大家好,在深度学习领域,神经网络几乎能处理各种任务,但通常需要依赖于海量数据来达到最佳效果。然而,对于像面部识别和签名验证这类任务,我们不可能总是有大量的数据可用。由此产生了一种新型的神经网络架构,称为孪生网络。
孪生神经网络能够基于少量数据实现精准预测,本文将介绍孪生神经网络的基本概念,以及如何用PyTorch来搭建一个签名验证系统。
1.孪生神经网络概述
孪生神经网络由两个或若干个结构和参数完全相同的子网络构成,这些子网络在更新参数时同步进行。
这种网络通过分析输入样本的特征向量来评估它们的相似度,这一特性让其在众多应用领域中发挥着重要作用。
传统神经网络一般被训练用于识别多个不同的类别。当数据集中需要添加或移除类别时,这些网络通常需要经过调整和重新训练,这个过程不仅耗时,而且通常需要大量的数据支持。
而孪生网络专注于学习样本之间的相似性,能够轻松识别图像是否相似。这种能力使孪生网络在处理新类别数据时,无需重新训练即可进行有效的分类,提供了一种灵活且高效的解决方案。
1.1 优劣势
优势:
-
对类别失衡的适应能力更强:通过一次性学习,孪生网络仅需少量样本即可有效识别图像类别,具有良好的鲁棒性和适应性。
-
与顶级分类器的协同效应:由于其独特的学习机制,与传统分类方法相比,孪生网络与最佳分类器(如GBM和随机森林)的结合能够带来更佳的性能表现。
-
学习语义相似性:孪生网络专注于深层特征的嵌入学习,将相同类别或概念的样本聚集在一起,从而能够捕捉和学习它们之间的语义相似性。
劣势:
-
训练耗时较长:孪生网络采用成对学习机制,需要综合考虑所有可用信息,因此其训练过程比逐点学习的分类网络更为耗时。
-
缺乏概率输出:孪生网络的训练过程专注于成对比较,它不提供预测结果的概率值,而是直接输出各类别之间的相对距离。
1.2 孪生网络中使用的损失函数
在孪生网络的训练过程中,由于采用的是成对学习方式,传统的交叉熵损失函数不再适用。目前,主要有两种损失函数用于训练这类网络:
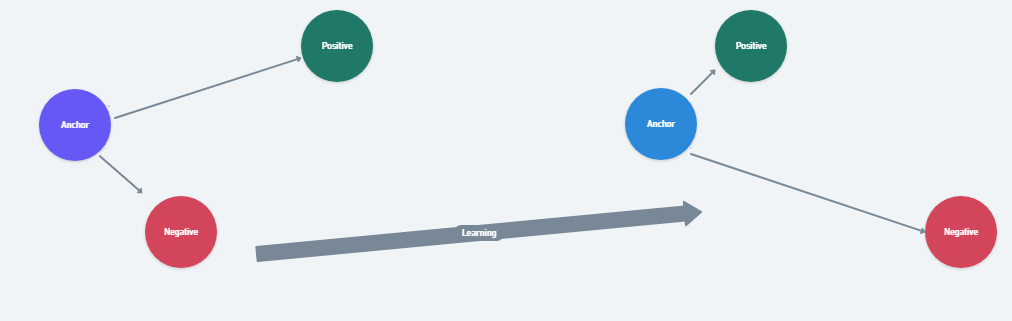
1)三元组损失
三元组是一种特殊的损失函数,它通过比较基线(锚点)输入与正样本(真实输入)和负样本(虚假输入)之间的差异来工作。其目标是最小化锚点与正样本之间的距离,同时最大化锚点与负样本之间的距离,从而确保网络能够准确区分不同类别的样本。
![]()
在上述方程中,α是控制间隔的参数,用于调整相似样本对与不相似样本对之间的距离差异;f(A)、f(P)、f(N)分别代表锚点、正样本和负样本的特征嵌入。
训练时,将由锚点图像、负样本图像和正样本图像组成的三元组作为单一样本输入到模型中。这样做的目的是确保锚点与正样本图像之间的距离小于锚点与负样本图像之间的距离。
2)对比损失
对比损失是当前非常流行的损失函数,它基于距离而非传统的错误预测来计算损失。该损失函数主要应用于特征嵌入的学习,目标是优化样本点在欧几里得空间(Euclidean space)的分布:对于相似的样本点,我们希望它们之间的距离尽可能地小,以便能够准确捕捉它们之间的相似性;对于不相似的样本点,则希望它们之间的距离足够大,以便于区分差异。
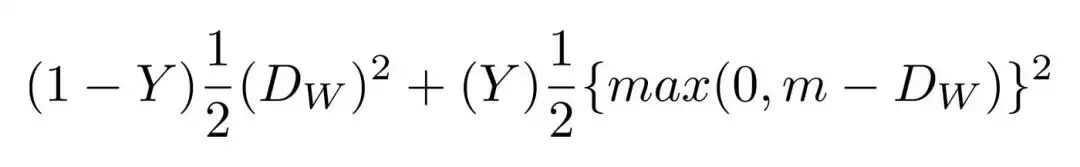
定义Dw是欧几里得距离(Euclidean distance):
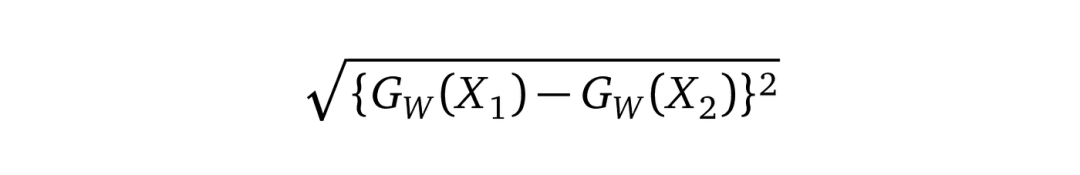
Gw是网络对一张图像的输出结果。
2.孪生网络在签名验证领域的应用
孪生网络具有优秀的相似性比较能力,常被应用于需要验证身份的系统中,例如面部识别和签名验证。
接下来,将在PyTorch框架下构建一个基于孪生神经网络的签名验证系统,实现高精度的身份验证功能。

2.1 数据集和数据集预处理
使用ICDAR 2011数据集进行签名验证,该数据集收录了荷兰用户的签名样本,包括真实和伪造的签名。数据集分为训练和测试部分,每个部分都有用户的真实与伪造签名文件夹。数据集的标签信息以CSV文件的形式提供。

ICDAR 数据集中的签名
在把这些原始数据输入神经网络之前,需要将图像转换为张量,并整合CSV中的标签。这可以通过PyTorch的自定义数据集类实现,以下是代码示例。
#数据预处理和加载
class SiameseDataset():
def __init__(self,training_csv=None,training_dir=None,transform=None):
# used to prepare the labels and images path
self.train_df=pd.read_csv(training_csv)
self.train_df.columns =["image1","image2","label"]
self.train_dir = training_dir
self.transform = transform
def __getitem__(self,index):
# 获取图像路径
image1_path=os.path.join(self.train_dir,self.train_df.iat[index,0])
image2_path=os.path.join(self.train_dir,self.train_df.iat[index,1])
# Loading the image
img0 = Image.open(image1_path)
img1 = Image.open(image2_path)
img0 = img0.convert("L")
img1 = img1.convert("L")
# 应用图像变换
if self.transform is not None:
img0 = self.transform(img0)
img1 = self.transform(img1)
return img0, img1 , th.from_numpy(np.array([int(self.train_df.iat[index,2])],dtype=np.float32))
def __len__(self):
return len(self.train_df)
预处理数据集后,需要在PyTorch框架中使用Dataloader类来加载这些数据。为了适应计算需求,通过transforms函数对图像进行尺寸调整,将其高度和宽度统一缩减至105像素。
# 从原始图像文件夹加载数据集
siamese_dataset = SiameseDataset(training_csv,training_dir,
transform=transforms.Compose([transforms.Resize((105,105)),
transforms.ToTensor()
])
)
2.2 神经网络架构
在PyTorch中创建一个神经网络:
#创建孪生网络
class SiameseNetwork(nn.Module):
def __init__(self):
super(SiameseNetwork, self).__init__()
# 设置CNN层序列
self.cnn1 = nn.Sequential(
nn.Conv2d(1, 96, kernel_size=11,stride=1),
nn.ReLU(inplace=True),
nn.LocalResponseNorm(5,alpha=0.0001,beta=0.75,k=2),
nn.MaxPool2d(3, stride=2),
nn.Conv2d(96, 256, kernel_size=5,stride=1,padding=2),
nn.ReLU(inplace=True),
nn.LocalResponseNorm(5,alpha=0.0001,beta=0.75,k=2),
nn.MaxPool2d(3, stride=2),
nn.Dropout2d(p=0.3),
nn.Conv2d(256,384 , kernel_size=3,stride=1,padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(384,256 , kernel_size=3,stride=1,padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(3, stride=2),
nn.Dropout2d(p=0.3),
)
# 定义全连接层
self.fc1 = nn.Sequential(
nn.Linear(30976, 1024),
nn.ReLU(inplace=True),
nn.Dropout2d(p=0.5),
nn.Linear(1024, 128),
nn.ReLU(inplace=True),
nn.Linear(128,2))
def forward_once(self, x):
# 前向传播
output = self.cnn1(x)
output = output.view(output.size()[0], -1)
output = self.fc1(output)
return output
def forward(self, input1, input2):
# 输入1的前向传播
output1 = self.forward_once(input1)
# 输入2的前向传播
output2 = self.forward_once(input2)
return output1, output2
在代码实现中,构建了这样的神经网络结构:首层卷积层配备了96个11x11大小的卷积核,步长为1像素,用于处理105x105像素的输入签名图像。紧接着的第二层卷积层,以第一层的输出(经过响应归一化和池化处理)为输入,使用256个5x5大小的卷积核进行特征提取。
第三层和第四层卷积层之间不涉及任何池化或归一化操作。第三层使用384个3x3大小的卷积核,直接连接到第二层卷积层的输出(该输出已经经过归一化、池化和dropout处理)。第四层卷积层则包含256个3x3大小的卷积核。这样的设计使网络能够学习到较少的低级特征,以适应更小的感受野,同时捕捉到更多的高级或抽象特征。
网络中的第一层全连接层包含1024个神经元,而第二层全连接层则有128个神经元。
通过限制两个网络共享相同的权重,实现了使用单一模型连续处理两张图像的策略。这种方法不仅节省了内存空间,还提升了计算效率。具体操作中,对这两张图像计算损失值,并执行反向传播来更新权重。
2.3 损失函数
对于这项任务,使用对比损失函数来学习特征嵌入,其目标是让相似的样本点在欧几里得空间中的距离尽可能小,而不相似的样本点则保持较大的距离。以下是在PyTorch框架中实现对比损失函数的方法。
class ContrastiveLoss(torch.nn.Module):
"""
Contrastive loss function.
Based on:
"""
def __init__(self, margin=1.0):
super(ContrastiveLoss, self).__init__()
self.margin = margin
def forward(self, x0, x1, y):
# 欧几里得距离
diff = x0 - x1
dist_sq = torch.sum(torch.pow(diff, 2), 1)
dist = torch.sqrt(dist_sq)
mdist = self.margin - dist
dist = torch.clamp(mdist, min=0.0)
loss = y * dist_sq + (1 - y) * torch.pow(dist, 2)
loss = torch.sum(loss) / 2.0 / x0.size()[0]
return loss
2.4 训练网络
孪生网络的训练过程如下:
-
初始化网络、损失函数和优化器,通过网络传递图像对的第一张图像,通过网络传递图像对的第二张图像。
-
使用第一张和第二张图像的输出计算损失,将损失反向传播以计算模型的梯度。
-
使用优化器更新权重,保存模型。
# 声明孪生网络
net = SiameseNetwork().cuda()
# 声明损失函数
criterion = ContrastiveLoss()
# 声明优化器
optimizer = th.optim.Adam(net.parameters(), lr=1e-3, weight_decay=0.0005)
#训练模型
def train():
loss=[]
counter=[]
iteration_number = 0
for epoch in range(1,config.epochs):
for i, data in enumerate(train_dataloader,0):
img0, img1 , label = data
img0, img1 , label = img0.cuda(), img1.cuda() , label.cuda()
optimizer.zero_grad()
output1,output2 = net(img0,img1)
loss_contrastive = criterion(output1,output2,label)
loss_contrastive.backward()
optimizer.step()
print("Epoch {}\n Current loss {}\n".format(epoch,loss_contrastive.item()))
iteration_number += 10
counter.append(iteration_number)
loss.append(loss_contrastive.item())
show_plot(counter, loss)
return net
#将设备设置为cuda
device = torch.device('cuda' if th.cuda.is_available() else 'cpu')
model = train()
torch.save(model.state_dict(), "model.pt")
print("Model Saved Successfully")
该模型在Google Colab上训练了20个周期,持续一个小时,以下是随时间变化的损失图:

2.5 测试模型
在测试数据集上测试我们的签名验证系统。使用Pytorch的DataLoader类加载测试数据集,传递图像对和标签,找到图像之间的欧几里得距离,根据欧几里得距离输出结果。
# 加载测试数据集
test_dataset = SiameseDataset(training_csv=testing_csv,training_dir=testing_dir,
transform=transforms.Compose([transforms.Resize((105,105)),
transforms.ToTensor()
])
)
test_dataloader = DataLoader(test_dataset,num_workers=6,batch_size=1,shuffle=True)
#测试网络
count=0
for i, data in enumerate(test_dataloader,0):
x0, x1 , label = data
concat = torch.cat((x0,x1),0)
output1,output2 = model(x0.to(device),x1.to(device))
eucledian_distance = F.pairwise_distance(output1, output2)
if label==torch.FloatTensor([[0]]):
label="Original Pair Of Signature"
else:
label="Forged Pair Of Signature"
imshow(torchvision.utils.make_grid(concat))
print("Predicted Eucledian Distance:-",eucledian_distance.item())
print("Actual Label:-",label)
count=count+1
if count ==10:
break
预测结果如下:











![[Mdp] lc198. 打家劫舍(记忆化搜索+dp)](https://i-blog.csdnimg.cn/direct/acf163a46a934db2a345dd505d4e1b06.png)