《Spark+Hive招聘推荐与预测系统》开题报告
一、引言
随着互联网技术的飞速发展,招聘行业积累了大量的数据,包括职位信息、应聘者信息、企业信息等。这些数据中蕴含着丰富的价值,能够帮助企业和求职者更好地匹配,提高招聘效率。然而,传统的数据处理和分析方法在处理如此庞大的数据量时显得力不从心,无法满足招聘行业对实时性和准确性的需求。因此,开发一个高效的招聘数据推荐与预测系统显得尤为重要。Spark和Hive作为大数据处理领域的优秀工具,以其快速处理能力和数据仓库功能,为招聘数据分析提供了有力支持。
二、研究背景与意义
2.1 研究背景
招聘行业面临着海量数据的挑战,包括职位发布、简历投递、面试反馈等多个环节的数据。这些数据不仅数量庞大,而且种类繁多,如何高效地处理和分析这些数据,提取有价值的信息,成为招聘行业亟待解决的问题。
2.2 研究意义
本研究旨在设计并实现一个基于Spark和Hive的招聘推荐与预测系统,通过对招聘数据的深度挖掘和分析,为企业和求职者提供更精准、更高效的匹配服务。该系统不仅能够提高数据处理和分析的效率,还能通过智能化的推荐和预测算法,提升招聘的准确性和实时性。
三、研究内容
3.1 系统架构
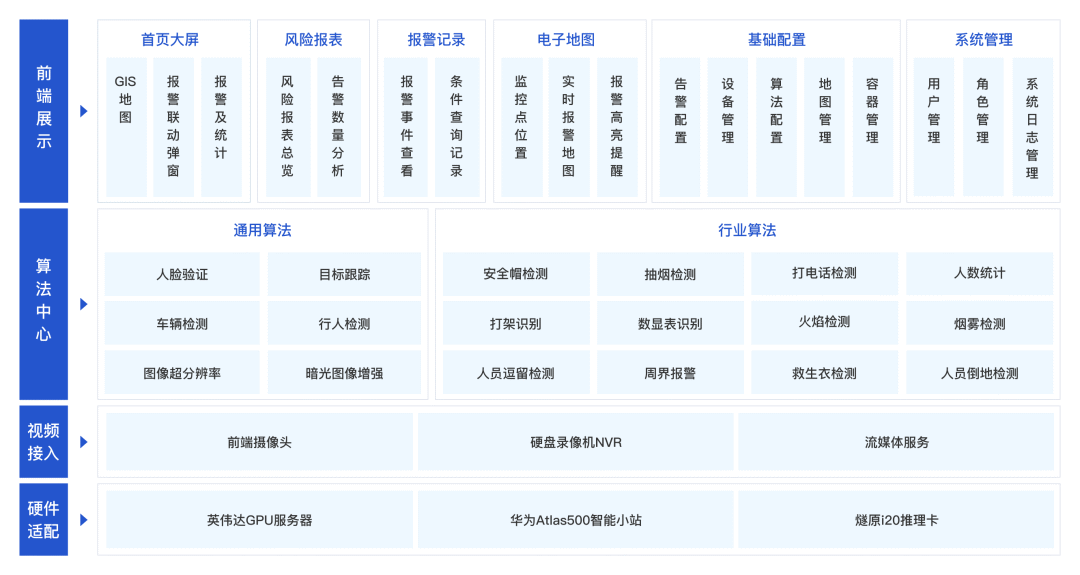
本系统主要由数据采集模块、数据存储模块、数据处理与分析模块、推荐与预测模块、可视化展示模块组成。其中,数据采集模块使用Python爬虫等技术从各大招聘网站采集数据;数据存储模块利用Hadoop HDFS和Hive进行数据仓库的建设和管理;数据处理与分析模块利用Spark进行快速的数据处理和分析;推荐与预测模块基于机器学习算法实现职位推荐和薪资预测;可视化展示模块则采用Echarts等前端技术,将分析结果以图表的形式直观展示。
3.2 数据采集与预处理
使用Python爬虫技术(如Scrapy、Selenium等)从各大招聘网站爬取招聘信息,包括职位名称、薪资范围、工作地点、公司规模、发布时间等。然后对采集到的数据进行清洗、去重、格式化等预处理操作,为后续分析提供高质量的数据基础。
3.3 数据存储
将预处理后的数据存储到Hadoop HDFS中,并利用Hive进行数据仓库的建设和管理。Hive提供SQL查询接口,方便进行复杂的数据查询和分析。
3.4 数据处理与分析
利用Spark的分布式计算能力,对存储在HDFS中的招聘数据进行快速处理和分析。包括数据挖掘、关联分析、聚类分析以及时间序列预测等,提取有价值的信息和特征。
3.5 推荐与预测
基于机器学习算法(如随机森林、梯度提升树等),构建职位推荐和薪资预测模型。通过对用户行为和职位属性的深度分析,实现个性化的职位推荐和薪资预测。
3.6 可视化展示
采用Echarts等前端技术,设计并实现一个直观、易用的可视化界面,展示推荐结果、薪资预测、职位分布、行业趋势等分析结果。帮助用户快速理解数据,优化招聘决策。
四、研究方法
4.1 文献研究法
通过查阅国内外相关文献,了解Spark、Hive以及招聘数据分析与推荐系统的研究现状和发展趋势,为本研究提供理论支持。
4.2 系统开发法
采用软件工程的方法,按照需求分析、系统设计、系统实现、系统测试等阶段进行系统开发。确保系统能够满足用户需求,并具备良好的稳定性和可扩展性。
4.3 实证研究法
通过实际招聘数据对系统进行测试和验证,评估系统的性能和效果,并进行必要的优化。确保系统能够在实际应用中发挥良好作用。
五、预期成果
5.1 技术成果
完成Spark+Hive招聘推荐与预测系统的设计与实现,包括数据采集模块、数据存储模块、数据处理与分析模块、推荐与预测模块、可视化展示模块的设计与实现。
5.2 理论成果
撰写一篇关于Spark+Hive招聘推荐与预测系统的学术论文,总结研究成果和技术创新点。为招聘数据分析与推荐系统的研究提供新的思路和方法。
5.3 应用成果
将系统应用于实际招聘场景,提高招聘企业的数据处理能力、推荐准确性和决策支持能力。为招聘行业提供高效、精准的招聘解决方案。
六、研究计划
6.1 第一阶段(1-2个月)
完成Hadoop集群的搭建与配置,确保系统能够正常运行。同时,进行数据采集模块的初步设计与实现。
6.2 第二阶段(3-4个月)
完成数据存储模块和数据处理与分析模块的设计与实现。对采集到的数据进行清洗、去重、格式化等预处理操作,并利用Spark进行快速的数据处理和分析。
6.3 第三阶段(5-6个月)
构建推荐与预测模型,实现个性化的职位推荐和薪资预测。同时,设计并实现可视化展示模块,将分析结果以图表的形式直观展示。
6.4 第四阶段(7-8个月)
进行系统测试和优化,通过实际招聘数据对系统进行测试和验证,评估系统的性能和效果,并进行必要的优化。确保系统能够在实际应用中发挥良好作用。
6.5 第五阶段(9-10个月)
撰写论文,准备答辩。总结研究成果和技术创新点,撰写学术论文并准备毕业答辩。
七、参考文献
(此处省略具体参考文献,实际撰写时应详细列出所有引用的文献。)
本开题报告旨在明确《Spark+Hive招聘推荐与预测系统》的研究内容、方法、计划和预期成果,为后续的研究工作提供指导。希望通过本研究的开展,能够为招聘行业的数据处理和推荐预测提供新的思路和方法,推动招聘行业的智能化发展。





























![[MySQL表的增删改查-进阶]](https://i-blog.csdnimg.cn/direct/626d73342e0c406894e1017eafd30cf2.png)