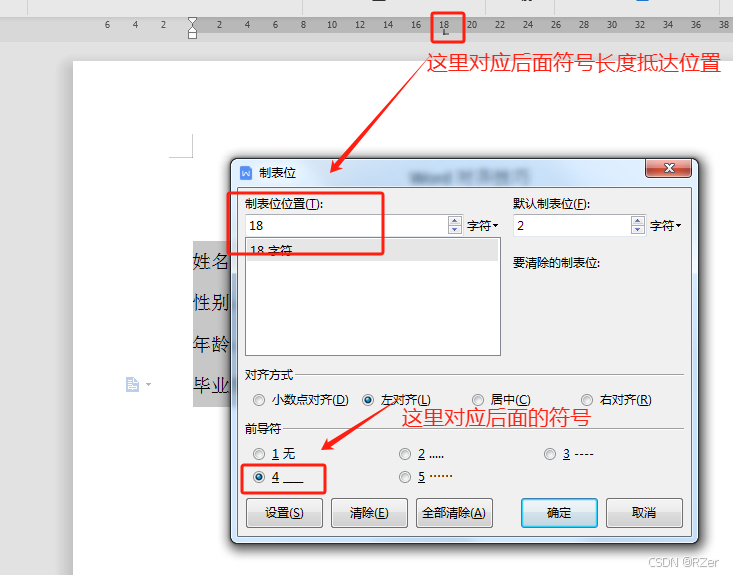
发表时间:NIPS2017
论文链接:https://readpaper.com/pdf-annotate/note?pdfId=4557560538297540609¬eId=2424799047081637376
作者单位:Berkeley AI Research Lab, Work done while at OpenAI Yan Duan†§ , Marcin Andrychowicz ‡ , Bradly Stadie†‡ , Jonathan Ho†§ , Jonas Schneider‡ , Ilya Sutskever‡ , Pieter Abbeel†§ , Wojciech Zaremba‡
Motivation:模仿学习通常用于孤立地解决不同的任务。这通常需要仔细的特征工程,或者需要大量的样本。这远非我们希望:理想情况下,机器人应该能够从任何给定任务的极少数演示中学习,并立即推广到同一任务的新情况,而不需要特定于任务的工程。
-
(a)之前的方法都是针对特定的方法有不同的policy.
-
(b)本文想学习一个通用的policy,并通过当前任务的single demonstration,适用于不同的任务。
-
(c)训练的时候是使用的同一任务的两个demonstration,先学一个,然后再去预测第二个demonstration的action,利用第二个demonstration的action的ground truth去进行有监督的学习(即元学习训练方法)
解决方法:在本文中,我们提出了一个元学习框架来实现这种能力,我们称之为one-shot模仿学习。
具体来说,我们考虑任务集非常大(可能是无限的)的设置,每个任务都有许多实例化。例如,一个任务可能是将桌子上的所有块堆叠成一个塔,另一个任务是将桌子上的所有块放入两块塔等。在每种情况下,任务的不同实例将由具有不同初始状态的不同块集组成。
-
在训练时,我们的算法会看到所有任务的子集的演示对。训练神经网络,以便在将第一个演示和从第二个演示中采样的状态作为输入时,它应该预测与采样状态相对应的动作。训练时候,也是一对样本pairs of demonstrations。训练时候同一任务的两个demonstrations作为输入去有监督的训练网络。(实际上并不是pairs of demonstrations,而是一个demonstration+很多个observation-action pairs)。
-
在测试时,输入新任务的单个实例的完整演示和当前观察,神经网络有望在这个新任务的新实例上表现良好。因为训练的时候就是这么训练的,看一遍演示,就进行动作的学习(这就是元学习)。 测试的时候输入包括一个新任务的成功的demonstrations和当前新任务的观察。然后预测当前任务。所以one-shot Imitation Learning实际上是体现在测试上,训练的时候同一任务的两个demonstrations都是有action作为监督的。
实现方式:
数据收集:我们首先为每个任务收集一组演示,我们将噪声添加到动作中,以便在轨迹空间中更广泛地覆盖。在每个训练迭代中,我们对一系列任务(带有替换)进行采样。对于每个采样任务,我们对演示以及小批量观察-动作对进行采样。该策略经过训练,可以根据当前观察和演示为条件,通过最小化基于动作是连续的还是离散的 l2损失 或交叉熵损失来回归所需的动作(若是离散的动作空间就是分类问题,要是连续的动作空间就是回归问题)。
也就是说实际训练的过程,对于 each sampled task, we sample a demonstration as well as a small batch of observation-action pairs。并不需要两个完整的demonstration。
模型结构:(是有一定的合理性的)
-
Demonstration Network:演示网络接收演示轨迹作为输入,并生成策略使用演示的嵌入。这种嵌入的大小随着演示的长度以及环境中块的数量的函数线性增长。 Temporal Dropout:randomly discard a subset of time steps during training, Neighborhood Attention:由于我们的神经网络需要处理可变数量的块的演示,它必须具有可以处理可变维度输入的模块。Soft attention是一种自然操作,它将变量维输入映射到固定维输出。因此,我们需要一个操作,可以将变量维输入映射到具有可比维度的输出(将变化的维度映射成一个固定的维度)。 直观地说,我们不是由于关注所有输入而使用单个输出,而是将尽可能多的输出作为输入,并且每个输出都关注与它自己的相应输入相关的所有其他输入。 Note that the output has the same dimension as a memory vector。
-
Context network:上下文网络是我们模型的关键。它处理演示网络产生的当前状态和嵌入,并输出上下文嵌入,其维度不依赖于演示的长度,或环境中的块数量。因此,它被迫只捕获相关信息,这些信息将被操作网络使用。 Attention over demonstration:上下文网络首先计算query向量作为当前状态的函数,然后用于关注演示嵌入中的不同时间步长。produce a single weight per time step(是一个向量),这种时间注意的结果是一个向量,其大小与环境中的blocks数量成正比(每个blocks可以理解为每个帧的特征)。 Attention over current state :前面的操作生成一个embedding,其大小与演示的长度无关,但仍然依赖于块的数量。然后,我们对当前状态应用标准软注意力来生成固定维向量,其中memory内容仅由每个块的位置组成,连同机器人的状态,形成上下文嵌入,然后将其传递给操作网络。 直观地说,尽管环境中的对象数量可能会有所不同,但在操作操作的每个阶段,相关对象的数量很小,通常是固定的。具体来说,对于块堆叠环境,机器人只需要关注它试图拾取的块的位置(源块),以及它试图在(目标块)之上放置的块的位置。因此,经过适当训练的网络可以学习将当前状态与演示中的相应阶段进行匹配,并推断源块和目标块的身份,表示为不同块上的软注意力权重,然后用于提取相应的位置传递给操作网络。
-
Manipulation network:操作网络是最简单的组件。在提取源块和目标块的信息后,使用简单的 MLP 网络计算完成在另一个块之上堆叠一个块的当前阶段所需的动作(MLP输出动作)。
实验:没说具体的模拟环境是什么,只说明了任务的形式。
We evaluate the policy on tasks seen during training, as well as tasks unseen during training. Concretely, we collect 140 training tasks, and 43 test tasks,The number of blocks in each task can vary between 2 and 10。
The particle reaching problem is a very simple family of tasks. In fact, even our scripted policy frequently fails on the hardest tasks。(只能做简单的任务)
The robot is a point mass controlled with 2-dimensional force.
结论:与语言相比,使用演示有两个基本优势:首先,它不需要语言知识,因为可以将复杂的任务传达给不说一种语言的人。其次,有很多任务很难用词来解释,即使我们假设完美的语言能力:例如,解释如何在没有演示和经验的情况下游泳似乎至少是一项极具挑战性的任务。
未来:我们计划以图像数据的形式将框架扩展到演示,这将允许更多的端到端学习,而不需要单独的感知模块。