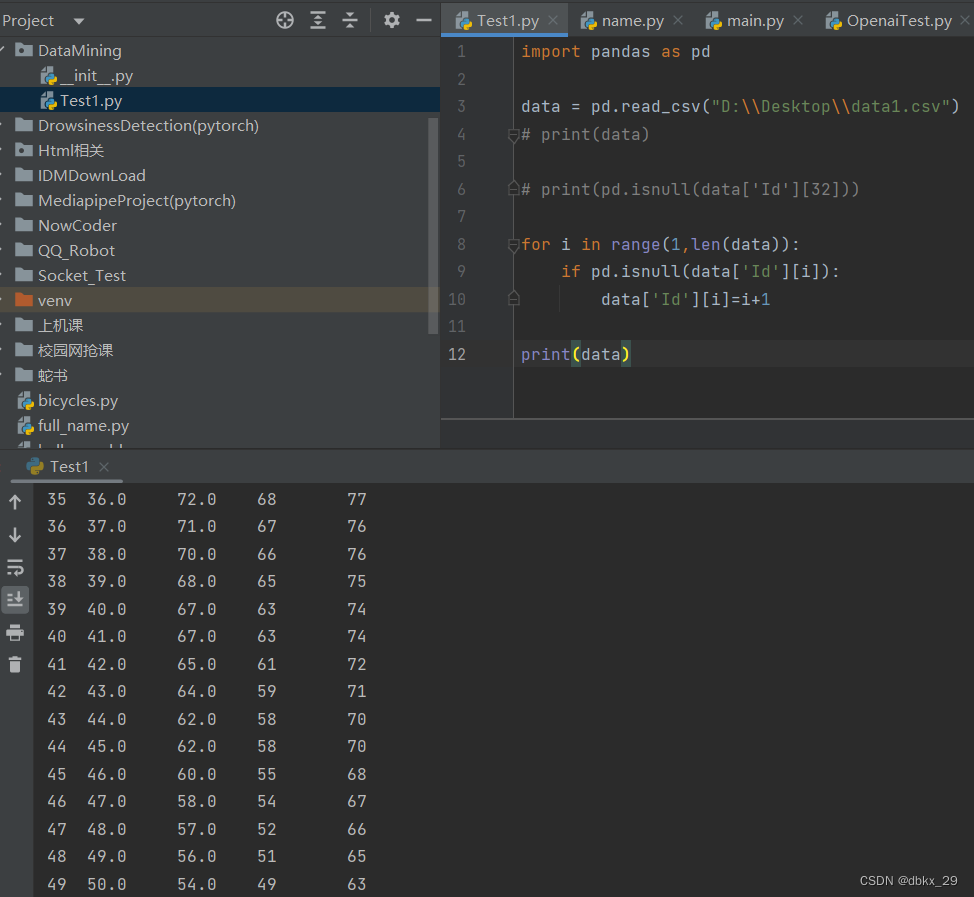
【实验内容】
- 程序清单
import pandas as pd
import numpy as np
# 读入文件,存放在字典data里
data = pd.read_csv("D:\\Desktop\\data1.csv")
# 填入Id列空缺的值
for i in range(1,len(data)):
if pd.isnull(data['Id'][i]):
data['Id'][i]=i+1
# Id属性列去重,保留重复时第一个值,默认将原来的东西覆盖
data.drop_duplicates(subset=['Id'],keep='first',inplace=True)
# 如果字典内有表格是NaN,把他替换为0
for (name,value) in data.items():
for i in range(1,len(data[name])): #对于name列的所有单元格
if pd.isnull(data[name][i]):
data[name][i]=0
# 为数据增加一个字段Average, 默认赋值为对每一行第1列(Id是第0列)以后所有数据取平均值,对行执行这个操作
# 关于axis:Keep in mind that axis=1 in mean(axis=1) is used to calculate the mean across each row.
# If you used axis=0 instead, the mean would be calculated across each column.
data = data.assign(Average = np.mean(data.iloc[:, 1:], axis=1))
# print(data)
# 将每一行Average的值的精度缩小到16位浮点数
data['Average'] = data['Average'].astype("float16")
# 按照 Average降序排序,覆盖以前的东西
data.sort_values("Average",ascending=False,inplace=True)
print(data)
# 降序排序后越靠前的行值就越大。data.iloc[x,y]代表data字典内第x行第y列(第y个属性)
# 这里的意思是在整个data范围内从第一个(降序,最大的)开始搜,搜到不对的了就停下
for i in range(len(data)):
if data.iloc[i, -1] != data.iloc[0,-1]:
break
else:
print(data.iloc[i,:])
# range(1,4)实际上就是1,2,3,对应语文数学英语三个列,cnt用户计数其中大于60的学生个数
for i in range(1,4):
cnt = 0
for j in range(len(data)):
if data.iloc[j,i]>=60:
cnt += 1
print(cnt)
# 将我们处理完的data输出
data.to_csv("E:\\private\\实验报告\\数据挖掘\\230905-1\\data1.csv")
2.截图:




【实验体会】
我从这次实验中学到了:用pandas库读取csv文件作为一个python数据对象,与将其逆向至一个csv文件,用pd.isnull()方法判断是否为空值;用DataFrame对象自带的drop_duplicates()对一列数据去重,为数据通过assign的方式添加属性列并指定初始值。更改数据类型,对数据排序。以及通过iloc方法通过下标的形式切分数据表。
收获良多、感触颇丰!
以下是原始的data1.csv表:
| Id | Chinese | Math | English |
| 1 | 66 | 70 | 57 |
| 2 | 67 | 71 | 59 |
| 3 | 68 | 72 | 60 |
| 4 | 70 | 73 | 62 |
| 5 | 71 | 74 | 63 |
| 6 | 72 | 75 | 64 |
| 7 | 73 | 75 | 65 |
| 8 | 73 | 76 | 67 |
| 9 | 74 | 77 | 68 |
| 10 | 75 | 77 | 69 |
| 11 | 76 | 78 | 70 |
| 12 | 76 | 78 | 71 |
| 13 | 77 | 79 | 72 |
| 14 | 78 | 79 | 73 |
| 15 | 78 | 79 | 74 |
| 16 | 78 | 79 | 75 |
| 17 | 79 | 79 | 75 |
| 18 | 79 | 79 | 76 |
| 19 | 79 | 79 | 77 |
| 20 | 79 | 79 | 77 |
| 21 | 79 | 79 | 78 |
| 79 | 79 | 78 | |
| 23 | 79 | 78 | 79 |
| 24 | 79 | 78 | 79 |
| 25 | 79 | 77 | 79 |
| 79 | 77 | 79 | |
| 27 | 78 | 76 | 79 |
| 28 | 78 | 76 | 79 |
| 29 | 77 | 75 | 79 |
| 30 | 74 | 79 | |
| 31 | 76 | 73 | 79 |
| 32 | 75 | 72 | 79 |
| 33 | 74 | 71 | 78 |
| 73 | 70 | 78 | |
| 35 | 73 | 69 | 77 |
| 36 | 72 | 68 | 77 |
| 37 | 71 | 67 | 76 |
| 38 | 70 | 66 | 76 |
| 39 | 68 | 65 | 75 |
| 40 | 67 | 63 | 74 |
| 67 | 63 | 74 | |
| 42 | 65 | 61 | 72 |
| 43 | 64 | 59 | 71 |
| 44 | 62 | 58 | 70 |
| 45 | 62 | 58 | 70 |
| 46 | 60 | 55 | 68 |
| 58 | 54 | 67 | |
| 48 | 57 | 52 | 66 |
| 49 | 56 | 51 | 65 |
| 50 | 54 | 49 | 63 |

最全的Linux教程,Linux从入门到精通
======================
-
linux从入门到精通(第2版)
-
Linux系统移植
-
Linux驱动开发入门与实战
-
LINUX 系统移植 第2版
-
Linux开源网络全栈详解 从DPDK到OpenFlow

第一份《Linux从入门到精通》466页
====================
内容简介
====
本书是获得了很多读者好评的Linux经典畅销书**《Linux从入门到精通》的第2版**。本书第1版出版后曾经多次印刷,并被51CTO读书频道评为“最受读者喜爱的原创IT技术图书奖”。本书第﹖版以最新的Ubuntu 12.04为版本,循序渐进地向读者介绍了Linux 的基础应用、系统管理、网络应用、娱乐和办公、程序开发、服务器配置、系统安全等。本书附带1张光盘,内容为本书配套多媒体教学视频。另外,本书还为读者提供了大量的Linux学习资料和Ubuntu安装镜像文件,供读者免费下载。

本书适合广大Linux初中级用户、开源软件爱好者和大专院校的学生阅读,同时也非常适合准备从事Linux平台开发的各类人员。
需要《Linux入门到精通》、《linux系统移植》、《Linux驱动开发入门实战》、《Linux开源网络全栈》电子书籍及教程的工程师朋友们劳烦您转发+评论
加入社区》https://bbs.csdn.net/forums/4304bb5a486d4c3ab8389e65ecb71ac0





![P1071 [NOIP2009 提高组] 潜伏者](https://i-blog.csdnimg.cn/direct/1c18230df43d4823a3833aeb2ec8424b.png)











