ANSI字符和Unicode字符
在Visual C++中,用CHAR来表示8位ANSI字符,用WCHAR来表示16位Unicode字符(宽字符)
1 typedef char CHAR 2 typedef wchar_t WCHAR
一般常用的定义如下
| Typedef | Definition |
|---|---|
| CHAR | char |
| PSTR or LPSTR | char* |
| PCSTR or LPCSTR | const char* |
| PWSTR or LPWSTR | wchar_t* |
| PCWSTR or LPCWSTR | const wchar_t* |
声明ANSI字符和字符串的方法如下:
1 char c = 'H'; 2 char szBuffer[100] = "Hello World"; 3 char *str = "Hello";
声明Unicode字符和字符串的方法如下:
1 wchar_t c = L'H'; 2 wchar_t szBuffer[100] = L"Hello World"; 3 wchar_t *str = L"Hello";
Windows中的ANSI和Unicode函数
在最初的Windows操作系统中,不支持Unicode字符,只有ANSI。
当引入Unicode后,通过提供两组并行api来简化转换,一组用于ANSI字符串,另一组用于Unicode字符串。
函数后面带A的使用ANSI字符,如
1 BOOL CreateDirectoryA( 2 LPCSTR lpPathName, 3 LPSECURITY_ATTRIBUTES lpSecurityAttributes 4 );
函数后面带W的使用Unicode字符,如
1 BOOL CreateDirectoryW( 2 LPCWSTR lpPathName, 3 LPSECURITY_ATTRIBUTES lpSecurityAttributes 4 );
在内部,ANSI版本的函数会将字符串转换成Unicode。
Windows头文件还定义了一个宏,该宏在定义预处理器符号Unicode时解析为Unicode版本,否则解析为ANSI版本。
1 #ifdef UNICODE 2 #define CreateDirectory CreateDirectoryW 3 #else 4 #define CreateDirectory CreateDirectoryA 5 #endif // !UNICODE
推荐使用Unicode字符集,Unicode字符集支持的字符更多,就不用担心区域化时,字符显示乱码的问题。 在新版本的API函数中,也将会只有Unicode的版本,而没有ANSI版本。
TCHAR和TEXT宏
为了更方便的使用Unicode和ANSI字符,系统还定义了如下宏
| Macro | Unicode | ANSI |
|---|---|---|
| TCHAR | wchar_t | char |
| TEXT("x") | L"x" | "x" |
如
1 SetWindowText(TEXT("My Application"));
会解析成
1 SetWindowTextW(L"My Application"); // Unicode
2 SetWindowTextA("My Application"); // ANSI
需要注意的是,有些头文件会使用预处理器符号UNICODE,而有些头文件使用_UNICODE,所以在Visual Studio 创建项目时,这两个符号都会被定义
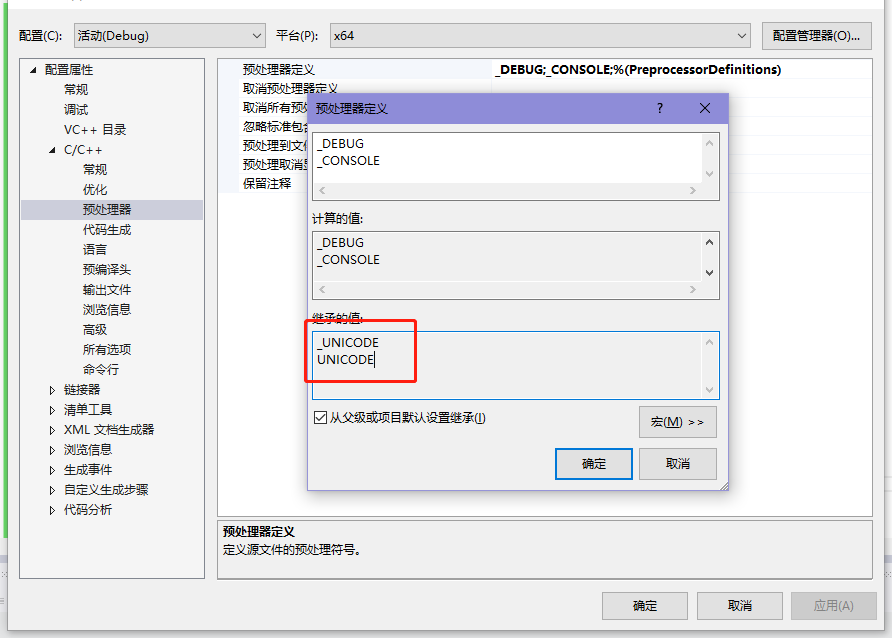
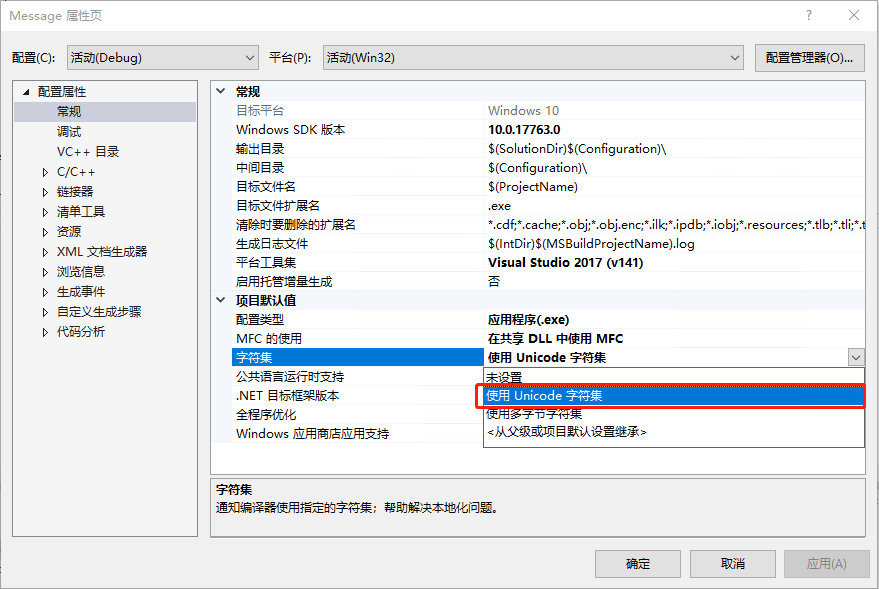
如果需要修改当前默认字符集,可以在属性页修改
C运行库的中的Unicode函数和ANSI函数
针对不同的字符版本,微软的C运行时库也定义了许多相似的宏,用于区分Unicode和ANSI,如
1 #ifdef _UNICODE 2 #define _tcslen wcslen 3 #else 4 #define _tcslen strlen 5 #endif
1 #ifdef _UNICODE 2 #define _tcscpy wcscpy 3 #else 4 #define _tcscpy strcpy 5 #endif
ANSI字符与Unicode字符互相转换的方法
Whttps://www.cnblogs.com/zhaotianff/p/12733569.html