性能分析
模型训练优化流程

-
我们根据性能问题的场景,按照单机和集群场景进行分类,再明确性能问题属于哪一类,明确好性能问题背景之后,才方便进行下一步问题的定位;
-
在明确问题背景后,参考性能分析工具介绍,选择对应的性能工具,采集性能数据并拆解性能,找到需要提升性能的模块;
-
在明确性能瓶颈模块后,将问题细化定位到下发、计算和通信等模块,并通过本文目录搜索到对应章节找到对应优化算法。
通用优化方法
1.并行策略
- 在面临显存不足、模型过大无法完全加载以及需要进行切分的情况下,优先考虑使用TP(Tensor Parallelism)进行切分,并确保切分的数量小于等于机器内的计算卡数。例如,在一台服务器上有8张计算卡,那么TP的最大设置不应超过8。这样可以充分利用计算资源,减少显存占用。
- 如果在TP切分达到最大显存容量仍然不足的情况下,可以考虑在机器之间使用PP(Pipeline Parallelism)进行切分。理论上,PP的数量应该越小越好,以尽可能减少空闲计算资源的浪费。
- 在机器资源富裕的情况下,可以开启DP(Data Parallelism)并行,将计算任务分配给多个机器进行并行处理,从而提高处理效率。然而,在机器资源有限的情况下,如果开启TP+PP切分后显存仍然不足,可以考虑使用ZeRO1和重计算技术。ZeRO1可以将模型优化器状态划分到更多的设备上,并通过集合通信进行同步。同时,重计算技术可以通过选择性重计算来提高显存的使用率,从而提高模型训练效率。
- 此外,即使在模型能够成功运行的情况下,也可以尝试主动地使用降低内存占用的手段,例如ZeRO1和重计算等,然后增大Batch Size。这样有时也会取得令人意外的效果。
总结:
并行策略一般是通过不断调整TP、PP、DP、及内存优化技术ZeRO1和重计算等参数来尝试提升性能;
2.IO优化(数据加载优化)
在PyTorch模型中,数据加载部分的逻辑一般是DataLoader及其衍生类,在DataLoader加载数据中,要注意以下两个核心点:
- 第一个是数据加载的预处理部分,数据的预处理通常会写在datasets里,数据的预处理包括对文本、图片、视频和语音等不同格式数据的处理,数据预处理耗时长是比较容易识别出来的,一般通过打点计时。
- 第二个就是要确定好数据读取的方式,一般而言,每张卡都去读取数据是比较理想的,如果存在0卡读取,广播给其他卡的数据读取形式,要关注其性能如何,很多时候都会让模型性能严重劣化。
硬件类
- 检查数据存放的硬盘,最好在NVME(Non-Volatile Memory Express,一种更快、更可靠的存储设备,适合存储需要高速读写的数据)盘上,当硬盘为共享存储时,需要注意IO瓶颈。
- 检查NUMA(Non-Uniform Memory Access,非一致性内存访问)数量,可以通过lscpu命令查看,一般需要NUMA数量为4或者8。
参数类
DataLoader入参:
- 在内存允许的情况下,保持pin_memory=True,在PyTorch中,该参数可以写为pin_memory_device。
- 一般而言,可以加上persistent_workers=True,该设置可以减小进程销毁或申请的开销,不过这个方法也可能带来内存瓶颈。
代码技巧类
-
在数据预处理时间较长而影响模型训练时,可以尝试预取数据,即Data prefetcher。
-
Infinite DataLoader同样可以缓解epoch间加载缓慢的问题。
-
提前缓存数据或制作二进制数据,轻量化数据加载,若原始数据是压缩或编码格式,则会引发解压缩或解码,加重CPU负载,容易引起host bound问题,建议提前处理成二进制格式,快速进行数据读取。
-
对于NPU预处理数据比较慢,例如dlrm模型,可以考虑将预处理放到datasets里用CPU多num_workers处理数据。
-
对于句子之间长度差距比较大的句子,组成batch时可以考虑resample一下。对于NLP任务,存在输入的sentence长短不一,tokenize之后需要padding成相同长度才能组成一个batch的情况。对于一些数据集中,所有sentence长度差别很大的情况,如果随机取句子,那么需要补的padding就很多,造成很多冗余的计算量。此时,可以通过调整DataSampler,尽量将长度接近的sentence组成一个batch,这样造成很多冗余的计算量就可以减少很多,训练整体的吞吐量会有显著提升。缺点:可能稍微会影响数据的随机性。
3.NPU亲和适配优化(难度高)
融合算子替换
融合优化器
亲和算子替换
亲和API替换
4.内存优化
PyTorch在内存上基于eager模式实现,eager模式的特点是如果没有必要,不会主动释放已经申请的内存,同时,PyTorch默认模式下是整块申请内存,因此,很容易出现碎片化的内存,而当模型当前内存不足够时,会触发内存重整操作,即将碎片化内存(包括之前申请但并未被表示的内存块)整理,得到大块连续内存。如果重整得到的内存能够满足模型训练需要,那么训练就会进行下去,但是这种内存重整操作需要花费大量时间,频繁触发内存重整操作会对模型性能产生很大影响。因此,本文就内存问题提出一些针对化建议。
调整内存参数
-
设置内存因子,限制进程申请的内存上限,取值0~1。
例如:设置0.95,可使用的内存上限为60G * 0.95 = 57G。
内存申请超过上限触发内存释放。设置PyTorch申请的内存上限,可以避免内存使用极限场景下,PyTorch耗尽Device内存,其他组件申请内存失败导致的进程异常。
torch_npu.npu.set_per_process_memory_fraction(0.95) -
垃圾回收阈值,默认不开启,与内存因子配合使用,取值0~1,为内存上限的百分比。
当内存申请到gc阈值,则触发内存池空闲内存块回收。建议由大到小配置调试。
export PYTORCH_NPU_ALLOC_CONF="garbage_collection_threshold:0.95" -
内存块允许切分上限,单位MB。
例如:设置50,大于等于50M的内存块不允许切分使用。设置该参数可避免大内存块被切分导致较多的内存碎片影响内存复用。调试时可以先采集内存profiling,按照算子内存申请降序排列,参数值由大到小尝试。
export PYTORCH_NPU_ALLOC_CONF="max_split_size_mb:50" -
使能内存池扩展段功能,由PyTorch自己管理虚拟地址与物理地址映射,降低内存碎片。
对于动态shape场景,shape随step增加而增大,从而导致内存块不能复用内存碎片上升,对该场景有较好优化。
export PYTORCH_NPU_ALLOC_CONF="expandable_segments:True"
5.通信优化
HCCL_INTRA_ROCE_ENABLE
Atlas 200T A2 Box16 异构子框进行单server 16P单server业务部署,开启该环境变量后,两个8P之间使用RDMA链路代替SDMA链路作为mesh间互联链路。
配置示例
export HCCL_INTRA_ROCE_ENABLE=1
使用场景
当用户使用设备虚拟化场景或PCIE带宽较低时(如不足20GB/s),建议使用此参数。
HCCL_RDMA_TC
用于配置RDMA网卡的traffic class。8bit无符号整型数据,bit27配置为DSCP值,bit01固定为零;默认值132。
配置示例
# DSCP配置为25
export HCCL_RDMA_TC=100
使用场景
昇腾网卡与交换机QOS(Quality of Service,服务质量)不匹配导致RDMA通信带宽下降时配置。
HCCL_RDMA_SL
用于配置RDMA网卡的service level,该值需要和网卡配置的PFC优先级保持一致,若配置不一致可能导致性能劣化。
取值范围[0,7],默认值4。
配置示例
# 优先级配置为3
export HCCL_RDMA_SL=3
使用场景
昇腾网卡与交换机QOS(Quality of Service,服务质量)不匹配导致RDMA通信带宽下降时配置。
HCCL_BUFFSIZE
此环境变量用于控制两个NPU之间共享数据的缓存区大小。单位为M,取值需要大于等于1,默认值是200M。
集合通信网络中,每一个HCCL通信域都会占用HCCL_BUFFSIZE大小的缓存区。若集群网络中存在较多的HCCL通信域,此缓存区占用量就会增多,可能存在影响模型数据正常存放的风险,此种场景下,可通过此环境变量减少通信域占用的缓存区大小;若业务的模型数据量较小,但通信数据量较大,则可通过此环境变量增大HCCL通信域占用的缓存区大小,提升数据通信效率。
大语言模型(LLM,Large Language Model)中的建议配置值如下,向上取整。
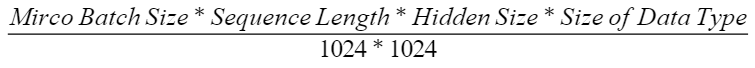
其中Mirco Batch Size为每张卡上的Batch Size,Sequence Length为序列长度,Hidden Size为模型隐藏层的维度,Size of Data Type为当前模型数据类型所占的内存大小。
此环境变量一般用于以下场景:
- 动态shape网络场景
- 开发人员调用集合通信库HCCL的C语言接口进行框架对接的场景,HCCL库的C语言接口可参见《集合通信接口参考》。
配置示例
export HCCL_BUFFSIZE=200
使用场景
当业务部署内存不足时,根据功能描述中的配置策略配置,小于配置策略会导致通信性能下降。
性能分析工具使用
性能对比分析–compare_tools
compare_tools(性能比对工具)支持比较GPU与NPU之间、NPU与NPU之间的性能差异,通过对训练耗时和内存占用的比对分析,定位到具体劣化的算子,帮助用户提升性能调优的效率。工具将训练耗时拆分为计算、通信、调度三大维度,并针对计算和通信分别进行算子级别的比对;将训练占用的总内存,拆分成算子级别的内存占用进行比对。
使用方法
环境依赖
使用本工具前需要安装的依赖包:
pip3 install prettytable
pip3 install xlsxwriter
pip3 install pandas
pip3 install numpy
PyTorch框架性能数据采集
使用本工具之前需要采集GPU或者NPU的性能数据,建议只采集一个step的性能数据,然后进行性能比对分析。
GPU性能数据采集
通过PyTorch Profiler工具采集GPU的性能数据,参考链接:torch.profiler。
详细请见**《chatglm2 性能分析实战》**
PyTorch Profiler采集结果数据目录结构如下:
|- pytorch_profiling
|- *.pt.trace.json
NPU性能数据采集
通过Ascend PyTorch Profiler工具采集NPU的性能数据,采集参数配置与GPU基本一致,只需将GPU的性能数据采集代码中torch.profiler替换成torch_npu.profiler。,参考链接:Profiling数据采集。
Ascend PyTorch Profiler采集结果数据目录结构如下:
|- ascend_pytorch_profiling
|- * _ascend_pt
|- ASCEND_PROFILER_OUTPUT
|- trace_view.json
|- FRAMEWORK
|- PROF_XXX
|- * _ascend_pt
性能数据比对
性能比对工具将总体性能拆解为训练耗时和内存占用,其中训练耗时可拆分为算子(包括算子和nn.Module)、通信、调度三个维度,以打屏的形式输出总体指标,帮助用户定界劣化的方向。与此同时,工具还会生成performance_comparison_result_*.xlsx,展示每个算子在执行耗时、通信耗时、内存占用的优劣,可通过DIFF列大于0筛选出劣化算子。详细介绍请参见“比对结果说明”。
性能比对工具支持使用命令行和脚本两种方式执行性能数据比对操作,这两种方式均支持通用参数和算子性能比对特有参数。
命令行方式
-
参见《性能工具》完成工具安装。
-
执行如下命令进行性能数据比对:
msprof-analyze compare -d [比对性能数据文件所在路径] -bp [基准性能数据文件所在路径] --output_path=[比对结果文件存放路径]- -d(必选):比对性能数据文件所在路径。可以指定以“ascend_pt”结尾的目录、ASCEND_PROFILER_OUTPUT目录或trace_view.json文件,指定trace_view.json无法显示算子的内存占用。
- -bp(必选):基准性能数据文件所在路径。基准性能数据文件若以GPU为基准,指定到以".pt.trace"结尾的json文件;若以NPU不同版本为基准,指定文件与-d一致。
- –output_path(可选):性能比对结果存放的路径,默认保存在当前目录。
脚本方式
将mstt代码仓下载到本地,执行如下命令:
# 进入mstt代码仓目录下的compare_tools目录
cd mstt/profiler/compare_tools
# 执行最简比对命令
python performance_compare.py [基准性能数据文件所在路径] [比对性能数据文件所在路径] --output_path=[比对结果文件存放路径]
- 基准性能数据文件所在路径(必选):若以GPU为基准,指定到以".pt.trace"结尾的json文件;若以NPU不同版本为基准,指定文件参考比对性能数据文件所在路径。
- 比对性能数据文件所在路径(必选):可以指定以“ascend_pt”结尾的目录、ASCEND_PROFILER_OUTPUT目录或trace_view.json文件,指定trace_view.json无法显示算子的内存占用。
- –output_path(可选):性能比对结果存放的路径,默认保存在当前目录。
通用参数说明
| 参数名 | 说明 | 是否必选 |
|---|---|---|
| –enable_profiling_compare | 开启总体性能比对。 | 否 |
| –enable_operator_compare | 开启算子性能比对。MindSpore场景暂不支持。该开关较耗时,建议只采集一个step的性能数据。 | 否 |
| –enable_communication_compare | 开启通信性能比对。 | 否 |
| –enable_memory_compare | 开启算子内存比对。MindSpore场景暂不支持。该开关较耗时,建议只采集一个step的性能数据。 | 否 |
| –enable_kernel_compare | 开启kernel性能比对。仅针对NPU与NPU比对的场景。需要使用性能数据中的kernel_details.csv文件。 | 否 |
| –enable_api_compare | 开启API性能比对。需要使用性能数据中的trace_view.csv文件。 | 否 |
| –disable_details | 隐藏明细比对,只进行统计级比对。 | 否 |
| –base_step | 基准性能数据step ID,配置后使用基准性能数据对应step的数据进行比对。为整数,需配置实际数据存在的step ID,默认未配置,比对所有性能数据,需要与–comparsion_step同时配置。配置示例:–base_step=1。 | 否 |
| 能数据中的trace_view.csv文件。 | 否 | |
| –disable_details | 隐藏明细比对,只进行统计级比对。 | 否 |
| –base_step | 基准性能数据step ID,配置后使用基准性能数据对应step的数据进行比对。为整数,需配置实际数据存在的step ID,默认未配置,比对所有性能数据,需要与–comparsion_step同时配置。配置示例:–base_step=1。 | 否 |
| –comparsion_step | 比对性能数据step ID,配置后使用比对性能数据对应step的数据进行比对。为整数,需配置实际数据存在的step ID,默认未配置,比对所有性能数据,需要与–base_step同时配置。配置示例:–comparsion_step=1。 | 否 |


















