这是我的第353篇原创文章。
一、引言
Super learner 是 Vander Laan et al.(2007)提出的一种基于损失函数的组合预测的学习算法。Super learner算法基于交叉验证理论,通过加权的方式组合多种候选算法,从而构造一种最小交叉验证风险的算法组合。
Super learner 算法的基本步骤可以归纳为:
-
首先,随机将数据集分为 k 组,本文的 k 为 5,然后选择不同的预测算法。
-
然后遍历每一种算法用于训练集数据,计算在验证集上的发病概率 S。
-
在验证集中,通过事件结局和发病概率计算风险,于是得到每一种算法的平均预测风险。
-
加权不同的预测算法进行组合,更新权重 α 从而得到最小交叉验证风险的算法组合。
-
最后在完整的数据集中拟合每个预测算法,构建 super learner 模型。
二、实现过程
1、准备数据
data = pd.read_csv(r'Dataset.csv')
df = pd.DataFrame(data)df:
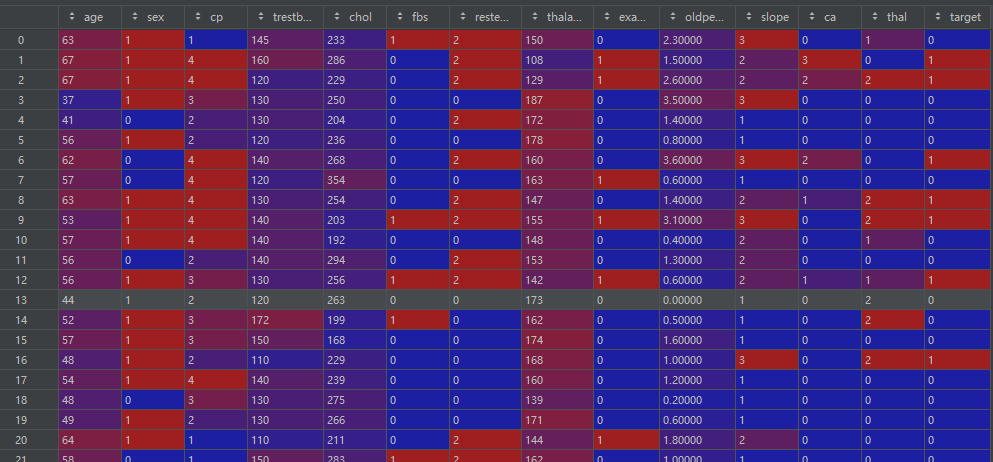
数据基本信息:
print(df.head())
print(df.info())
print(df.shape)
print(df.columns)
print(df.dtypes)
cat_cols = [col for col in df.columns if df[col].dtype == "object"] # 类别型变量名
num_cols = [col for col in df.columns if df[col].dtype != "object"] # 数值型变量名2、提取特征变量和目标变量
target = 'target'
features = df.columns.drop(target)
print(data["target"].value_counts()) # 顺便查看一下样本是否平衡3、数据集划分
X_train, X_test, y_train, y_test = train_test_split(df[features], df[target], test_size=0.2, random_state=0)
X_train = np.array(X_train)
y_train = np.array(y_train)
X_test = np.array(X_test)
y_test = np.array(y_test)4、归一化
# 此步骤略过5、模型的构建与训练
# 模型的构建与训练
model = SuperLearnerClassifier()
model.fit(X_train, y_train)6、模型的推理与评价
# 模型推理与评价
y_pred = model.predict(X_test)
y_scores = model.predict_proba(X_test)
acc = accuracy_score(y_test, y_pred) # 准确率acc
cm = confusion_matrix(y_test, y_pred) # 混淆矩阵
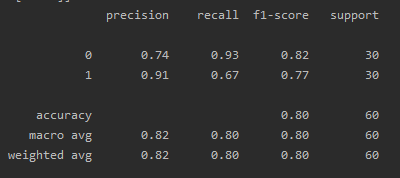
cr = classification_report(y_test, y_pred) # 分类报告
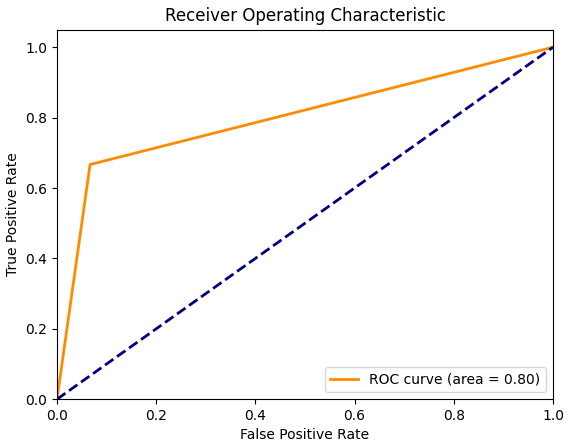
fpr, tpr, thresholds = roc_curve(y_test, y_scores[:, 1], pos_label=1) # 计算ROC曲线和AUC值,绘制ROC曲线
roc_auc = auc(fpr, tpr)
plt.figure()
plt.plot(fpr, tpr, color='darkorange', lw=2, label='ROC curve (area = %0.2f)' % roc_auc)
plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver Operating Characteristic')
plt.legend(loc="lower right")
plt.show()cm:
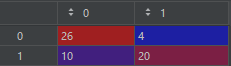
cr:
ROC:
作者简介:
读研期间发表6篇SCI数据挖掘相关论文,现在某研究院从事数据算法相关科研工作,结合自身科研实践经历不定期分享关于Python、机器学习、深度学习、人工智能系列基础知识与应用案例。致力于只做原创,以最简单的方式理解和学习,关注我一起交流成长。需要数据集和源码的小伙伴可以关注底部公众号添加作者微信。