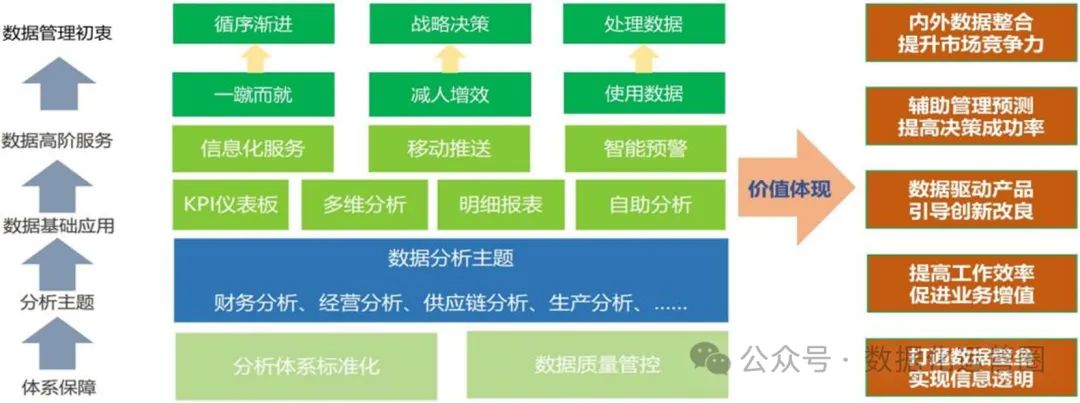
大模型之三十一-音乐分离模型
因为TTS模型训练还有几个结果没出,本篇先介绍一下音乐分离模型吧。其实可能你也猜到了,一部分TTS的数据是网上爬来的,这种音频可能会有背景音之类的,这里需要将乐器类的伴奏去掉。所以就此介绍一下本篇文章吧。
在选择和使用音乐源分离工具时,没有“一劳永逸”的最佳方案,因为每首歌曲的录制和混音方式都有所不同。因此,尝试和比较不同的模型和设置,根据具体情况调整策略,是达到最佳分离效果的关键。
因为本篇集中在对人声的提取,所以重点关注于vocal的性能。
当前音乐多轨分离比较流行的架构是Demucs、MDX-Net、MDXC以及VR Arch这几种,当前UVR5提供了UI界面进行分离的方法。本篇测试以audio-separator为例进行的。UVR5详细介绍文档
Demucs
“Demucs” 来自meta,经过4个版本的迭代之后,V4集成了 “Hybrid Transformer Demucs”,这是一种混合的频谱/波形分离模型,使用了 Transformer 技术。它能够从音乐伴奏中分离出鼓、贝斯和人声等元素。该模型基于 U-Net 卷积架构,灵感来源于 Wave-U-Net,一种用于音频处理的网络结构。
具体来说,Demucs v4 使用了 “Hybrid Demucs” 作为基础框架,并在最内层使用了跨域 Transformer 编码器来替换原有的一些层。这种 Transformer 在各自的域中进行自注意力处理,并通过跨域的注意力机制实现不同音频成分间的相互影响和处理。

模型在 MUSDB HQ 测试集上实现了 9.00 分贝的信号失真比(SDR, Signal-to-Distortion Ratio),SDR 越高,表示分离的音频质量越好,原始音源中的噪声和失真越少。此外,通过使用稀疏注意力核来扩展其接收范围以及对每个音源进行微调,该模型在 SDR 上达到了 9.20 分贝。
当前UVR5以及audio seperator支持的模型情况如下:
- htdemucs_ft - 分离质量最高 fine-tuned v4 模型, SDR instrument:9.9043, SDR vocals:10.2008
- htdemucs - 质量低,但是速度快
- htdemucs_6s - 一般分离式bass、drum、vocal、others这四轨,这个模型又增加了"piano" 和 “guitar”
- hdemucs_mmi 这个是在v3的基础上重新训练的基线模型,使用了最大互信息(MMI)技术进行优化,它在处理特定的音频分离任务时可能表现更好, 速度比较快。
MDX-Net
MDX-Net网络主要是基于TFC-TDF-U-Net的网络,目前项目方开源了当时参赛的源码,其结构上通过堆叠许多具有跳跃连接的层(stacking many layers with many skip connections),可以提高SDR性能。需要大量的计算资源和时间进行训练和评估。因而Minseok Kim等人提出了一种名为KUIELab-MDX-Net的音乐分离双流神经网络,在性能和所需资源之间的良好平衡。所提出的模型具有时频分支和时域分支,每个分支分别分离音轨。

现在在开源社区已经产生了非常多高质量的、不同针对性的预训练模型。迄今为止MDX-NET-Voc_FT、Kim Vocal 2等预训练模型仍然在MVSEP排行榜中名列前茅。Kim Vocal系列预训练模型甚至能够搭配其他模型提供主唱与和声的分离能力,还有一些模型能够从Reverb中提取出干音。
MDX-UVR 模型分为Inst模型和Vocal模型,Inst模型总是会在人声中留下一些器乐残音,反之亦然——人声模型更有可能在器乐中留下一些人声残音。
- Kim vocal 1&2: 针对Vocal fine-tuned的MDX比赛用模型,这个模型在Sound Demixing Challenge 2023的MDX’23比赛中获得了第3名的成绩,窄带模型,在生产领域只适用于人声。
- kim Inst: 针对Instrument的模型,与 inst3/464 相比,它能获得更清晰的结果和更好的 SDR,但有时也会产生更多噪音。这个模型是cutoff的,会切除17.7KHz以上的频率,不适用于生产,只适用于比赛刷分
- Inst HQ 3: 全频域的针对乐器的分离模型,目前为止细节效果在第一梯队,但是对弦乐的处理有问题,同时,HQ 3对部分吹奏乐器的处理也有一些问题,处理笛子和小号的效果不如其它模型。
- UVR-MDX-NET Voc FT: Vocal分离单模型,并且在MVSEP排行榜名列前茅,但是是窄带模型,如果之后还有器乐残留,可以考虑再用Kim vocal 2处理一下。
- inst HQ_1 (450)/HQ_2 (498) (full band): 在大多数情况下,都能使用高质量的模型。后者的 SDR 更好一些,人声残留可能更少一些。虽然不像 inst3 或kim ft那样少,但也是一个很好的起点。
- Inst 3: 窄带模型,结果会更浑浊一些,但在某些情况下也会更平衡一些, SDR instrument:10.6194, SDR vocals:11.0177
- Inst Main: 相比Inst 3对Vocal的残留更多
- 后缀带有Karaoke的系列: Vocal只去除主唱,保留和声的模型,目前效果最好的是UVR-MDX-NET Karoke 2
- UVR-MDX-NET 1, UVR-MDX-NET 2, UVR-MDX-NET 3: UVR团队自训练的模型,用于Vocal分离,其中模型1获得了9.703的SDR分数,2和3是减少参数的模型。这三个模型都有14.7kHZ的cutoff

MDXC
UVR5可以使用一些23年challenge挑战赛的一些模型,其Roformer Model是新出现的,其网络结构如下。

vocal和inst分离的质量如下表:

VR Arch
VR Architecture方法中,基本有5个模型,可以从设置中下载附加模型,总共可以选择25种模型。在5种基本模型中,
- 1_HP-UVR.pth 和 2_HP-UVR.pth 是适合从歌曲中去除人声的模型,
- 3_HP-Vocal-UVR.pth 和 4_HP-Vocal-UVR.pth 是适合从歌曲中提取人声的模型,
- 5_HP-karaoke-UVR.pth 则适合去除歌曲中仅有主唱(保留背景合唱)。其他设置如下。窗口大小:较小则品质更高,但会花费更多时间。320 是高品质,1024 是低品质。聚合设置:音频的人声和歌曲移除强度设置。无需更改默认值 10。GPU 转换:设置是否使用 GPU。必须使用支持 CUDA 的 GPU。仅保存人声/器乐:设置保存仅有人声或无人声的音源。TTA:使用“测试时间增强”可以提高分离质量,但会增加执行时间。模型测试模式:当想要尝试多个模型时,启用后输出文件名会附加使用的模型名称。
当前各个场景算法的得分情况见link