Vision Transformer(ViT)模型原理及PyTorch逐行实现
一、TRM模型结构
1.Encoder
- Position Embedding 注入位置信息
- Multi-head Self-attention 对各个位置的embedding融合(空间融合)
- LayerNorm & Residual
- Feedforward Neural Network 对每个位置上单独仿射变换(通道融合)
- Linear1(large)
- Linear2(d_model)
- LayerNorm & Residual
2.Decoder
- Position Embedding
- Casual Multi-head Self-attention
- LayerNorm & Residual
- Memory-base Multi-head Cross-attention
- LayerNorm & Residual
- Feedforward Neural Network
- Linear1(large)
- Linear2(d_model)
- LayerNorm & Residual
二、TRM使用类型
- Encoder only 【 ViT 所使用的】
- BERT、分类任务、非流式任务
- Decoder only
- GPT系列、语言建模、自回归生成任务、流式任务
- Encoder-Decoder
- 机器翻译、语音识别
三、TRM特点
- 无先验假设(例如:局部关联性、有序建模性)
- 核心计算在于自注意力机制,平方复杂度
- 数据量的要求与归纳偏置【人类通过归纳法得到的经验,把这些经验带入到模型中,很多事物的共性】的引入成反比
四、Vision Transformer(ViT)
- DNN perspective 图像的信息量主要还是聚集在一块区域上
- image2patch 将图片切分成很多个块
- patch2embedding 将每个块转换为向量
- CNN perspective 从卷积的角度得到向量
- 2D convolution over image 二维卷积
- flatten the output feature map 把输出的卷积图拉直
- class token embedding 占位符
- position embedding
- interpolation when inference
- Transformer Encoder 只使用的Encoder
- classification head 最后分类
五、ViT论文讲解
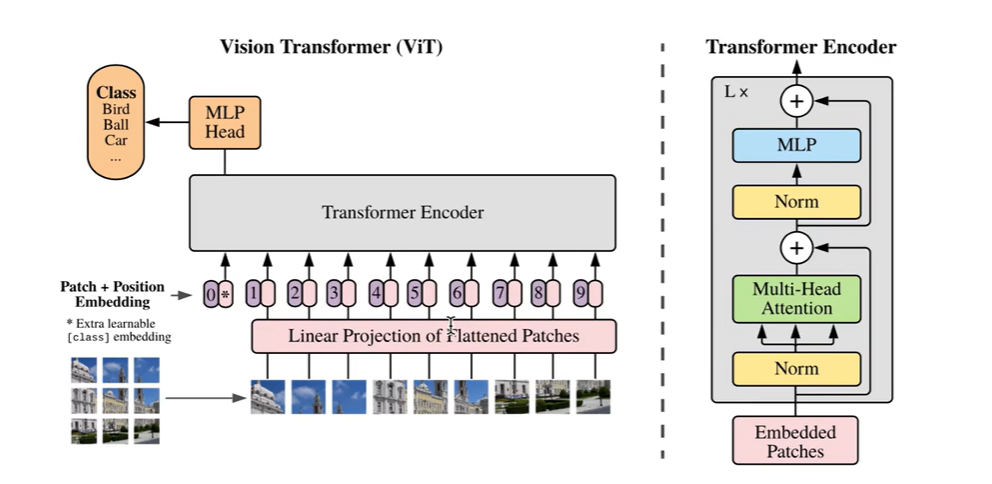
首先将一副图片分为很多个块,每个块的大小都是不会变化的,图片即使大一点,只是序列更长一点。先左到右,再上到下,把图片拉直成一个序列的形状。把每个块中的像素点进行归一化,范围变为0到1之间,再把块里面的所有值通过一个线性变换映射到模型的维度,得到patchembedding,得到以后,我们为了做分类任务,还需要在序列的开头加上一个可训练的embedding,这个是随机初始化的。这样就构造出了一个n+1长度的序列,然后我们再加入position embedding,加上后的这个序列的表征就可以送入到TRM的encoder当中,最后取出结果中的我们加入的可训练的embedding位置上的值(输出状态),经过一个MLP,得到各个类别的概率分布,再通过一个交叉熵函数算出分类的loss,这样就完成了一个ViT模型的搭建。
六、代码实现
1.convert image to embedding vector sequence
1.通过DNN实现
import torch
import torch.nn as nn
import torch.nn.functional as F
def image2emb_naive(image,patch_size,weight):
# image shape: bs*channel*h*w
patch = F.unfold(image,kernel_size=patch_size,stride=patch_size).transpose(-1,-2)
patch_embedding = patch @ weight
return patch_embedding
# test code for image2emb
bs,ic,image_h,image_w=1,3,8,8
patch_size=4 # 每个块的大小为4*4(自定义)
model_dim=8 #将每个块映射成长度为8的向量(自定义)
patch_depth=patch_size*patch_size*ic
image=torch.randn(bs,ic,image_h,image_w) #初始化
weight=torch.randn(patch_depth,model_dim)#初始化
patch_embedding_navie=image2emb_navie(image,patch_size,weight)
print(patch_embedding_naive.shape) # [1,4,8],分成四块了,每块对应一个长度为8的向量
2.通过CNN实现
import torch
import torch.nn as nn
import torch.nn.functional as F
def image2emb_conv(image,kernel,stride):
conv_output=F.conv2d(image,kernel,stride=stride) # bs*oc*oh*ow
bs,oc,oh,ow=conv_output.shape
patch_embedding=conv_output.reshape((bs,oc,oh*ow)).transpose(-1,-2)
return patch_embedding
# test code for image2emb
bs,ic,image_h,image_w=1,3,8,8
patch_size=4
model_dim=8
patch_depth=patch_size*patch_size*ic
image=torch.randn(bs,ic,image_h,image_w)
weight=torch.randn(patch_depth,model_dim) #model_dim是输出通道数目,patch_depth是卷积核的面积乘以输入通道数
kernel=weight.transpose(0,1).reshape((-1,ic,patch_size,patch_size)) # oc*ic*kh*kw
patch_embedding_conv=image2emb_conv(image,kernel,patch_size) # 二维卷积的方法得到embedding
2.prepend CLS token embedding
cls_token_embedding = torch.randn(1,model_dim,requires_grad=True)
token_embedding = torch.cat([[bs,cls_token_embedding],patch_embedding_conv],dim=1)
提问:本身cls_token_embedding没有和任何样本矩阵有乘法联系,最后训练出来的也是一张确定的表,在做inference的时候,完全是一个常数的作用。送入transformer后,又与其他矩阵做了MHA,没搞懂用意何在啊?
答:有联系啊,就是与其他时刻的sample做MHSA。这个token其实是取代了avg pool的作用,也就是说,你可以用avg pool得到分类的logits,也可以用采用cls token来得到分类的logits
注意:cls_token_embedding作为batch_size中每一个序列的开始,应该对于每一个序列的开始都torch.cat同样的一个cls_token_embedding,然后都是对这同一个cls_token_embedding进行训练,所以这里的cls token embedding应该是二维的,1*model_dim,与batchsize无关。
3.add position embedding
max_num_token=16 #自定义
position_embedding_table = torch.randn(max_num_token,model_dim,requires_grad=True)
seq_len=token_embedding.shape[1] # 刚刚的1+4
position_embedding=torch.tile(position_embedding_table[:seq_len],[token_embedding.shape[0],1,1]) # 5,bs,1,1
token_embedding += position_embedding
4.pass embedding to Transformer Encoder
encoder_layer = nn.TransformerEncoderLayer(d_model=model_dim,nhead=8)
transformer_encoder=nn.TransformerEncoder(encoder_layer,num_layers=6)
encoder_output=transformer_encoder(token_embedding)
5.do classification
cls_token_output=encoder_output[:,0,:] #拿到TRM的输出值
num_classes=10 # 自定义的类别数目
label=torch.randint(10,(bs,)) # 自定义的生成的label
linear_layer = nn.Linear(model_dim,num_classes)
logits = linear_layer(cls_token_output)
loss_fn=nn.CrossEntropyLoss()
loss=loss_fn(logits,label)
print(loss)