2024高教社杯全国大学生数学建模竞赛C题原创python代码
C题题目:农作物的种植策略
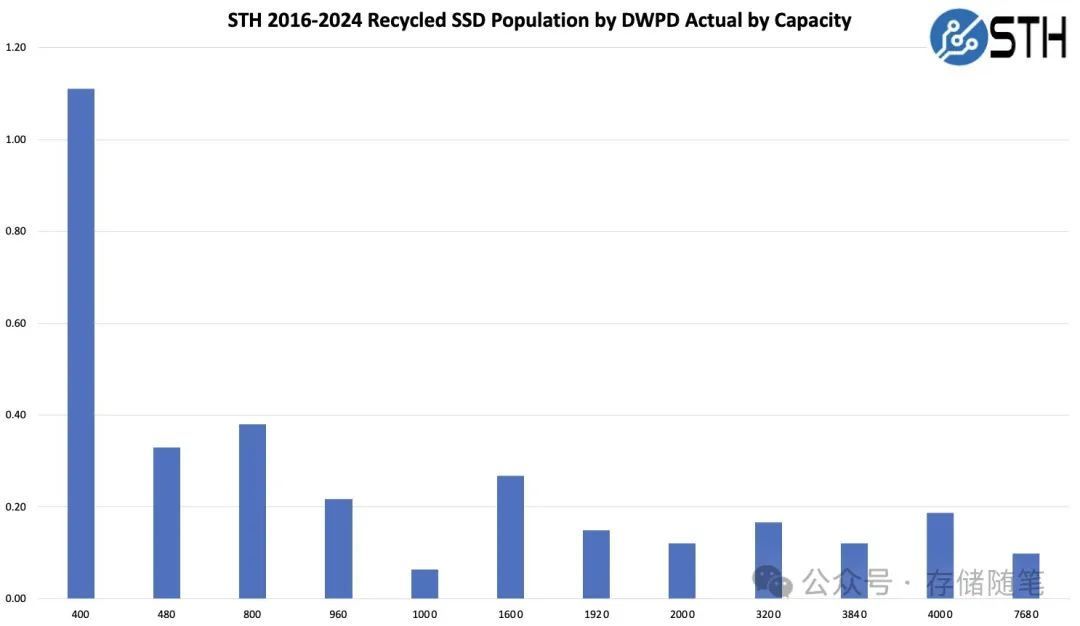
先给大家看看图吧:

#描述性统计分析
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from scipy.stats import kurtosis, skew
import os
# 读取Excel文件
filename = 'data\附件2-2清洗整理后数据.xlsx'
data = pd.read_excel(filename)
# 配置中文字体显示问题
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 提取相关数据列
crop_names = data['作物名称'] # 作物名称
yield_per_acre = data['亩产量/斤'] # 亩产量/斤
cost_per_acre = data['种植成本/(元/亩)'] # 种植成本/(元/亩)
price_per_kg = data['销售单价/(元/斤)'] # 销售单价/(元/斤)
# 设置seaborn样式
# 关闭 seaborn 的默认字体设置
sns.set(style="whitegrid", font_scale=1.2, rc={"font.sans-serif": ['SimHei'], "axes.unicode_minus": False})
# --- 1. 数据可视化 ---
# 保存图片的文件夹
output_dir = 'fig'
if not os.path.exists(output_dir):
os.makedirs(output_dir)
# 1.1 绘制直方图(数据分布)
plt.figure(figsize=(15, 15))
plt.subplot(3,1,1)
plt.hist(yield_per_acre, bins=30, color='skyblue', edgecolor='black')
plt.title('亩产量分布', fontsize=14)
plt.xlabel('亩产量(斤)')
plt.ylabel('频率')
plt.subplot(3,1,2)
plt.hist(cost_per_acre, bins=30, color='lightgreen', edgecolor='black')
plt.title('种植成本分布', fontsize=14)
plt.xlabel('种植成本(元/亩)')
plt.ylabel('频率')
plt.subplot(3,1,3)
plt.hist(price_per_kg, bins=30, color='lightcoral', edgecolor='black')
plt.title('销售单价分布', fontsize=14)
plt.xlabel('销售单价(元/斤)')
plt.ylabel('频率')
plt.tight_layout()
plt.savefig(os.path.join(output_dir, 'histograms.png')) # 保存直方图
plt.show()
# 1.2 绘制箱型图(展示数据的集中趋势和离群点)
plt.figure(figsize=(10, 12))
plt.subplot(3,1,1)
sns.boxplot(yield_per_acre, color='skyblue')
plt.title('亩产量箱型图', fontsize=14)
plt.ylabel('亩产量(斤)')
plt.subplot(3,1,2)
sns.boxplot(cost_per_acre, color='lightgreen')
plt.title('种植成本箱型图', fontsize=14)
plt.ylabel('种植成本(元/亩)')
plt.subplot(3,1,3)
sns.boxplot(price_per_kg, color='lightcoral')
plt.title('销售单价箱型图', fontsize=14)
plt.ylabel('销售单价(元/斤)')
plt.tight_layout()
plt.savefig(os.path.join(output_dir, 'boxplots.png')) # 保存箱型图
plt.show()
# 1.3 绘制散点图(展示变量之间的相关性)
plt.figure(figsize=(12, 12))
plt.subplot(2,2,1)
plt.scatter(yield_per_acre, cost_per_acre, color='skyblue')
plt.title('亩产量 vs 种植成本', fontsize=14)
plt.xlabel('亩产量(斤)')
plt.ylabel('种植成本(元/亩)')
plt.subplot(2,2,2)
plt.scatter(yield_per_acre, price_per_kg, color='lightgreen')
plt.title('亩产量 vs 销售单价', fontsize=14)
plt.xlabel('亩产量(斤)')
plt.ylabel('销售单价(元/斤)')
plt.subplot(2,2,3)
plt.scatter(cost_per_acre, price_per_kg, color='lightcoral')
plt.title('种植成本 vs 销售单价', fontsize=14)
plt.xlabel('种植成本(元/亩)')
plt.ylabel('销售单价(元/斤)')
plt.tight_layout()
plt.savefig(os.path.join(output_dir, 'scatterplots.png')) # 保存散点图
plt.show()
# --- 2. 描述性分析 ---
# 计算均值, 中位数, 标准差, 峰度, 偏度
desc_stats = {
'亩产量': {
'均值': np.mean(yield_per_acre),
'中位数': np.median(yield_per_acre),
'标准差': np.std(yield_per_acre),
'峰度': kurtosis(yield_per_acre),
'偏度': skew(yield_per_acre)
},
'种植成本': {
'均值': np.mean(cost_per_acre),
'中位数': np.median(cost_per_acre),
'标准差': np.std(cost_per_acre),
'峰度': kurtosis(cost_per_acre),
'偏度': skew(cost_per_acre)
},
'销售单价': {
'均值': np.mean(price_per_kg),
'中位数': np.median(price_per_kg),
'标准差': np.std(price_per_kg),
'峰度': kurtosis(price_per_kg),
'偏度': skew(price_per_kg)
}
}
# 打印描述性统计结果
print('--- 描述性分析 ---')
for key, stats in desc_stats.items():
print(f'{key}: 均值={stats["均值"]:.2f}, 中位数={stats["中位数"]:.2f}, 标准差={stats["标准差"]:.2f}, '
f'峰度={stats["峰度"]:.2f}, 偏度={stats["偏度"]:.2f}')
# --- 3. 相关性分析 ---
# 计算相关系数
correlations = {
'亩产量与种植成本': yield_per_acre.corr(cost_per_acre),
'亩产量与销售单价': yield_per_acre.corr(price_per_kg),
'种植成本与销售单价': cost_per_acre.corr(price_per_kg)
}
# 打印相关性分析结果
print('--- 相关性分析 ---')
for key, corr in correlations.items():
print(f'{key}的相关系数: {corr:.2f}')
# 创建 DataFrame
df = pd.DataFrame({
'作物名称': crop_names,
'亩产量': yield_per_acre,
'种植成本': cost_per_acre,
'销售单价': price_per_kg
})
# 绘制成对关系图
sns.pairplot(df[['亩产量', '种植成本', '销售单价']], diag_kind='kde', plot_kws={'alpha':0.6})
plt.suptitle('成对关系图', y=1.0, fontsize=16, fontweight='bold')
plt.savefig(os.path.join(output_dir, 'pairplot.png')) # 保存图像到fig文件夹
plt.show()
# 计算相关系数矩阵
correlation_matrix = df[['亩产量', '种植成本', '销售单价']].corr()
# 绘制热力图
plt.figure(figsize=(8, 6))
sns.heatmap(correlation_matrix, annot=True, cmap='coolwarm', center=0, linewidths=0.5, fmt='.2f')
plt.title('变量相关性热力图', fontsize=16, fontweight='bold')
plt.savefig(os.path.join(output_dir, 'correlation_heatmap.png')) # 保存图像到fig文件夹
plt.show()
import seaborn as sns
import matplotlib.pyplot as plt
# 绘制累积密度图
plt.figure(figsize=(10, 6))
sns.ecdfplot(yield_per_acre, label='亩产量', color='skyblue')
sns.ecdfplot(cost_per_acre, label='种植成本', color='lightgreen')
sns.ecdfplot(price_per_kg, label='销售单价', color='lightcoral')
plt.title('累积密度图', fontsize=16, fontweight='bold')
plt.xlabel('值')
plt.ylabel('累积概率')
plt.legend()
plt.grid(True, linestyle='--', alpha=0.6)
plt.savefig(os.path.join(output_dir, 'cdf_plots.png')) # 保存图像到fig文件夹
plt.show()
# 绘制对比图
plt.figure(figsize=(15, 10))
# 直方图
plt.subplot(2, 3, 1)
plt.hist(yield_per_acre, bins=30, color='skyblue', edgecolor='black')
plt.title('亩产量直方图')
plt.xlabel('亩产量(斤)')
plt.ylabel('频率')
plt.subplot(2, 3, 2)
plt.hist(cost_per_acre, bins=30, color='lightgreen', edgecolor='black')
plt.title('种植成本直方图')
plt.xlabel('种植成本(元/亩)')
plt.ylabel('频率')
plt.subplot(2, 3, 3)
plt.hist(price_per_kg, bins=30, color='lightcoral', edgecolor='black')
plt.title('销售单价直方图')
plt.xlabel('销售单价(元/斤)')
plt.ylabel('频率')
# 箱型图
plt.subplot(2, 3, 4)
sns.boxplot(yield_per_acre, color='skyblue')
plt.title('亩产量箱型图')
plt.ylabel('亩产量(斤)')
plt.subplot(2, 3, 5)
sns.boxplot(cost_per_acre, color='lightgreen')
plt.title('种植成本箱型图')
plt.ylabel('种植成本(元/亩)')
plt.subplot(2, 3, 6)
sns.boxplot(price_per_kg, color='lightcoral')
plt.title('销售单价箱型图')
plt.ylabel('销售单价(元/斤)')
plt.tight_layout()
plt.savefig(os.path.join(output_dir, 'histogram_boxplot_comparison.png')) # 保存图像到fig文件夹
plt.show()
异常值处理:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import kstest
# 设置字体和显示格式,确保中文显示正确
plt.rcParams['font.sans-serif'] = ['SimHei'] # 使用SimHei字体
plt.rcParams['axes.unicode_minus'] = False # 正确显示负号
# 读取Excel文件,保留原始列名
filename = 'data\附件2-2清洗整理后数据.xlsx' # 替换为实际文件路径
data = pd.read_excel(filename)
# 提取数据并删除缺失值
yield_per_acre = data['亩产量/斤'].dropna() # 删除亩产量中的缺失值
cost_per_acre = data['种植成本/(元/亩)'].dropna() # 删除种植成本中的缺失值
price_per_kg = data['销售单价/(元/斤)'].dropna() # 删除销售单价中的缺失值
# 定义函数:正态性检验,使用K-S检验
def is_normal_distribution(data):
# 如果P值大于0.05,则认为数据符合正态分布
return kstest((data - np.mean(data)) / np.std(data), 'norm')[1] > 0.05
# 检查三个变量是否符合正态分布
is_normal_yield = is_normal_distribution(yield_per_acre)
is_normal_cost = is_normal_distribution(cost_per_acre)
is_normal_price = is_normal_distribution(price_per_kg)
# 可视化:创建一个3x1的子图,用于展示异常值处理情况
fig, axs = plt.subplots(3, 1, figsize=(10, 12))
# 绘制亩产量的异常值处理图
if is_normal_yield:
# 如果亩产量符合正态分布,使用3σ原则检测异常值
mu_yield = np.mean(yield_per_acre)
sigma_yield = np.std(yield_per_acre)
outliers_yield = yield_per_acre[np.abs(yield_per_acre - mu_yield) > 3 * sigma_yield]
# 绘制直方图并标出3σ区域和异常值
axs[0].hist(yield_per_acre, bins=30, density=True, alpha=0.6, color='g')
axs[0].axvline(mu_yield - 3 * sigma_yield, color='r', linestyle='--', label='3σ下限')
axs[0].axvline(mu_yield + 3 * sigma_yield, color='r', linestyle='--', label='3σ上限')
axs[0].scatter(outliers_yield.index, outliers_yield, color='r', label='异常值')
axs[0].set_title('亩产量 (正态分布 - 3σ原则)')
else:
# 如果亩产量不符合正态分布,使用箱型图来显示异常值
axs[0].boxplot(yield_per_acre)
axs[0].set_title('亩产量 (非正态分布 - 箱型图)')
# 绘制种植成本的异常值处理图
if is_normal_cost:
mu_cost = np.mean(cost_per_acre)
sigma_cost = np.std(cost_per_acre)
outliers_cost = cost_per_acre[np.abs(cost_per_acre - mu_cost) > 3 * sigma_cost]
axs[1].hist(cost_per_acre, bins=30, density=True, alpha=0.6, color='g')
axs[1].axvline(mu_cost - 3 * sigma_cost, color='r', linestyle='--', label='3σ下限')
axs[1].axvline(mu_cost + 3 * sigma_cost, color='r', linestyle='--', label='3σ上限')
axs[1].scatter(outliers_cost.index, outliers_cost, color='r', label='异常值')
axs[1].set_title('种植成本 (正态分布 - 3σ原则)')
else:
axs[1].boxplot(cost_per_acre)
axs[1].set_title('种植成本 (非正态分布 - 箱型图)')
# 绘制销售单价的异常值处理图
if is_normal_price:
mu_price = np.mean(price_per_kg)
sigma_price = np.std(price_per_kg)
outliers_price = price_per_kg[np.abs(price_per_kg - mu_price) > 3 * sigma_price]
axs[2].hist(price_per_kg, bins=30, density=True, alpha=0.6, color='g')
axs[2].axvline(mu_price - 3 * sigma_price, color='r', linestyle='--', label='3σ下限')
axs[2].axvline(mu_price + 3 * sigma_price, color='r', linestyle='--', label='3σ上限')
axs[2].scatter(outliers_price.index, outliers_price, color='r', label='异常值')
axs[2].set_title('销售单价 (正态分布 - 3σ原则)')
else:
axs[2].boxplot(price_per_kg)
axs[2].set_title('销售单价 (非正态分布 - 箱型图)')
# 添加全局标题
plt.suptitle('作物亩产量、种植成本和销售单价的异常值检测')
# 调整布局并显示图表
plt.tight_layout(rect=[0, 0, 1, 0.95]) # 调整图表和标题的间距
plt.savefig('fig/异常值检测结果.png') # 保存图表为PNG文件
plt.show()
from scipy import stats
# 绘制QQ图
fig, axs = plt.subplots(3, 1, figsize=(10, 15))
# 亩产量QQ图
stats.probplot(yield_per_acre, dist="norm", plot=axs[0])
axs[0].set_title('亩产量 QQ图')
# 种植成本QQ图
stats.probplot(cost_per_acre, dist="norm", plot=axs[1])
axs[1].set_title('种植成本 QQ图')
# 销售单价QQ图
stats.probplot(price_per_kg, dist="norm", plot=axs[2])
axs[2].set_title('销售单价 QQ图')
plt.tight_layout()
plt.savefig('fig/qq_plots.png') # 保存图表为PNG文件
plt.show()占地面积可视化:
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
# 设置中文字体和显示负号
plt.rcParams['font.sans-serif'] = ['SimHei'] # 使用SimHei字体
plt.rcParams['axes.unicode_minus'] = False # 正确显示负号
# 读取Excel文件并提取相关数据
filename = 'data\附件1-1.xlsx' # 替换为实际文件路径
data = pd.read_excel(filename)
# 提取所需列,确保列名正确
plot_names = data['地块名称'] # 地块名称列
land_area = data['地块面积'] # 地块面积列
# 创建图形,设置图形大小
fig, ax = plt.subplots(figsize=(12, 8))
# 绘制条形图,使用自定义渐变色
colors = plt.cm.Blues(np.linspace(0.5, 1, len(plot_names))) # 渐变色
bars = ax.bar(plot_names, land_area, color=colors, edgecolor='black', linewidth=0.5)
# 设置X轴标签的旋转角度和对齐方式
ax.set_xticklabels(plot_names, rotation=45, ha='right')
# 添加坐标轴标签和标题,设置字体大小和加粗标题
ax.set_xlabel('地块名称', fontsize=12)
ax.set_ylabel('占地面积 (亩)', fontsize=12)
ax.set_title('各地块的占地面积分布', fontsize=16, fontweight='bold')
# 为每个条形图添加高度标签,调整标签位置,避免重叠
for bar in bars:
height = bar.get_height()
ax.text(bar.get_x() + bar.get_width() / 2.0, height + 0.5, # 标签位置稍微抬高
f'{height:.2f}', ha='center', va='bottom', fontsize=10, bbox=dict(facecolor='white', alpha=0.8))
# 去除图表的上、右边框线,增强简洁性
ax.spines['top'].set_visible(False)
ax.spines['right'].set_visible(False)
# 显示Y轴的虚线网格,设置为淡雅的灰色
ax.grid(axis='y', linestyle='--', alpha=0.5, color='gray')
# 调整图形布局,防止标签重叠
plt.tight_layout()
# 保存图像为PNG格式
plt.savefig('fig/地块面积分布图_美观.png', dpi=300)
# 显示图表
plt.show()
# 创建饼图
fig, ax = plt.subplots(figsize=(10, 8))
wedges, texts, autotexts = ax.pie(
land_area,
labels=plot_names,
autopct='%1.1f%%',
colors=colors,
startangle=140,
labeldistance=1.2, # 调整标签距离饼图的距离
pctdistance=0.8 # 调整比例文本距离饼图的距离
)
# 设置图表标题和字体
ax.set_title('各地块的占地面积占比', fontsize=16, fontweight='bold')
# 设置饼图标签和比例字体样式
for text in texts:
text.set_fontsize(12)
for autotext in autotexts:
autotext.set_fontsize(12)
# 保存图像为PNG格式
plt.savefig('fig/地块面积饼图.png', dpi=300)
# 显示图表
plt.show()
整体数据可视化:
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns # 用于增强配色
import os
# 读取Excel文件并保留原始列名
filename = 'data\附件2-2清洗整理后数据.xlsx' # 替换为实际文件路径
data = pd.read_excel(filename)
# 提取数据并确保作物名称是字符串类型,同时去掉缺失值
data = data.dropna(subset=['作物名称', '亩产量/斤', '种植成本/(元/亩)', '销售单价/(元/斤)']) # 删除包含空值的行
crop_names = data['作物名称'].astype(str) # 确保作物名称为字符串类型
yield_per_acre = data['亩产量/斤'] # 访问亩产量
cost_per_acre = data['种植成本/(元/亩)'] # 访问种植成本
price_per_kg = data['销售单价/(元/斤)'] # 访问销售单价
# 设置字体,解决中文显示问题
plt.rcParams['font.sans-serif'] = ['SimHei'] # 使用SimHei字体
plt.rcParams['axes.unicode_minus'] = False # 正确显示负号
# 使用seaborn的配色
colors = sns.color_palette('Set2', 10)
# 创建一个新的图窗
fig, axs = plt.subplots(3, 1, figsize=(10, 12)) # 创建3个子图,调整图窗大小
# 绘制亩产量柱状图
axs[0].bar(crop_names, yield_per_acre, color=colors)
axs[0].set_ylabel('亩产量(斤)', fontsize=12)
axs[0].set_title('不同作物的亩产量', fontsize=14)
axs[0].tick_params(axis='x', rotation=45, labelsize=10) # 旋转标签以便于显示
axs[0].grid(True, linestyle='--', alpha=0.6) # 添加网格线
# 添加数据标签
for i, value in enumerate(yield_per_acre):
axs[0].text(i, value + 0.5, f'{value:.0f}', ha='center', fontsize=10)
# 绘制种植成本柱状图
axs[1].bar(crop_names, cost_per_acre, color=colors)
axs[1].set_ylabel('种植成本(元/亩)', fontsize=12)
axs[1].set_title('不同作物的种植成本', fontsize=14)
axs[1].tick_params(axis='x', rotation=45, labelsize=10) # 旋转标签以便于显示
axs[1].grid(True, linestyle='--', alpha=0.6) # 添加网格线
# 添加数据标签
for i, value in enumerate(cost_per_acre):
axs[1].text(i, value + 10, f'{value:.0f}', ha='center', fontsize=10)
# 绘制销售单价柱状图
axs[2].bar(crop_names, price_per_kg, color=colors)
axs[2].set_ylabel('销售单价(元/斤)', fontsize=12)
axs[2].set_title('不同作物的销售单价', fontsize=14)
axs[2].tick_params(axis='x', rotation=45, labelsize=10) # 旋转标签以便于显示
axs[2].grid(True, linestyle='--', alpha=0.6) # 添加网格线
# 添加数据标签
for i, value in enumerate(price_per_kg):
axs[2].text(i, value + 0.1, f'{value:.2f}', ha='center', fontsize=10)
# 调整子图之间的间距
plt.subplots_adjust(hspace=0.5)
# 添加全局标题
fig.suptitle('作物亩产量、种植成本和销售单价比较', fontsize=16)
# 保存图片到fig文件夹中
output_dir = 'fig'
if not os.path.exists(output_dir):
os.makedirs(output_dir) # 如果文件夹不存在,创建该文件夹
output_path = os.path.join(output_dir, 'crop_comparison_chart.png')
plt.savefig(output_path, bbox_inches='tight') # 保存图片,bbox_inches='tight'确保不截断标签
# 显示图表
plt.show()
以上仅为部分。其中更详细的思路、各题目思路、代码、讲解视频、成品论文及其他相关内容,可以看文末卡片: