷积。
在深度学习和计算机视觉中,“Deconvolution layer” 或 “Transposed Convolution” 是一种用于上采样(增大图像尺寸)的神经网络层。这种层通常用于卷积神经网络中,以恢复图像的空间分辨率,常见于图像分割、生成对抗网络(GANs)和图像超分辨率等任务中。
转置卷积层的工作原理与传统的卷积层相反。在传统卷积层中,输入图像通过卷积核进行卷积操作,输出特征图(feature map)的尺寸通常小于输入图像。而在转置卷积层中,输入特征图的尺寸被增大,输出的图像尺寸因此变大,这有助于恢复细节信息。
转置卷积层在实现上通常通过补零(zero-padding)和旋转卷积核(即将卷积核转置)来实现。这种操作使得每个输出像素能够与输入特征图上的多个位置相关联,从而实现上采样。
在实际应用中,转置卷积层可以看作是一种学习型上采样方法,它通过训练过程中的反向传播算法来优化卷积核的权重,从而学习到最佳的上采样模式。这种学习型上采样方法相比于传统的固定插值方法(如最近邻插值或双线性插值)通常能够获得更好的性能。
总的来说,转置卷积层是一种强大的工具,它允许神经网络在保持学习参数的同时,对图像进行有效的上采样和分辨率恢复。
2.2. 高效的亚像素卷积层
另一种上采样低分辨率(LR)图像的方法是在LR空间中使用分数步长1/r的卷积,这可以通过插值、perforate或从LR空间到高分辨率(HR)空间的池化来实现,然后以步长1在HR空间进行卷积。这些实现将计算成本增加了r^2倍,因为卷积是在HR空间进行的。
或者,在LR空间中使用步长1/r的卷积,滤波器Ws,kernel大小为ks,权重间距为1/r,将激活Ws的不同部分进行卷积。落在像素之间的权重不会被激活,也不需要计算。激活模式的数量正好是r2。每个激活模式根据其位置,最多有⌈ks/r⌉2个权重被激活。这些模式在滤波器跨图像卷积期间根据不同的子像素位置:mod(x,r),mod(y,r)周期性地激活,其中x, y是HR空间中的输出像素坐标。在本文中,我们提出了一种有效的方法来实现上述操作,当mod(ks, r) = 0时:
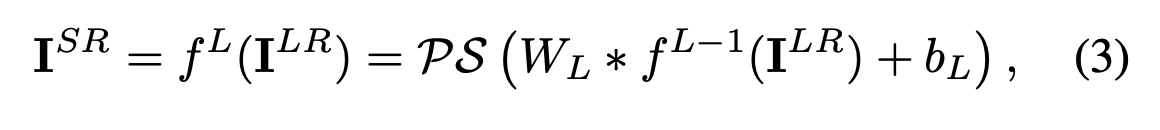
其中PS是一个周期性重排操作符,它将一个H×W×C·r^2张量的元素重新排列成形状为rH × rW × C的张量。这种操作的效果如Figure 1所示。从数学上讲,这种操作可以这样描述:
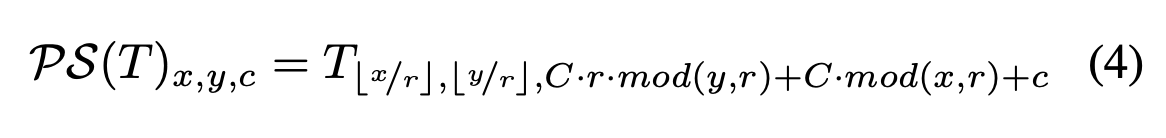
因此,卷积操作符WL的形状为n_{L-1} × r^2C × k_L × k_L。注意我们不在最后一层的卷积输出上应用非线性。很容易看出,当k_L = ks/r且mod(ks, r) = 0时,它等同于在LR空间中使用滤波器Ws的子像素卷积。我们将我们的新层称为子像素卷积层,我们的网络称为高效的子像素卷积神经网络(ESPCN)。这最后一层直接从LR特征图产生HR图像,每个特征图使用一个上采样滤波器,如下图所示。

给定一个由HR图像示例In_HR, n = 1 … N组成的训练集,我们生成相应的LR图像I_LR, n = 1 … N,并计算重构的像素级均方误差(MSE)作为训练网络的目标函数:
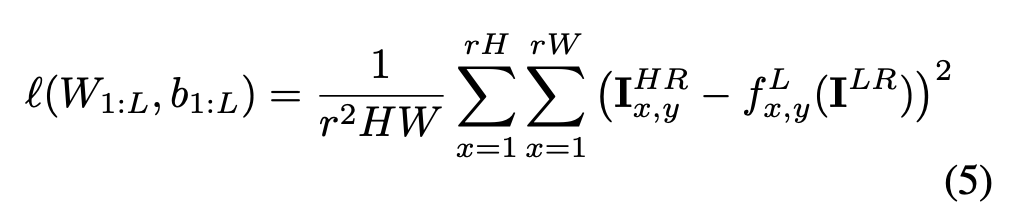
值得注意的是,上述周期性重排的实现可以在训练时去掉。我们不是将重排作为层的一部分来执行,而是可以预先重排训练数据以匹配层输出的PS之前的结果。因此,我们提出的层在训练时比反卷积层快log2(r2)倍,比使用各种形式的上采样后再进行卷积的实现快r2倍。
3.实验
3.1.数据集
在评估过程中,我们使用了公开可用的基准数据集,包括Timofte数据集,这是SISR论文广泛使用的数据集,它提供了多种方法的源代码、91张训练图像以及两个测试数据集Set5和Set14,分别提供5张和14张图像;伯克利分割数据集BSD300和BSD500,分别提供100张和200张图像用于测试,以及超级纹理数据集,提供136张纹理图像。对于我们的最终模型,我们从ImageNet中随机选择了50,000张图像进行训练。遵循先前的工作,我们在这一部分只考虑YCbCr颜色空间中的亮度通道,因为人类对亮度变化更敏感。对于每个上采样因子,我们训练一个特定的网络。
对于视频实验,我们使用了公开可用的Xiph数据库中的1080p高清视频。数据库包含8个大约10秒长的高清视频集合,宽高为1920×1080。此外,我们还使用了Ultra Video Group数据库,包含7个大小为1920×1080的视频,长度为5秒。
3.2 实现细节
对于ESPCN,我们在evaluations阶段,设置l = 3, (f1, n1) = (5, 64), (f2, n2) = (3, 32) 和 f3 = 3。参数的选择受到SRCNN的3层9-5-5模型和第2.2节中的方程的启发。在训练阶段,从训练基准图像I_HR中提取17r × 17r像素的子图像,其中r是上采样因子。为了合成低分辨率样本I_LR,我们使用高斯滤波器模糊I_HR,并按上采样因子进行子采样。子图像从原始图像中以
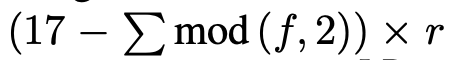
的步长从I_HR和以
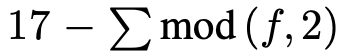
的步长从I_LR中提取。这确保了原始图像中的所有像素在训练数据的基准中只出现一次。我们选择tanh而不是relu作为最终模型的激活函数,这是基于我们的实验结果。
当cost function在100个epoch后没有观察到改善时停止训练。初始学习率设置为0.01,最终学习率设置为0.0001,并且当cost function的改善小于阈值μ时逐渐更新。在K2 GPU上,使用91张图像的训练大约需要三个小时,而使用ImageNet中的图像进行3倍上采样的训练需要七天。我们使用PSNR作为评估我们模型的性能指标。
3.3.图像超分结果
3.3.1 子像素卷积层的好处
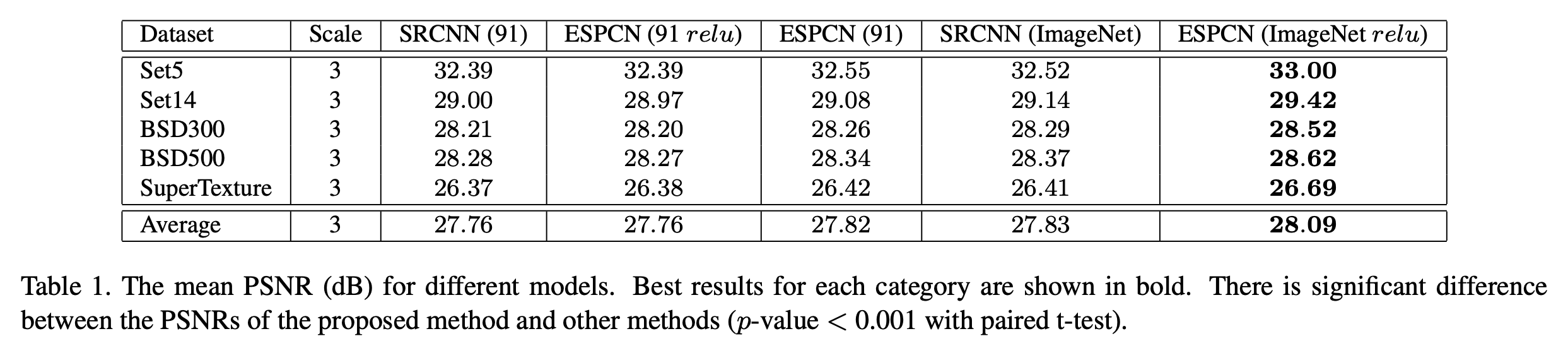
在本节中,我们展示了子像素卷积层以及tanh激活函数的有效性。我们首先通过与SRCNN的标准9-1-5模型进行比较,评估子像素卷积层的能力。在这里,使用relu作为我们模型的激活函数进行实验,并训练了一组使用91张图像的模型,以及另一组使用ImageNet图像的模型。结果下面的Table 1所示。在ImageNet图像上训练的带有relu的ESPCN在统计上显著优于SRCNN模型。值得注意的是,ESPCN (91)的表现与SRCNN (91)非常相似。使用ESPCN训练更多图像对PSNR的影响远大于使用类似参数数量的SRCNN(+0.33对比+0.07)。
为了在我们带有子像素卷积层的模型与SRCNN之间进行视觉比较,我们在下面的Figure 3和Figure 4中将我们的ESPCN (ImageNet) 模型的权重与SRCNN 9-5-5 ImageNet模型进行了对比。我们第一层和最后一层滤波器的权重与设计特征有很强的相似性,包括log-Gabor滤波器、小波和Haar特征。


这句话的意思是,ESPCN模型中第一层和最后一层的滤波器权重与一些设计好的特征提取器有强烈的相似性。这些特征提取器包括:
-
log-Gabor滤波器:这是一种常用于图像处理和计算机视觉的特征提取器,能够捕捉图像中的局部空间频率信息。log-Gabor滤波器因其对尺度和方向的变化具有不变性而被广泛应用。
-
小波(wavelets):小波变换是一种数学方法,用于分析、表示和压缩信号或图像。它通过将信号分解为不同尺度和位置的小波系数来提取信号的特征。
-
Haar特征:这是最早的小波变换形式,由Alfréd Haar在1910年提出。Haar变换通过计算图像块内的平均值和差异来提取特征,常用于图像压缩和模式识别。
这句话强调的是,ESPCN模型的滤波器权重能够捕捉到与这些经典特征提取器相似的图像特征,这表明ESPCN在设计上能够有效地提取图像的重要信息,从而提高图像超分辨率重建的性能。
值得注意的是,尽管每个滤波器在LR空间中是独立的,但我们的独立滤波器在PS之后实际上在HR空间中是平滑的。与SRCNN的最后一层滤波器相比,我们的最后一层滤波器对不同的特征图有复杂的模式,它也有更丰富、更有意义的表示。
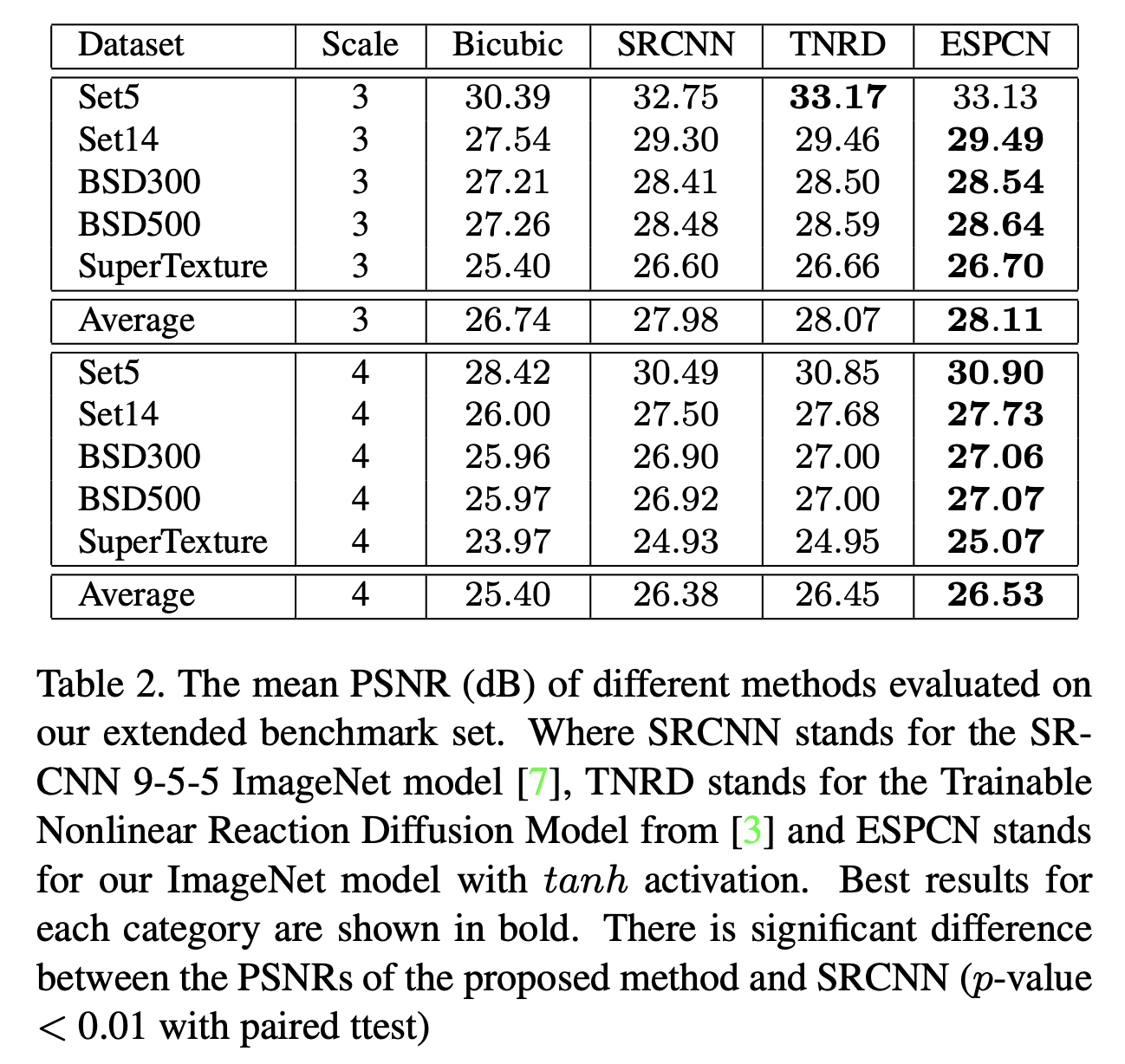
我们还评估了基于上述在91张图像和ImageNet图像上训练的模型的tanh激活函数的效果。Figure 1中的结果显示,对于SISR,tanh函数的表现优于relu。使用tanh激活的ImageNet图像的结果如下面的Tab 2所示。
3.3.2 与目前最优的方法比较
在这一部分,我们展示了在ImageNet上训练的ESPCN与SRCNN和TNRD的结果比较,后者是目前发表的效果最佳方法。为了简便,我们不展示已知比TNRD更差的结果。在这一部分,我们选择与最佳的SRCNN 9-5-5 ImageNet模型进行比较。对于TNRD,结果是基于7×7 5阶段模型计算的。
我们在上面的Tab 2中展示的结果明显优于SRCNN 9-5-5 ImageNet模型,同时接近,甚至在某些情况下超越了TNRD。尽管TNRD使用单一的双三次插值将输入图像上采样到高分辨率空间,但它可能从可训练的非线性函数中受益。超分辨率图像的可视化比较在下面的Figure 5和Figure 6中给出,CNN方法创建了更清晰、对比度更高的图像,ESPCN在SRCNN上提供了明显的改进。


3.4 视频超分结果
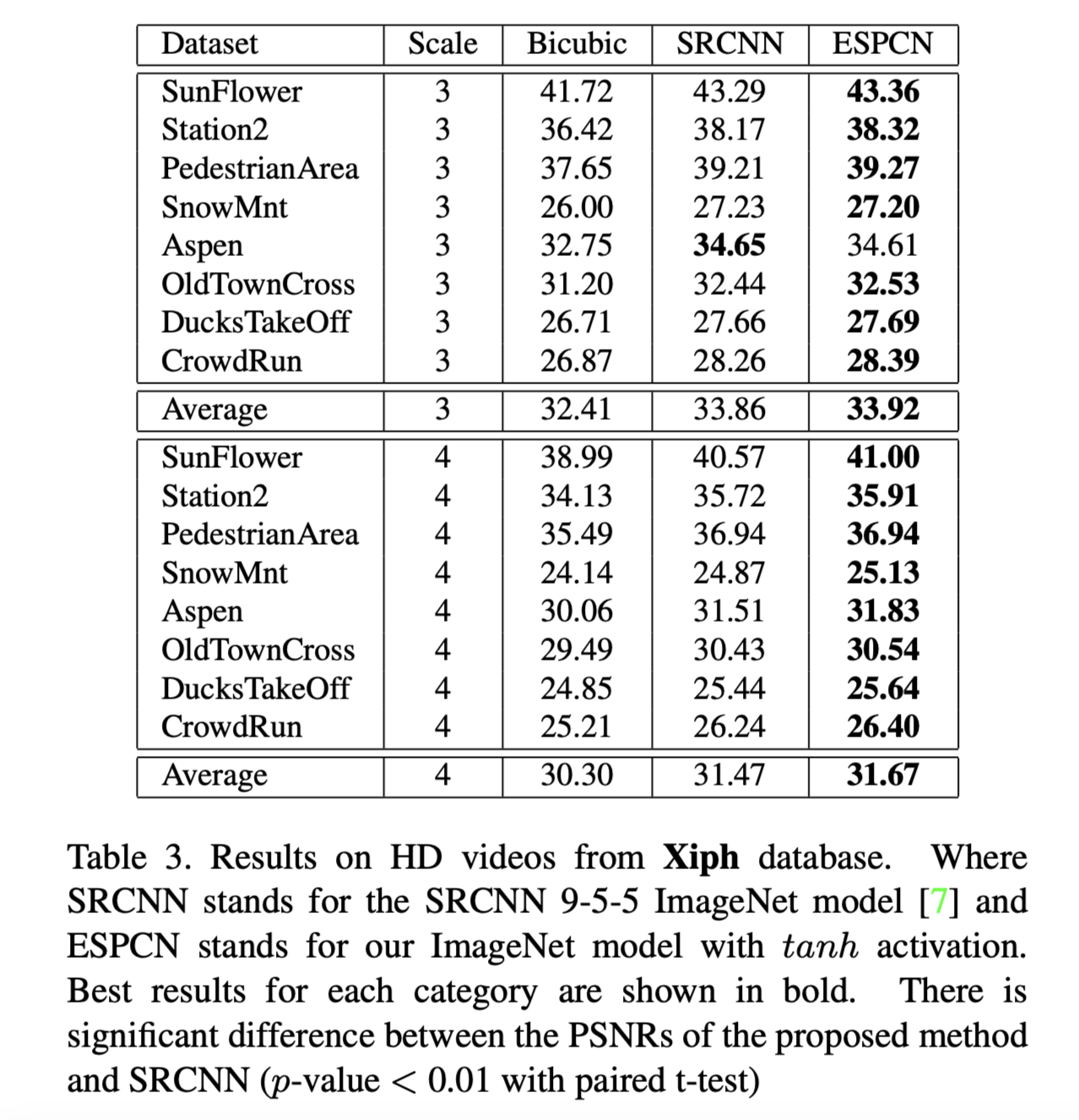
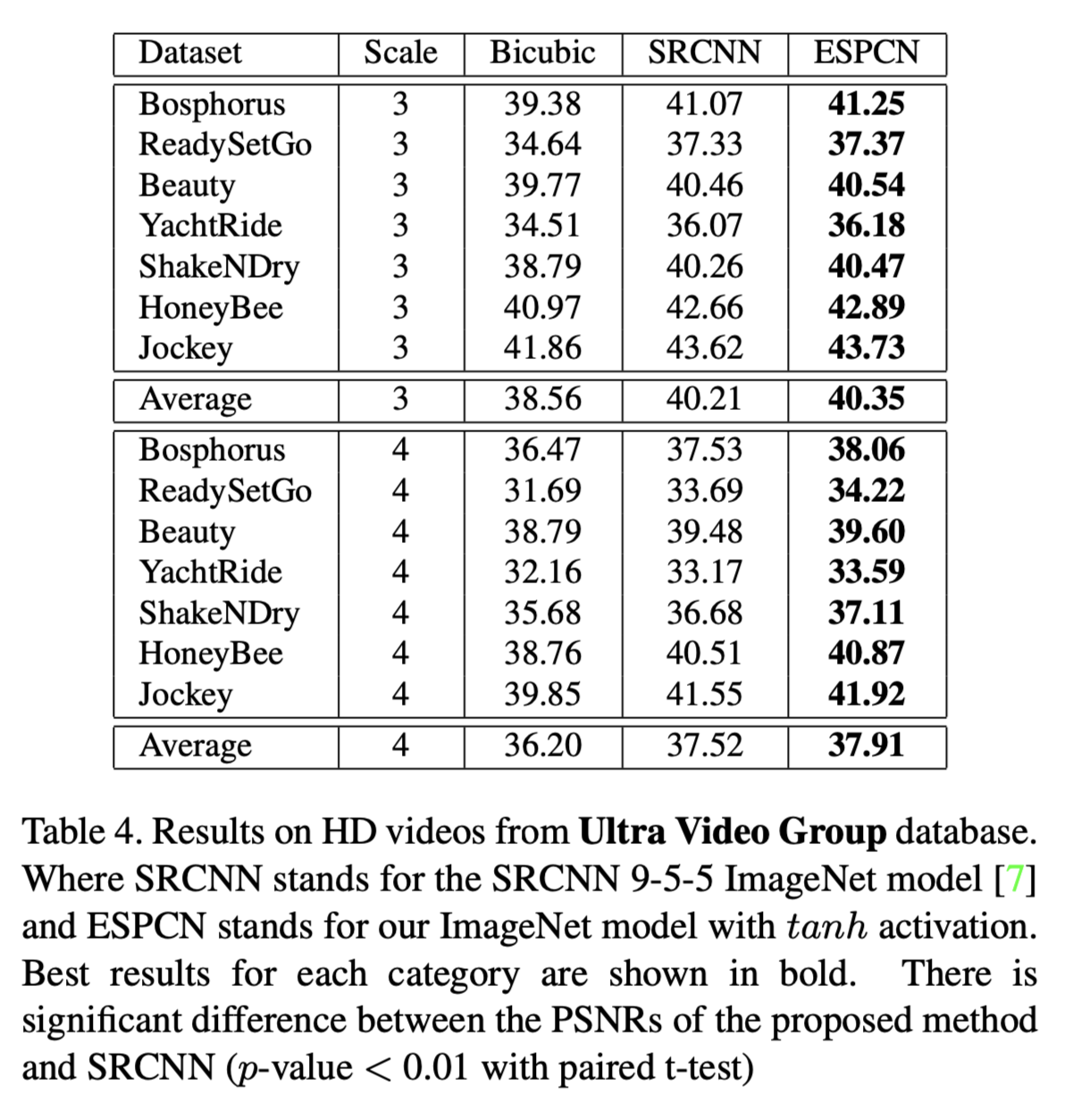
在本节中,我们比较了在两个流行的视频基准测试上训练的ESPCN模型与单帧双三次插值和SRCNN的结果。我们网络的一个巨大优势是其速度。这使得它成为视频超分辨率(SR)的理想选择,允许我们逐帧超分辨率视频。我们在Tab 3和Tab 4中显示的结果优于SRCNN 9-5-5 ImageNet模型。与图像数据上的结果相比,改进更为显著,这可能是由于数据集之间的差异。在图像基准的不同类别中也可以观察到类似的差异,如Set5与SuperTexture的比较。
3.5. 运行时间估计
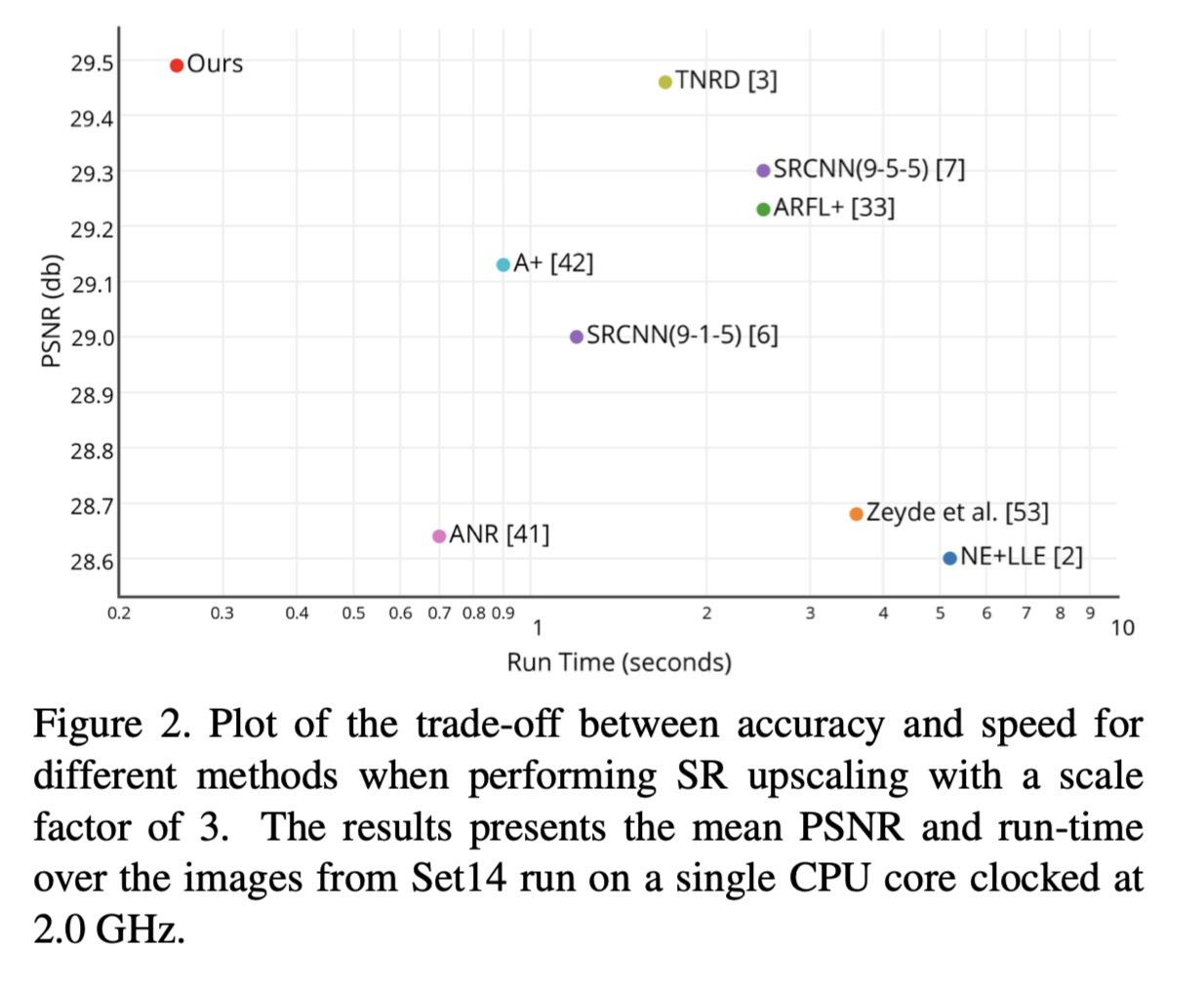
在这一节中,我们评估了我们最佳模型在放大因子为3的Set14数据集上的运行时间。我们从其他一些paper中提供的Matlab代码中评估了其他一些方法的运行时间。对于包括我们自己在内的使用卷积的方法,我们使用基于之前paper提供的Matlab代码,然后使用Python/Theano来实现以提高效率。结果下图的Figure 2中展示。我们的模型运行速度比迄今为止发表的最快方法还要快一个数量级。与SRCNN 9-5-5 ImageNet模型相比,超分辨率一张图像所需的卷积数量是r×r倍少,模型的总参数数量是2.5倍少。因此,超分辨率操作的总复杂度是2.5×r×r倍降低。我们在K2 GPU上实现了惊人的平均速度,仅需4.7毫秒即可超分辨率Set14上的一张单张图像。我们还评估了使用Xiph和Ultra Video Group数据库中的1080高清视频进行超分辨率的运行时间。在放大因子为3时,SRCNN 9-5-5 ImageNet模型每帧需要0.435秒,而我们的ESPCN模型仅需0.038秒。在放大因子为4时,SRCNN 9-5-5 ImageNet模型每帧需要0.434秒,而我们的ESPCN模型仅需0.029秒。
4.总结
在这篇论文中,我们展示了在第一层进行非自适应上采样比自适应上采样在超分辨率图像恢复(SISR)中提供更差的结果,并且需要更多的计算复杂性。为了解决这个问题,我们提出在低分辨率(LR)空间而不是高分辨率(HR)空间进行特征提取阶段。为此,我们提出了一种新颖的子像素卷积层,它能够在训练时以与deconvolution layer相比非常小的额外计算成本将LR数据超分辨率到HR空间。在放大因子为4的扩展基准数据集上进行的评估表明,与具有更多参数的先前CNN方法相比,我们在速度(>10倍)和性能(图像上+0.15dB,视频上+0.39dB)上都有显著提升。这使我们的模型成为第一个能够在单个GPU上实时对高清视频进行超分辨率的CNN模型。
5. 未来工作
在处理视频信息时,一个合理的假设是,大多数场景内容在相邻的视频帧之间是共享的。这一假设的例外情况是场景变化以及物体偶尔出现在场景中或从场景中消失。这创造了额外的数据隐含冗余,可以被利用于视频超分辨率。Spatio-temporal网络因其充分利用视频的时序信息进行人体动作识别而受到欢迎。在未来,我们将研究将我们的ESPCN网络扩展到spatio-temporal网络,使用3D卷积从多个相邻帧中超分辨率一个帧。
时空网络(Spatio-temporal networks,简称STN)是一类特殊的网络,它们在空间结构和/或属性上会随着时间变化。这些网络在许多关键领域都有应用,例如交通网络、电力分配网和移动用户的社会网络。时空网络的建模和计算带来了显著的挑战,因为模型必须在简单性和支持有效算法之间找到平衡。此外,还需要解决图操作语义变化的问题,例如当加入时间维度时,最短路径计算的语义可能会发生变化。此外,由于STN的动态性质,算法设计中使用的范式(例如动态规划)可能因为其假设(例如候选项的静态排名)可能被违反而变得无效。
近年来,时空网络在研究中引起了广泛关注。已经提出了新的表现方式以及算法来执行关键的STN操作,同时考虑到它们的时间依赖性。设计一个STN数据库将需要开发数据模型、查询语言和索引方法,以有效地表示、查询、存储和管理网络的时间变化属性。《Spatio-temporal Networks: Modeling and Algorithms》这本书的目的是探索在概念、逻辑和物理层面的设计。书中探讨并分析了用于表示STN的模型,并解决了STN操作的问题,特别是当加入时间维度时它们语义的变化。
时空卷积网络(Spatio-Temporal Convolutional Networks)是一种深度学习模型,它结合了空间卷积和时间卷积,能够处理视频数据中的时序和空间信息。这种网络通过使用三维卷积核对视频数据进行处理,这个三维卷积核包含了两个空间方向和一个时间方向上的权重。在网络的前向传播过程中,时空卷积核对整个视频序列进行滑动,从而提取出时序和空间上的特征。时空卷积网络在视频分析、动作识别和人体姿态估计等任务中取得了显著的成果,并且随着深度学习技术的不断发展,它们在更多领域展现出强大的能力。
时空图卷积网络(Spatio-temporal Graph Convolutional Networks)是一种用于交通流量预测的深度学习框架。与传统的卷积和循环单元不同,该框架在图上构建模型,使用完整的卷积结构,这使得训练速度更快,参数更少。实验表明,该模型能够通过模拟多尺度交通网络来有效地捕捉全面的时空相关性,并且在各种真实世界的交通数据集上一致性地超越了最先进的基线。
时空网络的研究和应用正在不断发展,它们在处理时空数据方面展现出了巨大的潜力和价值。随着研究的深入,这些网络模型有望在更多领域得到应用,并为我们带来更多的惊喜和突破。



















