摘要-本文开发了新的深度学习方法,即深度残余收缩网络,提高来自高噪声振动信号的特征学习能力,并实现较高的故障诊断准确性。软阈值作为非线性转换层插入到深层体系结构中,以消除不重要的特征。此外,考虑到通常为阈值设置适当的值具有挑战性,开发的深度残余收缩网络集成了一些专门的神经网络作为可训练的模块来自动确定阈值,因此不需要信号处理方面的专业知识。通过各种噪声的实验验证了所开发方法的有效性。
引言
深度残差网络 (ResNets) 是ConvNets的一个有吸引力的变体,它使用身份快捷方式来缓解参数优化的难度 [15]。在ResNets中,梯度不仅逐层向后传播,而且还通过身份快捷方式直接流回初始层 [16]。
当处理高噪声的振动信号时,ResNets的特征学习能力通常会降低。Resnet中用作本地特征提取器的卷积内核可能由于噪声的干扰而无法检测到与故障相关的特征。在这种情况下,在输出层学习的高级特征通常没有足够的区分性来正确分类故障。因此,有必要开发新的深度学习方法,用于在强背景噪声下基于振动的旋转机械故障诊断。
本文的贡献:
- 软阈值 (即一种流行的收缩函数) 作为非线性转换层插入到深度架构中,以有效消除噪声相关特征
- 使用专门设计的子网自适应地确定阈值,以便每个振动信号都可以具有自己的阈值集。
- 软阈值中考虑了两种阈值,即信道共享阈值和信道方式阈值
方法
身份捷径是使ResNet优于一般ConvNets的部分。交叉熵误差的梯度在通用ConvNet中逐层向后传播。通过使用身份快捷方式,梯度可以有效地流向靠近输入层的较早层,从而可以更有效地更新参数。减小输出特征图的宽度的动机是减少以下各层的计算量,增加输出特征图的通道数的动机是便于将不同特征集成为判别特征。
理论背景
在过去的20年中,软阈值通常被用作许多信号去噪方法中的关键步骤 [23],[24]。通常,将原始信号转换为接近零的数字不重要的域,然后应用软阈值将接近零的特征转换为零。例如,作为一种经典的信号去噪方法,小波阈值化通常由小波分解、软阈值化和小波重构三个步骤组成。为了确保信号去噪的良好性能,小波阈值的关键任务是设计一种滤波器,该滤波器可以将有用的信息转换为非常正的或负的特征,并将噪声信息转换为接近零的特征。然而,设计这样的滤波器需要大量的信号处理专业知识,并且一直是一个具有挑战性的问题。深度学习为解决这一问题提供了一种新的方法。深度学习可以使用梯度下降算法自动学习过滤器,而不是由专家人为地设计过滤器。因此,软阈值和深度学习的集成可能是消除噪声相关信息和构建高度区分性特征的一种有前途的方法。软阈值:
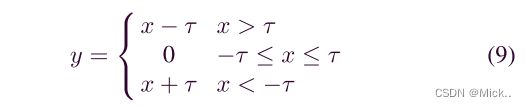
其中,x为输入特征,y为输出特征,τ 为阈值,即为正参数。软阈值化不是将relu激活函数中的负特征设置为零,而是将近零特征设置为零,这样可以保留有用的负特征。
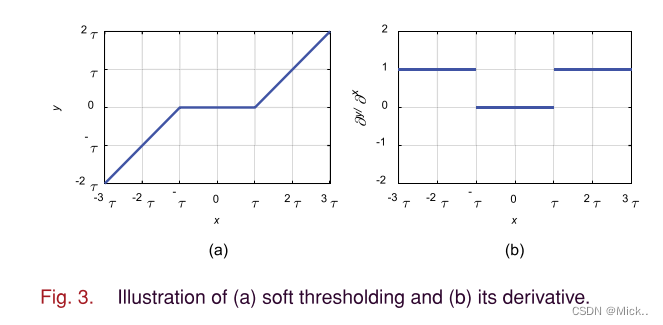
可以看出,输入输出的导数为1或0,这在防止梯度消失和爆炸。
在经典的信号去噪算法中,通常很难为阈值设置适当的值。
drsn-cs的体系结构
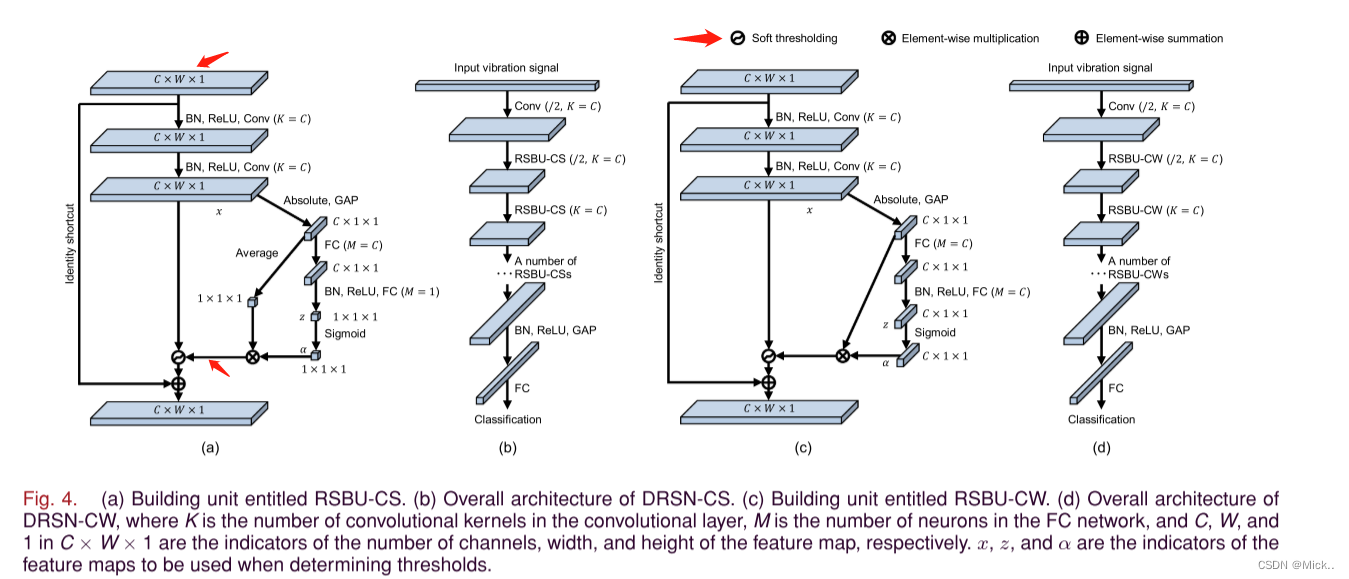
已开发的drsn-cs是ResNet的一种变体,它使用软阈值处理来消除与噪声相关的功能。软阈值作为非线性转换层插入到单元中。而且,可以在单元中学习阈值的值,这将在下面介绍。
如图4(a) 所示,名为 “具有信道共享阈值的剩余收缩构建单元 (RSBU-CS)” 的构建单元与图2(a) 中的RBU的不同之处在于,RSBU-CS具有用于估计要在软阈值中使用的阈值的特殊模块。在特殊模块中,将GAP应用于特征图x的绝对值,以获得一维向量。然后,将一维向量传播到两层FC网络中以获得缩放参数,该缩放参数类似于 [25] 中提供的缩放参数。然后在两层FC网络的末尾应用sigmoid函数,从而将缩放参数缩放到 (0,1) 的范围
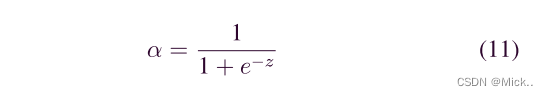
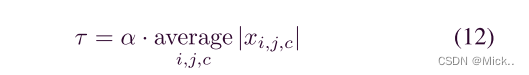
代码:
import torch
import torch.nn as nn
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, in_channels, out_channels, stride=1):
super().__init__()
self.shrinkage = Shrinkage(out_channels, gap_size=(1, 1))
#residual function
self.residual_function = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=stride, padding=1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True),
nn.Conv2d(out_channels, out_channels * BasicBlock.expansion, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(out_channels * BasicBlock.expansion),
self.shrinkage
)
#shortcut
self.shortcut = nn.Sequential()
#the shortcut output dimension is not the same with residual function
#use 1*1 convolution to match the dimension
if stride != 1 or in_channels != BasicBlock.expansion * out_channels:
self.shortcut = nn.Sequential(
nn.Conv2d(in_channels, out_channels * BasicBlock.expansion, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(out_channels * BasicBlock.expansion)
)
def forward(self, x):
return nn.ReLU(inplace=True)(self.residual_function(x) + self.shortcut(x))
class Shrinkage(nn.Module):
def __init__(self, channel, gap_size):
super(Shrinkage, self).__init__()
self.gap = nn.AdaptiveAvgPool2d(gap_size)
self.fc = nn.Sequential(
nn.Linear(channel, channel),
nn.BatchNorm1d(channel),
nn.ReLU(inplace=True),
nn.Linear(channel, channel),
nn.Sigmoid(),
)
def forward(self, x):
x_raw = x
x = torch.abs(x)
x_abs = x
x = self.gap(x)
x = torch.flatten(x, 1)
# average = torch.mean(x, dim=1, keepdim=True)
average = x
x = self.fc(x)
x = torch.mul(average, x)
x = x.unsqueeze(2).unsqueeze(2)
# soft thresholding
sub = x_abs - x
zeros = sub - sub
n_sub = torch.max(sub, zeros)
x = torch.mul(torch.sign(x_raw), n_sub)
return x
class RSNet(nn.Module):
def __init__(self, block, num_block, num_classes=100):
super().__init__()
self.in_channels = 64
self.conv1 = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True))
#we use a different inputsize than the original paper
#so conv2_x's stride is 1
self.conv2_x = self._make_layer(block, 64, num_block[0], 1)
self.conv3_x = self._make_layer(block, 128, num_block[1], 2)
self.conv4_x = self._make_layer(block, 256, num_block[2], 2)
self.conv5_x = self._make_layer(block, 512, num_block[3], 2)
self.avg_pool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(512 * block.expansion, num_classes)
def _make_layer(self, block, out_channels, num_blocks, stride):
"""make rsnet layers(by layer i didnt mean this 'layer' was the
same as a neuron netowork layer, ex. conv layer), one layer may
contain more than one residual shrinkage block
Args:
block: block type, basic block or bottle neck block
out_channels: output depth channel number of this layer
num_blocks: how many blocks per layer
stride: the stride of the first block of this layer
Return:
return a rsnet layer
"""
# we have num_block blocks per layer, the first block
# could be 1 or 2, other blocks would always be 1
strides = [stride] + [1] * (num_blocks - 1)
layers = []
for stride in strides:
layers.append(block(self.in_channels, out_channels, stride))
self.in_channels = out_channels * block.expansion
return nn.Sequential(*layers)
def forward(self, x):
output = self.conv1(x)
output = self.conv2_x(output)
output = self.conv3_x(output)
output = self.conv4_x(output)
output = self.conv5_x(output)
output = self.avg_pool(output)
output = output.view(output.size(0), -1)
output = self.fc(output)
return output
def rsnet18():
""" return a RSNet 18 object
"""
return RSNet(BasicBlock, [2, 2, 2, 2])
def rsnet34():
""" return a RSNet 34 object
"""
return RSNet(BasicBlock, [3, 4, 6, 3])参考文献:
深度残差收缩网络(完整PyTorch程序) - 腾讯云开发者社区-腾讯云 (tencent.com)
注意力机制与残差网络:深度残差收缩网络 - 简书 (jianshu.com)








![Unity学习shader笔记[一百零八]简单萤火效果](https://img-blog.csdnimg.cn/1edec93d4280494cb43fcd8ea45c4ece.gif)