
文章链接:https://arxiv.org/pdf/2409.02543
代码&数据集链接: https://github.com/alipay/style-tokenizer
亮点直击
- 介绍了一种名为StyleTokenizer的新方法,用于在扩散模型中进行风格控制。这种方法允许通过一个任意参考图像实现对生成图像风格的精确控制,无需训练,同时最小化对文本提示控制效果的影响。实验结果显示,方法在风格控制领域相比其他最先进的方法表现出色。
- 整理了一个名为Style30k的数据集,包含超过300种广泛分布的风格类别,由专业设计师手动收集。该数据集总共包括30,000张图像,这是目前最大、最具多样性的开源风格数据集。利用该数据集,训练了一个强大的风格编码器,能够基于单一参考图像有效地表示风格信息。

总结速览
解决的问题:
- 风格控制的难题:在文本生成图像的过程中,现有方法难以同时有效控制图像风格和保持文本提示的语义信息。
- 条件干扰:许多基于适配器的方法在去噪过程中施加图像表示条件,这些条件与文本控制条件之间会产生干扰,导致风格控制和文本控制的效果不理想。
- 风格表示获取困难:从单一参考图像中准确提取和表达风格,尤其是在保持文本提示语义完整性的同时,是一个具有挑战性的问题。
提出的方案:
- StyleTokenizer方法:是一种零样本风格控制的图像生成方法,能够在不影响文本表示效果的情况下,实现精确的风格控制。
- 风格与文本对齐:通过使用StyleTokenizer将风格表示与文本表示对齐,避免风格控制与文本控制条件之间的干扰。
- Style30k数据集:创建了一个名为Style30k的大规模风格数据集,用于训练模型更好地提取和表示风格特征。
- 风格特征提取器:设计并训练了一个风格特征提取器,能够准确捕捉和表达参考图像的风格特征,同时排除其他内容信息。
应用的技术:
- StyleTokenizer:将风格表示与文本表示对齐,避免风格和文本控制条件之间的干扰。
- 风格特征提取器:通过对Style30k数据集进行训练,准确表示风格细节,同时避免与内容信息的混淆。
- 对比学习:增强风格特征提取器的鲁棒性,使其能够更好地适应和处理新的风格。
达到的效果:
- StyleTokenizer方法能够充分捕捉参考图像的风格特征。
- 能够生成与目标图像风格和文本提示一致的图像。
- 与现有方法相比,StyleTokenizer实现了高效、准确的风格控制。
- 在保持文本提示语义完整性的同时,生成了令人满意的图像。
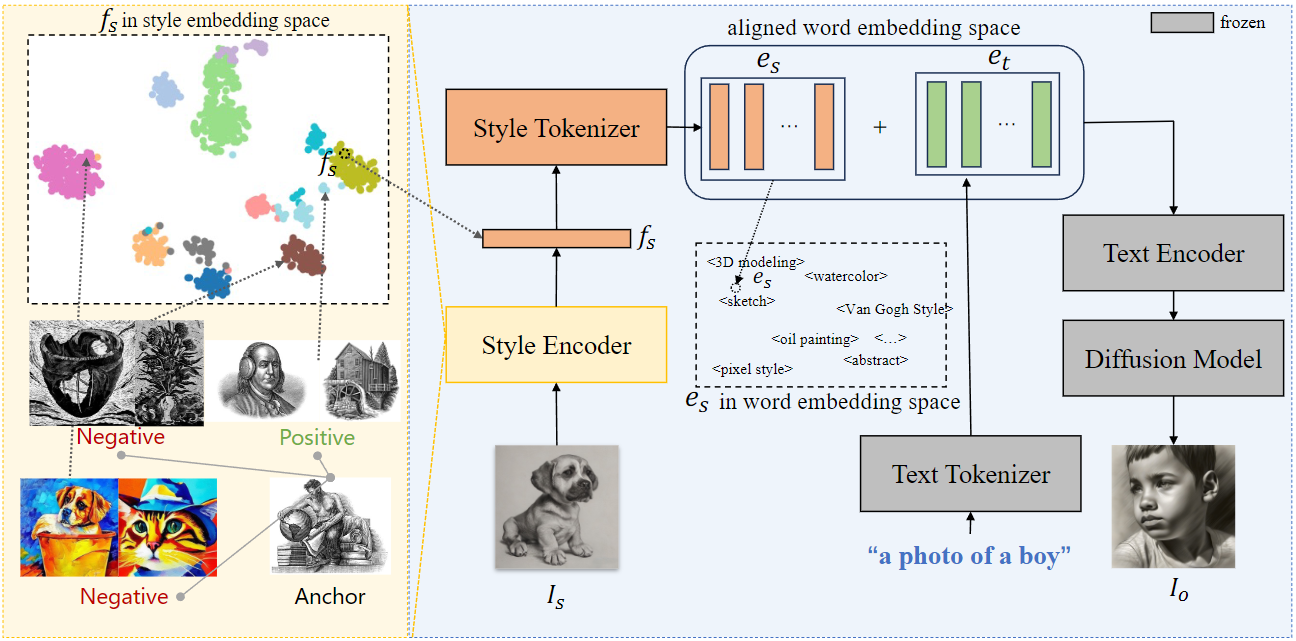
方法
这项研究提出了一种基于Stable Diffusion框架的创新方法,用于在图像生成中解耦内容和风格条件,从而创造出视觉上更加吸引人的图像。该方法主要引入了两个关键模块:
-
风格编码器(Style Encoder):此模块负责从图像中提取风格信息。通过在一个名为Style30K的风格数据集上进行训练,风格编码器能够准确捕捉图像的风格特征,为后续的风格控制提供基础。
-
风格标记器(Style Tokenizer):该模块将从风格编码器中提取的风格表示转换为风格token,并与文本token在词嵌入空间中对齐。风格标记器的训练过程确保了风格标记与文本token的兼容性,使得风格和内容能够有效结合。
在生成图像的最后阶段,这些风格token和文本token被连接在一起,并作为条件输入到稳定扩散模型中,从而生成最终的图像。这种方法通过精确控制图像的风格和内容,为图像生成提供了新的可能性。
StyleTokenizer方法总体流程
两个阶段。在第一阶段,风格编码器在风格数据集上进行训练,以获得风格表示能力。采用对比学习来强化它,以关注不同风格之间的距离差异,从而更好地表现风格。
在第二阶段,风格编码器从单个图像中提取风格嵌入,然后风格标记器将其转换为风格标记,这些token与单词嵌入空间中的文本token对齐。最后,这些token被输入到SD pipeline中,作为生成图像的条件。
StyleTokenizer整体如下图:
Style30K数据集
描述图像风格对于艺术家来说已经相当具有挑战性,而对普通人来说更是难上加难。图像风格涉及的内容非常复杂,包括色彩分布、光照、线条风格、艺术风格、笔触和情感等。这些特征虽然可以通过视觉感知,但用语言准确全面地表达却非常困难。因此,直接从图像中提取风格特征比单纯依赖文字描述要更为有效。
为了应对这一问题,研究人员开发了一个名为Style30K的风格数据集,并设计了一个专门用于捕捉风格特征的风格编码器(Style Encoder),如下图4所示。与现有的通用特征提取方法不同,Style30K旨在专门训练风格相关的特征提取能力。

该数据集的构建过程分为三个主要阶段。首先,研究人员收集了大量具有不同风格的图像,并用三张示例图像来代表每种风格。接着,使用不同的嵌入提取器从这些示例图像中提取特征,并在大规模数据集中进行检索。第二阶段中,研究人员手动筛选检索结果,确保收集到的图像与示例图像风格一致,并且每张图像都经过三位标注员的一致确认。最后,在第三阶段中,使用CogVLM为每张图像添加了内容描述。描述内容仅关注图像的实际内容,而不涉及风格,从而保证了风格和内容控制信号的独立性。
风格编码器
在这一部分,研究人员详细描述了如何训练风格编码器(Style Encoder,Es),该编码器的主要任务是从图像中提取风格线索,并将这些线索编码成风格嵌入(fs),以指导生成过程。
从单一参考图像中获取准确的风格表示并非易事。传统的方法通常依赖于CLIP图像编码器来提取图像表示,从而实现内容和风格的控制。尽管这种方法在对颜色、主体、布局等视觉方面的控制上表现不错,但它并未能独立控制这些方面,尤其是在风格控制方面,因为CLIP主要依赖粗粒度的语义信息进行训练。
为了克服这一限制,研究人员引入了一个经过标注的风格数据集——Style30K,用于训练一个专注于准确风格表示的编码器。这个风格编码器通过监督学习的方式进行训练,确保它仅关注与风格相关的信息,而忽略与内容无关的细节。通过这种方式,风格编码器能够专注于不同风格之间的细微差别。此外,为了进一步提高编码器的泛化能力,研究人员采用了对比损失的监督策略。这种方法帮助模型在嵌入空间中将相同风格的图像聚集在一起,而将不同风格的图像分散开来,从而增强了风格编码器处理新风格的鲁棒性。
风格控制
以往基于适配器的方法在扩散模型中引入了图像提示功能,这种做法显著提升了生成那些难以用提示语言描述的内容的能力。这些方法通过在Unet模块中添加额外的交叉注意力层,将风格表示融入生成过程中。然而,这种方法在去噪过程中同时应用文本和风格条件,可能导致控制信号之间的干扰,从而丧失部分语义信息。
相较而言,Stable Diffusion(SD)模型的词嵌入空间提供了丰富的风格控制能力。Dreambooth 和 Textual Inversion 已经展示了,通过现有词典之外的词嵌入可以表达各种内容。不过,这些方法需要额外的参考图像进行调优,并且容易在特定内容上出现过拟合。此外,尽管精心编写的文本提示可以影响图像风格,直接利用文本描述来控制风格依然具有挑战性。SD 在训练期间使用的文本描述通常缺乏对图像风格的详细说明,同时,图像风格涉及多方面特征,难以通过自然语言全面表达。
为了解决这些问题,研究人员提出了一种新的方法,旨在为每张图像提供全面且准确的风格描述,并能够应用于扩散流程。他们的风格编码器(Style Encoder)可以从图像中提取独特的风格嵌入。接着,研究人员利用一个名为StyleTokenizer的两层多层感知器(MLP)将这些风格嵌入映射到词嵌入空间中的风格标记。StyleTokenizer 的参数在训练过程中会更新,而SD模型的参数则保持冻结。这样,映射后的风格嵌入能够提供图像风格的全面和精准的表示。最终,风格嵌入和文本嵌入被结合,并输入到SD的文本编码器中,这样风格图像就可以作为风格提示来生成图像,从而更好地描述所需风格。同时,风格和内容在各自独立的语义空间中处理,避免了风格和内容之间的重叠。
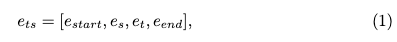
其中 e s = T s ( f s ) e_s = T_s(f_s) es=Ts(fs)在推理过程中,使用无分类器引导(classifier-free guidance)。为了独立控制文本和风格的权重,采用了类似于InstructPix2Pix的方法。
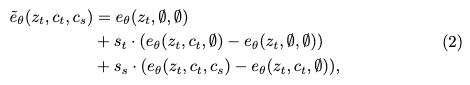
其中, c t c_t ct 和 c s c_s cs 分别表示文本和风格条件。 s t s_t st 和 s s s_s ss 的强度分别表示文本和风格条件的强度。
实验
实验细节
在本研究中,研究团队从互联网上收集了1000万张高质量图像用于训练模型。风格编码器(Style Encoder)采用了CLIP ViT-B/32的视觉编码器作为其预训练的骨干网络。训练过程分为两个阶段:首先,利用这1000万张图像进行预训练,然后使用专门的风格数据集Style30K进行监督训练。在风格控制方面,研究团队使用了Stable Diffusion(SD)v1.5作为生成模型。风格嵌入由StyleTokenizer生成,其形状为8×768,这些风格标记与文本嵌入标记进行连接,并被输入到SD的文本编码器中。所有图像在训练过程中用于训练StyleTokenizer。当去噪目标图像 I I I 来自Style30K数据集时,风格参考图像 I s I_s Is 是从同一风格类别的图像中随机选择的;如果 I I I 没有风格注释,则风格参考图像就是 I I I 本身。
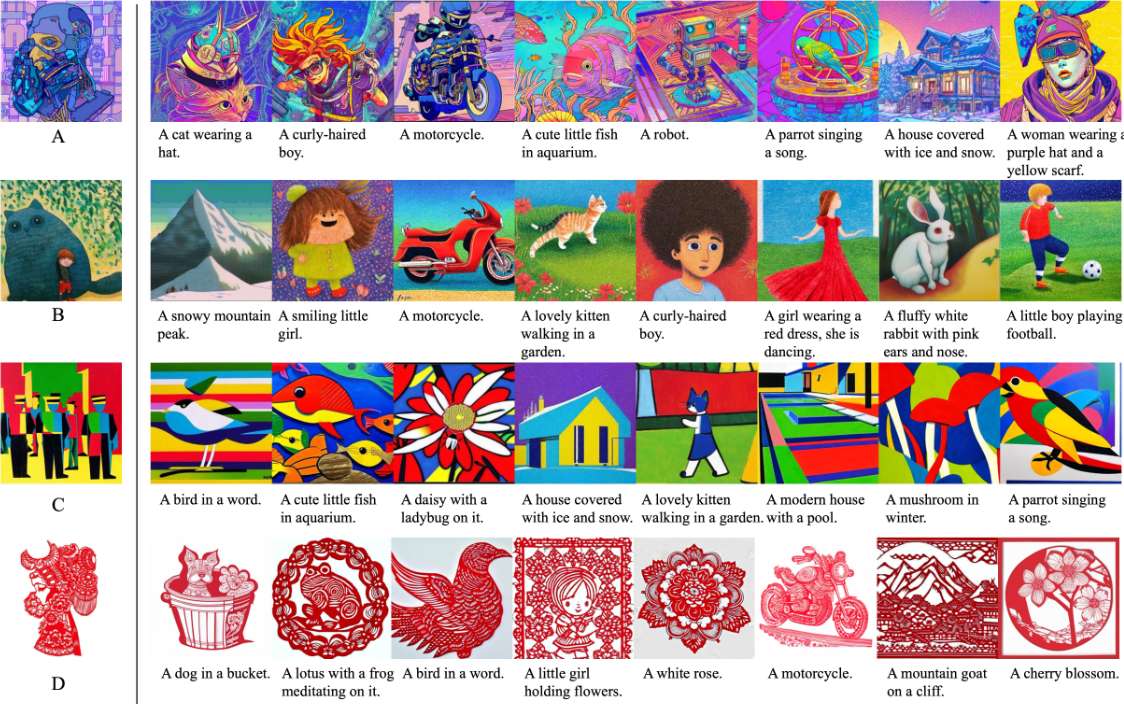
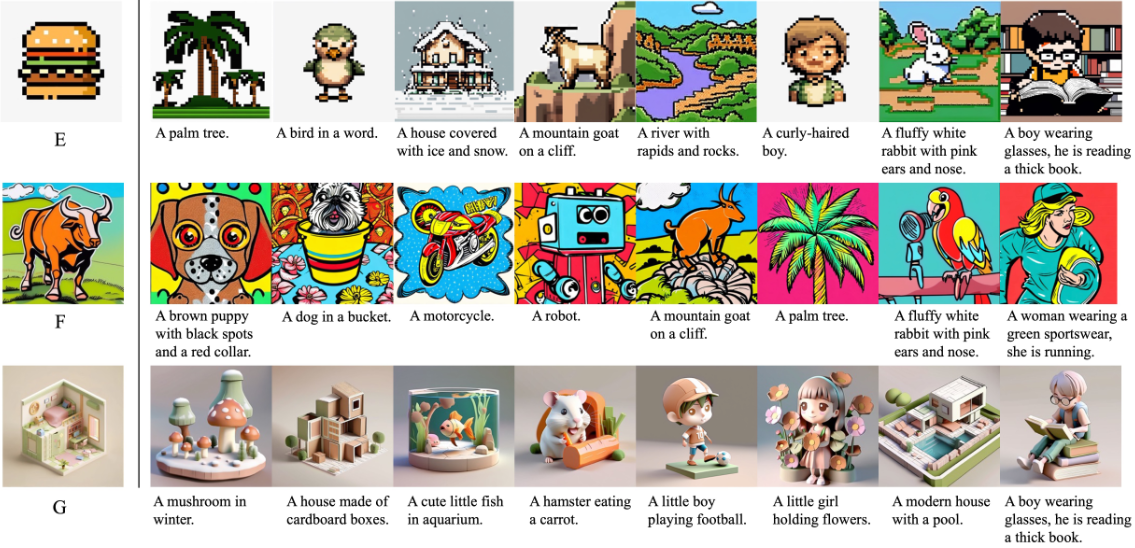
质量评价
为了评估他们的方法在风格控制和提示跟随方面的表现,研究团队将其方法与其他先进的方法进行了比较,包括StyTr2、InST、CAST、SD(使用风格提示控制)和IP-Adapter。为此,他们准备了一个基准测试,包括52个提示和28个风格参考图像,这些提示来源于StyleAdapter使用的设置。这些提示涵盖了各种内容,如人类、动物、物体和场景,而参考图像则包括一些常见风格和一些难以用语言描述的风格。这些参考图像和提示都没有排除在训练过程之外。下图5展示了不同方法生成的图像,每列展示了使用相同提示和参考图像生成的结果。

从结果中可以看出,StyTr2和InST在捕捉参考图像的主要色调方面表现良好,但在整体风格(如纹理)的把握上有所欠缺。例如,它们能够捕捉到参考图像中的红色,但未能准确呈现剪纸风格。此外,这些方法生成的图像质量通常低于其他方法。虽然风格提示控制在简单风格类别(如油画和水墨画)中能实现一定的风格控制,但缺乏参考图像会导致细节上的显著差异。
对于那些难以用语言描述的复杂风格,它们的风格控制能力显著下降。IP-Adapter能够生成接近原始风格的图像,但在内容与参考图像分离方面存在困难,导致提示跟随能力不足。例如,在生成的图像中,尽管包含了山脉和向日葵,但参考图像中的人类也出现在了结果中。IP-Adapter的主要优势在于图像变换和编辑。然而,相比之下,研究团队的方法在风格一致性方面表现优异,包括线条、纹理、颜色和情感等方面,并且在跟随文本提示方面具有强大的能力。总体来看,该方法生成的图像在美学质量上优于其他方法。
定量评估
使用以下指标来评估生成图像的质量和效果:
-
文本-图像相似性:我们使用CLIP模型从生成的图像及其相应的文本提示中提取嵌入。然后计算提示和生成图像之间的余弦相似性。较高的余弦相似性表示更好的指令跟随能力。
-
美学评分:为了评估生成图像的美学质量,我们使用LAION-Aesthetics Predictor 预测每个生成图像的美学评分。此指标衡量图像的视觉吸引力和艺术质量。较高的美学评分表示图像更具视觉吸引力。
-
风格相似性:由于没有普遍接受的风格相似性评估方法,我们模仿了由CLIP计算的文本-图像相似性指标。通过风格编码器提取风格参考图像和生成图像的风格嵌入。然后计算它们的余弦相似性。较高的余弦相似性表示生成图像中对所需风格的控制更好。
-
用户研究:为了更全面地评估风格相似性,进行了用户研究。对于每种方法生成的图像,我们让20名用户(10名专业设计师和10名普通用户)匿名投票选择他们认为风格最接近参考图像的图像。归一化的投票数(投票率)作为风格相似性评分。
对于这些指标中的每一个,计算所有生成结果的平均值,以提供对现有风格控制模型性能的总体评估。实验结果总结在下表1中,使用上述评估指标将本文方法与最新的方法进行比较。办法在风格相似性方面显著优于其他最新的方法。在用户研究中,方法也获得了比其他方法更多的投票。这些结果突出显示了方法在生成图像中保持期望风格的效果。
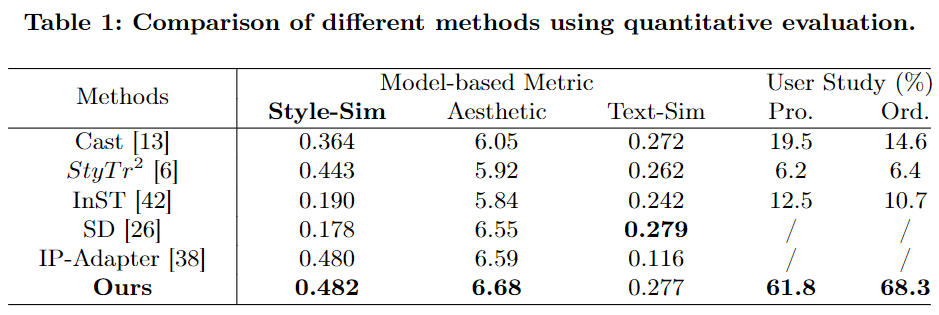
此外,本文方法在大规模高美学数据上进行训练,因此比基础SD模型获得了更高的美学评分。如前面图5所示,它在美学方面的结果优于其他方法。至于指令跟随,本文方法在文本-图像相似性方面的表现与基础SD模型相当。这表明方法在风格控制过程中没有降低指令跟随能力。总之,实验结果表明,本文方法能够实现更好的风格控制能力和生成视觉上更具吸引力的图像,同时风格控制不会影响指令跟随能力。
风格编码器评估
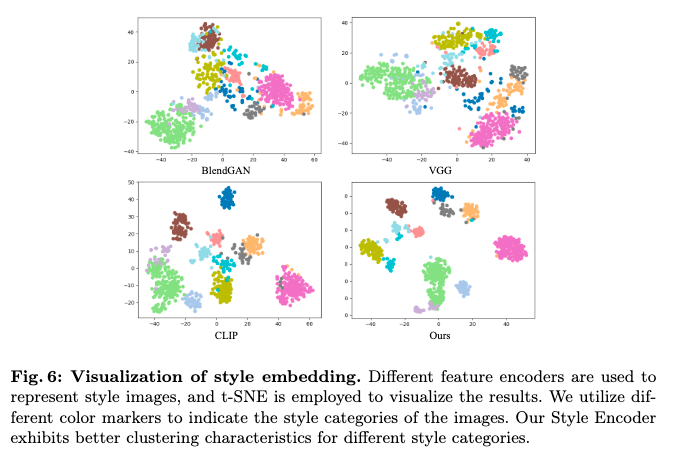
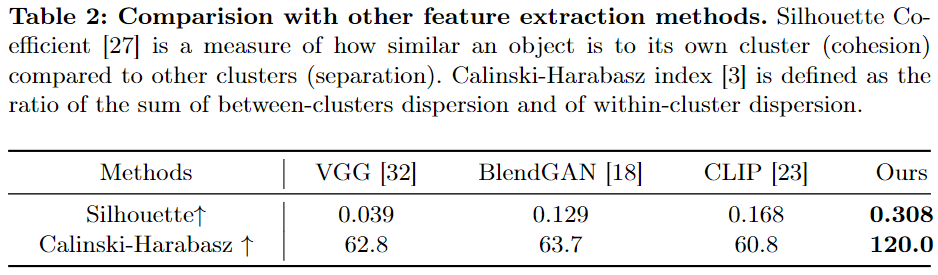
对风格编码器进行了评估,并与几个公开的特征编码器进行比较,即CLIP、VGG 和 BlendGAN 。评估在Style30K的验证集上进行,该验证集包含12种不同的风格类别,总共900张图像,这些图像与训练风格类别不重复。
研究者们使用了多种方法来提取验证集中每张图像的风格嵌入,并将这些嵌入的分布在表示空间中进行了可视化。下图6展示了不同类别的风格嵌入以不同颜色的点表示,这些点在空间中形成了各自的簇。结果表明,他们的风格编码器能够有效地将相同风格类别的图像聚集在一起,显示出较小的类内距离和较大的类间差异。这表明该方法在捕捉和展示图像风格方面表现出色,并且能够处理新颖的风格变化。进一步的定量评估通过Silhouette Coefficient和Calinski-Harabasz指标确认了这一点。无论是从视觉效果还是从聚类指标来看,该方法在提取风格特征并进行风格聚类方面都优于其他方法。
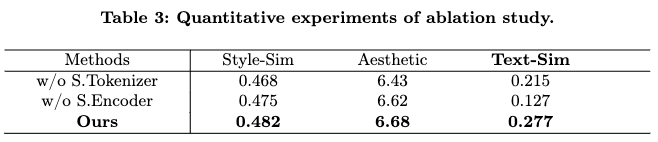
消融研究
通过消融研究以评估风格编码器和Style Tokenizer的有效性,如下图7和表3所示。图7(b)表示风格嵌入没有首先通过Style Tokenizer对齐到词嵌入空间,而是直接与文本嵌入连接。图7©表示没有使用风格编码器进行风格表示,而是直接使用CLIP视觉编码器对图像进行编码。实验结果表明,如果缺少其中任何一个,生成的图像要么指令跟随能力减弱,要么风格一致性较差。

其他应用
由于本文方法能够保持参考图像中的风格,如果使用多张不同风格的图像作为参考,则风格融合会产生新的风格。在图8中展示了使用两种风格进行风格混合的效果。通过以调色板风格作为控制开始,并逐渐融入素描风格,生成的图像显示出从调色板风格到素描风格的渐进过渡。

结论
这是一种创新的zero-shot方法,旨在精确控制生成图像的风格。该方法通过将风格和内容条件分离,实现了对生成图像风格的精准控制。首先,团队构建了一个精细标注的风格数据集——Style30K,并开发了一个风格编码器,用于从参考图像中提取风格特征。随后,引入了StyleTokenizer,将风格token和文本token对齐到一个统一的表示空间中。最终,这些对齐后的token被用作扩散模型去噪过程中的条件输入。该方法为图像生成中的风格控制提供了一种灵活而有效的解决方案,开辟了生成高质量风格化内容的新途径。
参考文献
[1]StyleTokenizer: Defining Image Style by a Single Instance for Controlling Diffusion Models



















