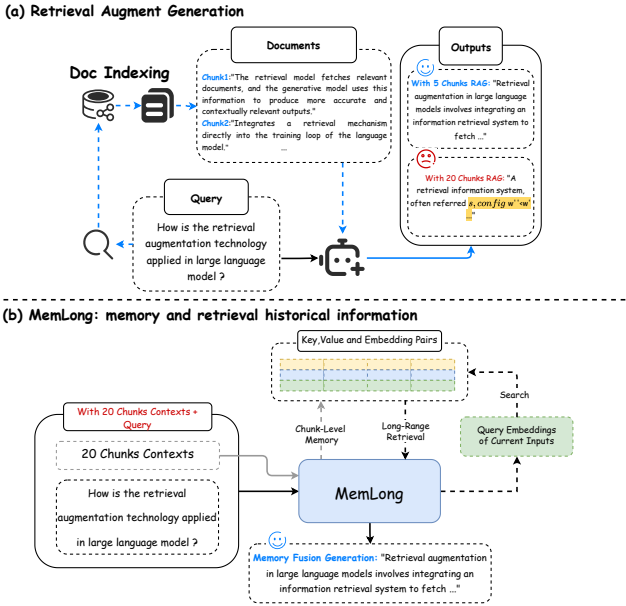
 这篇文章介绍了一个名为MemLong的模型,它通过使用外部检索器来增强长文本建模的能力。MemLong结合了一个不可微的检索-记忆模块和一个部分可训练的解码器-仅语言模型,并引入了一种细粒度、可控的检索注意力机制,利用语义级别的相关块。在多个长文本建模基准测试上的综合评估表明,MemLong在性能上一致超越了其他最先进的大型语言模型。更重要的是,MemLong能够在单个3090 GPU上将上下文长度从4k扩展到80k。
这篇文章介绍了一个名为MemLong的模型,它通过使用外部检索器来增强长文本建模的能力。MemLong结合了一个不可微的检索-记忆模块和一个部分可训练的解码器-仅语言模型,并引入了一种细粒度、可控的检索注意力机制,利用语义级别的相关块。在多个长文本建模基准测试上的综合评估表明,MemLong在性能上一致超越了其他最先进的大型语言模型。更重要的是,MemLong能够在单个3090 GPU上将上下文长度从4k扩展到80k。
论文:MemLong: Memory-Augmented Retrieval for Long Text Modeling
地址:https://arxiv.org/pdf/2408.16967

研究背景
研究问题:这篇文章要解决的问题是大型语言模型(LLMs)在处理长文本时面临的挑战,特别是由于注意力机制的二次时间和空间复杂度以及生成过程中关键值缓存的内存消耗不断增加。
研究难点:该问题的研究难点包括:如何在不显著增加计算复杂度的情况下扩展上下文长度,以及如何避免在存储信息时出现分布偏移。
相关工作:该问题的研究相关工作有:
稀疏注意力操作(Beltagy et al., 2020; Wang et al., 2020; Kitaev et al., 2020; Xiao et al., 2023a; Chen et al., 2023b; Lu et al., 2024)
记忆选择方法(Dai et al., 2019; Bertsch et al., 2024; Yu et al., 2023)
检索增强语言建模(Wu et al., 2022; Wang et al., 2024b; Rubin and Berant, 2023)
研究方法
这篇论文提出了MemLong,一种用于长文本生成的方法,通过使用外部检索器检索历史信息来增强长上下文语言建模的能力。具体来说,
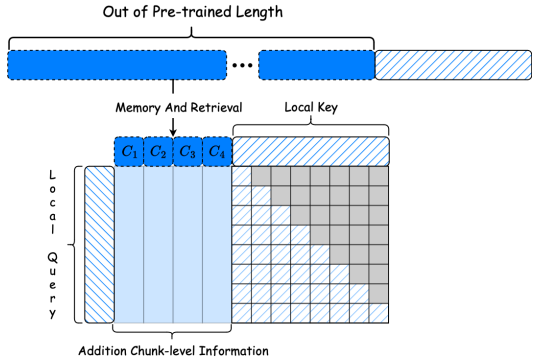
Ret-Mem模块:MemLong结合了不可微分的记忆模块和部分可训练的解码器语言模型,并引入了一种细粒度的、可控的检索注意力机制,利用语义相关的块。
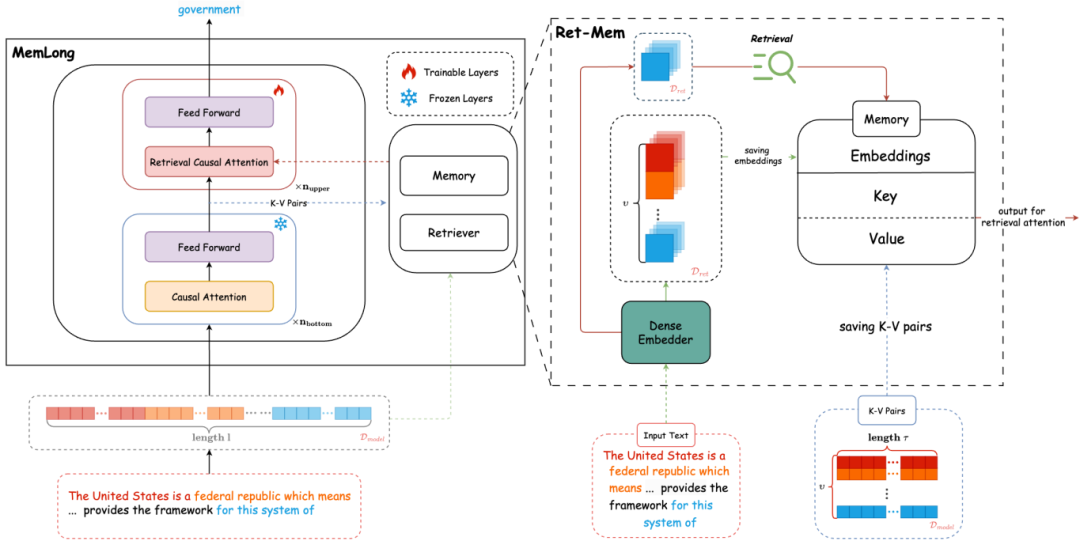
检索过程:给定一个文本块,首先通过检索器获取相关的键值对(K-V对),然后将这些K-V对与当前输入上下文结合,调整模型参数以校准检索参考。
动态内存管理:当内存溢出时,使用计数器智能更新内存,保留最新、最相关的信息,丢弃最旧的和不经常访问的信息。
注意力重构:在模型的可训练上层,修订了注意力机制以融合长期记忆,提出了一种检索因果注意力机制,使每个标记能够同时关注局部上下文和块级别的过去上下文。
实验设计
数据集:评估MemLong在各种需要内存中长上下文处理的任务上的表现,包括长上下文语言建模和检索增强语言建模。使用的数据集包括英语书籍PG-19和BookCorpus、维基百科文章Wikitext-103和数学论文Proof-Pile。
模型配置:使用OpenLLaMA-3B作为预训练主干LLM,采用LoRA技术进行训练。训练MemLong的可训练参数从第14层到第26层,使用slimpajama数据集进行训练。
位置重映射:由于检索的不确定性,需要对位置嵌入进行重映射。局部上下文(最多2048个标记)接收标准的旋转位置编码,而记忆键被编码为在局部上下文窗口中的位置0。
结果与分析
长上下文语言建模:在PG-19、Proof-Pile、BookCorpus和Wikitext-103数据集上的滑动窗口困惑度(PPL)结果表明,MemLong在所有数据集上均显著降低了困惑度。与全量微调模型相比,MemLong在测试长度超过预训练限制时仍能继续降低困惑度。
上下文学习:在5个自然语言理解(NLU)任务(SST-2、MR、Subj、SST-5、MPQA)上的4次和20次演示实验结果表明,MemLong在大多数数据集上优于LongLLaMA,且训练参数和微调数据量显著减少。
总体结论
这篇论文提出的MemLong通过利用外部检索器显著增强了语言模型处理长文本的能力。MemLong成功将模型的上下文窗口从2k扩展到80k标记,并在长距离文本建模和理解任务中表现出显著的竞争优势。与全上下文模型相比,MemLong的性能提升了高达10.4个百分点。未来的研究方向包括将该方法应用于不同大小的模型,以及研究更广泛的检索器。
AI辅助人工完成。
备注:昵称-学校/公司-方向/会议(eg.ACL),进入技术/投稿群

id:DLNLPer,记得备注呦