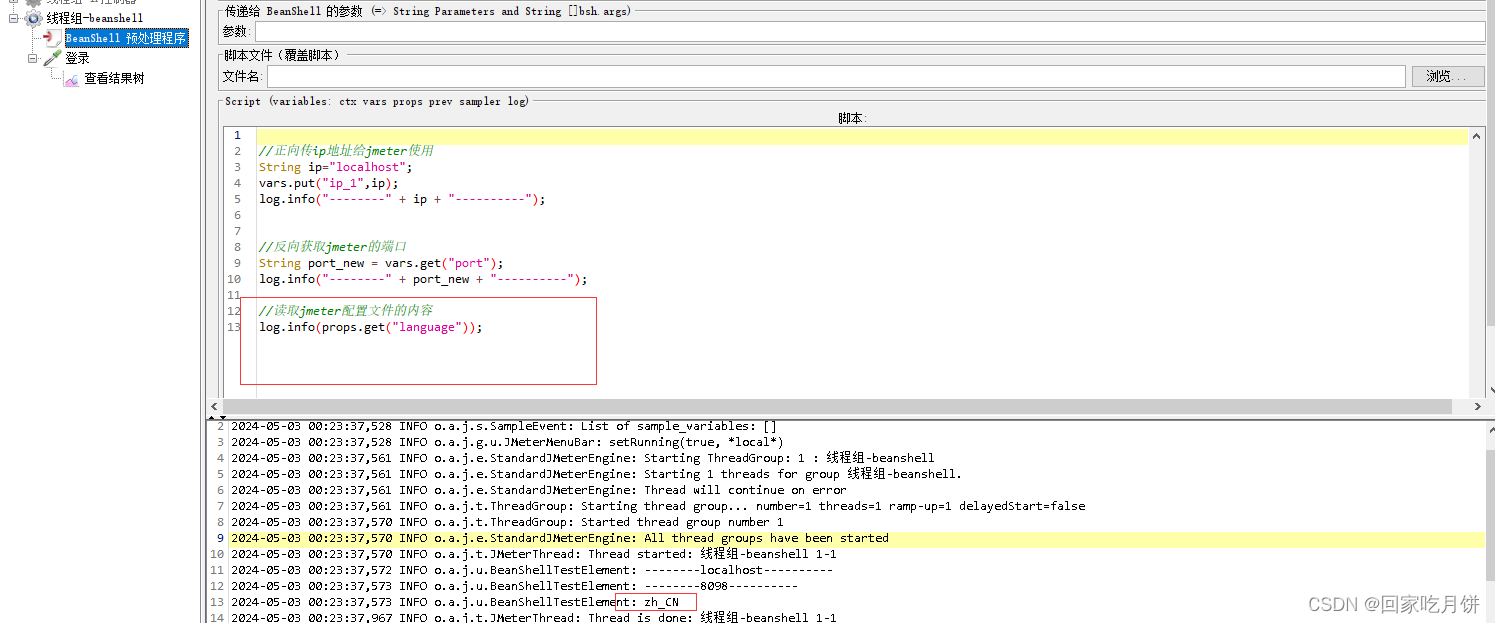
文章目录
- 一、说明
- 二、理解集成学习
- 2.1 什么是 Bagging?
- 2.2 Bagging 与 Boosting
- 2.3 套袋的优点
- 三、Python 中的 Bagging:简短教程
- 3.1 数据集
- 3.2 训练机器学习模型
- 3.3 模型评估
- 四、装袋分类器
- 4.1 评估集成模型
- 4.2 最佳实践和技巧
- 五、结论
一、说明
集成方法是机器学习中强大的技术,它可以结合多种模型来提高整体预测准确性和模型稳定性。Bootstrap Aggregating(俗称 Bagging)是一种流行且广泛实施的集成方法。在本教程中,我们将深入研究 bagging、其工作原理以及其优势所在。我们将它与另一种集成方法 (Boosting) 进行比较,并查看 Python 中的 bagging 示例。最后,您将对 bagging 有扎实的了解,包括最佳实践。
二、理解集成学习
集成建模是一种结合多种机器学习模型来提高整体预测性能的技术。其基本思想是将一组弱学习器组合在一起形成一个强学习器。
集成模型通常包括两个步骤:
1 多个机器学习模型进行独立训练。
2 他们的预测会以某种方式汇总,例如通过投票、平均或加权。然后使用该集合进行总体预测。

集成往往会产生更好的结果,因为不同的模型可以相互补充并克服各自的弱点。它们还可以减少方差并防止过度拟合。
一些流行的集成方法包括 bagging、boosting 和 stacking。集成学习广泛应用于分类、回归和聚类等机器学习任务,以提高准确性和稳健性。
2.1 什么是 Bagging?
Bagging(引导聚合)是一种集成方法,涉及在数据的随机子集上独立训练多个模型,并通过投票或平均聚合它们的预测。

具体来说,每个模型都是在随机抽样的数据子集上进行训练的,这意味着可以多次选择单个数据点。这个随机子集称为引导样本。通过在不同的引导程序上训练模型,bagging 可以减少各个模型的方差。它还通过将组成模型暴露给数据集的不同部分来避免过度拟合。
然后通过简单的平均法将所有采样模型的预测结果合并起来,得出总体预测。这样,聚合模型就吸收了各个模型的优势,并抵消了它们的误差。
Bagging 在减少方差和过度拟合方面特别有效,使得模型更加稳健和准确,特别是在单个模型容易出现高度可变的情况。
2.2 Bagging 与 Boosting
Boosting 是另一种流行的集成方法,经常与 Bagging 进行比较。主要区别在于组成模型的训练方式。
在 bagging 中,模型在不同的随机数据子集上独立并行训练。而在 boosting 中,模型按顺序训练,每个模型都会从前一个模型的错误中学习。此外,bagging 通常涉及模型的简单平均,而 boosting 则根据准确率分配权重。

Bagging 可减少方差,而 boosting 可减少偏差。Bagging 可用于决策树等不稳定模型,而 boosting 更适用于线性回归等稳定模型。
两种方法各有优缺点。Bagging 更容易并行运行,而 boosting 则更强大、更准确。在实践中,在新的问题上测试这两种方法有助于了解哪种方法效果更好。
2.3 套袋的优点
以下是 bagging 的一些主要优点:
1 减少过度拟合:它可以减少过度拟合模型的机会,从而提高看不见的数据的模型准确性。
2 减少模型方差:在不同数据子集上训练的多个模型平均它们的预测,从而比单个模型产生更低的方差。
3 提高稳定性:训练数据集的变化对 bagged 模型的影响较小,使得整体模型更加稳定。
4 处理高变异性:对于决策树等往往具有高方差的算法特别有效。
5 可并行计算:集成中的每个模型都可以独立训练,从而实现并行处理和有效利用计算资源。
6 易于理解和实施: bagging 背后的概念很简单,无需对学习算法进行复杂的修改即可实现。
7 适合处理噪声数据:平均过程有助于减少最终预测中的噪声。
8 处理不平衡数据: Bagging 可以在数据集不平衡的情况下提供帮助,从而提高这种情况下模型的性能。
三、Python 中的 Bagging:简短教程
在本 Python 教程中,我们将在电信客户流失数据集上训练决策树分类模型,并使用 bagging 集成方法来提高性能。我们将使用DataLab获取数据集并运行我们的代码。此DataLab 工作簿中也提供了该代码,您可以将其复制到浏览器中运行,而无需安装任何内容。
3.1 数据集
电信客户流失数据集来自伊朗一家电信公司。数据集中的每一行都对应一位客户在一年中的活动,包括通话失败信息、订阅时长以及表明客户是否已离开服务的流失标签。
首先,我们将加载数据集并查看前 5 行。
import pandas as pd
customer = pd.read_csv("data/customer_churn.csv")
customer.head()

之后,我们将创建独立变量(X)和因变量(y)。然后,我们将数据集分成训练子集和测试子集。
X = customer.drop("Churn", axis=1)
y = customer.Churn
# Split into train and test
from sklearn.model_selection import train_test_split, cross_val_score
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=1)
3.2 训练机器学习模型
我们将创建一个简单的机器学习管道并在其上拟合训练数据集。管道将在将输入提供给决策树分类器之前对数据进行规范化。
from sklearn.tree import DecisionTreeClassifier
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import Pipeline
pipeline = Pipeline([
('scaler', StandardScaler()),
('classifier', DecisionTreeClassifier(random_state=42))
])
pipeline.fit(X_train, y_train)

参加“使用 Python 中的基于树的模型进行机器学习”课程,学习如何使用基于树的模型和集成通过 scikit-learn 进行回归和分类。
3.3 模型评估
我们将评估决策树模型,以便将其与集成模型进行比较。我们将通过对测试数据表进行预测来生成分类报告。
from sklearn.metrics import classification_report
# Make prediction on the testing data
y_pred = pipeline.predict(X_test)
# Classification Report
print(classification_report(y_pred, y_test))
我们的模型在多数类别“0”上实现了 96% 的精确度和 97% 的召回率,但在少数类别“1”上表现不佳。

为了更好地了解模型的性能,我们将进行交叉验证并计算相应的分数。
# Evaluate the classifier using cross-validation
cv_scores = cross_val_score(pipeline, X, y, cv=5)
print(f"Cross-validation scores: {cv_scores}")
print(f"Mean CV accuracy: {np.mean(cv_scores):.2f}")
分数差异很大,最高分为 95%,最低分为 92%。
分数差异很大,最高分为 95%,最低分为 92%。
Cross-validation scores: [0.95079365 0.94126984 0.93492063 0.94285714 0.92222222]
Mean CV accuracy: 0.94
四、装袋分类器
现在,让我们使用基础估计器作为管道(标量+决策树分类器)创建一个 bagging 分类器,并在训练数据集上对其进行训练。
我们可以通过增加来提高模型性能n_estimators,但对于基线结果来说 50 已经足够了。
from sklearn.ensemble import BaggingClassifier
# Create a bagging classifier with the decision tree pipeline
bagging_classifier = BaggingClassifier(base_estimator=pipeline, n_estimators=50, random_state=42)
# Train the bagging classifier on the training data
bagging_classifier.fit(X_train, y_train)

4.1 评估集成模型
让我们评估集成模型的结果并将其与单一模型的性能进行比较。为此,我们将在测试数据集上生成分类报告。
# Make prediction on the testing data
y_pred = bagging_classifier.predict(X_test)
# Classification Report
print(classification_report(y_pred, y_test))
可以看到,模型性能得到了相对提升。少数类的准确率和召回率分别从 79% 提高到了 80% 和从 77% 提高到了 82%。这是一个显著的进步。

现在让我们计算交叉验证分数。
# Evaluate the classifier using cross-validation
cv_scores = cross_val_score(bagging_classifier, X, y, cv=5)
print(f"Cross-validation scores: {cv_scores}")
print(f"Mean CV accuracy: {np.mean(cv_scores):.2f}")
我们的交叉验证分数方差较小,范围从 94% 到 96%。模型的整体准确率也从 94% 提高到了 95%。
Cross-validation scores: [0.95396825 0.95714286 0.94126984 0.96190476 0.95714286]
Mean CV accuracy: 0.95
装袋技术是机器学习应用中提高模型准确性和稳定性的有用工具。
通过“Python 中的集成方法”课程学习 bagging、boosting 和 stacking 等集成技术,以在 Python 中构建先进而有效的机器学习模型。
4.2 最佳实践和技巧
在机器学习中使用 bagging 时,遵循最佳实践和技巧可以最大程度地提高其有效性:
1 当您拥有决策树等高方差模型时,请使用 bagging来提高稳定性。
2 将 bagging 与交叉验证结合起来,可以更可靠地评估您的模型。
3 使用随机森林(袋装决策树)作为一种强大的、可立即使用的装袋技术。
4 装袋时设置较高的n_estimators 值(如 100-200)以获得最大收益。
5 使用可以轻松实现 Bagging 的并行化n_jobs。在多个 CPU/机器上实现它,以加快训练速度。
6 由于 bagging 依赖于引导抽样,因此请确保每个模型都在足够多样化的数据子集上进行训练。
7 在聚合之前,使用 优化每个模型的性能GridSearchCV。单个模型的良好性能通常意味着整体性能的更好。
阅读MLOps(机器学习操作)最佳实践,了解成功的 MLOps 实践,以实现可靠且可扩展的机器学习系统部署。
五、结论
在本教程中,我们探索了 bagging,一种强大的集成机器学习技术。Bagging 聚合多个模型以提高整体预测性能。我们将其与 boosting 进行了比较,并了解了它相对于使用单个模型的优势。
最后,我们在电信客户流失数据集上用 Python 实现了 bagging 分类器。与单个决策树相比,bagged 决策树集合提高了准确性和少数类性能。此外,我们还学到了宝贵的技巧和窍门,可以最大限度地提高 bagging 在机器学习中的有效性。
如果您想成为一名专业的机器学习工程师,请先报名参加Python 机器学习科学家职业课程。您将学习如何使用 Python 编程语言训练监督、无监督和深度学习模型。



![[Linux入门]---进程替换](https://i-blog.csdnimg.cn/direct/72ee2e15599c48ac84ae759a09d3ef24.png)