参考:
- 计组复习:cache,虚拟内存,页表与TLB
- 小林coding - 为什么要有虚拟内存?
一、为什么进程切换比线程切换代价大,效率更低?
首先,先给出标题的答案(关键在于进程切换涉及到TLB的失效及更新,线程不涉及):
因为,每次进程切换时,都会涉及页表的切换,不过切换页表这个操作本身是不太耗费时间的。但是在切换之后,TLB(页表缓存/快表)就失效了,所以在进行地址转化时就需要重新去查找页表,这就造成了程序运行的效率低下。
而同一个进程的线程之间是共用一个页表的,所以线程之间的切换是不需要切换页表的,因此线程切换不存在上述代价大,效率低的问题。
其次,再来了解下几个基本概念:
- 虚拟内存技术:提供一种虚拟地址到实际物理地址的映射,将连续的虚拟地址暴露给程序,而实际上他们在物理内存(比如内存条)上面是不连续的。
虚拟内存能够很好的帮助程序员避免麻烦的内存管理与冲突等问题,并且将内存作为模块化独立出来。 - 虚拟内存地址:程序所使用的内存地址(Virtual Memory Address)。
- 物理内存地址:实际存在硬件里面的空间地址叫(Physical Memory Address)。
二、内存分页与页表
-
内存分页:是把整个虚拟内存和物理内存空间切成一段段固定大小的尺寸。这样一个连续并且尺寸固定的内存空间叫做页(Page)。
在 Linux 下,页是访问内存的最小单位,每一页大小为 4KB。 -
页表:记录【进程 虚拟地址】与【内存 物理地址】的映射关系。
每个进程都拥有自己的虚拟地址空间,也拥有一个页表。
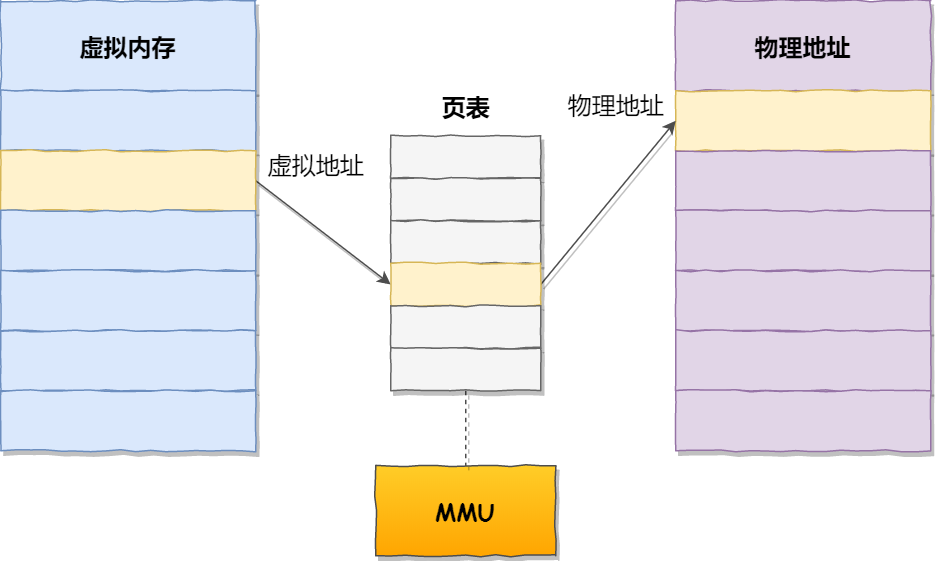
如果程序要访问虚拟地址时,由操作系统转换成不同的物理地址,这样不同的进程在运行时,写入的是不同的物理地址,这样就不会冲突了。
页表是存储在内存里的,而CPU芯片中的 内存管理单元 (MMU)就负责将虚拟内存地址转换成物理地址的工作。
而当进程访问的虚拟地址在页表中查不到时,系统会产生一个缺页异常,进入系统内核空间分配物理内存、更新进程页表,最后再返回用户空间,恢复进程的运行。
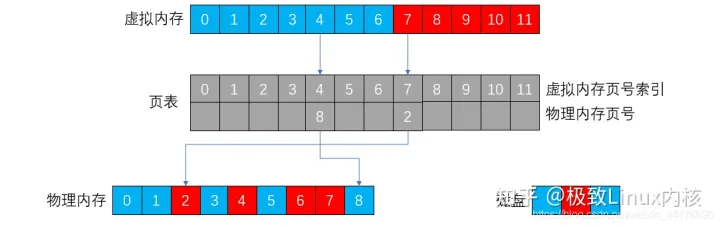
页表使用虚拟地址的页号作为索引,以找到实际物理存储器中的页号,即:key = 虚拟地址的页号, val = 实际物理存储器中的页号。索引的过程如下图:
首先引入 cache 高速缓存,来缓解高速的 cpu 和较低速的内存之间的拖带关系(cpu 速度远快于内存,那么每次读取数据都需要等待内存就绪)。
三、TLB(页表缓存/快表)
大家都知道, 计算机中的cpu的处理速度是要远快于内存操作的,那么每次cpu要读取数据时都需要等待内存就绪才行,这在一定程度上限制了cpu的执行效率。
于是计算机科学家们根据局部性原理,就在 CPU 芯片中加入了一个专门存放程序最常访问页表项的 Cache 高速缓存,这个 Cache 就是 TLB(Translation Lookaside Buffer) ,通常称为 页表缓存、转址旁路缓存、快表等,可以极大提高地址转换速度,加速对于页表的访问。
-
理解:TLB可以看作是一种硬件的哈希表,来快速查找 高速cache 中是否存在特定地址的数据,而其中应用到的内存淘汰策略则是常被提到的LRU内存淘汰策略。
-
作用:可以加速页表读取,极大提高虚拟地址到物理地址的转换速度。
-
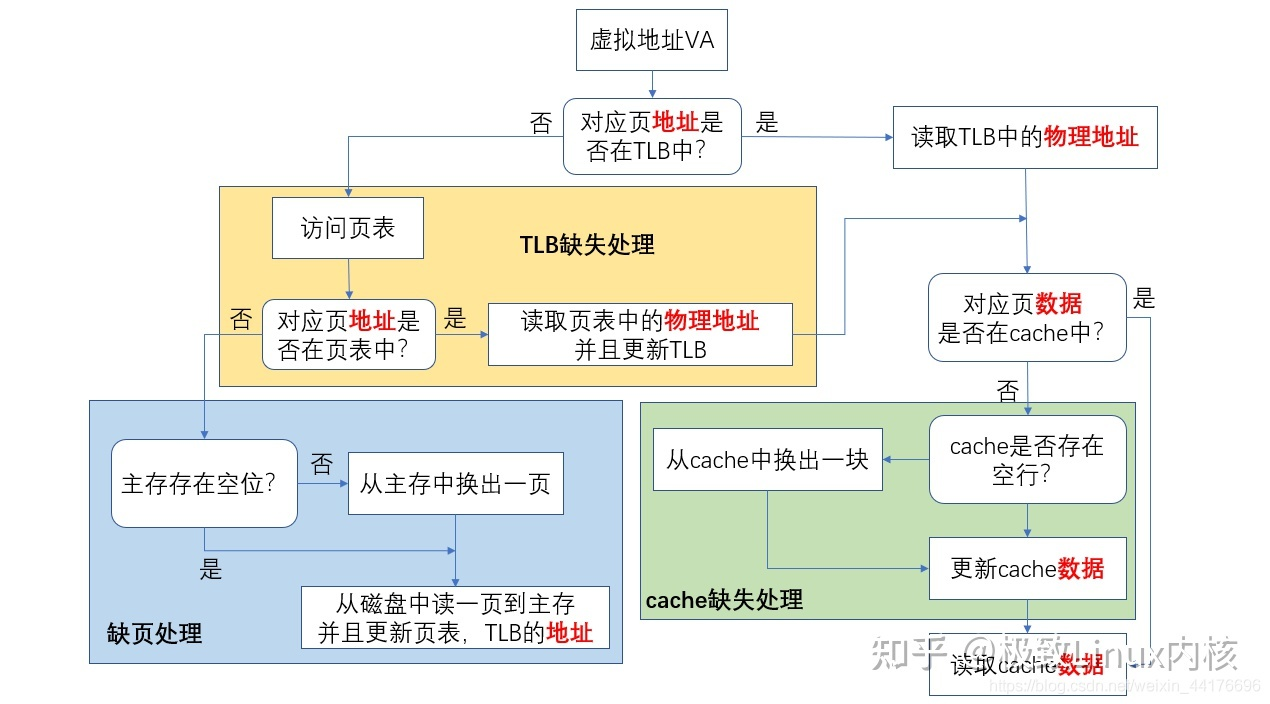
过程:那么对于一次存取,就会有分 3 种的情况:
- TLB hit:命中缓存直接访问内存取数据
- TLB miss:未命中缓存,但是在内存中有对应页 → 【要再去页表中找地址】
- TLB miss:同时内存中没有对应页,发生缺页 → 【要向磁盘要数据,同时更新 TLB 和 页表】
总之,就是先查找 TLB,如果缺失,那么查找页表;还缺就是发生缺页了,需要通过磁盘加载所需数据到物理内存中。如果查找 TLB 命中,那么根据 TLB 获取物理地址,然后查找数据 cache,后续就算普通的 cache 查找了。
加入 TLB 之后,虚拟地址到物理地址的完整地址映射长这样:
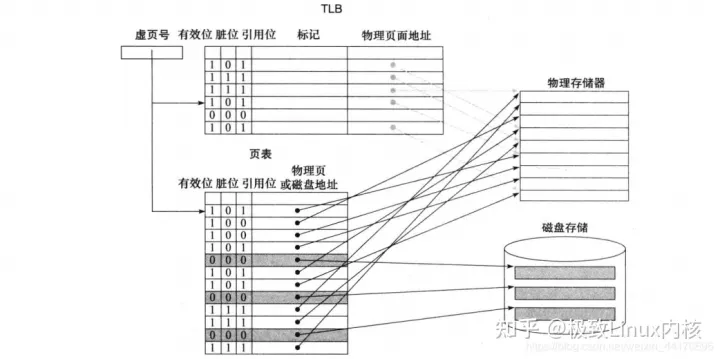
最后,附上一张关于 TLB 的总流程图:
最后再补充一点:
对于一个内存地址是如何转换为实际的物理内存地址的呢? 其实分为 3 个步骤:
- 把虚拟内存地址切分成页号和偏移量
- 根据页号,从页表里面查询对应的物理页号
- 直接拿物理页号加上前面的偏移量,就得到了实际的物理内存地址
四、总结
- 为什么进程切换比线程切换代价大,效率低?
- 关键在于进程切换涉及到TLB的失效及更新,线程不涉及
- 内存分页会把整个虚拟内存和物理内存空间切成一段段尺寸固定大小的页。在 Linux 下,页是访问内存的最小单位,占 4KB。
- 页表记录【虚拟地址空间】与【物理地址空间】的映射关系。
- 为了加速页表的读取,出现了一种存放 程序最常访问页表项的 Cache 高速缓存,称之为TLB,可以极大提高虚拟地址到物理地址的转换速度。