echo“”>>/etc/security/limits.conf
echo“*softnproc65535″>>/etc/security/limits.conf
echo“*hardnproc65535″>>/etc/security/limits.conf
echo“*softnofile65535″>>/etc/security/limits.conf
echo“*hardnofile65535″>>/etc/security/limits.conf
echo“”>>/root/.bash_profile
echo“ulimit-n65535″>>/root/.bash_profile
echo“ulimit-u65535″>>/root/.bash_profile
最后重启机器或者执行ulimit-u655345&&ulimit-n65535
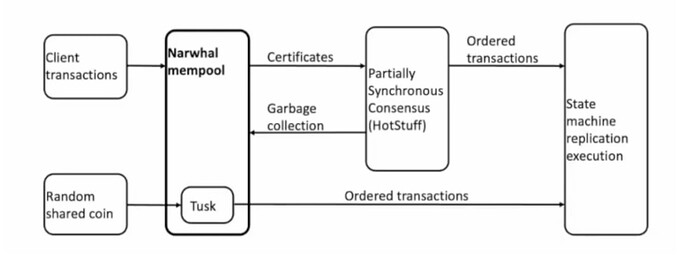
10.ibdata1和mysql-bin致磁盘空间问题
问题:
2.51磁盘空间报警,经查发现ibdata1和mysql-bin日志占用空间太多(其中ibdata1超过120G,mysql-bin超过80G)
原因:
ibdata1是存储格式,在INNODB类型数据状态下,ibdata1用来存储文件的数据和索引,而库名的文件夹里的那些表文件只是结构而已。
innodb存储引擎有两种表空间的管理方式,分别是:
1)共享表空间(可拆分为多个小的表空间文件),这个是我们目前多数数据库使用的方法;
2)独立表空间,每一个表有一个独立的表空间(磁盘文件)
对于两种管理方式,各有优劣,具体如下:
①共享表空间:
优点:可以将表空间分成多个文件存放到不同的磁盘上(表空间文件大小不受表大小的限制,一个表可以分布在不同步的文件上)
缺点:所有数据和索引存放在一个文件中,则随着数据的增加,将会有一个很大的文件,虽然可以把一个大文件分成多个小文件,但是多个表及索引在表空间中混合存储,这样如果对于一个表做了大量删除操作后表空间中将有大量空隙。对于共享表空间管理的方式下,一旦表空间被分配,就不能再回缩了。当出现临时建索引或是创建一个临时表的操作表空间扩大后,就是删除相关的表也没办法回缩那部分空间了。
②独立表空间:在配置文件(my.cnf)中设置:innodb_file_per_table
特点:每个表都有自已独立的表空间;每个表的数据和索引都会存在自已的表空间中。
优点:表空间对应的磁盘空间可以被收回(Droptable操作自动回收表空间,如果对于删除大量数据后的表可以通过:altertabletbl_nameengine=innodb;回缩不用的空间。
缺点:如果单表增加过大,如超过100G,性能也会受到影响。在这种情况下,如果使用共享表空间可以把文件分开,但有同样有一个问题,如果访问的范围过大同样会访问多个文件,一样会比较慢。如果使用独立表空间,可以考虑使用分区表的方法,在一定程度上缓解问题。此外,当启用独立表空间模式时,需要合理调整innodb_open_files参数的设置。
解决:
1)ibdata1数据太大:只能通过dump,导出建库的sql语句,再重建的方法。
2)mysql-binLog太大:
①手动删除:
删除某个日志:mysql>PURGEMASTERLOGSTO‘mysql-bin.010′;
删除某天前的日志:mysql>PURGEMASTERLOGSBEFORE’2010-12-2213:00:00′;
②在/etc/my.cnf里设置只保存N天的bin-log日志
expire_logs_days=30//BinaryLog自动删除的天数
二、故障排查汇总表


问题 1:文件系统破坏导致系统无法启动
Checking root filesystem /dev/sda6 contains a file system with errors,
check forced An error occurred during the file system check
这个错误可以看出,操作系统 / dev/sda6 分区文件系统出现了问题,这个问题发生的机率很高,通常引起这个问题的原因主要是系统突然断电,引起文件系统结构不一致,一般情况下,解决此问题的方法是采用 fsck 命令,进行强制修复。
# umount /dev/sda6
# fsck.ext3 -y /dev/sda6
问题 2:“Argument list too long” 错误与解决方法
# crontab -e
编辑完后保存退出后,报错 no space left on device
根据上面的报错了解到是磁盘空间满了,那么首先是检查磁盘空间,
# df -h
查看到是 / var 磁盘分区空间已经达到 100%,至此定位了问题所在。是 / var 磁盘空间饱满导致,因为 crontab 会在保存时将文件信息写到 / var 目录下面,然而这个磁盘没有空间了,所以报错。
接着通过命令 du –sh * 命令检查 / var 目录下面的所有文件或者目录的大小,发现 / var/spool/clientmqueue 目录占用了 / var 整个分区大小的 90%,那么 / var/spool/clientmqueue 目录下的文件都是怎么产生的,能否删除,基本上都是邮件信息,可以删除
# rm *
/bin/rm :argument list too long
当在 linux 系统中试图传递太多参数给一个命令时,就会出现 “argument list too long” 错误,这是 linux 系统一直以来都有的限制,查看这个限制可以通过命令 “getconf ARG_MAX” 来实现,
# getconf ARG_MAX
# more /etc/issue 查看版本
解决方法:1、
# rm [a-n]* -rf
# rm [o-z]* -rf
2、使用 find 命令来删除
# find /var/spool/clientmqueue –type f –print –exec rm –f {} ;
3、通过 shell 脚本
#/bin/bash
RM_DIR=’/var/spool/clientmqueue’
cd $RM_DIR
for I in `ls`
do
rm –f $i
done
4、重新编译内核
需要手动增加内核中分配给命令行参数的页数,打开 kernel source 下面的 include/linux/binfmts.h 文件,找到如下行:
#denfine MAX_ARG_PAGES 32
将 32 改为更大的值,例如 64 或者 128,然后重新编译内核
问题 3:inode 耗尽导致应用故障
客户的一台 Oracle 数据库如武器在关机重启后,Oracle 监听无法启动,提示报错 Linux error : No space left on device
从输出信息看出来是因为磁盘耗尽导致监听无法启动,因为 Oracle 在启动监听时需要创建监听日志文件,于是首先查看磁盘空间使用情况
# df -h
从磁盘输出信息可知,所有的分区磁盘空间都还有剩余不少,而 Oracle 监听写日志的路径在 / var 分区下,/var 下分区空间足够。
解决思路:
既然错误提示语磁盘空间有关,那就深入研究关于磁盘空间的问题,在 linux 系统中对磁盘空间的占用分为三个部分:第一个是物理磁盘空间,第二个是 inode 节点所占用的磁盘空间,第三个是 linux 用来存放信号量的空间,而平时接触较多的是物理磁盘空间。既然不是物理磁盘空间的问题,接着就检查是否是 inode 节点耗尽的问题,通过执行命令 “df -i” 查看可用的 inode 节点。由输出结果看出确实是因为 inode 耗尽导致无法写入文件。
可以通过下面的命令查看某个磁盘分区 inode 的总数
# dumpe2fs -h /dev/sda3 |grep ‘Inode count’
每个 inode 都有一个号码,操作系统用 inode 号码来区分不同的文件,通过‘ls -i’命令可以查看文件名对应的 inode 号
如果要查看这个文件更详细的 inode 信息,可以通过 stat 命令来实现
# stat install.log
解决问题
# find /var/spool/clientmqueue/ -name “*” -exec rm -rf {} ;
问题 4:文件已经删除,但是空间没有释放的原因
运维监控系统发来通知,报告一台服务器空间满了,登陆服务器查看,根分区确实满了,这里先说一下服务器的一些删除策略,由于 linux 没有回收站功能,所以线上服务器上所有要删除的文件都会先移到系统 / tmp 目录下,然后定期清除 / tmp 目录下的数据。这个策略本身没有什么问题,但是通过检查发现这台服务器的系统分区中并没有单独划分 / tmp 分区,这样 / tmp 下的数据其实占用根分区的空间,既然找到了问题,那么删除 / tmp 目录下一些占用空间较大的数据文件即可。
# du -sh /tmp/* | sort -nr |head -3
通过命令发现在 / tmp 目录下有个 66G 大小的文件 access_log,这个文件应该是 apache 产生的访问日志文件,从日志大小来看,应该是很久没有清理的 apache 日志文件了,基本判定是这个文件导致的根空间爆满,在确认此文件可以删除后,执行如下删除命令,
# rm /tmp/access_Iog
# df -h
从输出来看,根分区空间仍然没有释放,这是怎么回事
一般来说不会出现删除文件后空间不释放的情况,但是也存在例外,比如文件进程锁定,或者有进程一直在向这个文件写数据,要理解这个问题,就需要知道 linux 下文件的存储机制和存储结构。
一个文件在文件系统中存放分为两个部分:数据部分和指针部分,指针位于文件系统的 meta-data 中,在将数据删除后,这个指针就从 meta-data 中清除了,而数据部分存储在磁盘中。在将数据对应的指针从 meta-data 中清除后,文件数据部分占用的空间就可以被覆盖并写入新的内容,之所以出现删除 access_log 文件后,空间还没有释放,就是因为 httpd 进程还在一直向这个文件写入内容,导致虽然删除了 access_Ilog 文件,但是由于进程锁定,文件对应的指针部分并未从 meta-data 中清除,而由于指针并未删除,系统内核就认为文件并未被删除,因此通过 df 命令查询空间并未释放。
问题排查:
既然有了解决思路,那么接下来看看是否有进程一直在向 access_log 文件中写入数据,这里需要用到 linux 下的 losf 命令,通过这个命令可以获取一个仍然被应用程序占用的已删除文件列表
# lsof | grep delete
从输出可以看出,/tmp/access_log 文件被进程 httpd 锁定,而 httpd 进程还一直向这个文件写入日志数据,最后一列的‘deleted’状态说明这个日志文件已经被删除,但是由于进程还在一直向此文件写入数据,因此空间并未释放。
解决问题:
到这里问题就基本排查清楚了,解决这一类问题的方法有很多,最简单的方法就是关闭或者重启 httpd 进程,当然重启操作系统也可以。不过这些并不是最好的办法,对待这种进程不停对文件写日志的操作,要释放文件占用的磁盘空间,最好的方法是在线清空这个文件,具体可以通过如下命令完成:
# echo “”>/tmp/access_log
通过这种方法,磁盘空间不但可以马上释放,也可以保障进城继续向文件写入日志,这种方法经常用于在线清理 apache /tomcat/nginx 等 web 服务产生的日志文件。
问题 5:“too many open files” 错误与解决方法
问题现象:这是一个基于 java 的 web 应用系统,在后台添加数据时提示无法添加,于是登陆服务器查看 tomcat 日志,发现如下异常信息,java.io.IOException: Too many open files
通过这个报错信息,基本判断是系统可以用的文件描述符不够了,由于 tomcat 服务室系统 www 用户启动的,于是以 www 用户登陆系统,通过 ulimit –n 命令查看系统可以打开最大文件描述符的数量,输出如下:
$ ulimit -n
65535
可以看到这台服务器设置的最大可以打开的文件描述符已经是 65535 了,这么大的值应该够用了,但是为什么提示这样的错误呢
解决思路,这个案例涉及 ulimit 命令的使用
在使用 ulimit 时,有以下几种使用方法:
1、 在用户环境变量中加入
如果用户使用的是 bash,那么可以在用户目录的环境变量文件. bashrc 或者. bash_profile 中加入 “ulimit –u128” 来限制用户最多可以使用 128 个进程
2、 在应用程序的启动脚本中加入
如果应用程序是 tomcat,那么可以再 tomcat 的启动脚本 startup.sh 中加入‘ulimit -n 65535’来限制用户最多可以使用 65535 个文件描述符
3、 直接在 shell 命令终端执行 ulimit 命令
这种方法的资源限制仅仅在执行命令的终端生效,在退出或者和关闭终端后,设置失效,并且这个设置不影响其他 shell 终端
解决问题:
在了解 ulimit 知识后,接着上面的案例,既然 ulimit 设置没有问题,那么一定是设置没有生效导致的,接下来检查下启动 tomcat 的 www 用户环境变量是否添加 ulimit 限制,检查后发现,www 用户并无 ulimit 限制。于是继续检查 tomcat 启动脚本 startup.sh 文件是否添加了 ulimit 限制,检查后发现也没有添加。最后考略是否将限制加到了 limits.conf 文件中,于是检查 limits.conf 文件,操作如下
# cat /etc/security/limits.conf | grep www
www soft nofile 65535
www hard nofile 65535
从输出可知,ulimit 限制加在 limits.conf 文件中,既然限制已经添加了,配置也没有什么错,为何还会报错,经过思考,判断只有一种可能,那就是 tomcat 的启动时间早于 ulimit 资源限制的添加时间,于是首先查看下 tomcat 启动时间,操作如下
# uptime
Up 283 days
# pgrep -f tomcat
4667
# ps -eo pid,lstart,etime|grep 4667
4667 Sat Jul 6 09;33:39 2013 77-05:26:02
从输出可以看出,这台服务器已经有 283 没有重启了,而 tomcat 是在 2013 年 7 月 6 日 9 点启动的,启动了将近 77 天,接着继续看看 limits.conf 文件的修改时间,
# stat /etc/security/limits.conf
通过 stat 命令清除的看到,limits.conf 文件最后的修改时间是 2013 年 7 月 12,晚于 tomcat 启动时间,清楚问题后,解决问题的方法很简单,重启一下 tomcat 就可以了。
问题 6:Read-only file system 错误与解决方法
解析:出现这个问题的原因有很多种,可能是文件系统数据块出现不一致导致的,也可能是磁盘故障造成的,主流 ext3/ext4 文件系统都有很强的自我修复机制,对于简单的错误,文件系统一般都可以自行修复,当遇到致命错误无法修复的时候,文件系统为了保证数据一致性和安全,会暂时屏蔽文件系统的写操作,讲文件系统 变为只读,今儿出现了上面的 “read-only file system” 现象。
手工修复文件系统错误的命令式 fsck,在修复文件系统前,最好卸载文件系统所在的磁盘分区
# umount /www/data
Umount : /www/data: device is busy
提示无法卸载,可能是这个磁盘中还有文件对应的进程在运行,检查如下:
# fuser -m /dev/sdb1
/dev/sdb1: 8800
接着检查一下 8800 端口对应的什么进程,
# ps -ef |grep 8800
检查后发现时 apache 没有关闭,停止 apache
# /usr/local/apache2/bin/apachectl stop
# umount /www/data
# fsck -V -a /dev/sdb1
# mount /dev/sdb1 /www/data

最全的Linux教程,Linux从入门到精通
======================
1. **linux从入门到精通(第2版)**
2. **Linux系统移植**
3. **Linux驱动开发入门与实战**
4. **LINUX 系统移植 第2版**
5. **Linux开源网络全栈详解 从DPDK到OpenFlow**

第一份《Linux从入门到精通》466页
====================
内容简介
====
本书是获得了很多读者好评的Linux经典畅销书**《Linux从入门到精通》的第2版**。本书第1版出版后曾经多次印刷,并被51CTO读书频道评为“最受读者喜爱的原创IT技术图书奖”。本书第﹖版以最新的Ubuntu 12.04为版本,循序渐进地向读者介绍了Linux 的基础应用、系统管理、网络应用、娱乐和办公、程序开发、服务器配置、系统安全等。本书附带1张光盘,内容为本书配套多媒体教学视频。另外,本书还为读者提供了大量的Linux学习资料和Ubuntu安装镜像文件,供读者免费下载。

**本书适合广大Linux初中级用户、开源软件爱好者和大专院校的学生阅读,同时也非常适合准备从事Linux平台开发的各类人员。**
> 需要《Linux入门到精通》、《linux系统移植》、《Linux驱动开发入门实战》、《Linux开源网络全栈》电子书籍及教程的工程师朋友们劳烦您转发+评论
加入社区》https://bbs.csdn.net/forums/4304bb5a486d4c3ab8389e65ecb71ac0