第六章. UVM中的sequence
6.1 sequence基础
6.1.1 从driver中剥离激励产生功能
sequence机制的作用是为了从driver中剥离出产生激励的功能。在不同的测试用例中,将不同的sequence设置成sequencer的main_phase的default_sequence。当sequencer执行到main_phase时,发现有default_sequence,那么就会启动sequence(default也是调用start任务启动sequence)。
6.1.2 sequence的启动与执行
- 调用sequence的start任务将其启动。
- 使用default_sequence启动。(事实上default_sequence会调用sequence的start任务)
- 一种是直接将sequence类设置为某个sequencer的default_sequence
- 另一种是先实例化要启动的sequence,之后再设置为某个sequencer的default_sequence
//直接设置sequence的类类型为default_sequence
uvm_config_db#(uvm_object_wrapper)::set(this,
"env.i_agt.sqr.main_phase",
"default_sequence",
case0_sequence::type_id::get());
//实例化sequence对象,再设置default_sequence
function void my_case0::build_phase(uvm_phase phase);
case0_sequence cseq;
super.build_phase(phase);
cseq = new("cseq");
uvm_config_db#(uvm_sequence_base)::set(this,
"env.i_agt.sqr.main_phase",
"default_sequence",
cseq);
endfunction
当一个sequence启动后会自动执行sequence的body任务。除了body任务外,还会自动调用sequence的pre_body和post_body任务。
6.2 sequence的仲裁机制
6.2.1 在同一sequencer上启动多个sequence
在同一个sequencer上启动多个sequence时,哪个sequence先执行,这就涉及到seq的优先级和UVM仲裁算法。
- 对于transaction来说,存在优先级的概念,通常来说,优先级越高越容易被选中。当使用uvm_do或者uvm_do_with宏时,产生的transaction的优先级是默认的优先级,即-1。可以使用uvm_do_pri及uvm_do_pri_with改变所产生的transaction的优先级。
`uvm_do_pri(m_trans, 100)
`uvm_do_pri_with(m_trans, 200, {m_trans.pload.size < 500;})
- 对于sequence来说,也存在优先级概念。可以在sequence启动的时候指定其优先级。对sequence设置优先级的本质即设置其内产生的transaction的优先级。
seq0.start(env.i_agt.sqr, null, 100);
UVM中仲裁算法:
SEQ_ARB_FIFO:先进先出,不考虑优先级(默认)
SEQ_ARB_WEIGHTED:加权仲裁
SEQ_ARB_RANDOM:随机选择
SEQ_ARB_STRICT_FIFO:严格按照优先级,当有多个同一优先级,按照先进先出
SEQ_ARB_STRICT_RANDOM:严格按照优先级,当有多个同一优先级,随机从最高优先级中选择
SEQ_ARB_USER:用户自定义新的仲裁算法
通常transaction和sequence的优先级和UVM仲裁算法配合使用。如果想按照sequence或者transaction的优先级进行发送激励,则要讲UVM仲裁算法设置为SEQ_ARB_STRICT_FIFO或者SEQ_ARB_STRICT_RANDOM。仲裁算法通过sequencer的set_arbitration来实现。
env.i_agt.sqr.set_arbitration(SEQ_ARB_STRICT_FIFO);
6.2.2 sequencer的lock操作
Lock操作就是sequencer在开始相应这个lock请求,此后sequencer会一直连续发送此sequence的transaction,直到unlock操作被调用。从效果上来看,此sequencer的所有权并没有被所有的sequence共享,而是被申请lock操作的sequence独占了。代码如下,在lock语句之后,一直发送sequence1的transaction,直到unlock语句被调用。
class sequence1 extends uvm_sequence #(my_transaction);
…
virtual task body();
…
repeat (3)
begin
`uvm_do_with(m_trans, {m_trans.pload.size < 500;})
`uvm_info("sequence1", "send one transaction", UVM_MEDIUM)
end
lock();
`uvm_info("sequence1", "locked the sequencer ", UVM_MEDIUM)
repeat (4)
begin
`uvm_do_with(m_trans, {m_trans.pload.size < 500;})
`uvm_info("sequence1", "send one transaction", UVM_MEDIUM)
end
`uvm_info("sequence1", "unlocked the sequencer ", UVM_MEDIUM)
unlock();
repeat (3)
begin
`uvm_do_with(m_trans, {m_trans.pload.size < 500;})
`uvm_info("sequence1", "send one transaction", UVM_MEDIUM)
end
…
endtask
…
endclass
如果两个sequence都使用lock任务来获取sequencer的所有权,先获得所有权的sequence在执行完毕后才会将所有权交还给另外一个sequence。
6.2.3 sequencer的grab操作
grab操作也是用于暂时用于sequencer的所有权,grab操作比lock操作优先级更高。lock请求是被插入sequencer仲裁队列的最后面,等到它时,他前面的仲裁请求都已经结束了。grap请求则被放入sequencer仲裁队列的最前面,它几乎是已发出就拥有了sequencer的所有权。
如果两个sequence同时使用grab任务获取sequencer的所有权,则此情形和两sequence同时调用lock函数一样,在先获得所有权的sequence执行完毕后才会将所有权交还给另一个试图获取所有权的sequence。
如果一个sequence在使用grap任务获取sequencer的所有权前,另一个sequence已经使用lock任务获得了sequencer的所有权,则grap任务会一直等待lock的释放。grap任务会插队,但是绝对不会打断别人正在进行的事情。
6.2.4 sequence的有效性
通过lock/grab任务,sequence可以独占sequencer,强行sequencer发送自己产生的transaction。同样的,UVM也提供了措施使sequence可以在一定时间不参与仲裁。
sequencer在仲裁时,会查看sequence的is_relevant函数的返回结果。如果为1,说明此sequence有效,否则无效。可以通过重载is_relevant函数来使sequence失效。
class sequence0 extends uvm_sequence #(my_transaction);
my_transaction m_trans;
int num;
bit has_delayed;
…
virtual function bit is_relevant();
if((num >= 3)&&(!has_delayed)) return 0;
else return 1;
endfunction
virtual task body();
fork
repeat (10)
begin
num++;
`uvm_do(m_trans)
`uvm_info("sequence0", "send one transaction", UVM_MEDIUM)
end
while(1)
begin
if(!has_delayed)
begin
if(num >= 3)
begin
`uvm_info("sequence0", "begin to delay", UVM_MEDIUM)
#500000;
has_delayed = 1'b1;
`uvm_info("sequence0", "end delay", UVM_MEDIUM)
break;
end
else #1000;
end
end
join
…
endtask
…
endclass
上述代码中sequence在发送3个transaction后开始变为无效,延时500000时间单位后又开始有效。
除了is_relevant外,sequence还有一个任务wait_for_relevant也与sequence的有效性相关。当sequencer发现sequence无效时,会调用其wait_for_relevant任务。在wait_for_relevant中,必须将使sequence无效的条件清除(当不清除sequence无效状态时,在sequencer调用sequence的wait_for_relevant后,发现sequence依然处于无效状态,那么会继续调用wait_for_relevant任务,系统将陷入死循环)。因此is_relevant和wait_for_relevant一般应成对重载,不能只重载一个。
6.3 sequence相关的宏及实现
6.3.1 uvm_do系列宏
uvm_do系列宏主要有以下8个:
- uvm_do(SEQ_OR_ITEM)
- uvm_do_pri(SEQ_OR_ITEM, PRIORITY)
- uvm_do_with(SEQ_OR_ITEM, CONSTRAINTS)
- uvm_do_pri_with(SEQ_OR_ITEM, PRIORITY, CONSTRAINTS)
- uvm_do_on(SEQ_OR_ITEM, SEQR)
- uvm_do_on_pri(SEQ_OR_ITEM, SEQR, PRORITY)
- uvm_do_on_with(SEQ_OR_ITEM, SEQR, CONSTRAINTS)
- uvm_do_on_pri_with(SEQ_OR_ITEM, SEQR, PRIORITY, CONSTRAINTS)
uvm_do_on用于显式地指定使用哪个sequencer发送此transaction。他有两个参数,第一个是transaction的指针,第二个是sequencer的指针。当在sequence中使用uvm_do等宏时,其默认的sequencer就是此sequence启动时为其指定的sequencer,sequence将这个sequencer的指针放在其成员变量m_sequencer中。
uvm_do系列宏中,其第一个参数除了可以是transaction的指针外,还可以是某个serquence的指针。当第一个参数是transaction时,他会调用start_item和finish_item(参考6.3.4);当第一个参数是sequence时,他调用sequence的start任务。
//uvm_do宏等价于如下代码
`uvm_do_on(tr, this.m_sequencer)
uvm_do_on_pri的第三个参数是优先级,这个数值必须是一个大于等于-1的整数。数值越大,优先级越高。
`uvm_do_on_pri(tr, this, 100)
uvm_do_on_with的第三个参数是约束。
`uvm_do_on_with(tr, this, {tr.pload.size==100;} )
uvm_do_on_pri_with,有四个参数,是所有uvm_do宏中参数最多的一个。uvm_do系列宏的其他七个宏都是用uvm_do_on_pri_with宏来实现的。
`uvm_do_on_pri_with(tr, this, 100, {tr.pload.size==100;} )
6.3.2 uvm_create与uvm_send
除了uvm_do宏产生transaction,还可以使用uvm_create宏与uvm_send宏来产生。
- uvm_create:实例化transaction(可以使用new函数替代uvm_create)
- uvm_send:发送transaction
- uvm_send_pri:发送transaction时指定优先级
相比uvm_do系列宏,使用uvm_create/uvm_send/uvm_send_pri系列宏更加灵活,可以对transaction进行控制。
6.3.3 uvm_rand_send系列宏
- uvm_rand_send(SEQ_OR_ITEM)
- uvm_rand_send_pri(SEQ_OR_ITEM, PRIORITY)
- uvm_rand_send_with(SEQ_OR_ITEM,CONSTRAINTS)
- uvm_rand_send_pri_with(SEQ_OR_ITEM, PRIORITY, CONSTRAINTS)
uvm_rand_send宏与uvm_send宏类似,唯一的区别是它会对transaction进行随机化。这个宏使用的前提是transaction已经被分配了空间(已经被实例化)。
uvm_rand_send,uvm_send系列宏的意义主要在于,如果一个transaction占用的内存比较大,那么可能希望前后两次发送的transaction都使用同一块内存,只是其中的内容可以不同,这样比较节省内存。
6.3.4 start_item与finish_item
宏隐藏了细节,方便了用户的使用,但是也给用户带来了困扰:宏到底做了什么事情?
- start_item
- finish_item
使用uvm_do系列宏就相当于使用以下代码:
virtual task bodu();
tr=new("tr");
start_item(tr);
assert(tr.randomize() with {tr.pload.size() == 200;
});
finish_item(tr);
endtask
6.3.5 pre_do,mid_do与post_do
uvm_do宏封装了从transaction实例化到发送的一系列操作,封装的越多,则其灵活性越差。为了增加uvm_do系列宏的功能,UVM提供了三个接口:pre_do,mid_do和post_do(类似于回调函数)。
- pre_do是一个任务,在start_item中被调用,他是start_item返回前执行的最后一行代码。
- mid_do是一个函数,位于finish_item的最开始,在执行完此函数后,finish_item才进行其他操作。
- post_do是一个函数,位于finish_item中,他是finish_item返回前执行的最后一行代码。

start_item和finish_item的使用需要配合pre_do,mid_do和post_do一同使用。
6.4 sequence进阶应用
6.4.1 嵌套的sequence
如果有需求需要产生不同类型的sequence,那么可以使用嵌套sequence。所谓嵌套sequence,即在一个sequence的body中,启动其他的sequence。通过嵌套sequence实现sequence的重用。
class case0_sequence extends uvm_sequence #(my_transaction);
…
virtual task body();
crc_seq cseq;
long_seq lseq;
…
repeat (10)
begin
cseq = new("cseq");
cseq.start(m_sequencer);
lseq = new("lseq");
lseq.start(m_sequencer);
end
…
endtask
…
endclass
6.4.2 在sequence中使用rand类型变量
在transaction的定义中,通常使用rand来对变量进行修饰,说明在调用randomize时要对此字段进行随机化。
sequence中也可以添加任意多的rand修饰符,此sequence作为底层的sequence供顶层sequence调用。
6.4.3 transaction类型的匹配
一个sequencer只能产生一种类型的transaction,一个sequence如果想要在此sequencer上启动,那么其所产生的transaction的类型必须是这种transaction或者派生自这种transaction。这里需注意的是嵌套sequence,由于包含多个sequence,必须保证嵌套sequence中每个sequence产生的transaction与sequencer上允许的transaction是同一种transaction,此时嵌套sequence才可以在此sequencer上启动。
在sequencer上发送两个或者多个不同的transaction:将sequencer中允许发送的transaction定义为父类(uvm_sequence_item),在嵌套seuqnece中每个sequence上发送的transaction继承自uvm_sequence_item,即可实现在同一个sequencer上发送不同transaction(sequence中的transaction是sequencer上transaction的子类)。这里对其他组件带来的影响是,driver组件中的transaction同样需要声明为uvm_sequence_item类型。
6.4.4 m_sequencer与p_sequencer
考虑一种情况,如何在sequence中访问sequencer中的成员变量呢?
一种方法是使用m_sequencer。m_sequencer是属于每个sequence的成员变量,其指向该sequence启动的sequencer。如果直接使用m_sequencer访问sequencer的变量,会引起编译错误。因为m_seuqencer是uvm_sequencer_base(uvm_sequencer的基类)类型,而不是my_sequencer类型。使用前需要在my_sequence中通过case转换将m_sequencer转换成my_sequencer类型,这样就可以引用sequencer中定义的变量。
virtual task body();
my_sequencer x_sequencer;
…
$cast(x_sequencer, m_sequencer);
repeat (10)
begin
`uvm_do_with(m_trans, {m_trans.dmac == x_sequencer.dmac;
m_trans.smac == x_sequencer.smac;})
end
…
endtask
另一种方法是使用p_sequencer。UVM内置了一个宏uvm_declare_p_sequencer(SEQUENCER),该宏声明了一个SEQUENCER类型的成员变量。使用此宏的本质是声明了一个SEQUENCER类型的成员变量,如下代码是等同的效果。
class case0_sequence extends uvm_sequence #(my_transaction);
my_transaction m_trans;
`uvm_object_utils(case0_sequence)
`uvm_declare_p_sequencer(my_sequencer)
…
endclass
class case0_sequence extends uvm_sequence #(my_transaction);
my_sequencer p_sequencer;
…
endclass
UVM会自动将m_sequencer通过cast转换成p_sequencer。这个过程在pre_body()之前就完成了。因此sequence中可以直接使用成员变量p_sequencer访问sequencer中的成员变量。
6.4.5 sequence的派生与继承
sequence作为一个类,可以从其中派生其他sequence的。同一个项目中各sequence都是类似的,所以可以将很多公用的函数或者任务下载base_sequence中,其他的sequence都从此sequence派生。
普通的sequence这样使用没有任何问题,但是对于使用了uvm_declare_p_sequence声明的base_sequence,在派生的sequence中是否也要使用此宏重新声明p_sequencer?答案是不需要重新声明,因为uvm_declare_p_sequence的实质是在base_sequence中声明了一个成员变量p_sequencer,当其他sequence从其派生时,子类sequence会继承父类的成员变量p_sequencer,所以无需再声明一次。如果在子类sequence中再声明一次,系统也不会报错,此时相当于声明了两个p_sequencer,一个属于父类,一个属于子类。
6.5 virtual sequence的使用
6.5.2 sequence之间的简单同步
利用全局事件进行同步
event send_over; //global event
class drv0_seq extends uvm_sequence #(my_transaction);
…
virtual task body();
…
`uvm_do_with(m_trans, {m_trans.pload.size == 1500;})
->send_over;
repeat (10)
begin
`uvm_do(m_trans)
`uvm_info("drv0_seq", "send one transaction", UVM_MEDIUM)
end
…
endtask
endclass
class drv1_seq extends uvm_sequence #(my_transaction);
…
virtual task body();
@send_over;
repeat (10)
begin
`uvm_do(m_trans)
`uvm_info("drv1_seq", "send one transaction", UVM_MEDIUM)
end
…
endtask
endclass
如上述代码中,drv0_seq在发送一个m_trans后,触发全局事件send_overdrv1_seq才会开始发送transaction。
6.5.3 sequence之间的复杂同步
上节中使用了全局变量进行同步,但是,除非有必要,尽量不要使用全局变量。事实上,上节中使用全局变量只实现了一次同步,如果要进行多次同步呢?
实现sequence之间的同步最好的方式是使用virtual sequence。虚拟的sequence本身不发送transaction,只是控制其他sequence,起统一调度作用。为了使用virtual sequence,一般需要一个virtual sequencer。virtual sequencer里面包含指向其他真实sequencer的指针。由于virtual sequence/sequencer根本不直接产生transaction,所以virtual sequence/sequencer在定义时根本无需指明要发送的transaction数据类型。
class my_vsqr extends uvm_sequencer;
my_sequencer p_sqr0;
my_sequencer p_sqr1;
…
endclass
在base_test中,实例化vsqr,并将相应的sequencer赋值给vseq中的sequencer的指针。
class base_test extends uvm_test;
my_env env0;
my_env env1;
my_vsqr v_sqr;
…
endclass
function void base_test::build_phase(uvm_phase phase);
super.build_phase(phase);
env0 = my_env::type_id::create("env0", this);
env1 = my_env::type_id::create("env1", this);
v_sqr = my_vsqr::type_id::create("v_sqr", this);
endfunction
function void base_test::connect_phase(uvm_phase phase);
v_sqr.p_sqr0 = env0.i_agt.sqr;
v_sqr.p_sqr1 = env1.i_agt.sqr;
endfunction
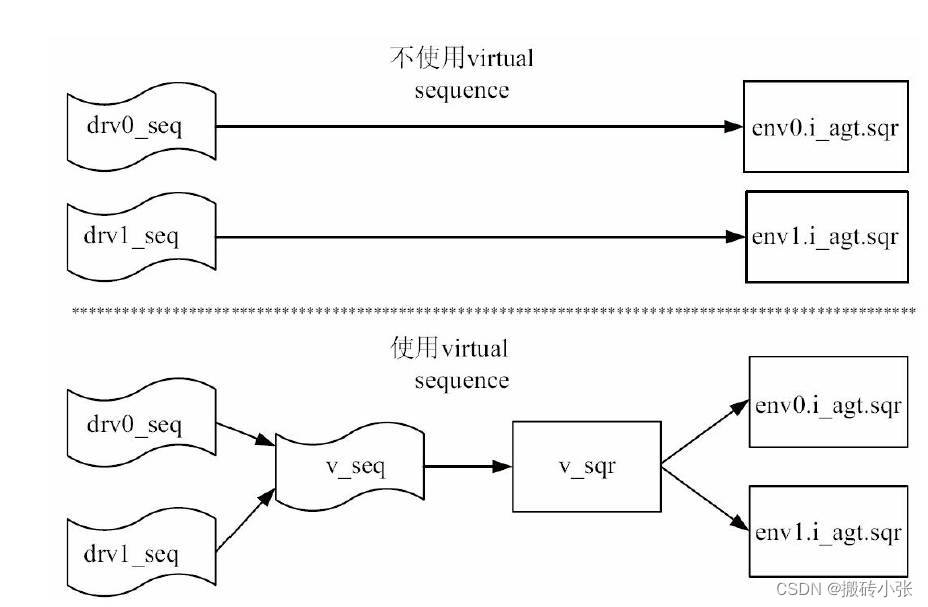
在virtual sequence中则可以使用uvm_do_on系列宏来发送transaction。
class case0_vseq extends uvm_sequence;
`uvm_object_utils(case0_vseq)
`uvm_declare_p_sequencer(my_vsqr)
…
virtual task body();
my_transaction tr;
drv0_seq seq0;
drv1_seq seq1;
…
`uvm_do_on_with(tr, p_sequencer.p_sqr0, {tr.pload.size == 1500;})
`uvm_info("vseq", "send one longest packet on p_sequencer.p_sqr0", UVM_MEDIUM)
fork
`uvm_do_on(seq0, p_sequencer.p_sqr0);
`uvm_do_on(seq1, p_sequencer.p_sqr1);
join
…
endtask
endclass
virtual sequence是uvm_do_on宏用的最多的地方。virtual sequence中的body任务代码是顺序执行的,在其中启动seq会自动顺序执行,同时可以使用fork…join系列语句对不同seq启动进行控制。
另外,virtual sequence的使用可以减少config_db语句的使用(设置sequence为启动sequencer的main_phase的default sequence)。virtual sequence作为一种特殊的sequence,也可以在其中启动其他的virtual sequence。
6.5.4 仅在virtual sequence中控制objection
在sequence中可以使用starting_phase来控制验证平台的关闭。除了手动启动sequence时为starting_phase赋值外,只有将此sequence作为sequencer的某动态运行phase的default_sequence时,其starting_phase才不为null。如果将某些sequence作为uvm_do宏的参数,那么此sequence的starting_phase是为null的,在此sequence中使用starting_phase的raise_objection是没有任何用处的。
在有virtual sequence之后,有三个地方可以控制objection。一个是普通的sequence,二是中间层的virtual sequence。三是最顶层的virtual sequence。
一般来说只在最顶层的virtual sequence中控制objection。因为virtual sequence是起统一调度作用的,这种统一调度不只体现在transaction,也应该体现在objection的控制上。
6.5.5 在sequence中慎用fork join_none
class case0_vseq extends uvm_sequence;
virtual task body();
drv_seq dseq[4];
for(int i = 0; i < 4; i++)
fork
automatic int j = i;
`uvm_do_on(dseq[j], p_sequencer.p_sqr[j]);
join_none
endtask
endclass
在for循环中使用fork join_none,其等同于以下代码:
class case0_vseq extends uvm_sequence;
virtual task body();
drv_seq dseq[4];
fork
uvm_do_on(dseq[0], p_sequencer.p_sqr[0]);
join_none
fork
uvm_do_on(dseq[1], p_sequencer.p_sqr[1]);
join_none
fork
uvm_do_on(dseq[2], p_sequencer.p_sqr[2]);
join_none
fork
uvm_do_on(dseq[3], p_sequencer.p_sqr[3]);
join_none
//wait fork; wait all 4-thread end
endtask
endclass
上述代码启动了四个线程,系统并不会等这4个sequence执行完毕就返回了。执行完成之后,系统会清理这4个sequence之前占据的内存空间。因此,这个四个线程只是启动,并没有完成就被系统杀掉了。要避免这个问题,需要在线程后添加wait fork语句。
6.6 在sequence中使用config_db
6.6.1 在sequence中获取参数
sequence机制是UVM中强大的机制之一,config_db机制也对sequence机制提供了支持,可以在sequence中获取参数。sequence本身是一个object,无法像uvm_component那样出现在UVM树中,所以在sequence中获取参数最大的问题是路径问题。
可以使用get_full_name得到一个component的完整路径,同样的,此函数也可以在一个sequence中被调用。以下为sequence中调用此函数打印的结果:
uvm_test_top.env.i_agt.sqr.case0_sequence
这个路径有两部分组成:此sequence的sequencer的路径+此sequence实例化时传递的名字。因此可以使用如下方式为一个sequencer传递参数:
uvm_config_db#(int)::set(this, "env.i_agt.sqr.*", "count", 9);
在set函数的第二个参数出现了通配符,因为sequence在实例化名字一般是不固定的,而且有时是未知的(如使用default_sequence启动的sequence的名字就是未知的),所以使用通配符。在sequence中使用如下函数获取参数:
class case0_sequence extends uvm_sequence #(my_transaction);
…
virtual task pre_body();
if(uvm_config_db#(int)::get(null, get_full_name(), "count", count))
`uvm_info("seq0", $sformatf("get count value %0d via config_db", count), UVM_MEDIUM)
else
`uvm_error("seq0", "can't get count value!")
endtask
…
endclass
这里需要说明的是第一个参数,由于sequence不是一个component,所以第一个参数不能是this。只能使用null,或者uvm_root::get()。
6.6.2 在sequence中设置参数
在sequence中获取参数与设置参数类似:
//向scb中设置参数cmp_en
uvm_config_db#(bit)::set(uvm_root::get(), "uvm_test_top.env0.scb", "cmp_en", 0);
//向sequence中设置参数first_start
uvm_config_db#(bit)::set(uvm_root::get(), "uvm_test_top.v_sqr.*", "first_start", 0);
6.6.3 wait_modified的使用
一个sequence是在task phase中运行的,当其设置一个参数时,其时间往往是不固定的。真毒这种不固定的设置参数的方式,UVM中提供了wait modified任务。wait_modified的其参数有三个,与config_db::get的前三个参数完全一样。当他检测到第三个参数的值被更新过后,它就返回,否则一直等待。
task my_scoreboard::main_phase(uvm_phase phase);
…
fork
while(1)
begin
uvm_config_db#(bit)::wait_modified(this, "", "cmp_en");
void'(uvm_config_db#(bit)::get(this, "", "cmp_en", cmp_en));
`uvm_info("my_scoreboard", $sformatf("cmp_en value modified, the new value is %0d", cmp_en), UVM_LOW)
end
…
join
endtask
上述代码中,wait_modified检测到参数值被设置后,立刻调用config_db::get得到新的参数。与get函数一样,除了可以在一个component中使用,还可以在一个sequence中使用wait_modified任务。
6.7 response的使用
6.7.1 put_response与get_response
sequence提供了一种sequence→sequencer→driver的单向数据传输机制。在一个复杂的验证平台中,sequence需要根据driver对transaction的反应来决定要发送的transaction,换而言之,sequence需要得到driver的一个反馈。sequence机制提供对这种反馈的支持,它允许driver将一个response返回给sequence。如果要使用response,那么在sequence中需要使用get_response任务:
class case0_sequence extends uvm_sequence #(my_transaction);
…
virtual task body();
…
repeat (10)
begin
`uvm_do(m_trans)
get_response(rsp);
`uvm_info("seq", "get one response", UVM_MEDIUM)
rsp.print();
end
…
endtask
在driver中,则需要使用put_response任务:
task my_driver::main_phase(uvm_phase phase);
…
while(1)
begin
seq_item_port.get_next_item(req);
drive_one_pkt(req);
rsp = new("rsp");
rsp.set_id_info(req);
seq_item_port.put_response(rsp);
seq_item_port.item_done();
end
endtask
这里关键是设置set_id_info函数,它将req的id等信息复制到rsp中。由于可能存在多个sequence在同一个sequencer上启动的情况,只有设置了rsp的id等信息,sequencer才知道将response返回给哪个sequence。除了使用put_response外,UVM还支持直接将response作为item_done的参数。
6.7.2 response的数量问题
通常来说,一个transaction对应一个response,事实上,UVM也支持一个transaction对应多个response的情况,在这种情况下,在sequence中需要多次调用get_response,而在driver中,需要多次调用put_response。
task my_driver::main_phase(uvm_phase phase);
while(1)
begin
seq_item_port.get_next_item(req);
drive_one_pkt(req);
rsp = new("rsp");
rsp.set_id_info(req);
seq_item_port.put_response(rsp);
seq_item_port.put_response(rsp);
seq_item_port.item_done();
end
endtask
class case0_sequence extends uvm_sequence #(my_transaction);
virtual task body();
repeat (10)
begin
`uvm_do(m_trans)
get_response(rsp);
rsp.print();
get_response(rsp);
rsp.print();
end
endtask
endclass
当存在多个response时,将response作为item_done参数的方式就不适用了。由于一个transaction只能对应一个item_done,所以多次调用item_done会出错。
response机制的原理是,driver将rsp推送给sequencer,而sequencer内部维持一个队列,当有新的response进入时,就推入此对垒。默认情况下,此队列的大小为8。当队列中元素满时,driver再次向此队列推送新的response,UVM会报错。
6.7.3 response handler与另类的response
driver发送response和sequence获取response是在同一个进程中进行的。如果想将两者分离开来,在不同的进程中运行将会看到不同的结果,这种情况需要使用response_handler。
class case0_sequence extends uvm_sequence #(my_transaction);
…
virtual task pre_body();
use_response_handler(1);
endtask
virtual function void response_handler(uvm_sequence_item response);
if(!$cast(rsp, response))
`uvm_error("seq", "can't cast")
else
begin
`uvm_info("seq", "get one response", UVM_MEDIUM)
rsp.print();
end
endfunction
virtual task body();
if(starting_phase != null)
starting_phase.raise_objection(this);
repeat (10)
begin
`uvm_do(m_trans)
end
#100;
if(starting_phase != null)
starting_phase.drop_objection(this);
endtask
`uvm_object_utils(case0_sequence)
endclass
response handler功能默认是关闭的,如果要是用response_handler,首先要调用use_response_handler函数,打开sequence的response handler功能。
打开response_handler功能后,用户需要重载函数response_handler,此函数的参数是一个uvm_sequence_item类型的指针,需要首先将其通过case转换成my_transaction类型,之后就可以根据rsp的值来决定后续sequencer的行为。
6.7.4 rep和req类型不同
以上例子中response与req都是相同的情况,UVM也支持response与req类型不同的情况。driver,sequencer,sequence的原型分别是:
class uvm_driver #(type REQ=uvm_sequence_item, type RSP=REQ) extends uvm_component;
class uvm_sequencer #(type REQ=uvm_sequence_item, RSP=REQ) extends uvm_sequencer_param_base #(REQ, RSP);
virtual class uvm_sequence #(type REQ = uvm_sequence_item, type RSP = REQ) extends uvm_sequence_base;
默认情况下response与req的类型是相同的,如果要使用rsp与req不同的情况,需要在定义driver,sequencer,sequence在定义时都要传入两个参数。
6.8 sequence library
6.8.1 随机选择sequence
sequence library:一系列sequence的集合。sequence_library类的原型为:
class uvm_sequence_library #(type REQ=uvm_sequence_item, RSP=REQ) extends uvm_sequence #(REQ, RSP);
sequence library派生自uvm_sequence,本质上说他是一个sequence,它根据特定的算法随机选择注册在其中的一些sequence,并在body中执行这些sequence。
定义一个sequence library:
class simple_seq_library extends uvm_sequence_library#(my_transaction);
function new(string name= "simple_seq_library");
super.new(name);
init_sequence_library();
endfunction
`uvm_object_utils(simple_seq_library)
`uvm_sequence_library_utils(simple_seq_library);
endclass
定义sequence library时要注意:
- 从uvm_sequence派生时要指明此sequence library所产生的transaction类型
- 在其new函数要调用init_sequence_library,否则其内部的候选sequence队列是空的。
- 调用uvm_sequence_library_utils注册。
一个sequence library在定义后,如果没有其他任何的sequence注册到其中,是没有任何意义的。使用uvm_add_to_seq_lib宏将sequence加入某个sequence library中。uvm_add_to_seq_lib有两个参数,第一个是此sequence的名字,第二个是要加入sequence library的名字。一个sequence可以加入多个不同的sequence library中。
class seq0 extends uvm_sequence#(my_transaction);
…
`uvm_object_utils(seq0)
`uvm_add_to_seq_lib(seq0, simple_seq_library)
virtual task body();
repeat(10)
begin
`uvm_do(req)
`uvm_info("seq0", "this is seq0", UVM_MEDIUM)
end
endtask
endclass
当sequence与sequence library定义好后,可以将sequence library作为sequencer的default sequence。
function void my_case0::build_phase(uvm_phase phase);
super.build_phase(phase);
uvm_config_db#(uvm_object_wrapper)::set(this,
"env.i_agt.sqr.main_phase",
"default_sequence",
simple_seq_library::type_id::get()
);
endfunction
执行上述代码后,UVM会随机从加入simple_seq_library中的sequence中选择几个并顺序启动他们。
6.8.2 控制选择算法
上节中,sequence library随机从其sequence队列中选择几个执行,这是由变量selection_mode决定的。selection_mode是一个枚举类型,一共有四个值:
typedef enum
{
UVM_SEQ_LIB_RAND, //完全随机
UVM_SEQ_LIB_RANDC, //周期随机
UVM_SEQ_LIB_ITEM, //自己产生transaction,不执行其sequence队列中的sequence
UVM_SEQ_LIB_USER //用户自定义的算法,需要用户重载select_sequence函数
} uvm_sequence_lib_mode;
设置selection_mode的数值:
function void my_case0::build_phase(uvm_phase phase);
…
uvm_config_db#(uvm_sequence_lib_mode)::set(this,
"env.i_agt.sqr.main_phase",
"default_sequence.selection_mode",
UVM_SEQ_LIB_RANDC);
endfunction
重载select_sequecne函数:
class simple_seq_library extends uvm_sequence_library#(my_transaction);
...
virtual function int unsigned select_sequence(int unsigned max);
static int unsigned index[$];
static bit inited;
int value;
if(!inited)
begin
for(int i = 0; i <= max; i++)
begin
if((sequences[i].get_type_name() == "seq0") || (sequences[i].get_type_name() == "seq1") || (sequences[i].get_type_name() == "seq3"))
index.push_back(i);
end
inited = 1;
end
value = $urandom_range(0, index.size() - 1);
return index[value];
endfunction
endclass
select_sequence会传入一个max,select_sequence函数必须返回一个介于0~max之间的数值。如果sequences队列的大小为 4,那么传入的max数值应该是3而不是4。
6.8.3 控制执行次数
sequence library会在min_random_count和max_random_count之间随意选择一个树来作为执行次数。可以通过设定这两个值来改变迭代次数。
uvm_config_db#(int unsigned)::set(this,
"env.i_agt.sqr.main_phase",
"default_sequence.min_random_count",
5);
uvm_config_db#(int unsigned)::set(this,
"env.i_agt.sqr.main_phase",
"default_sequence.max_random_count",
20);
6.8.4 使用sequence_library_cfg
UVM中提供了一个类uvm_sequence_library_cfg来对sequence library进行配置。它一共有三个成员变量:
class uvm_sequence_library_cfg extends uvm_object;
`uvm_object_utils(uvm_sequence_library_cfg)
uvm_sequence_lib_mode selection_mode;
int unsigned min_random_count;
int unsigned max_random_count;
…
endclass
通过配置上述三个变量,并将其传递给sequence library就可对sequence library进行配置。
function void my_case0::build_phase(uvm_phase phase);
uvm_sequence_library_cfg cfg;
super.build_phase(phase);
cfg = new("cfg", UVM_SEQ_LIB_RANDC, 5, 20);
uvm_config_db#(uvm_object_wrapper)::set(this,
"env.i_agt.sqr.main_phase",
"default_sequence",
simple_seq_library::type_id::get());
uvm_config_db#(uvm_sequence_library_cfg)::set(this,
"env.i_agt.sqr.main_phase",
"default_sequence.config",
cfg);
endfunction
除了使用专门的cfg外,还可以使用在build_phase中直接对lib中变量进行赋值来配置lib变量。
function void my_case0::build_phase(uvm_phase phase);
simple_seq_library seq_lib;
super.build_phase(phase);
seq_lib = new("seq_lib");
seq_lib.selection_mode = UVM_SEQ_LIB_RANDC;
seq_lib.min_random_count = 10;
seq_lib.max_random_count = 15;
uvm_config_db#(uvm_sequence_base)::set(this,
"env.i_agt.sqr.main_phase",
"default_sequence",
seq_lib);
endfunction
6.9 default sequence,m_sequencer及p_sequencer的对比及使用场景
- default sequence:启动sequence的一种方式。UVM中启动sequence有两种方式:一种是将sequence设置(通常在uvm_test类中使用config_db进行设置)为验证平台中的某个seqr的main_phase的default sequence,在验证平台运行到此seqr的main_phase时,发现该phase有default sequence,那么会自动执行该sequence中的body任务;另外一种是调用sequence的start函数,直接启动。
- m_sequencer:属于每个sequence的成员变量,保存的数值是sequence启动时的sequencer的指针。m_seuqencer的数据类型是uvm_sequencer_base(uvm_sequencer的基类)类型,不能直接访问其启动sequencer的成员变量和方法,需要使用cast强制转换符向下转换为实际sequencer的类型才可以访问sequencer中的变量/方法。
- p_sequencer:需要在uvm_seqeunce中使用uvm_declare_p_seqeunce宏进行声明,sequence才有p_sequencer变量。p_sequencer为指向宏声明时指定sequencer的指针,可以通过p_sequencer指针直接访问sequencer中的变量/函数(效果类似m_sequencer,但是与m_sequencer类型不同)。通常用法是,在virtual_sequence使用此宏声明irtual_sequencer(此virtual_sequencer中包含验证平台的多个sequencer),这样就可以在virtual中使用uvm_do_on宏通过p_sequencer.xxx指定此sequence实际启动的sequencer。
参考文献:
UVM实战(卷Ⅰ)张强 编著 机械工业出版社