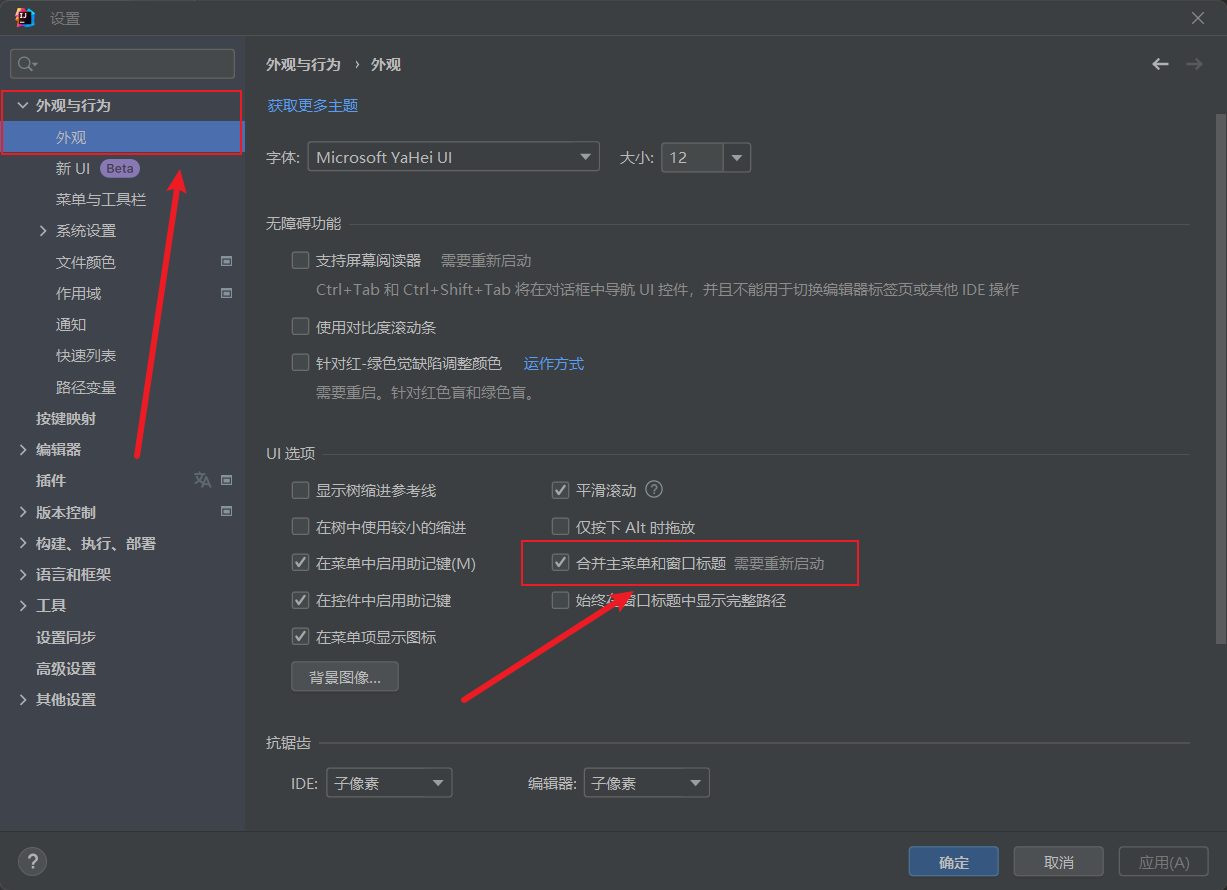
论文来源:https://arxiv.org/abs/2402.18115
《UniVS: Unified and Universal Video Segmentation with Prompts as Queries》是2024CVPR中的一篇关于视频分割的论文,
主要内容:
论文提出了一个名为UniVS的新型统一视频分割架构,它能够处理多种视频分割任务,包括类别指定的视频分割(category-specified VS)和提示指定的视频分割(prompt-specified VS)。UniVS通过将视频分割任务转换为由提示引导的目标分割任务,从而消除了传统方法中需要的启发式帧间匹配过程。
创新点:
- 使用提示作为查询(Prompts as Queries):UniVS将先前帧中目标的提示特征平均值作为初始查询,以明确解码掩码。
- 目标提示交叉注意力层(Target-wise Prompt Cross-Attention Layer):引入了目标提示交叉注意力(ProCA)层,以在记忆池中整合提示特征。
- 统一的视频掩码解码器(Unified Video Mask Decoder):通过使用预测的实体掩码作为视觉提示,UniVS将不同的视频分割任务转换为提示引导的目标分割任务。
- 通用训练和测试:UniVS不仅统一了不同的视频分割任务,还自然实现了通用训练和测试,确保在不同场景下的鲁棒性能。
- 跨多个基准的性能平衡:UniVS在10个具有挑战性的视频分割基准测试中表现出色,涵盖了视频实例、语义、全景、对象和引用分割任务。
网络结构:
UniVS主要由三个模块组成:
- 图像编码器(Image Encoder):将RGB图像转换为特征令牌。
- 提示编码器(Prompt Encoder):将原始视觉/文本提示转换为提示嵌入。
- 统一视频掩码解码器(Unified Video Mask Decoder):明确解码视频中任何实体或提示引导目标的掩码。
统一视频掩码解码器包含四个关键组件:
-
初始提示查询(Initial Prompt Query):使用与目标相关的所有提示令牌的平均值作为初始查询。
-
提示交叉注意力(Prompt Cross-Attention, ProCA):增强目标表示的独特性。
-
“Prompt Cross-Attention”(ProCA)是统一视频掩码解码器(Unified Video Mask Decoder)中的一个关键组件。它的目的是增强目标表示的独特性,以便更好地区分视频中的不同目标。以下是ProCA层的一些详细信息:
-
(1)功能和目的:
-
增强目标区分性:ProCA层通过学习提示信息来增强目标表示的独特性,这对于区分视频中具有相似特征的目标(例如,不同的人或物体)尤其重要。
-
整合提示特征:该层将存储在记忆池中的提示特征与目标的当前表示结合起来,以生成更丰富、更准确的目标掩码。
-
工作原理:
-
初始查询:对于每个目标,ProCA层使用先前帧中该目标的提示特征的平均值作为初始查询。
-
交叉注意力机制:ProCA层使用交叉注意力机制来整合提示特征。这涉及到计算查询(目标的初始查询)与键(提示特征)之间的注意力分数,然后使用这些分数来加权值(也是提示特征)。
-
更新表示:通过这种方式,ProCA层更新目标的表示,使其包含更多与提示相关的信息,从而在解码过程中生成更准确的掩码。
-
(2)数学表达:
-
ProCA层的计算可以表示为以下数学公式:

-
其中:
-
( q^*_i ) 是目标的初始查询。
-
( P^*_i ) 是提示特征。
-
( W^Q ), ( W^K ), 和 ( W^V ) 是投影权重。
-
( d_k ) 是缩放因子,用于控制注意力分数的尺度。
-
(3)在UniVS框架中,ProCA层位于图像交叉注意力层之前,以确保在解码器的深层阶段不会丢失提示信息。通过这种方式,UniVS能够将不同的视频分割任务转换为由提示引导的目标分割任务,从而避免了传统方法中需要的启发式帧间匹配过程。
-
ProCA层是UniVS能够处理多种视频分割任务的关键,它使得模型能够灵活地处理各种提示类型,包括视觉点击、框选、遮罩和涂鸦,以及文本描述。这种设计提高了模型的通用性和适应性,使其能够在不同的视频分割场景中表现出色。
-
图像交叉注意力(Image Cross-Attention):专注于从输入帧中提取实体细节。
-
分离自注意力(Separated Self-Attention, SepSA):隔离可学习查询和提示查询之间的交互,同时促进目标在空间和时间域内的内容交互。
此外,UniVS在训练过程中包括三个阶段:图像级训练、视频级训练和长视频微调,以逐步提高模型对视频数据的理解能力。
论文还进行了一系列的消融研究,以验证所提出组件的有效性,并通过实验结果展示了UniVS在多个视频分割任务上的性能。
分割过程
在论文《UniVS: Unified and Universal Video Segmentation with Prompts as Queries》中,完成分割部分的过程涉及以下几个关键步骤:
-
图像编码(Image Encoding):
- 输入的RGB视频帧首先通过图像编码器转换成特征表示。这通常包括一个卷积神经网络(CNN)骨干网络,它提取空间特征,以及一个像素解码器,它融合不同尺度的特征以增强表示。
-
提示编码(Prompt Encoding):
- 对于视觉提示(如点击、框选、遮罩、涂鸦等),通过视觉采样器从图像特征中提取特征点,形成视觉提示嵌入。
- 对于文本提示(如类别名称或描述性文本),使用CLIP文本编码器将文本转换为嵌入,然后通过交叉注意力层与图像特征进行交互,生成文本提示嵌入。
-
统一视频掩码解码(Unified Video Mask Decoding):
- 使用初始提示查询(由先前帧中目标的提示特征平均值生成)作为掩码解码器的输入。
- 引入目标提示交叉注意力(ProCA)层,以整合记忆池中的提示特征,并增强目标表示的独特性。
- 通过图像交叉注意力层和分离自注意力(SepSA)层,专注于从输入帧中提取目标的详细信息,并在空间和时间域内促进目标内容的交互。
-
掩码预测:
- 掩码解码器的输出通过一个前馈网络(FFN)和其他转换层,最终生成每个目标的预测掩码。
- 对于类别指定的视频分割任务,使用可学习查询来识别第一帧中的所有实体掩码,然后使用非极大值抑制(NMS)和分类阈值来过滤冗余掩码和低置信度掩码。
-
跨帧跟踪和实体匹配:
- 对于类别指定的视频分割任务,使用周期性目标检测策略,将分割转换为提示引导的目标分割问题。
- 对于提示指定的视频分割任务,使用预测的实体掩码作为视觉提示,更新目标的记忆池,并在后续帧中识别和分割目标。
-
训练和优化:
- 训练过程中,使用像素级掩码监督损失、分类损失和ReID损失来优化模型参数。
- 训练分为三个阶段:图像级训练、视频级训练和长视频微调,以逐步提高模型对视频数据的理解能力。
-
推理和输出:
- 在推理阶段,模型接收视频帧和提示,通过上述编码和解码过程预测每个目标的掩码。
- 最终输出是视频中每个目标的分割掩码,这些掩码可以用于各种应用,如视频编辑、增强现实、视频恢复等。
整个分割过程是端到端的,意味着从输入视频帧到输出分割掩码的所有步骤都是连续的,并且可以通过反向传播和梯度下降自动优化。