欢迎来到雲闪世界。我希望在我还是初学者时能有一份循序渐进的实践指南
数据可观测性及其重要性经常被讨论和撰写为现代数据和分析工程的一个重要方面。市场上有许多工具,具有各种功能和价格。在这篇由两部分组成的文章中,我们将重点介绍 Elementary 的开源版本,它是这些数据可观测性平台之一,专为 dbt 量身定制并旨在与 dbt 无缝协作。我们将从零开始设置,并力求在第 2 部分结束时了解它的工作原理以及在不同数据场景中可能实现的功能。在开始之前,我还想透露一下,我与 Elementary 没有任何关系,所有表达的观点均为我个人观点。 在第 1 部分中,我们将设置 Elementary 并检查如何读取 Elementary 的每日报告。
我已经使用 Elementary 很长一段时间了,作为一名数据工程师,我的经验是积极的,至于我的团队如何构思结果。我们的团队使用 Elementary 通过自托管的 elementary 仪表板进行自动日常监控。作为付费产品,Elementary 还有一个非常方便的云平台,但开源版本对我们来说已经足够了。如果您想探索差异以及开源中缺少哪些功能,elementary在这里比较了这两种产品。让我们首先设置开源版本。
-
如何安装 Elementary
安装 Elementary 与在 dbt 项目中安装任何其他包一样简单。只需将以下内容添加到您的packages.yml文件中即可。如果您还没有,您可以创建一个packages.yml与您的文件同级的文件dbt_project.yml。包本质上是另一个 dbt 项目,由可合并到您的 dbt 项目中的附加 SQL 和 Jinja 代码组成。
packages:
- package: elementary-data/elementary
version: 0.15.2
## you can also have different minor versions as:
## version: [">=0.14.0", "<0.15.0"]
## Docs: https://docs.elementary-data.com我们希望 Elementary 拥有自己的模式来编写输出。在文件中dbt_project.yml,我们在模型下为 Elementary 定义模式名称。如果您使用的是 dbt Core,默认情况下,所有 dbt 模型都构建在配置文件目标中指定的模式中。根据您定义自定义模式的方式,模式将被命名elementary为<target_schema>_elementary. 模型:
models:
## see docs: https://docs.elementary-data.com/
elementary:
## elementary models will be created in the schema 'your_schema_elementary'
+schema: "elementary"
## If you dont want to run Elementary in your Dev Environment Uncomment following:
# enabled: "{{ target.name in ['prod','analytics'] }}"从 dbt 1.8 开始,dbt 不再支持已安装软件包在未经用户明确选择的情况下覆盖内置实现的功能。此更改会导致一些基本功能崩溃,因此需要在 dbt_project.yml 文件中与模型同级别的标志部分下添加一个标志。
flags:
require_explicit_package_overrides_for_builtin_materializations: True最后,为了使 Elementary 正常运行,它需要连接到您的 dbt 项目使用的相同数据仓库。如果您有多个开发环境,Elementary 会确保 dbt 连接到这些仓库的方式与 Elementary 连接到它们的方式保持一致。这就是为什么 Elementary 需要在您的profiles.yml文件中指定配置的原因。
elementary:
outputs:
dev:
type: bigquery
method: oauth
project: dev
dataset: elementary
location: EU
priority: interactive
retries: 0
threads: 4
pp:
type: bigquery
method: oauth # / service-account
# keyfile : [full path to your keyfile]
project: prod # project_id
dataset: elementary # elementary dataset, usually [dataset name]_elementary
location: EU # [dataset location]
priority: interactive
retries: 0
threads: 4以下代码在 dbt 项目中运行后也会为您生成配置文件:
dbt run-operation elementary.generate_elementary_cli_profile最后,通过运行以下命令安装 Elementary CLI:
pip install elementary-data
# you should also run following for your platform too, Postgres does not requiere this step
pip install 'elementary-data[bigquery]' -
基本工作原理如何?
现在,希望 Elementary 能够处理您的 dbt 项目,了解 Elementary 的运作方式也很有用。本质上,Elementary 通过利用 dbt 运行期间生成的 dbt 工件来运行。这些工件(例如manifest.json、run_results.json和其他日志)用于收集详细的模型元数据、跟踪模型执行和评估测试结果。Elementary 集中这些数据以提供管道性能的全面视图。然后,它会根据分析生成报告并生成警报。
-
如何使用基本
简单来说,如果您想创建一份通用的基本报告,以下代码将生成一份 HTML 文件形式的报告: edr 报告 在您的 CLI 上,这将使用我们在前面步骤中提供的连接配置文件访问您的数据仓库。如果基本配置文件没有定义默认目标名称,它将抛出一个错误,为了避免错误,您也可以--profile-target <target_name>在终端上运行时将其作为变量提供。 一旦 Elementary 运行完成,它会自动将基本报告以 HTML 文件形式打开。
添加图片注释,不超过 140 字(可选)
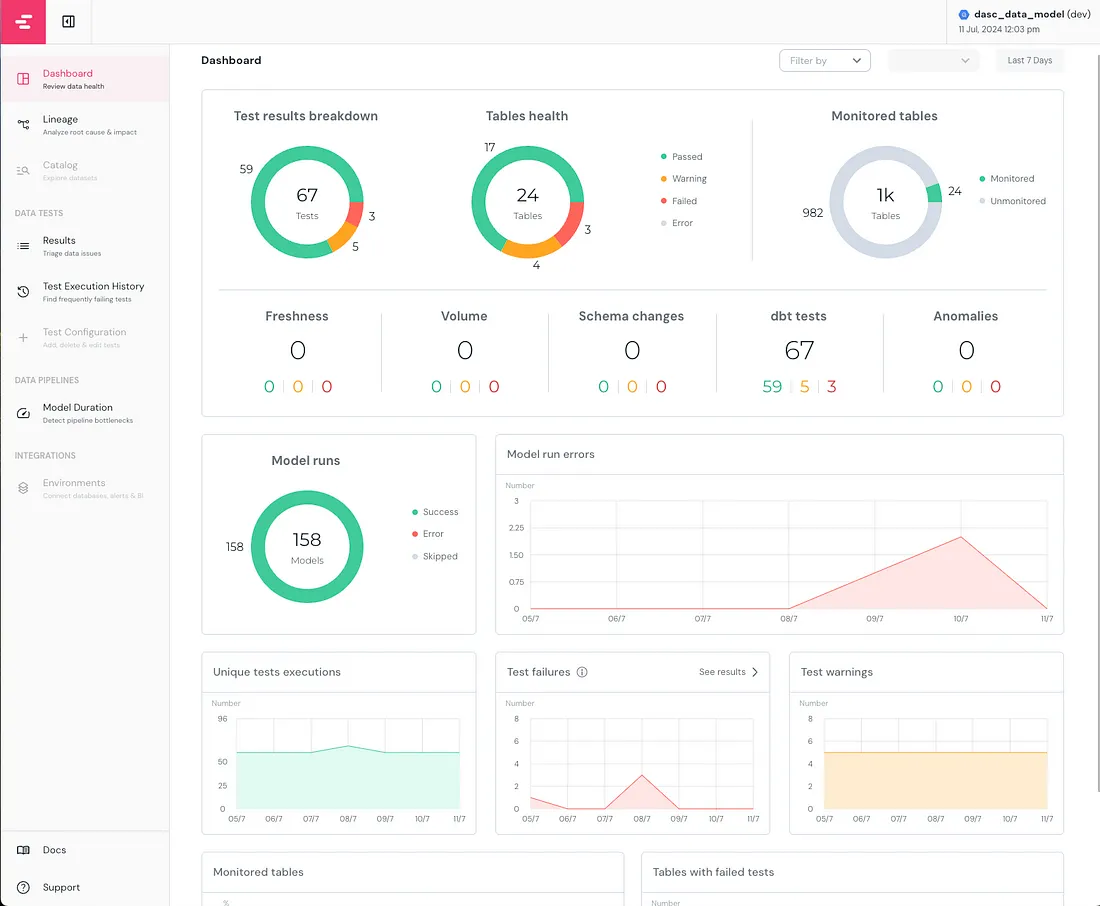
在仪表板的左侧,您可以看到不同的页面,仪表板页面全面概述了 dbt 项目的性能和状态。目录和测试配置页面仅在 Elementary Cloud 中可用,但这些配置也可以在 OSS 版本中手动实现,第 2 部分将更详细地解释。
-
如何阅读本报告?
在此示例报告中,我特意为本文预先创建了警告和错误。总共运行了 67 个测试,其中 3 个失败,5 个发出警告。我监控了 24 个表,所有配置和检查的测试都是 dbt 测试,如果配置了 Elementary 的新鲜度或容量测试,它们将显示在第一个视觉效果的第二行中。 正如您在模型运行视图中看到的,我已经运行了 158 个模型,没有任何错误或跳过。在过去的几天里,运行模型时出现的错误越来越多。我可以轻松看到从 09/7 开始发生的错误并相应地对其进行故障排除。 您可以在生产中托管此仪表板并将其发送到您的通信/警报渠道。下面是来自 Argo 工作流程的一个示例,但您也可以在此处查看适合您的设置/您想要在生产中托管它的位置的不同方法。
名称: generate-elementary-report
容器:
图像: “ {{inputs.parameters.elementary_image}} “ ## configmap.yaml 中预定义的元素图像
命令: [ “edr” ] ## 运行元素报告的命令
参数: [ “report”,“--profile-target= {{inputs.parameters.target}} “ ]
workingDir: workdir ## 工作目录
输入:
参数:
- 名称: target
- 名称: elementary_image
- 名称: bucket
工件:
- 名称: 源
路径: workdir ## 工作目录
输出:
工件:
- 名称: 状态
路径: /workdir/edr_target
gcs:
bucket: “ {{inputs.parameters.bucket}} “ ## 这是您想要托管仪表板输出的存储桶
键: path_to_key
存档:
无: {}通过在 Argo 工作流中使用上述模板,我们将创建 Elementary HTML 报告并将其保存在定义的存储桶中。我们稍后可以从您的存储桶中获取此报告并将其与您的警报一起发送。 现在我们知道了如何设置报告,并且希望了解 Elementary 的基础知识,接下来,我们将检查不同类型的测试,以及哪种测试最适合哪种场景。
感谢关注雲闪世界。(Aws解决方案架构师vs开发人员&GCP解决方案架构师vs开发人员)