译者序
本文翻译自 2024 年的一篇文章: LLM inference speed of light, 分析了大模型推理的速度瓶颈及量化评估方式,并给出了一些实测数据(我们在国产模型上的实测结果也大体吻合), 对理解大模型推理内部工作机制和推理优化较有帮助。
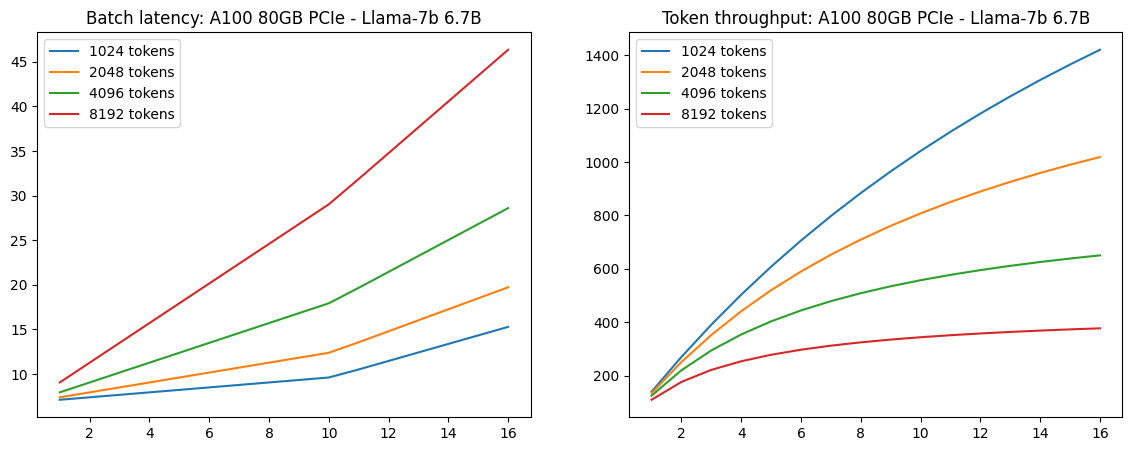
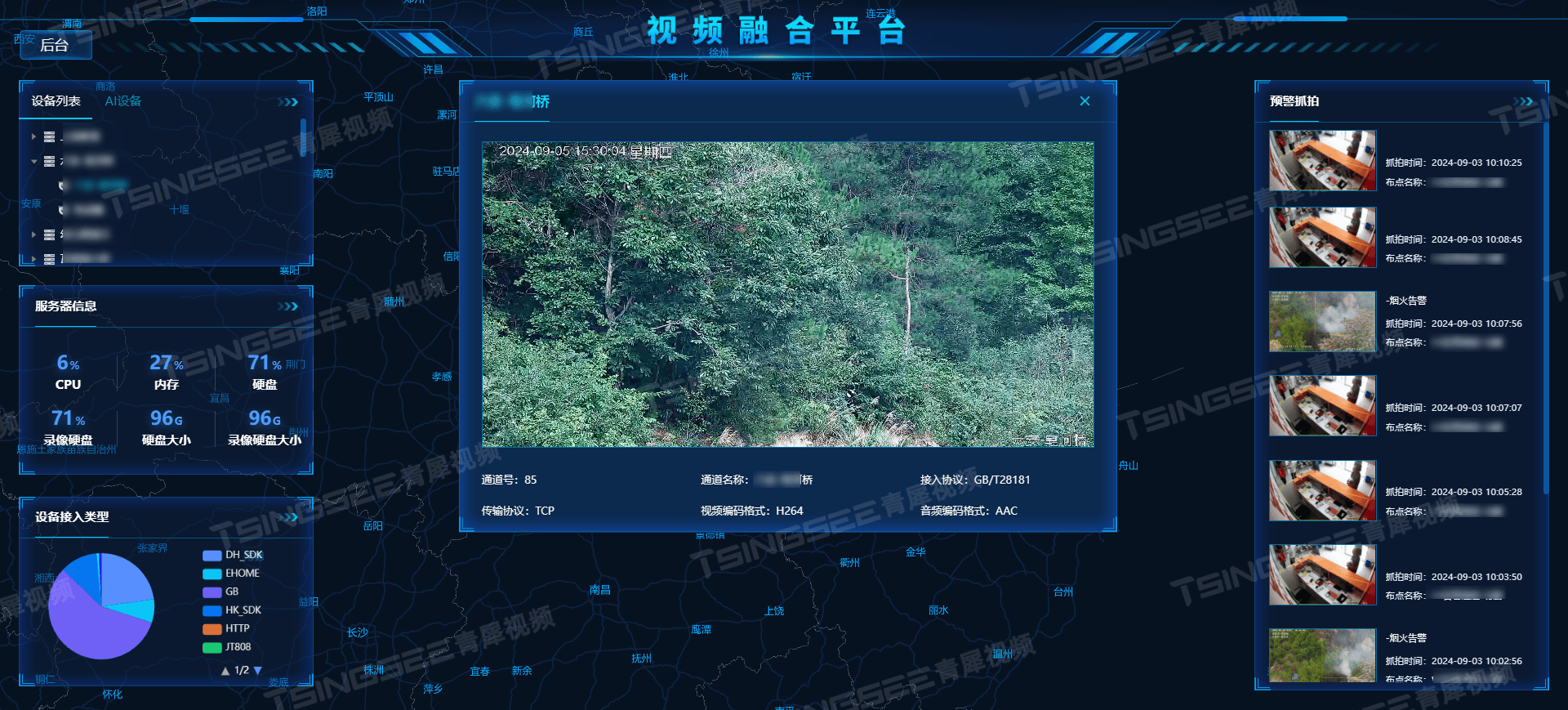
A100-80GB PICe 推理延迟与吞吐。Image Source
译者水平有限,不免存在遗漏或错误之处。如有疑问,敬请查阅原文。
以下是译文。
摘要
在开发 calm 的过程中,我们考虑的一个核心问题是: 推理的极限在哪儿?因为我们需要以此为准绳,去衡量真实推理系统的速度。
calm 是一个基于 CUDA、完全从头开始编写的轻量级 transformer-based language models 推理实现。
本文试图讨论这个极限及其影响。 如果对推导细节感兴趣,可参考这个 python notebook。
1 推理机制
1.1 transformer:逐 token 生成,无法并行
当语言模型生成文本时,它是逐个 token 进行的。 可以把语言模型(特别是 decoder-only text transformer,本文统称为 LLM) 看做是一个函数,
- 输入:一个 token
- 输出:一组概率,每个概率对应词汇表中一个 token。
- 推理程序使用概率来指导抽样,产生(从词汇表中选择)下一个 token 作为最终输出。
词汇表(vocabulary):通常由单词、单词片段、中文汉字等组成(这些都称为 token)。 vocabulary 长什么样,可以可以看一下
bert-base-chinese的词典 vocab.txt。 更多基础:
- GPT 是如何工作的:200 行 Python 代码实现一个极简 GPT(2023)。
- Transformer 是如何工作的:600 行 Python 代码实现 self-attention 和两类 Transformer(2019)
译注。
文本生成过程就是不断重复以上过程。可以看出,在生成一个文本序列时,没有并行性的可能性。
speculative execution尝试通过一个 less accurate predictor 来实现某种程度的并行,本文不讨论。
1.2 生成过程建模:矩阵乘法
广义上,当处理一个 token 时,模型执行两种类型的操作:
- 矩阵-向量乘法:一个大矩阵(例如 8192x8192)乘以一个向量,得到另一个向量,
-
attention 计算。
在生成过程中,模型不仅可以看到当前 token 的状态,还可以看到序列中所有之前 token 的内部状态 —— 这些状态被存储在一个称为
KV-cache的结构中, 它本质上是文本中每个之前位置的 key 向量和 value 向量的集合。attention 为当前 token 生成一个 query 向量,计算它与所有之前位置的 key 向量之间的点积, 然后归一化得到的一组标量,并通过对所有之前的 value 向量进行加权求和来计算一个 value 向量,使用点积得到最终得分。
This description omits multi-head attention and the details of “normalization” (softmax), but neither are critical for understanding the inference performance.
1.3 瓶颈分析
以上两步计算有一个重要的共同特征:从矩阵或 KV-cache 读取的每个元素,只需要进行非常少量的浮点运算。
- 矩阵-向量乘法对每个矩阵元素执行一次乘加运算(2 FLOPs);
- attention 对每个 key 执行一次乘加,对每个 value 执行一次乘加。
1.3.1 典型“算力-带宽”比
现代 CPU/GPU 的 ALU 操作(乘法、加法)内存 IO 速度要快得多。例如:
- AMD Ryzen 7950X:
67 GB/s内存带宽和 2735 GFLOPS,Flop:byte = 40:1 - NVIDIA GeForce RTX 4090:
1008 GB/s显存带宽和 83 TFLOPS,Flop:byte = 82:1 - NVIDIA H100 SXM:
3350 GB/s内存带宽和 67 TFLOPS, 对于矩阵乘法,tensor core 提供 ~494 TFLOPS 稠密算力,Flop:byte = 147:1。
对于 FP16/FP8 等精度较低的浮点数,比率更夸张:
- H100 TensorCore 对于 dense FP8 矩阵的理论吞吐量为 1979 TFLOPS,
FLOP:byte = 590:1。
在这些场景中,无论是否使用 TensorCore 或使用什么浮点格式,ALU 都非常充足。
1.3.2 瓶颈:访存带宽
因此,transformer 这种只需要对每个元素执行两次操作的场景,必定受到访存带宽的限制。 所以,基于下面几个因素,
- 模型配置(参数多少)
- KV-cache 大小
- 访存带宽
我们就能估计推理过程的最短耗时。 下面以 Mistral 7B 为例来具体看看。
2 以 Mistral-7B 为例,极限推理延迟的计算
2.1 参数(权重)数量的组成/计算
Mistral-7B 有 72 亿参数(所有矩阵元素的总数是 72 亿个)。 参数的组成如下:
4096 * 32000 = 131M用于 embedding 矩阵;- 4096: hidden size (tokens per hidden-vector)
- 32000: vocabulary size
矩阵-向量乘法中不会使用这整个大矩阵,每个 token 只读取这个矩阵中的一行,因此数据量相对很小,后面的带宽计算中将忽略这个;
32 * (4096 * (128 * 32 + 128 * 8 * 2) + 4096 * 128 * 32) = 1342M用于计算与 attention 相关的向量;32 * (4096 * 14336 * 3) = 5637M用于通过 feed-forward 转换 hidden states;4096 * 32000 = 131M用于将 hidden states 转换为 token 概率;这与 embedding 矩阵不同,会用于矩阵乘法。
以上加起来,大约有 7111M (~7B) “活跃”参数用于矩阵乘法。
2.2 计算一个 token 所需加载的数据量
2.2.1 总数据量
如果模型使用 FP16 作为矩阵元素的类型, 那每生成一个 token,需要加载到 ALU 上的数据量:
7111M params * 2Byte/param = ~14.2 GB
虽然计算下一个 token 时每个矩阵都可以复用,但硬件缓存的大小通常只有几十 MB, 矩阵无法放入缓存中,因此我们可以断定,这个生成(推理)过程的速度不会快于显存带宽。
attention 计算需要读取当前 token 及前面上下文中所有 tokens 对应的 KV-cache, 所以读取的数据量取决于生成新 token 时模型看到多少前面的 token, 这包括
- 系统提示词(通常对用户隐藏)
- 用户提示词
- 前面的模型输出
- 可能还包括长聊天会话中多个用户的提示词。
2.2.2 KV-cache 部分的数据量
对于 Mistral,KV-cache
- 为每层的每个 key 存储 8 个 128 元素向量,
- 为每个层的每个 value 存储 8 个 128 元素向量,
这加起来,每个 token 对应 32 * 128 * 8 * 2 = 65K 个元素; 如果 KV-cache 使用 FP16,那么对于 token number P,我们需要读取 P * 130 KB 的数据。 例如, token number 1000 将需要从 KV-cache 读取 130MB 的数据。 跟 14.2GB 这个总数据量相比,这 130MB 可以忽略不计了。
2.3 以 RTX 4090 为例,极限延迟计算
根据以上数字,现在可以很容易地计算出推理所需的最小时间。
例如,在 NVIDIA RTX 4090(1008 GB/s)上,
- 14.2GB (fp16) 需要
~14.1ms读取,因此可以预期对于位置靠前的 token, 每个 token 大约需要14.1ms(KV-cache 影响可以忽略不计)。 - 如果使用
8bit权重,需要读取 7.1GB,这需要大约7.0ms。
这些都是理论下限,代表了生成每个 token 的最小可能时间。
2.4 ChatGLM3-6B/Qwen-7B 实测推理延迟(译注)
简单的单卡推理测试,16bit 权重,平均延迟,仅供参考:
| LLM | RTX 4090 24GB (2022) | A100 80GB (2020) | V100 32GB (2017) |
|---|---|---|---|
| ChatGLM3-6B | 16ms/token | 18ms/token | 32ms/token |
| Qwen-7B | 19ms/token | 29ms/token | 41ms/token |
可以看到,单就推理速度来说,只要模型能塞进去(< 24GB),4090 与 A100 相当甚至更快,比 V100 快一倍。
说明:以上测的是 4090,不带
D(4090D)。
3 数学模型和理论极限的用途
以上根据数学建模和计算得出了一些理论极限数字,接下来看看这些理论极限有什么用。
3.1 评估推理系统好坏
要接近理论极限,需要一个高质量的软件实现,以及能够达到峰值带宽的硬件。 因此如果你的软件+硬件离理论最优很远,那肯定就有问题:可能在软件方面,也可能在硬件方面。
例如,在 RTX 4090 上 calm 使用 16 位权重时达到 ~15.4 ms/tok,使用 8 位权重时达到 ~7.8 ms/tok, 达到了理论极限的 90%。
Close, but not quite there - 100% bandwidth utilization is unfortunately very hard to get close to on NVidia GPUs for this workload. Larger GPUs like H100 are even more difficult to fully saturate; on Mixtral - this is a different architecture but it obeys the same tradeoffs for single sequence generation if you only count active parameters - calm achieves ~80% of theoretically possible performance, although large denser models like Llama 70B can get closer to the peak.
在 Apple M2 Air 上使用 CPU 推理时,calm 和 llama.cpp 只达到理论 100 GB/s 带宽的 ~65%, 然后带宽就上不去了,这暗示需要尝试 Apple iGPU 了。
3.2 指导量化
带宽与每个权重使用的 bit 数成正比;这意味着更小的权重格式(量化)能实现更低的延迟。 例如,在 RTX 4090 上 llama.cpp 使用 Mistral 7B
- 16 bit 权重:~17.1 ms/tok(82% 的峰值)
- 8.5 bit 权重:~10.3ms/tok (71% 的峰值)
- 4.5 bit 权重:~6.7ms/tok (58% 的峰值)
因此对于低延迟场景,可以考虑低精度量化。
3.3 指导优化方向
除了为推理延迟提供下限外,上述建模还表明:推理过程并未充分利用算力(ALU)。 要解决这个问题,需要重新平衡 FLOP:byte 比例, speculative decoding 等技术试图部分解决这个问题。
3.3.1 批处理 batch 1 -> N:瓶颈 访存带宽 -> 算力
这里再另一种场景:多用户场景。注意到,
- 当多个用户请求同时处理时,我们用相同的矩阵同时执行多个矩阵-向量乘法, 这里可以将多个矩阵-向量乘法变成一个矩阵-矩阵乘法。
- 对于足够大的矩阵来说,只要矩阵-矩阵乘法实现得当,速度就比访存 IO 快,
因此这种场景下,瓶颈不再是访存 IO,而是算力(ALU)。这就是为什么这种 ALU:byte 不平衡对于生产推理系统不是关键问题 —— 当使用 ChatGPT 时,你的请求与同一 GPU 上许多其他用户的请求并发评估,GPU 显存带宽利用更加高效。
3.3.2 批处理无法改善所需加载的 KV-cache 数据量
批处理通常不会减轻 KV-cache 带宽(除非多个请求共享非常大的前缀),因为 KV-cache 大小和带宽随请求数量的增加而增加,而不像权重矩阵保持不变。
像 Mistral 这样的混合专家模型(MoE)scaling 特性稍有不同:batching initially only increases the bandwidth required, but once the expert utilization becomes significant the inference becomes increasingly ALU bound.
3.4 硬件相对推理速度评估
带宽是评估推理性能的关键指标,对于模型变化/设备类型或架构来说是一个恒定的, 因此即使无法使用 batch processing,也可以用它来评估你用的硬件。
例如,NVIDIA RTX 4080 有 716 GB/s 带宽,所以可以预期它的推理速度是 RTX 4090 的 ~70% —— 注意,游戏、光线追踪或推理其他类型的神经网络等方面,相对性能可能与此不同!
4 GQA (group query attention) 的影响
Mistral-7B 是一个非常平衡的模型;在上面的所有计算中,几乎都能忽略 KV-cache 部分的 IO 开销。 这背后的原因:
- 较短的上下文(Mistral-7B 使用 windowed attention,限制 4096 token 的窗口),
- 使用了 GQA,这个是更重要的原因。
LLaMA 2:开放基础和微调聊天模型(Meta/Facebook,2023) 也使用了 GQA。
4.1 GQA 为什么能减少带宽
在 GQA 中(with a 4x ratio),为了得到 attention 的 4 个点积,
- 不是使用 4 个 query 向量并分别与 4 个相应的 key 向量计算点积,
- 而是只取一个 key 向量,然后执行 4 个点积。
这能够减少 KV-cache 的大小和所需带宽,也在某种程度上重新平衡了 ALU:bandwidth 比例。
4.2 有无 GQA 的数据量对比
这对于 KV-cache 内存大小也很关键,不过,这可能对短上下文模型不太明显:
- 4096 token 上下文的 Mistral 需要 0.5GiB,
- 没有 GQA 的可比模型(如 Llama 7B)“只需要”2 GiB。
让我们看看一个最近不使用 GQA 的模型,Cohere 的 Command-R。
Command-R has a large vocab (256K) and large hidden state (8192) so it spends a whopping 2B parameters on embeddings, but it reuses the same matrix for embedding and classification so we don’t need to exclude this from the inference bandwidth calculation.
模型本身有大约 35b 参数,所以以 16 位/权重计算,我们在推理期间需要为每个 token 读取 70 GB 的权重。 对于每个 token ,它需要在 KV-cache 中存储 40 * 128 * 64 * 2 = 655K 元素,以 16 位/元素计算是每个 token 1.3 MB。
因此,一个 4096 token 的上下文将需要大约 5.3GB; 与 ~70 GB 的权重相比,这已经相当显著了。然而,如果考虑到 Cohere 的模型宣传有 200K token 上下文窗口 —— 计算最后一个 token 需要读取 260 GB(还需要 260GB 的显存来存储它)!
4.3 多用户场景下 KV-cache 占用的显存规模
这么大的模型,典型的生产环境配置(单用户),
weights通常使用4bit量化(通常的实现占用 ~4.5bit/权重)KV-cache可能会使用8bit(FP8)值。
如果我们“保守地”假设上下文为 100K,则
- 模型权重占 ~19.7GB
- KV-cache 占
~65GB
计算到最后一个 token 时,我们需要从内存中读取这么大的数据。 可以看到,突然之间,attention 计算部分的数据量(最终转变成耗时)从微不足道变成了占 ~75%!
虽然 100K 上下文可能看起来有点极端,但在短上下文+多用户场景中,情况也是类似的:
- 批处理优化将多次矩阵-向量乘法变成了一次矩阵-矩阵乘法(为一批用户请求读取一次模型权重),瓶颈来到算力(ALU),
- 但每个用户请求通常都有自己的 KV-cache,
因此最终的 attention 仍然受访存带宽限制,并且需要大量内存/显存才能将所有用户请求放到单个节点!
4.4 GQA:减小从 KV-cache 加载的数据量
如果模型使用 4x GQA,KV-cache 的大小和所需带宽将会变成原来的 1/4。
对于 100k+ token 的上下文场景,虽然 KV-cache 的开销仍然很大(65GB -> 16GB+),但已经进入实用范围。
4.5 GQA 的问题
对于 Cohere 的目标使用场景,引入 GQA 可能会导致模型质量有下降,具体得看他们的技术报告。
但是,纯粹从成本/性能角度来看,每个基于 transformer 的 LLM 都需要评估是否能引入 GQA,因为收益太大了。
5 总结
对于大模型推理场景,计算和访存的次数是已知的,因此可以进行数学建模,计算理论极限。 这非常有用,不仅可以用来验证推理系统的性能, 而且能预测架构变化带来的影响。