作者: 代晓磊_Mars 原文来源: https://tidb.net/blog/02df4029
要想搞定在线机房迁移之TiDB数据库迁移,看完本文基本上所有的迁移方案你都可以搞定了(数据库迁移方案和流程大同小异)。本文给了3种TiDB在线迁移的场景和方案,大家可以根据各自的业务场景各取所需了。
一、在线机房prepare阶段
一般在线机房迁移都是同城,且机房距离在150km,需要具备条件:
1、专线要求
- 数据中心距离在 150 km 以内,通常位于同一个城市或两个相邻城市
- 数据中心间的网络至少采用2条光纤专线连接,并且要求延迟 3 ms左右,并且长期稳定运行
- 双专线且带宽大于 200 Gbps
2、资源要求
- 物理机:比之前的配置要好,尤其当前的高密机型,考虑好硬盘pv、cpu、内存资源规划。
- K8s:版本选择,以及环境搭建完毕,到达可用程度,并且可以绑定物理机nodes资源
- Operator:tidb-operator尽量选择高版本,做好调研和测试验证,到达可用状态
二、在线TiDB集群迁移切换方案
在之前我写过的多云多活文章中有提及切换方案,并且基于线上的核心集群实施成功,相当于帮我们在线数据库迁移打好了坚实的基础。
因为知乎的tidb是all in k8s,我就先按照k8s给大家展示方案。
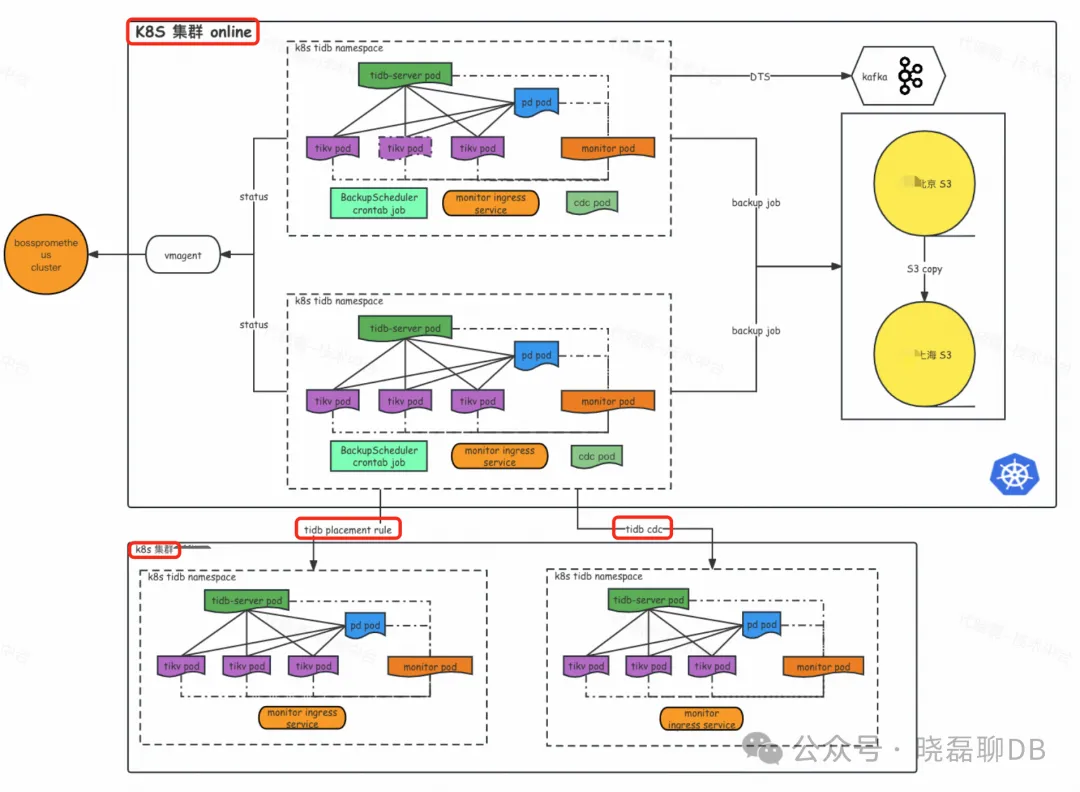
整体的迁移架构如上图所示,可以看到:
- 从结构上看,上方k8s集群online代表当前老机房的tidb集群部署,里面包含了tidb集群的各个组件。下方是新建立一套k8s集群,里面也部署了tidb集群
- 中间2个红框代表的同步链路,一个是基于tidb placement-rule副本投放,从视图上还是同一套tidb集群的迁移链路。另外一个是由tidb cdc(ticdc) 同步的上下游2套不同的tidb集群(上下游的版本可以不一样)。
下面我们分别来聊下这2种迁移方案:
1、跨云跨k8s的tidb placement-rule副本投放迁移(60% tidb集群都由此方案迁移)
迁移架构说明
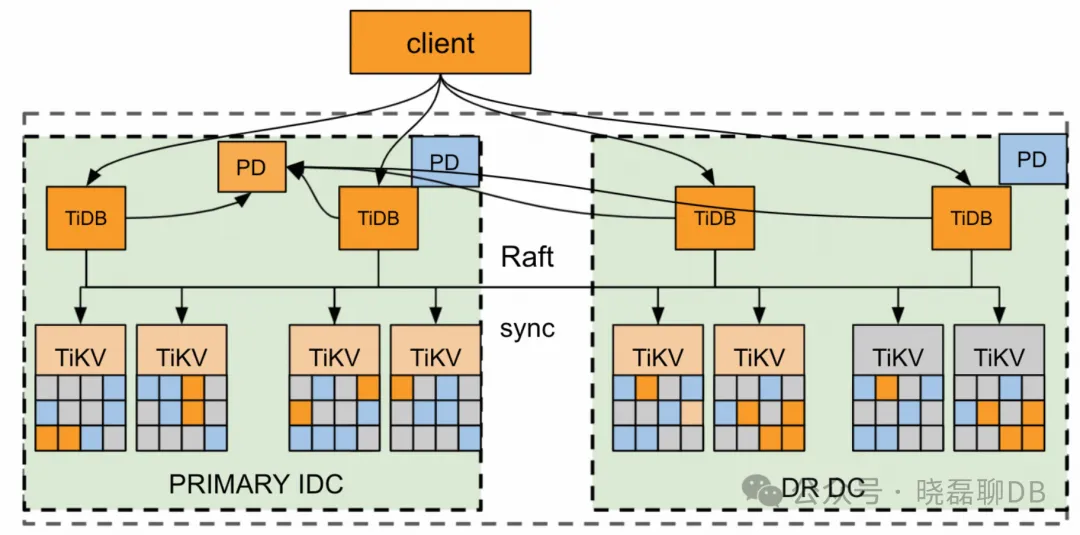
Placement Rules 是 PD 在 4.0 版本引入的一套副本规则系统,用于指导 PD 针对不同类型的数据生成对应的调度。通过组合不同的调度规则,用户可以精细地控制任何一段连续数据的副本数量、存放位置、主机类型、是否参与 Raft 投票、是否可以担任 Raft leader 等属性。Placement Rules 特性在 TiDB v5.0 及以上的版本中默认开启(5.0之前开启需要通过pd-ctl命令:config set enable-placement-rules true开启)。默认开启placement-rule 后的情况如下:
# ./pd-ctl -i
» config placement-rules show
[
{
"group_id": "pd",
"id": "default",
"start_key": "",
"end_key": "",
"role": "voter",
"is_witness": false,
"count": 5
}
]
PS :"count": 5 副本是因为之前我 config set max-replicas 5 修改过集群副本量
如果我想给这个tidb集群实现同城2中心的副本放置 3 个 voter 副本在老集群 : 2 个 follower 副本在新集群,并且在每个规则内通过 label_constraints 将副本限定在对应的数据中心内。配置如下:
[
{
"group_id": "pd",
"id": "default",
"start_key": "",
"end_key": "",
"role": "voter",
"count": 3,
"label_constraints": [
{"key": "zone", "op": "in", "values": ["zone1"]}
],
"location_labels": ["rack", "host"]
},
{
"group_id": "pd",
"id": "online2",
"start_key": "",
"end_key": "",
"role": "follower",
"count": 2,
"label_constraints": [
{"key": "zone", "op": "in", "values": ["zone2"]}
],
"location_labels": ["rack", "host"]
}
]
通过以上配置就搞定了新机房的副本投放,相当于我将之前 5 voter 副本都在 id=default 的老机房,拆分成了 3 个 voter 在老机房,2 个 follower 在新机房的同构集群。在 2 个 follower 副本数据同步完成后,修改 placement-rule 配置,将 id=online2 的 region role 由 follower 调整 voter 即可完成 region leader 的跨机房分布,通过观察监控等 leader 均衡后,调整老机房的 count=0,新机房的 count=5 来完成新机房的副本补充,一定时间后老机房 region 掉 0 就完全完成数据的迁移了。调整方式如下:
[
{
"group_id": "pd",
"id": "default",
"start_key": "",
"end_key": "",
"role": "voter",
"count": 0, ####这里的0就代表把老机房的副本删除了
"label_constraints": [
{"key": "zone", "op": "in", "values": ["zone1"]}
],
"location_labels": ["rack", "host"]
},
{
"group_id": "pd",
"id": "online2",
"start_key": "",
"end_key": "",
"role": "voter", ####这里将之前的follower调整到voter
"count": 5, ####这里的5就代表把新online2的副本扩容到5
"label_constraints": [
{"key": "zone", "op": "in", "values": ["zone2"]}
],
"location_labels": ["rack", "host"]
}
]
优点:
tikv 数据根据 placement-rule 规则自动投放,业务读写访问都是同一个集群,只是 tikv 存储节点投放到了不同 k8s 里的不同 tidb 集群中,整体的迁移对于业务透明,刚才的 3voter : 2follower 配置,好处就在于 3 个 voter都在老数据中心,tidb 的写入也基本都是本中心多数派提交,写入性能基本没有什么变化,tidb 读取也是老数据中心的 leader 读取。
缺点:
副本投放方式不能够跨版本,必须保证和当前集群版本一致,另外一旦有leader 在新机房产生,业务存在跨机房读写 region leader 的延迟增加问题(增加的延迟对于大部分业务都可控)。
多云同构集群迁移操作步骤
(1)在 online2 创建同版本 tidb 集群 ,拷贝老集群的 tc.yaml 的配置,修改里面的配置,只有配置了 clusterDomain 的集群,新集群的 PD 才能在跨云跨 k8s 跟老集群的 PD 通信,另外还需要注意修改 PD 的权重配置,目的在迁移期间将PD leader圈在老机房来保证性能(别忘了tidb server 经常跟 pd 获取 TSO 和全局 ID 等请求)
pd-ctl member leader_priority <member_name> <priority>
(2) 创建同配置同数量的 tikv节点+配置 placement-rule ,这时需要考虑副本的 leader 放置策略(角色设定:voter/follower/learner),参考刚才的 3:2 的 placement-rule 配置。
注意:为啥同数量?单副本的 size,新集群需要能容纳2个副本的size,避免因为新机房的tikv节点过少而打满资源。为啥同配置?tikv集群的cpu负载和mem使用保证迁移后能扛住。
(3) 调优region的创建速度 :store limit 配置,这里可以使用下面的命令专门给新的 online2 的 tikv store 配置较高的 region 创建速度。相关的操作如下:
kubectl exec tidb-test-0 -n tidb-test -- ./pd-ctl store |grep -B 2 'tidb-test.online2.com'|grep 'id":'|awk -F':' '{print $2}'|awk -F',' '{print "store limit "$1" 40 add-peer"}'
如何观察?查看监控 region health(注意 miss-peer/extra-peer 的变化),另外还可以通过计算 leader region 数量 X 2 ,或者 store region数量 X store 量看估算。
注: Store Limit 与 PD 其他 xxxx-schedule-limit 相关的参数不同的是,Store Limit 限制的主要是 operator 的消费速度,而其他的 limit 主要是限制 operator 的产生速度。
(4) config set schedule来加速调度 ,先config show查看当前调度配置默认值,执行下面的命令调整region/leader调度的并发(注意观察PD leader的负载)
config set leader-schedule-limit 16 ### 控制 Transfer Leader 调度的并发数
config set region-schedule-limit 2048 ### 控制增删 Peer 调度的并发数
config set replica-schedule-limit 64 ### 同时进行 replica 调度的任务个数
(5)均衡region leader到新机房集群(follower->voter)
上面讲方案时提到了 online2 机房的 tikv 如何通过 placement-rule提升为 leader,并且将老集群 region 缩 0 的方法。
需要考虑业务是否能接受跨机房读写 region leader 的延迟增加(从整个迁移周期来看,大部分都是接受的,影响可控),如果读写敏感业务,就需要定一个凌晨切全部的 leader 到 online2,以及切 PD leader和业务域名到新机房。
(6)多云多活状态,缩容老机房所有tikv,delete store,对于“顽固region”进行delete region
这种状态会持续一段时间,因为均衡 region leader,以及下线老机房的 region 都需要天级别的时间,对于下线老机房 store 时,会出现只剩下部分 region 无法迁移走的情况,这是需要用到强制删除的策略,下面的命令就是给 store id=10 的这个 tikv 强制增加 remove-peer 来删除老机房的 region:
kubectl exec tidb-test-pd-0 -n tidb-test -- ./pd-ctl region store 10| jq '.regions | .[]| "\(.id)"'|awk -F'"' '{print "kubectl exec tidb-test-pd-0 -n tidb-test -- ./pd-ctl operator add remove-peer ",$2," 10"}' > /home/daixiaolei/remove_peer.sh
(7)切pd leader到新机房
切 PD leader 时需要注意集群抖动和低峰切(我们曾经出现因百万region 切 PD leader 卡集群 1h,通过 pd-recover 修复的故障),因为之前设定了 leader_priority,需要进行调整,可以有2个方式切 PD leader:
- 直接设定online2的pd leader_priority比老机房高,这时PD集群就会因权重调整自动切PD。
- 设定online2的pd leader_priority跟老机房一致,手动并且选低峰执行member leader transfer <member_name>切主到online2的集群。
(8) 业务切读写到新机房
因为副本投放的集群两边机房访问的是同一个集群,所以只需要把 dns 从老机房迁到新机房即可,不用kill连接,待容器自动销毁后连接自动释放。
(9)缩容老机房tidb server
缩容前查看cluster-processlist确认是否还有业务链接,如果有通过pods IP找到对应的业务程序,让业务及时切主。
查看监控是否还有业务流量,确认没有流量后,老机房tidb server 缩0
(10) 老机房缩容所有pd节点
确认新online2机房有至少3个pd节点,就可以缩容老机房的所有pd节点
(11) 老机房delete pvc
默认缩容tikv的pods,它的PVC不会删除的,这里要手动删除下PVC,这样pv也自然释放
(12)老机房delete tc
老机房delete tc的操作风险非常的巨大,万一你操作错新online2机房的集群就完蛋了,操作时一定要kubectl get pods -n tidb-test看下是否是已经空的老集群,然后操作是找DBA double check。
(13)回收物理机资源(delete nodes,关机回收)
回收资源后,机房迁移完毕。
当然了,上面升级同构集群的迁移方案,上述能迁移的,当你遇到无法副本投放的集群。 其实这个就涉及到集群tc.yaml中的一个重要的配置clusterDomain,如果没有这个配置,就要创建异构集群来添加(所以对于tidb on k8s,以后要跨k8s建立集群,必须要配置clusterDomain) 。
2、 ticdc链接的主备集群(30% tidb集群都由此方案迁移)

基于ticdc 迁移需要先通过BR 恢复老集群的全量数据,再通过TiCDC 同步增量数据即可,在数据同步后需要和业务配合进行迁移,A/S 级别业务必要时需要在低峰时进行迁移,对数据一致性有严格要求的需要配合停写迁移。
优点
- 上下游都是独立集群,下游新集群的版本可以高于当前集群,对于需要替换的老tidb版本或者希望用到新版本特性的业务可以迁移升级一并做了。但是一定要注意:tidb升级版本后的SQL兼容性。
- 对于之前多个核心 DB 共用一套 tidb 集群的拆分到多套集群,增加隔离和稳定性。
- ticdc 的迁移可以随时回滚,在业务停写切读写到下游集群时创建新集群到旧集群的反向同步任务,将新集群生产的数据同步回老集群,在业务确定迁移成功一周后再停掉同步任务,并删除老集群。
缺点
- ticdc 同步的延迟较高,对于读敏感业务,无法切读流量验证。
- ticdc 的同步能力有限制(单worker 3w/s),对于线上写入5w/s的增量同步链路可能无法搭建
- BR 备份/恢复大集群可能时间较长,需要调整gc-life-time来保证增量同步,gc-life-time配置过长会保留较多MVCC,可能会对tidb读性能造成部分影响。
ticdc迁移操作步骤
(1)在online2创建新tidb集群 (根据业务要求,版本可以一样也可以升级到高版本)
(2)调整老集群的gc_life_time,比如设定为3天(72h,按需调整)
mysql> select * from mysql.tidb where VARIABLE_NAME like '%gc_life_time%';
+-------------------+----------------+----------------------------------------------------------------------------------------+
| VARIABLE_NAME | VARIABLE_VALUE | COMMENT |
+-------------------+----------------+----------------------------------------------------------------------------------------+
| tikv_gc_life_time | 10m | All versions within life time will not be collected by GC, at least 10m, in Go format. |
+-------------------+----------------+----------------------------------------------------------------------------------------+
1 row in set (0.02 sec)
mysql> update mysql.tidb set VARIABLE_VALUE='72h' where VARIABLE_NAME='tikv_gc_life_time';
Query OK, 1 row affected (0.01 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql> select * from mysql.tidb where VARIABLE_NAME like '%gc_life_time%';
+-------------------+----------------+----------------------------------------------------------------------------------------+
| VARIABLE_NAME | VARIABLE_VALUE | COMMENT |
+-------------------+----------------+----------------------------------------------------------------------------------------+
| tikv_gc_life_time | 72h | All versions within life time will not be collected by GC, at least 10m, in Go format. |
+-------------------+----------------+----------------------------------------------------------------------------------------+
1 row in set (0.00 sec)
(3)使用 BR 工具备份老集群 databases 数据到 S3 ,BR的版本要跟tidb集群版本一致.
br backup db \
--pd "${PDIP}:2379" \
--db test \
--storage "s3://backup-data/db-test/2024-06-30/" \
--ratelimit 128 \
--log-file backuptable.log
(4)使用 BR 将 S3 的 TiDB 备份恢复到 online2 新集群
br restore db \
--pd "${PDIP}:2379" \
--db "test" \
--ratelimit 128 \
--storage "s3://backup-data/db-test/2024-06-30/" \
--log-file restore_db.log
(5)创建老集群到新集群的cdc任务 (老集群需要部署cdc组件),注意从备份日志中获取 TSO,这个 TSO 是 ticdc 创建同步任务的依赖
kubectl logs -f backup-tidb-test-backup-06301455-nv4pw -n tidb-test
./cdc cli changefeed create --pd=http://tidb-test-pd:2379 --sink-uri="tidb://test_wr:xxxx@tidb-test-peer.online2.com:4000/" --start-ts=434373684418314309 --config service_tree.toml --changefeed-id=tidb-test-migration
**(6)同步验证:**观察grafana cdc监控或者 cdc query changefeed-id命令查看已经没有延迟,从数据量和 sample 抽样验证数据一致性
**(7)数据验证没问题,**可以让读取不敏感的业务灰度读流量到新集群,验证业务 SQL 的执行情况。
(8)业务方读流量灰度 100% 到新集群就可以切写了 ,或者读写敏感型的选择凌晨低峰期切读写。业务切写的方式有2种选择:
业务自己控制停写,然后切到下游。
DB 回收老集群用户的写入权限来强制停写,回收权限对已建链接不生效,需要 kill 一遍所有的链接或者重启一遍 tidb server。
(9)停写后,需要观察下同步链路,确认没有数据同步,然后停止老机房到新机房的 ticdc 同步链路,并且建立新机房tidb集群反向同步老机房的链路,目的是一旦新集群有任何问题,可以随时切回老集群,数据也不会丢失。
(10)业务切到下游新集群完成tidb切换
(11)观察一周后,下线 ticdc 反向同步链路以及删除老集群
(12)回滚方案:如果在一周内出现读写问题,可以随时切换回老集群。
3、其他场景(业务双写、业务只凌晨写,10%)
- 空集群业务双写
对于日志型业务,可以在新机房建立集群,业务双写7~30天就完成切换
- BR/dumping备份,业务切读切写
有些tidb集群只有凌晨写入,白天可以BR/dumping+lightning备份恢复后切主
三、总结
通过3个月的迁移,我们将几十套TIDB集群,总量PB级数据,通过以上各种方式,安全稳定的迁移到了新机房,在此期间,我们根据迁移方案,也开发了平台化的DTS,以及机房迁移模块跟进迁移进度。总之感谢业务团队配合以及团队兄弟们的辛苦努力才能达成这么NB的在线机房迁移项目。















![[000-01-002].第03节:Git基础命令](https://i-blog.csdnimg.cn/blog_migrate/79efa3864d304b6341d2ddd594208311.png)