书接上文GaussDB关键技术原理:高弹性(三)从段页式技术方面对GaussDB高弹性能力进行了解读,本篇将从hashbucket扩容方面继续介绍GaussDB高弹性技术。
4 hashbucket扩容
基于hashbucket表的扩容整体流程主要包含三个步骤:
-
基线数据搬迁:生成扩容搬迁计划,根据搬迁计划中对涉及的库中的bucket文件进行跨节点文件搬迁。包含库级别的数据文件和实例级别的事务日志。
-
bucket日志流追增:识别bucket扩容过程中的增量修改,将对应的日志发送到目的节点并在目的端进行增量修改的日志回放。
-
bucket元数据切换:当bucket日志流追增完成后,原节点和目的节点的bucket数据达到一致状态,可以对原节点的bucket进行下线删除,对目的节点的bucket进行上线操作,同时修改CN上的bucket map映射使新的业务能够路由到正确的DN节点。
如下图1所示以DN节点2扩3为例描述hashbucket扩容的详细流程:
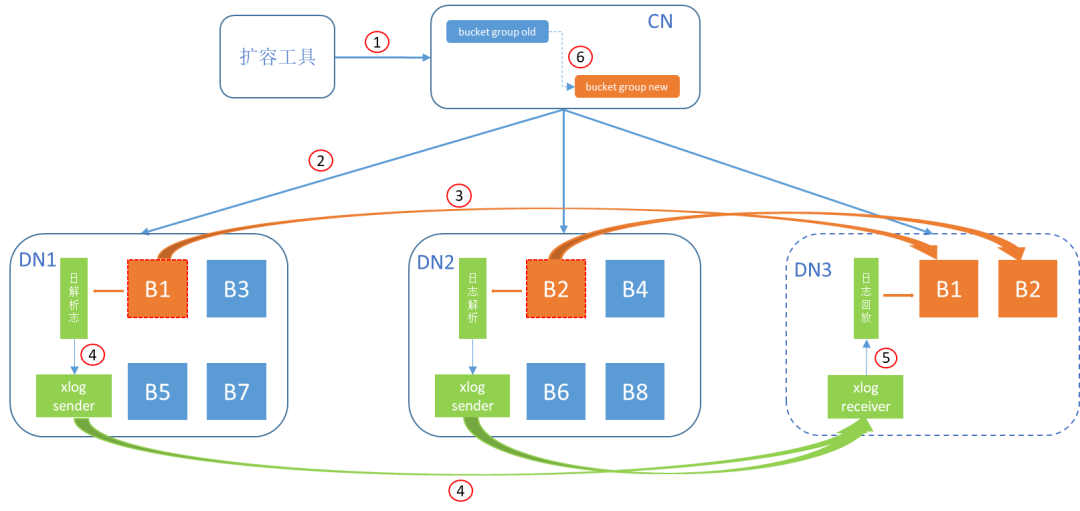
图1 hashbucket扩容流程(以DN由2扩3为例)
(1) CN从扩容工具测处收到MOVE BUCKETS搬迁命令;
(2) CN解析后分别给DN1、DN2、DN3(目标DN)下发搬迁命令;
(3) DN1/DN2将迁移bucket目录(包含数据及事务日志)拷贝到目标DN3上;
(4) DN3收到命令后,进入receiver逻辑,与DN1/DN2建立连接,DN1/DN2进入sender逻辑,将相关bucket的日志解析出来发送给DN3;
(5) bucket目录拷贝完成后,DN3回放收到的bucket日志,进行追增;
(6) 完成最后一轮的追增后CN上切换bucket group,DN1/DN2上的旧bucket进行清除。
4.1 扩容流程框架
本节详细介绍hashbucket扩容流程框架,其主流程在gs_redis_bucket工具中实现,主要包括扩容迁移计划、扩容期间元数据处理、扩容状态与统计信息、扩容上线策略等部分。
进入重分布流程首先做一些前置处理,从系统表读取并设置重分布参数,以便后续扩容流程使用。在内核中记录本次重分布的database信息,以便后续解析日志使用。调用CHECKPOINT进行一次刷盘,作为后续日志回放的起始点。
4.1.1 获取扩容迁移计划
介绍扩容迁移计划前首先介绍NodeGroup相关概念。PGXC_GROUP系统表存储节点组信息,其每一行均为一个NodeGroup相关信息,其中与扩容迁移计划相关的字段如表1所示。
表1 系统表PGXC_GROUP部分字段
| 名称 | 类型 | 描述 |
| oid | oid | 行标识符(隐含字段,必须明确选择)。 |
| group_name | name | 节点组名称。 |
| in_redistribution | "char" | 是否需要重分布。取值包括n,y,t。 n:表示NodeGroup没有再进行重分布。 y:表示NodeGroup是重分布过程中的源节点组。 |
| group_members | oidvector_extend | 节点组的节点OID列表。 |
| group_buckets | text | 分布数据桶所在节点编号的集合。 |
| is_installation | boolean | 是否安装子集群。 t(true):表示安装。 f(false):表示不安装。 |
| bucket_map | text | 物理bucket与逻辑bucket的映射关系。 |
首先介绍物理bucket和逻辑bucket的概念。GaussDB中数据分布在16384个bucket中,记为逻辑bucket。为减少文件数量过多资源浪费问题,引入物理bucket概念,DN内部存储采用物理1024个bucket。如图2所示为3DN集群的物理逻辑bucket映射关系示意图,每一个方格代表一个逻辑bucket,用 ',' 分隔;每一行代表一个物理bucket,用 ';' 分隔;同一行的逻辑bucket组成一个物理bucket。
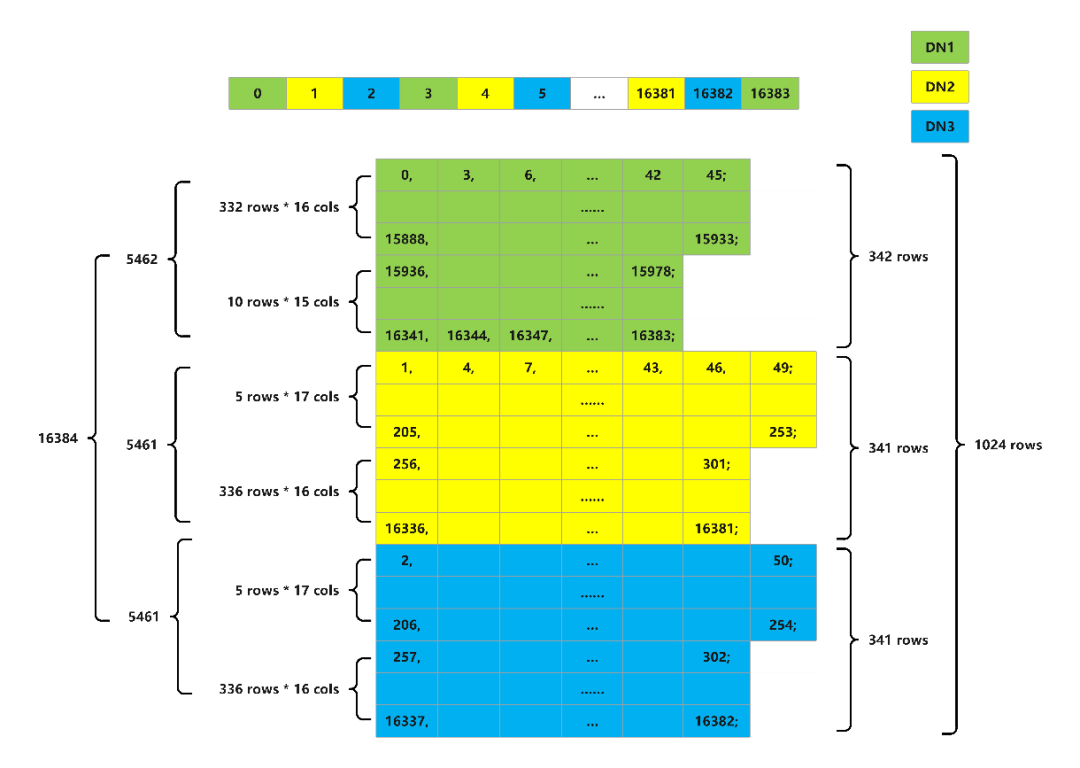
图2 物理逻辑bucket映射关系示意图
group_buckets为一个16384长度的数组,表示每个逻辑bucket所在节点的编号,可以表示数据在节点上的分布。工具根据当前绑定NodeGroup与目标NodeGroup中bucket分布(group_buckets)的差异,即可计算出所有需要迁移的buckets。再将这些待迁移的bucket按照扩容链路(即从哪个原DN迁移到哪个新DN)分类,即可得到迁移计划。图3为2DN扩3DN的搬迁计划与bucket分布示意图。
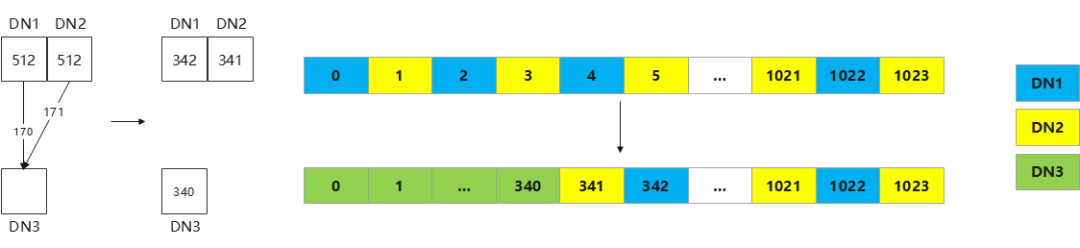
图3 2DN扩3DN迁移计划与bucket分布示意图
4.1.2 扩容主流程相关线程
在获取迁移计划后,工具开始当前database的扩容主流程。扩容重分布过程涉及gs_redis_bucket工具的三个线程:主线程、监控线程、上线事务线程。图4为gs_redis_bucket工具中扩容流程相关线程示意图。
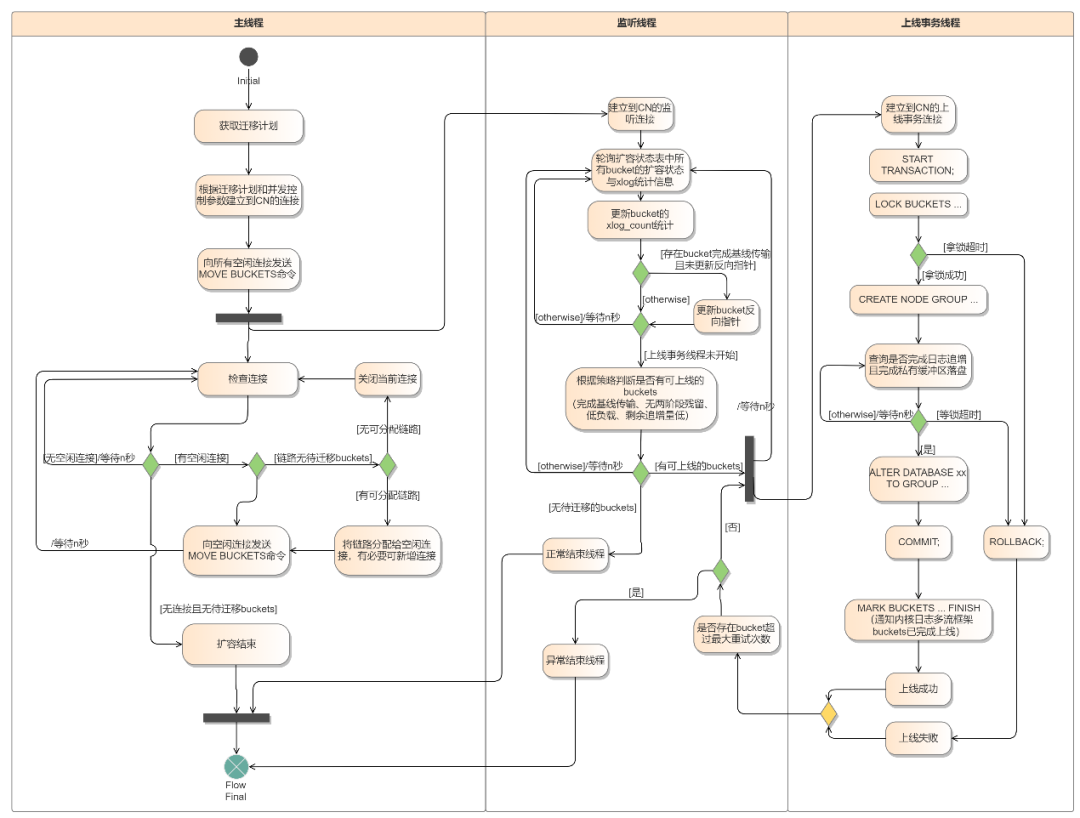
图4 扩容流程工具相关线程示意图
(1)主线程根据迁移计划向内核发送MOVE BUCKETS命令,其格式为:
ALTER DATABASE database_name MOVE BUCKETS (bucket_list) FROM sender_dn TO receiver_dn;例如:
ALTER DATABASE my_database MOVE BUCKETS (0,1,2) FROM dn_6001_6002_6003 TO dn_6010_6011_6012;MOVE BUCKETS命令是hashbucket扩容重分布的核心命令,完成了基线数据搬迁和日志追增,MOVE BUCKETS命令在内核中的实现详见“日志多流”小节。
其中单次MOVE BUCKETS命令搬迁bucket的个数(即bucket_list长度)越小对业务影响越小。同时为降低扩容重分布对业务的影响,sender DN和receiver DN的并发度均为1,即sender DN同一时刻最多只能处理一条MOVE BUCKETS语句,receiver DN同一时刻最多只能处理一条MOVE BUCKETS语句。
主线程根据迁移计划与内核建立连接链路并发送MOVE BUCKETS命令,当有MOVE BUCKETS执行完毕退出后,主线程会检查是否可以发送新的MOVE BUCKETS命令(优先继续发送原链路剩余的buckets;如原链路已发送完毕,则选择新链路发送),直到迁移计划中的所有bucket全部通过MOVE BUCKETS命令完成迁移。
以2DN扩5DN为例,其扩容计划可以用下图来简要表示。假设当前设置单次搬迁个数为150,则主线程会首先发送【DN1àDN3, (0,1,…,149)】与【DN2àDN4, (512,513,…,614)】到内核(此时另外两条链路由于并发度限制无法发送)。假设第一条命令首先执行完毕返回,由于此时该链路上还有剩余buckets,因此会继续发送【DN1àDN3, (150,151,…,204)】。假设【DN2àDN4】命令随后执行完毕返回,由于该链路所有bucket已发送完毕,则选择新链路命令【DN2àDN5, (615,616,…,764)】发送(此时【DN1àDN4】不满足DN1并发度限制)。
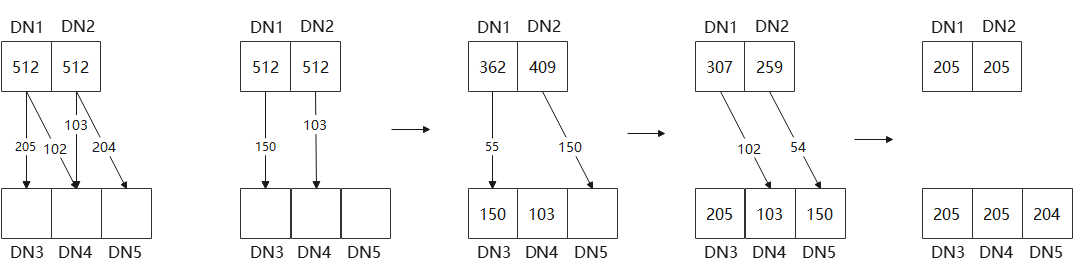
图5 2DN扩5DN迁移计划示意图
需要注意的是,MOVE BUCKETS命令并不会自行结束返回,需要与上线事务线程配合,等待该命令中的所有BUCKETS完成迁移并上线后才会返回。
(2)监控线程由主线程创建,在主线程发送MOVE BUCKETS命令后开始运行。其主要任务有二:一是通过调用扩容统计信息函数定期轮询(1s)监测每个bucket的迁移状态和业务负载等信息;二是根据上线策略判断是否有某些bucket处于可上线状态(见“扩容上线策略”部分),若是,则创建上线事务线程进完成这些bucket的新节点上线。当全部bucket均已上线时退出监控线程。
(3)上线事务线程在监控线程判断某些bucket可以进行上线时由监控线程创建,用于完成上述bucket的上线步骤。
首先获取这些待上线的bucket的bucket锁(详见“bucket锁”小节),阻塞相应bucket上的所有业务,确保没有增量日志产生,然后完成最后的日志追增且保证回放数据全部落盘,最后切换NodeGroup完成上述buckets上线。
在上线事务线程中,可能会出现两种异常场景导致上线失败:拿锁超时与持锁超时。拿锁超时指的是在给定时间阈值内无法成功拿到bucket级锁而终止此次上线;持锁超时指的是在拿到bucket级锁之后在给定时间阈值内无法完成日志追增与私有缓冲区落盘,为避免长时间阻塞业务而终止此次上线。
若出现拿锁超时或持锁超时,上线事务线程会退出,此时监控线程将对这一事件进行记录。对于这些bucket将被惩罚在一段时间内不再尝试上线(见“扩容上线策略”部分)。进一步地,当存在bucket超过最大拿锁超时次数或持锁超时次数时,gs_redis_bucket将主动退出自动重入。
对于上线事务线程的LOCK BUCKET语句,如果参数enable_cancel设置为true且存在至少一个bucket的拿锁超时的次数或持锁超时的次数不小于相应最大超时次数的1/2(向下取整),则LOCK BUCKETS语句将添加CANCELABLE关键字,会尝试主动取消业务。如果参数enable_cancel设置为false,则LOCK BUCKETS语句永远不会添加CANCELABLE关键字。
4.1.3 扩容期间元数据处理
(1) 更新SegmentHeader
hashbucket扩容方案中,新DN是由CN build出来的,新DN上hashbucket表元数据在新DN 大段页式1号文件中的类型是SegmentHead且没有对应小段页式1号文件SegmentHead所在的页号,无法进行对应bucket的数据管理。且新DN上hashbucket表在pg_class中的relbucket列为1而不是3,需要在日志回放前统一修改元数据支持扩容。
(2) 更新反向指针
hashbucket表扩容后新DN上小段页式数据文件中SegmentHead反向指针记录所属的owner可能不正确,应该修改为新DN主表的relfilenode。在扩容工具gs_redis_bucket中,某一批bucket上线前执行更新操作。更新的方式特殊处理,从新DN获取hashbucket表的relfilenode作为反向指针的owner,在源DN执行更新操作,只记录XLOG不实际更新,通过日志流的方式同步到新DN。新DN通过日志回放,完成反向指针更新。
4.1.4 扩容状态与信息统计
gs_redis_bucket通过gs_redis_get_bucket_statistics(扩容统计信息)系统函数在扩容期间查询每个bucket的迁移状态与业务负载情况,系统函数返回值如下表所示。
表2 扩容统计信息函数返回值
| 名称 | 类型 | 描述 |
| bucket_id | OID | bucket id |
| redis_state | INT1 | bucket的扩容状态,0表示扩容未开始,1表示扩容基线数据已完成。 |
| xlog_count | INT8 | bucket在当前database扩容开始后,在原DN产生的XLOG数量。 |
| sndr_latest_lsn | INT8 | bucket在当前database扩容开始后,在原DN产生的最新LSN。 |
| parser_latest_lsn | INT8 | bucket在当前database扩容开始后,被原DN的扩容相关线程解析到的最新LSN。 |
| parser_latest_lsn_new | INT8 | bucket在当前database扩容开始后,被原DN的扩容相关线程解析到bucketxlog的最新LSN。 |
| rcvr_redo_latest_lsn | INT8 | bucket在当前database扩容开始后,被新DN的扩容相关线程回放到的最新LSN。 |
| rcvr_redo_latest_lsn_new | INT8 | bucket在当前database扩容开始后,被原DN的扩容相关线程解析到bucketxlog的最新LSN。 |
| rcvr_checkpoint | INT8 | bucket在当前database扩容开始后的CHECKPOINT点。 |
| rcvr_redo_start_lsn | INT8 | bucket在当前database扩容开始后,回放开始的原始LSN。 |
上述扩容相关信息在GaussDB内核中的全局变量中存储与更新。gs_redis_bucket通过在定时轮询扩容统计信息系统函数来获取各bucket的以上信息。redis_state字段可以用来指示当前bucket是否完成基线迁移;xlog_count字段的值随时间的变化可以反映当前bucket的业务负载情况;而LSN相关字段则可以反映当前bucket的日志追增情况。
具体来说,bucket的日志追增剩余量由两部分组成:第一部分为sndr_latest_lsn到parser_latest_lsn的差值,该部分对应原DN的parser线程尚未解析的日志;第二部分为parser_latest_lsn_new到rcvr_redo_latest_lsn_new,该部分对应原DN的parser线程已解析但尚未被新DN回放的日志。需要说明的是,parser_latest_lsn_new与rcvr_redo_latest_lsn_new是为日志多流传输框架要传输的bucket日志流封装的一层新LSN,以过滤掉其他bucket或非bucket模式的日志。以上信息可以帮助判断bucket的上线时机并检验bucket是否完成日志追增。
4.1.5 扩容上线策略
扩容上线策略主要用来在监控线程中判断哪些bucket在扩容期间进入日志追增阶段后可以准备上线。可以准备上线的buckets需要满足以下四个条件:已完成基线搬迁且已执行更新反向指针操作、处于业务低负载时间、日志追增框架剩余追增量小、bucket不在上次上线失败后的惩罚时间内。
(1) bucket是否已完成基线搬迁通过扩容统计信息系统函数返回的redis_state获取,其值会在receiver端完成基线文件传输后赋值,便于判断元数据处理的时机。此外,bucket还需要在监控线程基线传输完成后完成更新反向指针的操作。
(2) bucket是否处于业务低负载时间通过记录每个bucket的历史负载来判断。扩容上线策略在监控线程中定期轮询所有扩容中的buckets的统计信息(即xlog_count)并记录。因此,监控线程可以掌握每个bucket在扩容期间的历史负载情况。由于bucket上线需要对其上锁,为减小对业务的影响,扩容上线策略应当尽量选择在bucket低历史负载期间进行上线操作。
(3) 日志剩余追增量通过统计信息系统函数返回的LSN相关字段来计算,即(parser_latest_lsn - sndr_latest_lsn) + (rcvr_redo_latest_lsn_new - parser_latest_lsn_ new)。当追增量小于给定阈值时,判断其满足条件。
(4) 若当前bucket在此前的上线事务线程中由于拿锁超时或持锁超时而终止上线,则会为该bucket指定一段惩罚时间,在惩罚时间内不允许该bucket上线。
监控线程的上线策略在上线事务线程未在运行时选择满足上述(1)-(4)条件的所有buckets,并创建上线事务线程完成这些buckets的上线,上线事务线程会完成这些buckets的上线。随后监控线程会继续选择新的满足上线策略的buckets,并再次创建上线事务线程完成新一轮的上线,重复动作直到所有buckets均上线完成。
以上内容从hashbucket扩容技术方面对GaussDB高弹性能力进行了解读,下篇将从日志多流和事务相关方面继续介绍GaussDB高弹性技术,敬请期待!