原文阅读:【巨人肩膀社区·博客·分享】记一次Hiveserver2连接异常的解决-腾讯云-emr
离线任务跑的好好的,忽然有一天失败了,查看海豚上的任务执行日志发现是hiveserver2连接超时了。
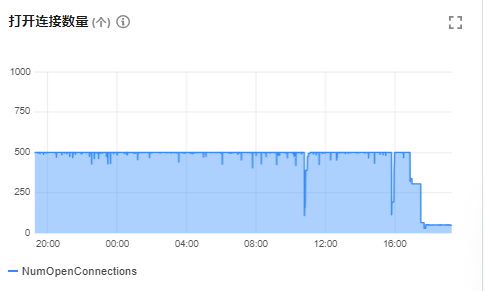
查看监控发现了几个问题一个是GC变得频繁,另一个是连接数达到上限了。
1、针对内存问题
GC变得频繁 =》内存不足 =》通过jdbc连接Hive查数数据时会使用hiveserver2配置的内存,如果查询需要的内存大于配置的内存时就会出现OOM
其中查询需要的内存会随着查询涉及的数据量的增加而增加,这就是为什么之前都是好好的,某一天出问题了,因为日增数据在一天天增长。
解决:修改配置增加所需内存
hive-env.sh中调整HS2Heapsize为8192,并重启hiveserver2生效。
<property>
<name>hive.server2.heapsize</name>
<value>4096</value>
</property>因为我们用的是公有云的产品,所以可以直接通过可视化界面修改:
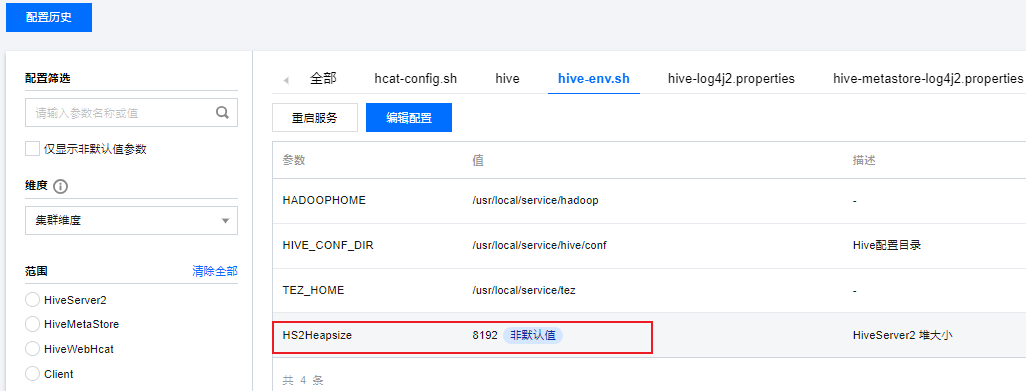
修改后重启hiveserver2生效
Tips:内存不是越大越好,多了浪费,还有一个更重要的就是会占用本节点其他服务的内存。
2、针对连接超上限
正常hive sql执行完对应hiveserver2的连接随之释放,但是某些原因可能导致任务异常,海豚调度的worker进程没有处理好这种异常导致一直不断开对hiveserve的连接。
解决:重启海豚调度的相关worker节点。
1.查看哪些ip和端口在连hiveserver2:netstat -tunp | grep xxxx
2.查看在这些ip里又是哪个进程发起的连接:sudo lsof -i :端口号
3.最终发现是海豚调度的worker进程一直不释放hs2的连接
4.最终重启海豚调度的worker进程
排查过程相关命令参见: shell 网络工具 netstat
结果:重启后连接断崖式下降: