在数据预测领域,传统的统计方法和时间序列分析在面对复杂、非线性的数据时往往力不从心。随着人工智能技术的快速发展,神经网络特别是BP(Back Propagation)神经网络因其强大的非线性映射能力,在预测领域得到了广泛应用。然而,BP神经网络也存在易陷入局部最优、收敛速度慢等问题。为了克服这些缺点,本文将介绍一种基于人工蜂群算法(Artificial Bee Colony Algorithm, ABC)优化BP神经网络的数据预测方法,即ABC-BP模型。
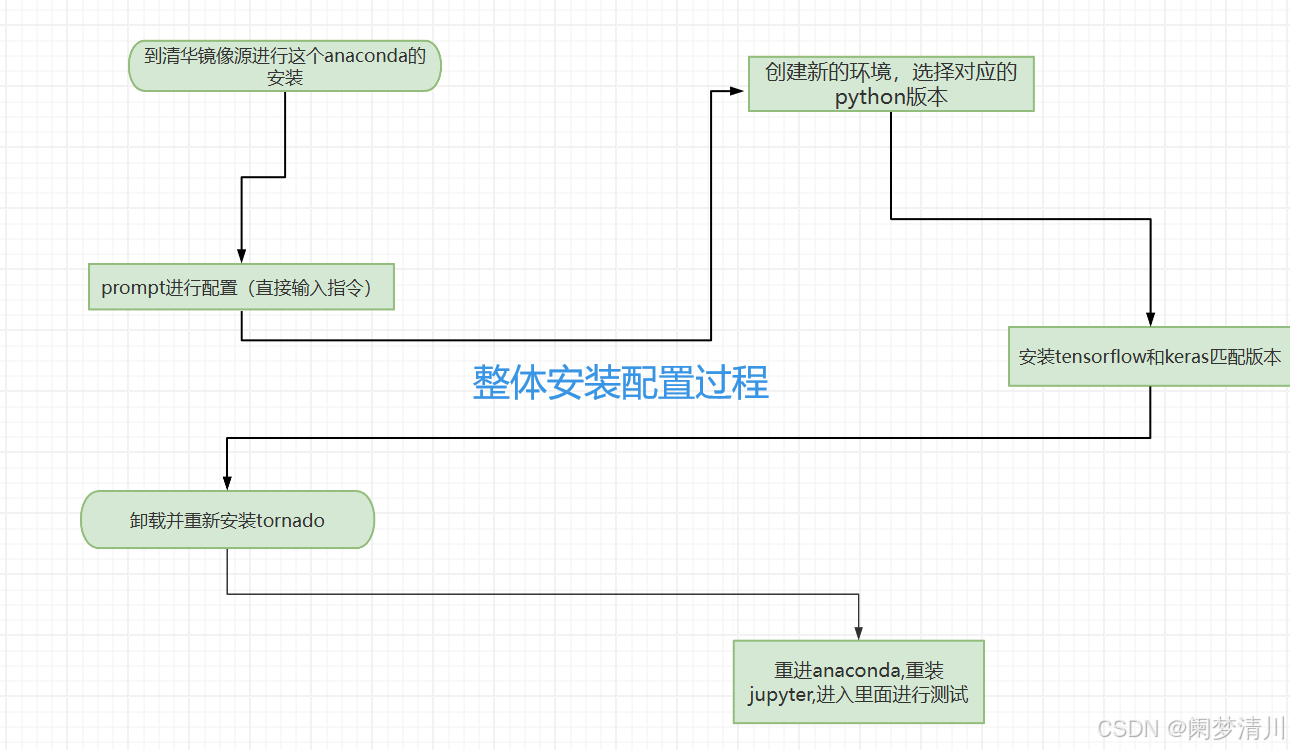
一、ABC-BP算法概述
1.ABC人工蜂群算法
人工蜂群算法是一种受蜜蜂觅食行为启发的群体智能算法。蜜蜂在寻找食物源时,通过侦察蜂、雇佣蜂和跟随蜂的协同工作,实现全局最优解的搜索。ABC算法通过模拟这一过程,实现复杂优化问题的求解。ABC算法主要包括以下步骤:生成一组初始的神经网络权重作为“食物源”位置。蜜蜂(代表神经网络的解决方案)通过评估函数(如分类准确度或预测误差)来搜索最优解。工蜂(其他解决问题的个体)共享它们发现的好食物源,更新整个群体的最佳解。根据工蜂的数量和食物源的质量,采用一定的概率规则选择下一个解决方案。ABC算法具有分布式、并行性和自适应性的特点,能够有效避免局部最优解,提高搜索效率。
2.BP神经网络(BP)
BP神经网络是一种具有三层或三层以上的多层神经网络,包括输入层、隐含层和输出层。每一层都由若干个神经元组成,神经元之间通过加权和的方式传递信号,并经过激活函数进行非线性变换。BP神经网络的训练过程包括前向传播和反向传播两个阶段。在前向传播阶段,输入信号从输入层逐层传递到输出层;在反向传播阶段,根据输出误差调整各层之间的连接权重,使误差逐步减小。
3.SSA算法
SSA算法流程如下:
(1)初始化:确定种群规模(蜜蜂总数)、最大迭代次数、控制参数“limit”(同一蜜源被限定开采的次数)等。随机生成初始蜜源(问题的可行解),并计算每个蜜源的适应度(即蜜量大小)。
(2)引领蜂阶段:每个引领蜂在其对应的蜜源附近进行局部搜索,寻找新的蜜源(即新的解)。计算新蜜源的适应度,并与原蜜源进行比较。如果新蜜源的适应度优于原蜜源,则替换原蜜源;否则,原蜜源的开采次数加1。
(3)跟随蜂阶段:跟随蜂根据引领蜂分享的蜜源信息(通过某种概率机制,如轮盘赌方式)选择合适的蜜源。在选定的蜜源附近进行局部搜索,生成新解并计算其适应度。同样地,根据贪婪选择机制保留较优的解。
(4)侦查蜂阶段:检查每个蜜源的开采次数是否达到“limit”。如果某个蜜源的开采次数超过“limit”,则认为该蜜源已经陷入局部最优,对应的引领蜂转变为侦查蜂。侦查蜂在全局范围内随机生成新的蜜源,替代原来的蜜源,以增加算法跳出局部最优的能力。
(5)记忆最佳蜜源:在每次迭代过程中,记录并更新迄今为止找到的最佳蜜源(即最优解)。
(6)判断终止条件:检查是否达到最大迭代次数或其他预设的终止条件。如果满足终止条件,则输出最佳蜜源作为优化问题的解;否则,返回步骤2继续迭代。
(7)输出结果:输出算法找到的最优解及其适应度值。
二、实验步骤
SSA-BP神经网络回归预测步骤:
1.数据清洗:去除缺失值和异常值。
2.特征选择:根据相关性分析选择对预测结果影响显著的特征。
3.数据归一化:将特征值缩放到同一量纲,提高训练效率。
4.确定BP神经网络结构:首先,根据问题的需求确定BP神经网络的输入层、隐藏层和输出层的节点数,以及隐藏层的层数。
5.初始化BP神经网络参数:随机初始化BP神经网络的权重和偏置。这些参数将作为ABC优化过程中的搜索变量。
6.定义适应度函数:使用训练数据集训练BP神经网络,并计算网络输出与实际输出之间的误差(如均方误差MSE)作为适应度函数。适应度值越小,表示神经网络的预测性能越好。
7.ABC算法优化:利用ABC算法对BP神经网络的权重和阈值进行优化,最小化网络输出与真实值之间的均方误差(MSE)。
8.迭代:重复执行适应度评估、分类和位置更新的过程,直到达到最大迭代次数或满足其他停止条件。
9.输出最优BP神经网络:在SSA优化过程结束后,选择适应度值最小的麻雀(即最优的BP神经网络权重和偏置)作为最终的网络参数。
10.测试与评估:使用测试数据集评估优化后的BP神经网络的预测性能,并与其他优化算法进行比较。
三、代码部分
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import torch
import torch.nn as nn
from sklearn.preprocessing import MinMaxScaler
from sklearn.metrics import mean_squared_error, r2_score, mean_absolute_error
import torch.optim as optim
import matplotlib
# 设备配置
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
matplotlib.rcParams['font.sans-serif'] = ['SimHei']
matplotlib.rcParams['axes.unicode_minus'] = False
# 导入数据
data = pd.read_csv('数据集.csv').values
# 划分训练集和测试集
np.random.seed(0)
temp = np.random.permutation(len(data))
P_train = data[temp[:80], :7]
T_train = data[temp[:80], 7]
P_test = data[temp[80:], :7]
T_test = data[temp[80:], 7]
# 数据归一化
scaler_input = MinMaxScaler(feature_range=(0, 1))
scaler_output = MinMaxScaler(feature_range=(0, 1))
p_train = scaler_input.fit_transform(P_train)
p_test = scaler_input.transform(P_test)
t_train = scaler_output.fit_transform(T_train.reshape(-1, 1)).ravel()
t_test = scaler_output.transform(T_test.reshape(-1, 1)).ravel()
# 转换为 PyTorch 张量
p_train = torch.tensor(p_train, dtype=torch.float32).to(device)
t_train = torch.tensor(t_train, dtype=torch.float32).view(-1, 1).to(device)
p_test = torch.tensor(p_test, dtype=torch.float32).to(device)
t_test = torch.tensor(t_test, dtype=torch.float32).view(-1, 1).to(device)
# 定义神经网络
class NeuralNet(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(NeuralNet, self).__init__()
self.fc1 = nn.Linear(input_size, hidden_size)
self.relu = nn.ReLU()
self.fc2 = nn.Linear(hidden_size, output_size)
def forward(self, x):
out = self.fc1(x)
out = self.relu(out)
out = self.fc2(out)
return out
# 实例化模型
input_size = 7
hidden_size = 14
output_size = 1
model = NeuralNet(input_size, hidden_size, output_size).to(device)
criterion = nn.MSELoss()
class ArtificialBeeColony:
def __init__(self, bee_count, max_iter, limit, search_space, input_size, hidden_size, output_size, device):
self.bee_count = bee_count
self.max_iter = max_iter
self.limit = limit
self.search_space = search_space
self.input_size = input_size
self.hidden_size = hidden_size
self.output_size = output_size
self.device = device
self.network_structure = NeuralNet(self.input_size, self.hidden_size, self.output_size).to(self.device)
self.population = self.initialize_population()
self.fitness = np.zeros(self.bee_count)
self.trial = np.zeros(self.bee_count)
self.best_solution = None
self.best_fitness = float('inf')
def initialize_population(self):
population = []
for _ in range(self.bee_count):
weights_biases = []
for param in self.network_structure.parameters():
weights_biases.append(
torch.rand(param.shape, device=self.device) * (self.search_space[1] - self.search_space[0]) + self.search_space[0])
population.append(weights_biases)
return population
def evaluate_fitness(self, network, data, target):
network.eval() # Ensure the model is in evaluation mode
data = data.to(self.device)
target = target.to(self.device)
with torch.no_grad():
output = network(data)
loss = criterion(output, target)
return loss.item()
四、实验与结果
1.数据集准备
为了验证ABC优化BP神经网络的有效性,本文采用如下数据集进行实验。下面所示本次采用的数据集(部分)。

2.结果分析
实验结果表明,采用基于ABC优化BP神经网络的预测模型与传统BP神经网络模型进行对比分析。实验结果表明,ABC-BP模型在准确率、鲁棒性和收敛速度方面均优于传统BP神经网络模型。
(1) 训练集预测值和真实值对比结果

(2) 测试集预测值和真实值对比结果

(3) 训练集线性回归图

(4) 测试集线性回归图

(5) 其他性能计算和新数据预测

五、结论
本文介绍了基于ABC优化BP神经网络进行数据预测的方法。通过结合ABC的全局搜索能力和BP神经网络的非线性映射能力,可以有效提高模型的预测精度。实际应用中,可根据具体问题调整ABC和BP神经网络的参数,以达到最佳预测效果。