【学习AI-相关路程-工具使用-自我学习-jetson&模型训练-图片识别-使用模型检测图片-基础样例 (5)】
- 1 -前言
- 2 -环境说明
- 3 -先行了解
- (1)整理流程了解
- (2)了解模型-MobileNet
- 1、MobileNetV2 的主要特性:
- 2、MobileNet_V2_Weights.IMAGENET1K_V1 的使用:
- (1)适用场景:
- (2)优点与局限性:
- (3)其他模型了解
- 4 -实验过程
- 1、创建目录结构
- 2、编写训练代码
- 3、训练过程
- 4、使用模型检测
- 5、使用GPU问题
- 6、历史记录
- 5-代码过程
- 1、目录截图
- 2、代码链接
- 6 -细节部分
- (1)获取版本信息
- 1. 验证CUDA和cuDNN是否正常工作
- 2. 验证PyTorch和torchvision安装
- 3. 查看Jetson设备的系统信息
- 4. 查看python版本信息
- (2)查看目录结构
- (3)每个目录下放的什么文件
- (4)报错:ModuleNotFoundError: No module named 'torchvision'
- (5)报错:文件路径没找到&路径拼写错误
- 7 -总结
1 -前言
我们在上一篇,学习了收集图片,以及使用代码对图片进行一定批量出来,那么本章,我们终于可以训练模型了,但对于识别屏幕开关机这样的任务,我自己最后其实没有用那些匹配转换的图片,而是直接用原图片,直接进行训练的。但个人认为 ,实际应用中,处理图片应该是不能省略的。
【学习AI-相关路程-工具使用-自我学习-jetson&收集数据-图片采集-训练前准备-基础样例 (4)】
2 -环境说明
本次环境是在jetson orin NX 上,环境信息如下。

wjl-linux@ubuntu:~$ jetson_release
Software part of jetson-stats 4.2.9 - (c) 2024, Raffaello Bonghi
Model: NVIDIA Orin NX Developer Kit - Jetpack 5.1.2 [L4T 35.4.1]
NV Power Mode[3]: 25W
Serial Number: [XXX Show with: jetson_release -s XXX]
Hardware:
- P-Number: p3767-0000
- Module: NVIDIA Jetson Orin NX (16GB ram)
Platform:
- Distribution: Ubuntu 20.04 Focal Fossa
- Release: 5.10.120-tegra
jtop:
- Version: 4.2.9
- Service: Active
Libraries:
- CUDA: 11.4.315
- cuDNN: 8.6.0.166
- TensorRT: 8.5.2.2
- VPI: 2.3.9
- Vulkan: 1.3.204
- OpenCV: 4.5.4 - with CUDA: NO
wjl-linux@ubuntu:~$ nvcc --version
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2022 NVIDIA Corporation
Built on Sun_Oct_23_22:16:07_PDT_2022
Cuda compilation tools, release 11.4, V11.4.315
Build cuda_11.4.r11.4/compiler.31964100_0
wjl-linux@ubuntu:~$ python3 --version
Python 3.8.10
wjl-linux@ubuntu:~$ python3 -c "import torch; print(torch.__version__)"
2.4.0
3 -先行了解
开始学习的时候,或者说,你在选择可能的模型时,并不知道,自己要选择什么样的模型,本次样例,是先用了模型,后来能出来东西的时候,才去了解模型的,我们其实也是先了解过程,模型大概知道就可以了。
(1)整理流程了解
(1)我们学习AI训练模型的过程中,要大概知道在什么阶段,我们之前完成数据的准备,本次是模型训练,本章我们在阶段4。
- 阶段 1: 硬件设置
- 阶段 2: 软件准备
- 阶段 3: 数据准备
- 阶段 4: 模型设计和训练
- 阶段 5: 优化和部署
- 阶段 6: 应用集成
- 阶段 7: 监控和维护
(2)了解模型-MobileNet
本次使用的模型,在代码里可以看到“MobileNet_V2_Weights.IMAGENET1K_V1”字样。或者自己自考的时候,大致上知道要使用一个分类的模型,即识别出是屏幕是关机还是开机。
MobileNetV2 是一种专为移动设备和嵌入式系统设计的高效卷积神经网络(CNN)架构。它在保持计算效率的同时,能够在图像分类等任务中实现较高的准确性。MobileNetV2 通过引入深度可分离卷积和线性瓶颈单元,大幅减少了模型参数和计算量,非常适合资源受限的设备。
1、MobileNetV2 的主要特性:
-
深度可分离卷积(Depthwise Separable Convolution):
- 这是 MobileNetV2 的核心组件,分为两个步骤:深度卷积(Depthwise Convolution)和逐点卷积(Pointwise Convolution)。
- 深度卷积:在每个输入通道上独立执行卷积操作,从而减少计算量。
- 逐点卷积:通过 1x1 卷积将深度卷积的输出合并在一起,以整合信息。
这种操作与传统卷积相比,大幅降低了计算复杂度和模型参数量,提升了运行速度。
-
线性瓶颈(Linear Bottleneck):
- MobileNetV2 中的每个卷积块都包含一个线性瓶颈层。这个瓶颈层起到压缩特征图的作用,将特征维度从高维(输入)压缩到低维(输出)。
- 通过这个压缩过程,MobileNetV2 能够在保持模型表达能力的同时,进一步减少计算需求。
-
倒残差结构(Inverted Residuals):
- MobileNetV2 引入了倒残差结构,与 ResNet 中的标准残差块不同。倒残差块将输入的低维特征映射到高维,然后再通过瓶颈压缩回低维。这种结构能更有效地捕捉模型中的特征信息,提升模型的表达能力。
2、MobileNet_V2_Weights.IMAGENET1K_V1 的使用:
这个预训练模型权重是在 ImageNet 数据集上训练的。ImageNet 是一个包含超过 100 万张图像和 1000 个类别的广泛使用的数据集。预训练模型学习了各种物体和场景的特征,用户可以利用这些预训练的权重来进行迁移学习,即在自己的数据集上微调模型,以适应特定任务。这可以显著缩短训练时间,同时在较小的数据集上仍然能获得较好的性能。
(1)适用场景:
- 移动应用:由于其高效性,MobileNetV2 常用于需要在移动设备上进行实时图像处理的应用,如实时对象检测、增强现实(AR)等。
- 嵌入式设备:适用于边缘计算设备,如无人机、智能摄像头等,这些设备通常计算能力有限,但需要进行复杂的图像处理任务。
- 迁移学习:通过使用 ImageNet 预训练权重,用户可以快速将模型应用到新任务上,如图像分类、对象检测或语义分割等。
(2)优点与局限性:
-
优点:
- 极低的计算成本,非常适合低功耗设备。
- 优异的性能与计算效率平衡,适合资源受限的环境。
- 可通过迁移学习快速适应新任务。
-
局限性:
- 在超大规模数据集或极高精度要求的任务上,可能不如更复杂的模型如 ResNet 或 EfficientNet 表现优秀。
- 模型精度可能会因为过度追求轻量化而略有下降。
总体来说,MobileNetV2 及其预训练模型权重在需要高效计算和实时处理的任务中表现出色,尤其适合移动和嵌入式场景。
(3)其他模型了解
选择一个基本模型开始。对于图像分类,可以使用如ResNet, VGG或MobileNet等预训练模型,如果进行对象检测(例如标注开机画面的特定部分),可以考虑使用YOLO或SSD,以下是在网上找到的其他模型,大概了解下。
- ResNet (Residual Network)
- 简介: ResNet是由微软研究院提出的一种深度卷积神经网络架构,它通过引入“残差块”来解决深层网络中的梯度消失问题。这些残差块允许网络直接学习输入和输出之间的残差,而不是直接学习函数映射。
- 特点: ResNet以其深度和稳定性著称,有不同的版本(如ResNet-18, ResNet-50, ResNet-101),数字代表层数。它在ImageNet比赛中表现优异,常用于图像分类、检测等任务。
- 优点: 能够训练非常深的网络,同时保持较好的性能;在图像分类任务中广泛使用。
- VGG (Visual Geometry Group)
- 简介: VGG是由牛津大学的Visual Geometry Group提出的一种深度卷积神经网络。VGG网络以其简单且统一的卷积层设计(例如所有卷积核都为3x3)而闻名,特别是VGG16和VGG19这两种变体。
- 特点: 该模型非常深(16或19层),但其卷积核大小固定为3x3,池化层大小固定为2x2。它通常用于图像分类任务。
- 优点: 结构简单易于理解,性能良好;尽管深度较大,但由于设计的统一性,使得模型具有较高的稳定性。
- MobileNet
- 简介: MobileNet是为移动设备和嵌入式应用设计的轻量级卷积神经网络。它通过引入深度可分离卷积(Depthwise Separable Convolution)来减少模型参数量和计算量。
- 特点: 该模型特别适合在资源受限的环境中使用(如移动设备),可以在保证一定精度的同时显著降低计算开销。
- 优点: 高效、快速,适合嵌入式设备;在图像分类、对象检测等任务中表现良好。
- YOLO (You Only Look Once)
- 简介: YOLO是一个实时目标检测系统,它将目标检测视为一个单一的回归问题,将图像分割为SxS的网格,并预测每个网格的边界框和类概率。
- 特点: YOLO模型处理速度非常快,适合实时应用。它在检测速度和准确性之间进行了很好的权衡。
- 优点: 能够在单个前向传递中完成对象检测,非常适合需要实时处理的任务。
- SSD (Single Shot Multibox Detector)
- 简介: SSD是一种目标检测模型,它在一张图片的多个位置上预测多个对象类别,并且每个对象使用多个边界框。SSD将检测任务分为分类和回归两个部分,且不需要提取候选区域,直接预测检测结果。
- 特点: SSD模型在检测精度和速度之间做出了很好的平衡,尤其是在小目标检测中表现良好。
- 优点: 处理速度快,适合嵌入式系统中的实时检测;具有不同尺度的特征图,使其在多尺度目标检测上表现出色。
4 -实验过程
上边整个是对图片采集和裁剪过程,对于一个真正的项目,我理解是必要的,需要整理收到的图片,但是人为实在太麻烦了,所以要写代码,进行批量处理。
其实上章进行缩小和处理的图片自己没有用上。 我是直接用图片训练的,而在模型训练过程中,代码已经加入自动缩小。
1、创建目录结构
如下目录结果,我们需要创建两个目录“train”和“val”目录,并且在这两个目录下,再分别创建“off”和“on”分解夹。
因为我们用于训练数据不够多,开和关的图片一起一共才40张,我们需要分别放在两个目录“train”和“val”目录下,其中
dataset/
train/
on/
off/
val/
on/
off/
wjl-linux@ubuntu:~/Desktop/get_AI_data_jpg_photo/dataset$ tree
.
├── python_AI_built_models1.py
├── python_display_cuda_is_availbel.py
├── python_load_model_prediction.py
├── screen_status_model.pth
├── test_image
│ ├── image1.jpg
│ ├── image2.jpg
│ ├── image3.jpg
│ ├── image4.jpg
│ ├── image5.jpg
│ ├── image6.jpg
│ ├── image7.jpg
│ ├── image8.jpg
│ ├── image.jpg
│ ├── off-012.jpg
│ ├── off-013.jpg
│ ├── off-014.jpg
│ ├── test012.jpg
│ ├── test013.jpg
│ ├── test014.jpg
│ └── test015.jpg
├── train
│ ├── off
│ │ ├── off-001.jpg
│ │ ├── off-002.jpg
│ │ ├── off-003.jpg
│ │ ├── off-004.jpg
│ │ ├── off-005.jpg
│ │ ├── off-006.jpg
│ │ ├── off-007.jpg
│ │ ├── off-008.jpg
│ │ ├── off-009.jpg
│ │ ├── off-010.jpg
│ │ ├── off-011.jpg
│ │ ├── off-012.jpg
│ │ ├── off-013.jpg
│ │ ├── off-014.jpg
│ │ ├── off-015.jpg
│ │ ├── off-016.jpg
│ │ ├── off-017.jpg
│ │ ├── off-018.jpg
│ │ └── off-019.jpg
│ └── on
│ ├── on-001.jpg
│ ├── on-002.jpg
│ ├── on-003.jpg
│ ├── on-004.jpg
│ ├── on-005.jpg
│ ├── on-006.jpg
│ ├── on-007.jpg
│ ├── on-008.jpg
│ ├── on-009.jpg
│ ├── on-010.jpg
│ ├── on-011.jpg
│ ├── on-012.jpg
│ ├── on-013.jpg
│ ├── on-014.jpg
│ ├── on-015.jpg
│ ├── on-016.jpg
│ ├── on-017.jpg
│ ├── on-018.jpg
│ ├── on-019.jpg
│ ├── on-020.jpg
│ ├── on-021.jpg
│ └── on-022.jpg
└── val
├── off
│ ├── off-001.jpg
│ ├── off-002.jpg
│ ├── off-003.jpg
│ ├── off-004.jpg
│ ├── off-005.jpg
│ ├── off-006.jpg
│ ├── off-007.jpg
│ ├── off-008.jpg
│ ├── off-009.jpg
│ ├── off-010.jpg
│ ├── off-011.jpg
│ ├── off-012.jpg
│ ├── off-013.jpg
│ ├── off-014.jpg
│ ├── off-015.jpg
│ ├── off-016.jpg
│ ├── off-017.jpg
│ ├── off-018.jpg
│ └── off-019.jpg
└── on
├── on-001.jpg
├── on-002.jpg
├── on-003.jpg
├── on-004.jpg
├── on-005.jpg
├── on-006.jpg
├── on-007.jpg
├── on-008.jpg
├── on-009.jpg
├── on-010.jpg
├── on-011.jpg
├── on-012.jpg
├── on-013.jpg
├── on-014.jpg
├── on-015.jpg
├── on-016.jpg
├── on-017.jpg
├── on-018.jpg
├── on-019.jpg
├── on-020.jpg
├── on-021.jpg
└── on-022.jpg
7 directories, 102 files
2、编写训练代码
前面准备了那么多,终于到了训练模型的阶段了,如下代码,就是整个训练模型的过程了,从引入个文件包头,到数据变换,再到创建数据集,等等。
import os
import torch
import torch.nn as nn
from torchvision import datasets, transforms, models
from torch.utils.data import DataLoader
data_dir = '/home/wjl-linux/Desktop/get_AI_data_jpg_photo/dataset' # 请根据实际路径调整
# 数据变换
data_transforms = {
'train': transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
'val': transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
}
# 创建数据集
image_datasets = {x: datasets.ImageFolder(os.path.join(data_dir, x), data_transforms[x])
for x in ['train', 'val']}
# 创建数据加载器
dataloaders = {x: DataLoader(image_datasets[x], batch_size=32, shuffle=True, num_workers=4)
for x in ['train', 'val']}
dataset_sizes = {x: len(image_datasets[x]) for x in ['train', 'val']}
class_names = image_datasets['train'].classes
# 设置设备
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# 加载预训练的 MobileNetV2 模型
model = models.mobilenet_v2(weights='MobileNet_V2_Weights.IMAGENET1K_V1')
# 修改最后一层
model.classifier[1] = nn.Linear(model.last_channel, 1)
model = model.to(device)
# 定义损失函数和优化器
criterion = nn.BCEWithLogitsLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
# 训练模型
num_epochs = 10
for epoch in range(num_epochs):
print(f'Epoch {epoch}/{num_epochs - 1}')
print('-' * 10)
# 每个 epoch 有训练和验证阶段
for phase in ['train', 'val']:
if phase == 'train':
model.train() # 设置模型为训练模式
else:
model.eval() # 设置模型为评估模式
running_loss = 0.0
running_corrects = 0
# 迭代数据
for inputs, labels in dataloaders[phase]:
inputs = inputs.to(device)
labels = labels.to(device).float()
# 零参数梯度
optimizer.zero_grad()
# 前向传播
with torch.set_grad_enabled(phase == 'train'):
outputs = model(inputs)
preds = torch.sigmoid(outputs) > 0.5
loss = criterion(outputs, labels.unsqueeze(1))
# 只有在训练阶段进行反向传播和优化
if phase == 'train':
loss.backward()
optimizer.step()
# 统计损失和准确性
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum(preds == labels.data.unsqueeze(1))
epoch_loss = running_loss / dataset_sizes[phase]
epoch_acc = running_corrects.double() / dataset_sizes[phase]
print(f'{phase} Loss: {epoch_loss:.4f} Acc: {epoch_acc:.4f}')
print('Training complete')
# 保存模型
torch.save(model.state_dict(), '/home/wjl-linux/Desktop/get_AI_data_jpg_photo/dataset/screen_status_model.pth')
如下图,就是目录和代码的截图。

3、训练过程
如下当使用指令,运行python文件后,训练就开始了。
python3 python_AI_built_models1.py

如下是截图特写

4、使用模型检测
当训练好后,会出现一个名为“screen_status_model.pth”文件,然后我们就可以使用这个模型,编写代码,进行测试了。
import torch
from torchvision import models, transforms
from PIL import Image
# 设置设备
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# 打印设备信息
if device.type == 'cuda':
print(f"Using CUDA device: {torch.cuda.get_device_name(0)}")
else:
print("Using CPU")
# 加载模型
model = models.mobilenet_v2(weights='MobileNet_V2_Weights.IMAGENET1K_V1')
model.classifier[1] = torch.nn.Linear(model.last_channel, 1)
model.load_state_dict(torch.load('/home/wjl-linux/Desktop/get_AI_data_jpg_photo/dataset/screen_status_model.pth'))
model = model.t 673 mkdir off
674 cd ../
675 ls
676 cd validation/
677 mkdir off
678 mkdir on
o(device)
model.eval()
# 预处理单张图片
img_path = '/home/wjl-linux/Desktop/get_AI_data_jpg_photo/dataset/test_image/image8.jpg' # 请将此路径替换为实际图片路径
img = Image.open(img_path)
preprocess = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]),
])
img_tensor = preprocess(img)
img_tensor = img_tensor.unsqueeze(0).to(device)
# 进行预测
with torch.no_grad():
output = model(img_tensor)
prediction = torch.sigmoid(output) > 0.5
if prediction.item():
print('Screen is ON')
else:
print('Screen is OFF')
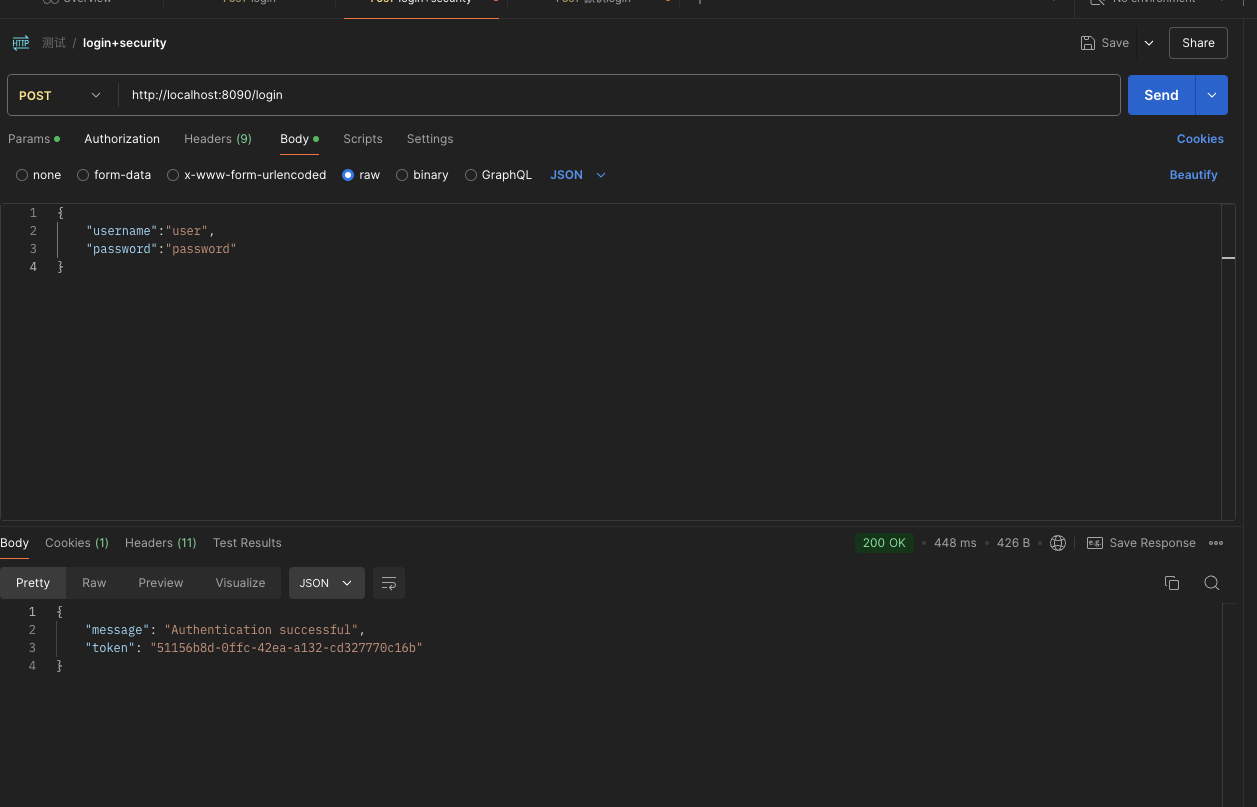
如下图,是使用模型预测的代码截图。

然后我们需要创建一个新目录,名为“test_image”目录,存放我们要检测的图片。
结果截图如下,我们新拍摄一张屏幕开机或者关机的图片(自己定),然后运行脚本进行测试。
可以看到屏幕虽然反光,但是还是识别为屏幕为关。

5、使用GPU问题
简单说下问题,就是我发现在使用训练和检测过程中,都是用的cpu,对于计算,CPU会慢些,应该是安装工具不匹配问题,这块还在查,在写本篇是,还没有,后续需要单出一篇了。
如下是检测使没使用cuda,检测代码。
import torch
print("CUDA is available:", torch.cuda.is_available())

6、历史记录
对于自己操作过程记录,其中也有很多错误尝试吧 。
587 python3 python_AI_load_data.py
588 cat python_AI_load_data.py
589 python3 python_AI_load_data.py
590 claer
591 clear
592 pip install torchvision
593 pip install torch
594 pip show torch torch vision
595 pip show torch vision
596 ls
597 python3 python_AI_load_data.py
598 cat python_AI_load_data.py
599 vim python_AI_load_data.py
600 python3 python_AI_load_data.py
601 ls
602 python3 python_AI_load_data.py
603 vim python_AI_load_data.py
604 python3 python_AI_load_data.py
605 ls
606 terr
607 tree
608 ls
609 vim python_AI_load_data.py
610 ls
611 vim python_AI_load_data.py
612 python3 python_AI_load_data.py
613 cat python_AI_load_data.py
614 vim python_AI_load_data.py
615 vim python_AI_load_data1.py
616 python3 python_AI_load_data1.py
617 vim python_AI_built_mmodels.py
618 python3 python_AI_built_mmodels.py
619 vim python_AI_built_models1.py
620 python3 python_AI_built_models1.py
621 ls
622 cat python_AI_built_m
623 cat python_AI_built_models1.py
624 vim python_AI_built_models1.py
625 ls
626 cd CSI-Camera/
627 ls
628 pwd
629 cd ../
630 ls
631 python3 python_load_model_prediction.py
632 cat python_load_model_prediction.py
633 python3 python_load_model_prediction.py
634 cat python_load_model_prediction.py
635 python3 python_load_model_prediction.py
636 ls
637 vim python_main_camera_for_test.py
638 python3 python_main_camera_for_test.py
639 ls /dev/*
640 pip install opencv-python PyQt5
641 pip install opencv-python
642 ls
643 python3 python_main_camera_for_test1.py
644 vim python_main_camera_for_test1.py
645 python3 python_main_camera_for_test1.py
646 python3 python_main_camera_for_test1.py
647 python3 python_load_model_prediction.py
648 vim python_display_cuda_is_availbel.py
649 python3 python_display_cuda_is_availbel.py
650 nvidia-smi
651 nvcc -v
652 cat ~/.bashrc
653 source ~/.bashrc
654 jtop
655 pwd
656 ls
657 cd ../
658 ls
659 cd off_status
660 ls
661 cd ../../
662 ls
663 mkdir dataset
664 ls
665 cd dataset/
666 mkdir train/
667 mkdir validation
668 cd train/
669 ls
670 mkdir on
671 mkdir off\
672 ls
673 mkdir off
674 cd ../
675 ls
676 cd validation/
677 mkdir off
678 mkdir on
679 ls
680 tree
681 sudo apt-get install tree
682 tree
683 ls
684 cd ..
685 ls
686 tree
687 pwd
688 ls
689 python3 python_AI_built_models1.py
690 cat python_AI_built_models1.py
691 vim python_AI_built_models1.py
692 python3 python_AI_built_models1.py
693 ls
694 vim python_load_model_prediction
695 nvcc --version
696 nvcc --version # 检查 CUDA 版本
697 cat /usr/local/cuda/include/cudnn_version.h | grep CUDNN_MAJOR -A 2
698 # 先卸载可能不匹配的PyTorch版本
699 sudo pip3 uninstall torch torchvision
700 sudo apt-get install python3-pip libopenblas-base libopenmpi-dev
701 pip3 install --upgrade pip
702 sudo pip3 install torch-1.14.0+nv23.03-cp38-cp38-linux_aarch64.whl torchvision-0.15.0+nv23.03-cp38-cp38-linux_aarch64.whl
703 sudo pip3 uninstall torch torchvision
704 sudo pip3 install torch==1.10.0+nv21.05.1 torchvision==0.11.1+nv21.05.1 -f https://developer.download.nvidia.com/compute/redist/jp/v45/pytorch/torch_stable.html
705 ls
706 python3 python_display_cuda_is_availbel.py
707 sudo pip3 install --upgrade pip
708 python3 python_display_cuda_is_availbel.py
709 # 先卸载现有版本
710 sudo pip3 uninstall torch torchvision
711 # 通过 pip 安装 PyTorch 和 torchvision
712 sudo pip3 install torch==1.10.0+nv21.05.1 torchvision==0.11.1+nv21.05.1 -f https://developer.download.nvidia.com/compute/redist/jp/v45/pytorch/torch_stable.html
713 dpkg-query --show nvidia-14t-core
714 dpkg-query --show nvidia-l4t-core
715 sudo apt-get update
716 sudo apt-get install python3-pip libopenblas-base libopenmpi-dev
717 sudo pip3 install torch-2.0.0+nv23.03-cp38-cp38-linux_aarch64.whl
718 ls
719 python3 python_display_cuda_is_availbel.py
720 cat python_AI_built_models1.py
721 ls
722 python3 python_display_cuda_is_availbel.py
723 nvidia-smi
724 reboot
725 python3 python_load_model_prediction.py
726 ls
727 history
728 nvidia-smi
729 sudo tegrastats
730 nvcc --version
731 sudo -H pip3 install -U jetson-stats
732 sudo jtop
733 sudo systemctl restart jtop.service
734 sudo jtop
735 ls
736 cat python_display_cuda_is_availbel.py
737 python3 python_display_cuda_is_availbel.py
738 nvcc --version
739 cat ~/.bashrc
740 vim ~/.bashrc
741 source ~/.bashrc
742 vim ~/.bashrc
743 python3 python_display_cuda_is_availbel.py
744 cuda -v
745 nvcc --version
746 cat python_display_cuda_is_availbel.py
747 pip3 uninstall torch torchvision torchaudio
748 sudo apt-get install python3-pip libopenblas-base libopenmpi-dev
749 https://developer.download.nvidia.com/compute/redist/jp/v50/pytorch/
750 python3 python_display_cuda_is_availbel.py
751 ls
752 python3 python_load_model_prediction.py
753 cat python_load_model_prediction.py
754 python3 python_load_model_prediction.py
755 python3 python_display_cuda_is_availbel.py
756 python3 python_load_model_prediction.py
757 cat python_load_model_prediction.py
758 python3 python_load_model_prediction.py
759 python3 python_display_cuda_is_availbel.py
760 python3 python_load_model_prediction.py
761 python3 python_load_model_prediction.py \
762 python3 python_display_cuda_is_availbel.py
763 pip3 uninstall torch torchvision torchaudio
764 pip3 install --pre torch torchvision torchaudio --extra-index-url https://developer.download.nvidia.com/compute/redist/jp/v51/pytorch/
765 python3 python_display_cuda_is_availbel.py
766 python3 python_load_model_prediction.py \pip3 uninstall torch torchvision torchaudio
767 python3 python_load_model_prediction.py
768 python3 python_display_cuda_is_availbel.py
769 export TORCH_INSTALL=https://developer.download.nvidia.cn/compute/redist/jp/v511/pytorch/torch-2.0.0+nv23.05-cp38-cp38-linux_aarch64.whl
770 python3 python_display_cuda_is_availbel.py
771 python3 python_load_model_prediction.py
772 history
773 python3 python_display_cuda_is_availbel.py
774 python3 python_load_model_prediction.py
775 python3 python_display_cuda_is_availbel.py
776 git clonehttps://github.com/pytorch/visioncd vision
777 git clone https://github.com/pytorch/visioncd vision
778 git clone https://github.com/pytorch/vision
779 python3 python_display_cuda_is_availbel.py
780 python3 python_load_model_prediction.py
781 python3 python_display_cuda_is_availbel.py
782 python3 python_load_model_prediction.py
783 python3 python_display_cuda_is_availbel.py
784 pip install torch-1.13.0a0+340c4120.nv22.06-cp38-cp38-linux_aarch64.whl
785 pip3 install torchvision
786 ls
787 history
788 pip3 uninstall torchvision
789 pip install torch-1.13.0a0+340c4120.nv22.06-cp38-cp38-linux_aarch64.whl
790 pip3 install --pre torch torchvision torchaudio --extra-index-url https://developer.download.nvidia.com/compute/redist/jp/v50/pytorch/
791 pip install torch-1.13.0a0+340c4120.nv22.06-cp38-cp38-linux_aarch64.whl
792 python3 -c "import torch; print(torch.__version__)"
793 python3 -c "import torchvision; print(torchvision.__version__)"
794 ls
795 pip3 install tensorflow-2.9.1+nv22.06-cp38-cp38-linux_aarch64.whl
796 python -m pip install --upgrade pip
797 ls
798 pip3 install torch-2.0.0+nv23.05-cp38-cp38-linux_aarch64.whl
799 history
800 pip3 install --pre torchvision --extra-index-urlhttps://developer.download.nvidia.cn/compute/redist/jp/v511/pytorch/
801 pip3 install torchvision --extra-index-urlhttps://developer.download.nvidia.cn/compute/redist/jp/v511/pytorch/
802 pip3 install torchvision --extra-index-url https://developer.download.nvidia.cn/compute/redist/jp/v511/pytorch/
803 sudo apt-get -y update;
804 export TORCH_INSTALL=https://developer.download.nvidia.cn/compute/redist/jp/v60dp/pytorch/torch-2.2.0a0+6a974be.nv23.11-cp310-cp310-linux_aarch64.whl
805 head -n 1 /etc/nv_tegra_release
806 pip3 install --pre torch torchvision torchaudio --extra-index-url https://developer.download.nvidia.com/compute/redist/jp/v50/pytorch/
807 pip3 install torch-2.1.0a0+41361538.nv23.06-cp38-cp38-linux_aarch64.whl
808 sudo apt-get -y install python3-pip libopenblas-dev;
809 export TORCH_INSTALL=https://developer.download.nvidia.cn/compute/redist/jp/v511/pytorch/torch-2.0.0+nv23.05-cp38-cp38-linux_aarch64.whl
810 python3 -m pip install --upgrade pip; python3 -m pip install numpy==’1.26.1’; python3 -m pip install --no-cache $TORCH_INSTALL
811 pip3 install --no-cache https://developer.download.nvidia.com/compute/redist/jp/v51/pytorch/
812 pip3 install torch https://developer.download.nvidia.com/compute/redist/jp/v51/pytorch/
813 ls
814 pip3 install torch-2.0.0a0+8aa34602.nv23.03-cp38-cp38-linux_aarch64.whl
815 pip3 uninstall torchvision
816 pip3 install torchvision==0.16.0
817 pip3 uninstall torch torchvision torchaudio
818 git clone https://github.com/pytorch/vision
819 pip3 install --pre torch torchvision torchaudio --extra-index-url https://developer.download.nvidia.com/compute/redist/jp/v50/pytorch/
820 ls
821 pwd
822 cat ~/.bashrc
823 pwd
824 vim ~/.bashrc
825 source ~/.bash\
826 source ~/.bash
827 source ~/.bashrc
828 python3 python_display_cuda_is_availbel.py
829 robot
830 reboot
831 pwd
832 history
5-代码过程
1、目录截图
如下图,为目录截图。

2、代码链接
有需要的可以拿走,如下为代码链接
https://download.csdn.net/download/qq_22146161/89696036
6 -细节部分
(1)获取版本信息
在遇到GPU无法使用的时候,各个软件版本的匹配还是挺重要的,以下是获取各个版本的方式,做个总结。
1. 验证CUDA和cuDNN是否正常工作
确保CUDA和cuDNN都已经正确安装,并且可以正常使用。可以使用以下命令进行验证:
(1)运行以下命令查看CUDA版本:
nvcc --version
(2)执行以下命令来检查cuDNN的版本:
cat /usr/include/cudnn_version.h | grep CUDNN_MAJOR -A 2
2. 验证PyTorch和torchvision安装
确保PyTorch和torchvision已经正确安装并与CUDA兼容。运行以下命令来检查:
(1)在Python环境中,输入以下命令:
import torch
print("PyTorch version:", torch.__version__)
print("CUDA available:", torch.cuda.is_available())
CUDA available: 应该返回 True,这表示PyTorch可以识别并使用CUDA。
(2)验证torchvision是否安装正确,在Python环境中,输入以下命令:
import torchvision
print("torchvision version:", torchvision.__version__)
3. 查看Jetson设备的系统信息
使用jetson_release命令来查看设备的详细信息:
jetson_release
这将显示包括JetPack版本、CUDA版本、cuDNN版本等详细信息。
4. 查看python版本信息
使用如下命令,来查看python相关版本信息
python3 --version
(2)查看目录结构
在本章中,为了展示目录结构使用了tree这个工具,以下为具体安装方式
1、tree工具安装
sudo apt-get install tree
2、查看目标目录结构
tree /mnt/data/dataset
3、其他代替方式
ls -R /mnt/data/dataset
或者
find /mnt/data/dataset -type d
4、如果使用tree,目录结构大概是如下样子的
/mnt/data/dataset/
├── train
│ ├── on
│ │ ├── on-001.jpg
│ │ ├── on-002.jpg
│ │ └── ...
│ └── off
│ ├── off-001.jpg
│ ├── off-002.jpg
│ └── ...
└── val
├── on
│ ├── on-011.jpg
│ ├── on-012.jpg
│ └── ...
└── off
├── off-011.jpg
├── off-012.jpg
└── ...
(3)每个目录下放的什么文件
/mnt/data/dataset/
├── train
│ ├── on
│ │ ├── on-001.jpg
│ │ ├── on-002.jpg
│ │ └── ...
│ └── off
│ ├── off-001.jpg
│ ├── off-002.jpg
│ └── ...
└── val
├── on
│ ├── on-011.jpg
│ ├── on-012.jpg
│ └── ...
└── off
├── off-011.jpg
├── off-012.jpg
└── ...
如上,如果目录结构一直的话,那么每个目录放置文件代表含有如下,因为我们本次实验,直接用训练集合当做、验证集了,正常应该不一样的。
- 在 train/on 目录中放置所有训练集中屏幕处于打开状态的图片。
- 在 train/off 目录中放置所有训练集中屏幕处于关闭状态的图片。
- 在 val/on 目录中放置所有验证集中屏幕处于打开状态的图片。
- 在 val/off 目录中放置所有验证集中屏幕处于关闭状态的图片
(4)报错:ModuleNotFoundError: No module named ‘torchvision’
如上,自己在运行代码的时候报错,提示没有这个module,安装后可以,但是实际上没有使用gpu 不过这都是后话了,先解决我们眼前问题。
这个错误是因为没有安装 torchvision 模块。可以通过以下命令安装 torchvision:
pip install torchvision
如果没有安装torch,可以一同安装。
pip install torch torchvision
安装后好后,再次尝试之前python脚本。
(5)报错:文件路径没找到&路径拼写错误
在实践中操作过程中,发现提示路径没存在,这块可以使用ls或者tree来查看下,路径到底存不在,来更正到底有没有这个路径。
ls /home/xxx/Desktop/xxx/dataset
tree /home/xxx/Desktop/xxx/dataset
网址:
https://pytorch.org/get-started/previous-versions/
7 -总结
如此一来就做了一个简单demo,学习了一下AI,体验了过程,为后续学习打下基础