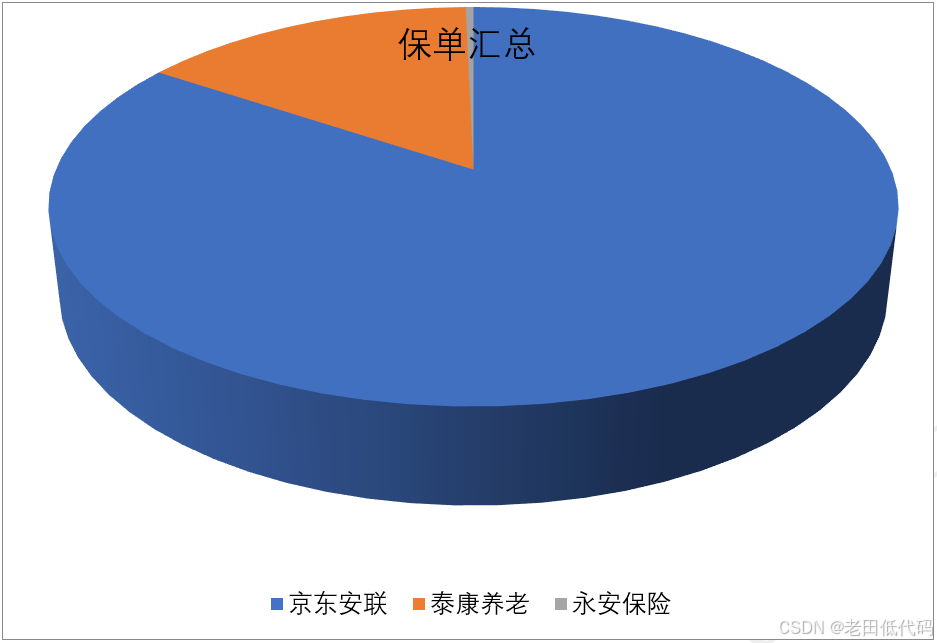
7.1 贝叶斯决策论
贝叶斯决策论(Bayesian decision theory)是概率框架下实施决策的基本方
法.对分类任务来说,在所有相关概率都已知的理想情形下,贝叶斯决策论考虑
如何基于这些概率和误判损失来选择最优的类别标记.下面我们以多分类任务
为例来解释其基本原理.

贝叶斯判定准则:

此时,h称为贝叶斯最优分类器(Bayes optimal classifier),与之对应的总体风
险R(h)称为贝叶斯风险(Bayes risk). 1 -R(h*)反映了分类器所能达到的最
好性能,即通过机器学习所能产生的模型精度的理论上限.


7.2 生成式模型和判别式模型

在对数几率回归中,是最大化极大似然估计,就是希望它每个样本就分类正确的话,算这样的损失,然后最小化这个损失。这个就是贝叶斯决策论的这个角度

显然,前面介绍的决策树、B P 神经网络、支持向量机等,都可归入判别式模型的范畴.

归一化就是要把需要处理的数据经过处理后(通过某种算法)限制在你需要的一定范围内。 首先归一化是为了后面数据处理的方便,其次是保证程序运行时收敛加快。 归一化的具体作用是归纳统一样本的统计分布性。 归一化在0-1之间是统计的概率分布,归一化在某个区间上是统计的坐标分布。
类先验概率P©表达了样本空间中各类样本所占的比例,根据大数定律,当训练集包含充足的独立同分布样本时,P©可通过各类样本出现的频率来进行估计.
对类条件概率P(x|c)来说,由于它涉及关于x 所有属性的联合概率,直接根据样本出现的频率来估计将会遇到严重的困难.例如,假设样本的d个属性都是二值的,则样本空间将有2^d种可能的取值,在现实应用中,这个值往往远大于训练样本数m,也就是说,很多样本取值在训练集中根本没有出现,直接使用频率P(x|c)来估计显然不可行,因为“未被观测到”与 “出现概率为零”通常是不同的
条件概率、全概率、先验概率、后验概率、类条件概率
如果我们把事件A看做 “结果”,把诸事件B1,B2…看做导致这个结果的可能的“原因”,则可以形象地把全概率公式看做成为“由原因推结果”。 而贝叶斯公式则恰好相反,其作用于“由结果推原因”:现在有一个“结果”A以发生,在众多可能的“原因”中,到底是哪一个导致了这结果。
举个例子:
桌子上如果有一块肉喝一瓶醋,你如果吃了一块肉,然后你觉得是酸的,那你觉得肉里加了醋的概率有多大?你说:80%可能性加了醋。OK,你已经进行了一次后验概率的猜测。

7.3 朴素贝叶斯分类器
基于有限训练样本直接估计联合概率,在计算上将会遭遇组合爆炸问题,在数据上将会遭遇样本稀疏问题;属性数越多,问题越严重
不难发现,基于贝叶斯公式(7.8)来估计后验概率P(x|c)的主要困难在于:
类条件概率P(x|c)是所有属性上的联合概率,难以从有限的训练样本直接
估计而得.为避开这个障碍,朴素贝叶斯分类器(naive Bayes classifier)采用了
“属性条件独立性假设 " (attribute conditional independence assumption): 对
已知类别,假设所有属性相互独立.换言之,假设每个属性独立地对分类结果发
生影响.
带你理解朴素贝叶斯分类算法


显然,朴素贝叶斯分类器的训练过程就是基于训练集D 来估计类先验概率
P©,并为每个属性估计条件概率P(x_i|c)
若有充足的独立同分布样本(也就是说这里是基于 大数定律 的),则可容易地估计出 类先验概率:

以下这个 条件概率 也是基于 大数定律 的

7.4 半朴素贝叶斯分类器
为了降低贝叶斯公式(7.8)中估计后验概率P(c|x)的困难,朴素贝叶斯分类器采用了属性条件独立性假设,但在现实任务中这个假设往往很难成立.于是,人们尝试对属性条件独立性假设进行一定程度的放松,由此产生了一类称为 “半朴素贝叶斯分类器“的学习方法.
半朴素贝叶斯分类器的基本想法是适当考虑一部分属性间的相互依赖信
息,从而既不需进行完全联合概率计算,又不至于彻底忽略了比较强的属性依
赖关系.“独依赖估计" (One-Dependent Estimator,简称ODE)是半朴素贝叶
斯分类器最常用的一种策略.顾名思议,所谓“独依赖”就是假设每个属性在
类别之外最多仅依赖于一个其他属性,即
(类条件概率 因此,类别必须考虑)





![[Golang] goroutine](https://img-blog.csdnimg.cn/img_convert/38ccad396f4a1b4fba9f26f49e0db2a0.png)