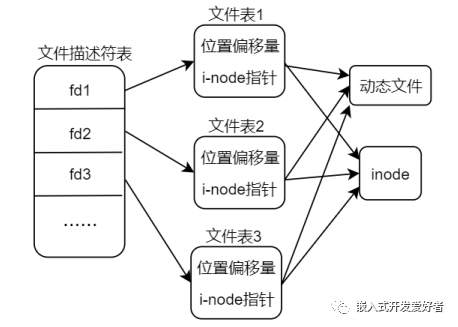
大数据编程实验一:HDFS常用操作和Spark读取文件系统数据
文章目录
- 大数据编程实验一:HDFS常用操作和Spark读取文件系统数据
- 一、前言
- 二、实验目的与要求
- 三、实验内容
- 四、实验步骤
- 1、HDFS常用操作
- 2、Spark读取文件系统的数据
- 五、最后我想说
一、前言
这是我们大数据专业开设的第二门课程——大数据编程,使用的参考书是《Spark编程基础》,这门课跟大数据技术基础是分开学习的,但这门课是用的我们自己在电脑上搭建的虚拟环境进行实验的,不是在那个平台上,而且搭建的还是伪分布式,这门课主要偏向于有关大数据编程方面的,而且使用的编程语言是Python。
我上课的时候也没有怎么听,所以我再自己做一遍实验。
二、实验目的与要求
- 掌握在Linux虚拟机中安装Hadoop和Spark的方法
- 熟悉HDFS的基本使用方法
- 掌握使用Spark访问本地文件和HDFS文件的方法
三、实验内容
-
安装Hadoop和Spark
进入Linux系统,完成Hadoop伪分布式模式的安装。完成Hadoop的安装以后,再安装Spark(Local模式)。
-
HDFS常用操作
使用Hadoop提供的Shell命令完成如下操作:
- 启动Hadoop,在HDFS中创建用户目录“/user/hadoop”
- 在Linux系统的本地文件系统的“/home/hadoop”目录下新建一个文本文件test.txt,并在该文件中随便输入一些内容,然后上传到HDFS的“/user/hadoop”目录下
- 把HDFS中“/user/hadoop”目录下的test.txt文件,下载到Linux系统的本地文件系统中的“/home/hadoop/下载”目录下
- 将HDFS中“/user/hadoop”目录下的test.txt文件的内容输出到终端中进行显示
- 在HDFS中的“/user/hadoop”目录下,创建子目录input,把HDFS中“/user/hadoop”目录下的test.txt文件,复制到“/user/hadoop/input”目录下
- 删除HDFS中“/user/hadoop”目录下的test.txt文件,删除HDFS中“/user/hadoop”目录下的input子目录及其子目录下的所有内容
-
Spark读取文件系统的数据
- 在pyspark中读取Linux系统本地文件“/home/hadoop/test.txt”,然后统计出文件的行数
- 在pyspark中读取HDFS系统文件“/user/hadoop/test.txt”(如果该文件不存在,请先创建),然后,统计出文件的行数
- 编写独立应用程序,读取HDFS系统文件“/user/hadoop/test.txt”(如果该文件不存在,请先创建),然后,统计出文件的行数;通过 spark-submit 提交到 Spark 中运行程序
四、实验步骤
这里我们已经提前在课上安装好Hadoop和Spark,所以就不演示了,如果不会的话可以上网查阅一下有很多教程或者等我后面有空写一遍博客也许,我得先把实验做完才行。
我们直接进行后面两个步骤。
1、HDFS常用操作
首先启动Hadoop集群,我们输入如下命令进入到hadoop的sbin目录下面,然后执行启动指令:
cd /usr/local/servers/hadoop/sbin/
start-dfs.sh
然后使用jps查看进程验证是否启动成功:

然后我们再进入hadoop目录下的bin目录中,输入如下命令创建用户目录“/user/hadoop”:
hdfs dfs -mkdir -p /user/hadoop
然后我们在master主机内的“/home/hadoop”目录下新建一个文本文件test.txt:
vi /home/hadoop/test.txt
然后再文件中随便输入一些内容:

然后我们我们重新进入hadoop的bin目录中并将这个文件上传到HDFS的“/user/hadoop”目录下:
hdfs dfs -put /home/hadoop/test.txt /user/hadoop
查看一些我们是否成功上传到HDFS中:
hdfs dfs -ls /user/hadoop

可以看出我们上传成功了。
然后我们再通过如下命令把HDFS中“/user/hadoop”目录下的test.txt文件,下载到Linux系统的本地文件系统中的“/home/hadoop/下载”目录下:
hdfs dfs -get user/hadoop/test.txt /home/hadoop/
然后我们使用如下命令将HDFS中“/user/hadoop”目录下的test.txt文件的内容输出到终端中进行显示:
hdfs dfs -cat /user/hadoop/test.txt

我们再在HDFS中的“/user/hadoop”目录下,创建子目录input:
hdfs dfs -mkdir /user/hadoop/input
并把HDFS中“/user/hadoop”目录下的test.txt文件,复制到“/user/hadoop/input”目录下:
hdfs dfs -cp /user/hadoop/test.txt /user/hadoop/input/
并查看一下是否复制成功:
hdfs dfs -ls /user/hadoop/input

最后我们删除HDFS中“/user/hadoop”目录下的test.txt文件:
hdfs dfs -rm -r /user/hadoop/test.txt
并删除HDFS中“/user/hadoop”目录下的input子目录及其子目录下的所有内容:
hdfs dfs -rm -r /user/hadoop/input

2、Spark读取文件系统的数据
我们首先启动pyspark:
cd /usr/local/spark/bin/
pyspark

启动pyspark之后我们就可以直接在这里面进行编程。
我们在pyspark中读取Linux系统本地文件“/home/hadoop/test.txt”,然后统计出文件的行数:
lines = sc.textFile("file:/home/hadoop/test.txt")
lines.count()

然后我们在pyspark中读取HDFS系统文件“/user/hadoop/test.txt”(如果该文件不存在,请先创建),然后,统计出文件的行数:
lines = sc.textFile("/user/hadoop/test.txt")
lines.count()

最后我们先在/home/hadoop中创建一个py文件并编写独立应用程序,读取HDFS系统文件“/user/hadoop/test.txt”(如果该文件不存在,请先创建),然后统计出文件的行数:
sudo vi st-app.py

最后通过 spark-submit 提交到 Spark 中运行程序:
/usr/local/spark/bin/spark-submit --master local[4] st-app.py 2>&1 | grep "The HDFS"

五、最后我想说
到这里本次实验就结束了,我重新做了一遍加深了一下印象,也更加熟练的使用这些Linux命令了。
后面一个实验就是RDD编程,我马上就会更新,Hold on!







![Unity学习shader笔记[一百零八]简单萤火效果](https://img-blog.csdnimg.cn/1edec93d4280494cb43fcd8ea45c4ece.gif)