算法day22|组合总和 (含剪枝)、40.组合总和II、131.分割回文串
- 39. 组合总和 (含剪枝)
- 40.组合总和II
- 131.分割回文串
39. 组合总和 (含剪枝)
给你一个 无重复元素 的整数数组 candidates 和一个目标整数 target ,找出 candidates 中可以使数字和为目标数 target 的 所有 不同组合 ,并以列表形式返回。你可以按 任意顺序 返回这些组合。
candidates 中的 同一个 数字可以 无限制重复被选取 。如果至少一个数字的被选数量不同,则两种组合是不同的。
对于给定的输入,保证和为 target 的不同组合数少于 150 个。
示例 1:
输入:candidates = [2,3,6,7], target = 7
输出:[[2,2,3],[7]]
解释:
2 和 3 可以形成一组候选,2 + 2 + 3 = 7 。注意 2 可以使用多次。
7 也是一个候选, 7 = 7 。
仅有这两种组合。
示例 2:
输入: candidates = [2,3,5], target = 8
输出: [[2,2,2,2],[2,3,3],[3,5]]
示例 3:
输入: candidates = [2], target = 1
输出: []
提示:
1 <= candidates.length <= 302 <= candidates[i] <= 40candidates的所有元素 互不相同1 <= target <= 40
class Solution {
public:
vector<int> path;
vector<vector<int>> result;
int vectorSum(vector<int> path)
{
int sum=0;
for(int i=0;i<path.size();i++)
{
sum+=path[i];
}
return sum;
}
void backtracking(vector<int>& candidates, int target,int startIndex)
{
if(vectorSum(path)==target)
{
result.push_back(path);
return;
}
for(int i=startIndex;i<candidates.size();i++)
{
if(vectorSum(path)<target)
path.push_back(candidates[i]);
else
break;
backtracking(candidates,target,i);
path.pop_back();
}
return;
}
vector<vector<int>> combinationSum(vector<int>& candidates, int target) {
backtracking(candidates,target,0);
return result;
}
};
最主要的问题是:如何避免重复的组合?因为当循环到后面的数了,下面的递归还得从头开始,这就会造成组合重复。所以,关键的解决方法是:引入startIndex。标记每次循环的开始,让本层递归必须在上一次递归的数开始,而不是都从头开始,即:
for(int i=startIndex;i<candidates.size();i++)
backtracking(candidates,target,i);
当上一次递归到 i 的时候,下一层递归就从 i 开始,如图(来自卡哥):
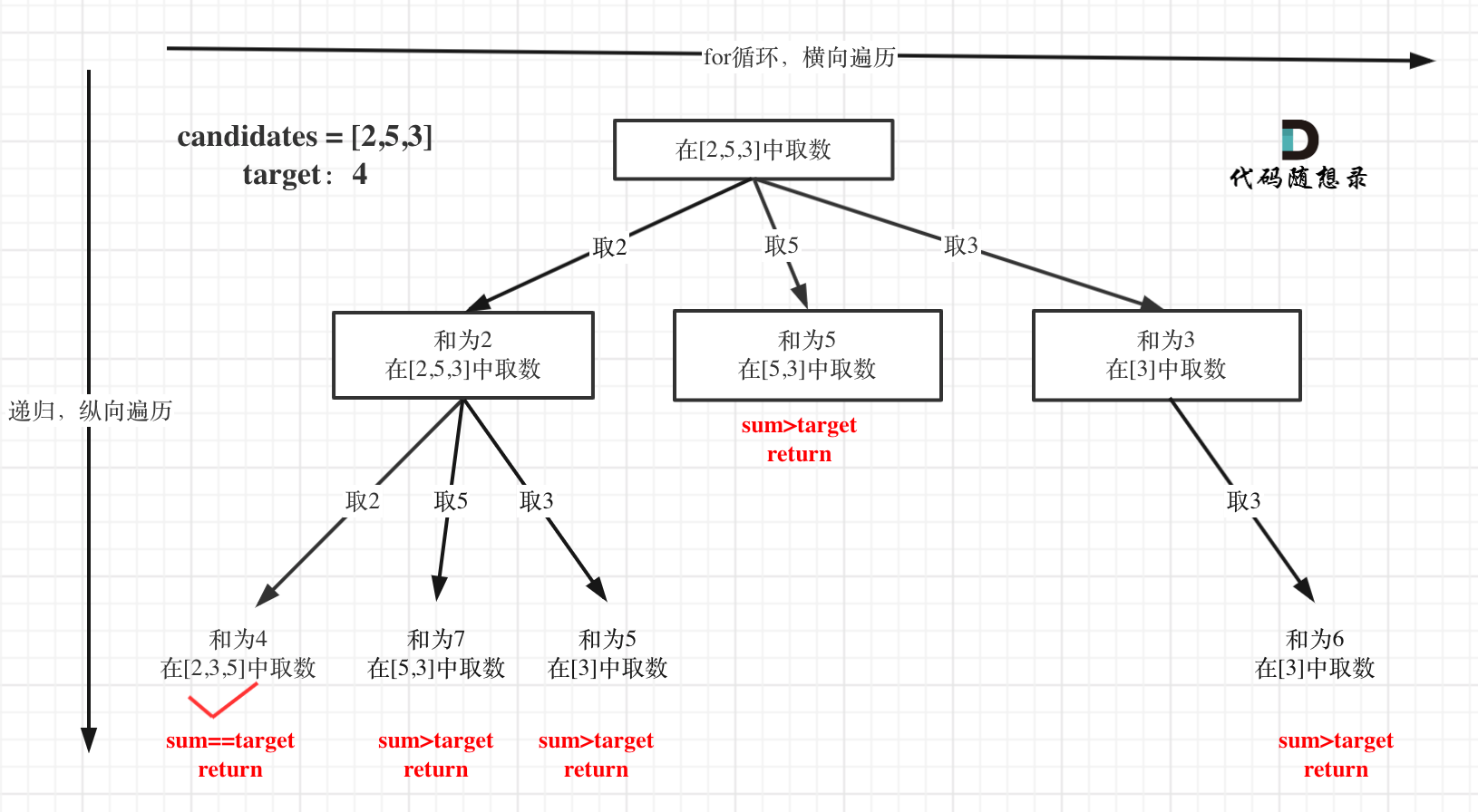
最好画图来帮助理解。对于取和的操作,最好还是不要用函数,用变量sum,边遍历边求和,这样可以减少时间复杂度。
40.组合总和II
给定一个候选人编号的集合 candidates 和一个目标数 target ,找出 candidates 中所有可以使数字和为 target 的组合。
candidates 中的每个数字在每个组合中只能使用 一次 。
**注意:**解集不能包含重复的组合。
示例 1:
输入: candidates = [10,1,2,7,6,1,5], target = 8,
输出:
[
[1,1,6],
[1,2,5],
[1,7],
[2,6]
]
示例 2:
输入: candidates = [2,5,2,1,2], target = 5,
输出:
[
[1,2,2],
[5]
]
提示:
1 <= candidates.length <= 1001 <= candidates[i] <= 501 <= target <= 30
class Solution {
public:
vector<int> path;
vector<vector<int>> result;
int sum=0;
void backtracking(vector<int>& candidates, int target,int startIndex,vector<bool> &used)
{
if(sum==target)
{
result.push_back(path);
return;
}
for(int i=startIndex;i<candidates.size();i++)
{
if(i>0&&candidates[i]==candidates[i-1]&&used[i-1]==false)
continue;
path.push_back(candidates[i]);
sum+=candidates[i];
used[i]=true;
if(sum>target)
{
path.pop_back();
sum-=candidates[i];
used[i]=false;
continue;
}
backtracking(candidates,target,i+1,used);
path.pop_back();
sum-=candidates[i];
used[i]=false;
}
}
vector<vector<int>> combinationSum2(vector<int>& candidates, int target) {
vector<bool> used(candidates.size(),false);
sort(candidates.begin(),candidates.end());
backtracking(candidates,target,0,used);
return result;
}
};
本题的关键:去重
方法:用一个布尔型数组,用来给candidates中的每一项做标记。
具体过程:
-
首先,将candidates排序,使得重复的元素相邻(如果没有重复元素的话,正常处理是不会有重复组合的。),要知道,重复的组合都来自之后重复的元素(仔细想想其中的过程)
-
然后,对vector作初始化,把所有的项都设为false:
vector<bool> used(candidates.size(),false);
- 最后,在for循环中,当(i>0)candidates[i]==candidates[i-1]时,说明前后两个数是重复的项,那么问题来了:只要重复就要跳过吗?显然,如果是树枝重复,即在一个组合内有重复元素是OK的;而如果是树层重复,就会产生重复的组合了(想像一下),所以这种情况是不行的。所以判定条件为:
if(i>0&&candidates[i]==candidates[i-1]&&used[i-1]==false)
continue;
131.分割回文串
给你一个字符串 s,请你将 s 分割成一些子串,使每个子串都是
回文串
。返回 s 所有可能的分割方案。
示例 1:
输入:s = "aab"
输出:[["a","a","b"],["aa","b"]]
示例 2:
输入:s = "a"
输出:[["a"]]
提示:
1 <= s.length <= 16s仅由小写英文字母组成
class Solution {
public:
vector<string> path;
vector<vector<string>> result;
bool HuiWen(string s, int start,int end)
{
bool flag=true;
for(int i=start,j=end;i<j;i++,j--)
{
if(s[i]!=s[j])
flag=false;
}
return flag;
}
void backtracking(string s,int startIndex)
{
if(startIndex==s.size())
{
result.push_back(path);
return;
}
for(int i=startIndex;i<s.size();i++)
{
if(HuiWen(s,startIndex,i))
{
string str=s.substr(startIndex,i-startIndex+1);
path.push_back(str);
}
else
continue;
backtracking(s,i+1);
path.pop_back();
}
return;
}
vector<vector<string>> partition(string s) {
backtracking(s,0);
return result;
}
};
这题难度很大,熟能生巧吧。关键思路在于如何表示切割:用区间 [ startIndex , i ] 来表示,每次都切割这个区间内的字符串即可。能够不断重新切割的逻辑就是回溯,切完之后就回去了,重新让下一个 i 来切。
代码细节:
- strsub()函数
s.substr (pos, n) ,pos表示要截取的字符串的开始的位置,n 代表要截取的字符串的长度。
s.substr(pos) , 表示从pos位置开始的到字符串最后一位截取的字符串
string str=s.substr(startIndex,i-startIndex+1);