背景
OPPO是一家全球化的科技公司,随着公司的快速发展,业务方向越来越多,对中间件的依赖也越来越紧密,中间件的集群的数量成倍数增长,在中间件的部署,使用,以及运维出现各种问题。
1.中间件与业务应用混部在物理机,资源隔离困难
2.集群申请周期长,人工介入多,交互流程复杂
3.中间件整体CPU、内存、磁盘资源利用率低
4.业务使用中间件资源使用难以量化,成本核算困难
5.稳定性不足,故障恢复慢,步骤繁琐
6.传统物理机制没办法提供很强的资源弹性
容器化前业务申请中间件集群流程如下:
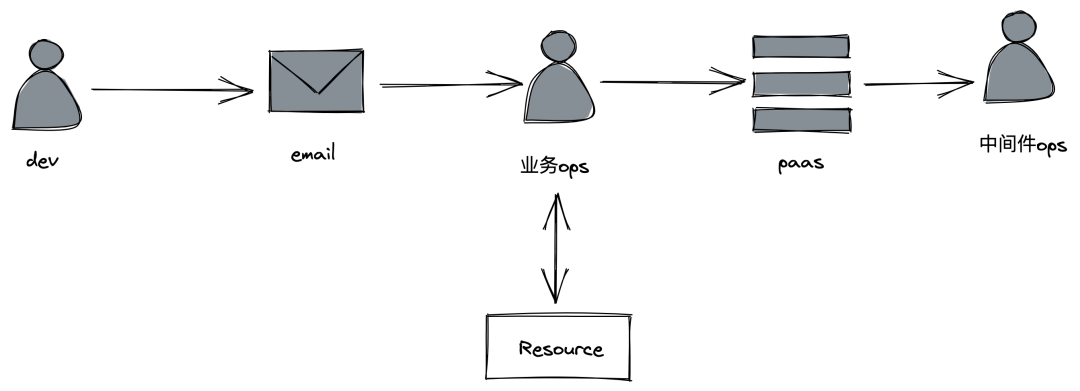
容器化前中间件基于传统的物理机进行部署,业务申请中间件,需填写中间件集群的所需机器规格,邮件到业务运维,业务运维与资源交互小组申请机器,然后业务运维在PaaS平台申请中间件集群,手动录入机器列表,中间件运维审批前,根据机器列表手动安装好中间件部署的Agent,最终通过Agent将中间件集群部署到业务的提供机器中。容器技术和云原生的火热,将为中间件的部署,使用以及运维带来变革。
容器化挑战
目前在OPPO有非常强的维护和定制K8S的团队,因此在我们中间件侧不用去考虑K8S底座的编排,调度,运维,容器管理等(专人专事),而是从上层中间件应用侧去考虑容器化的挑战。
1.有转态中间件容器故障后重新调度如何保持原有状态(固定IP和数据保持)
2.IO密集性的中间件如何做IO隔离
3.当性能不足或资源利用率不高时,如何快速探测并进行扩缩容(HPA和VPA)
4.如何做到故障自愈对用户无感知,对业务无损
5.如何云原生化以及未来展望
容器化
状态保持
在中间件容器化生产环境K8S暂未使用共享存储,而是使用本地盘FlexVolume+LVM,但共享块存储和共享文件存储也在陆续推进中,因此目前若容器所在的宿主机宕机,容器重新调度虽能保持IP固定不变,但数据会丢失,因此在中间件层面需保障高可用,数据有主备等关系。
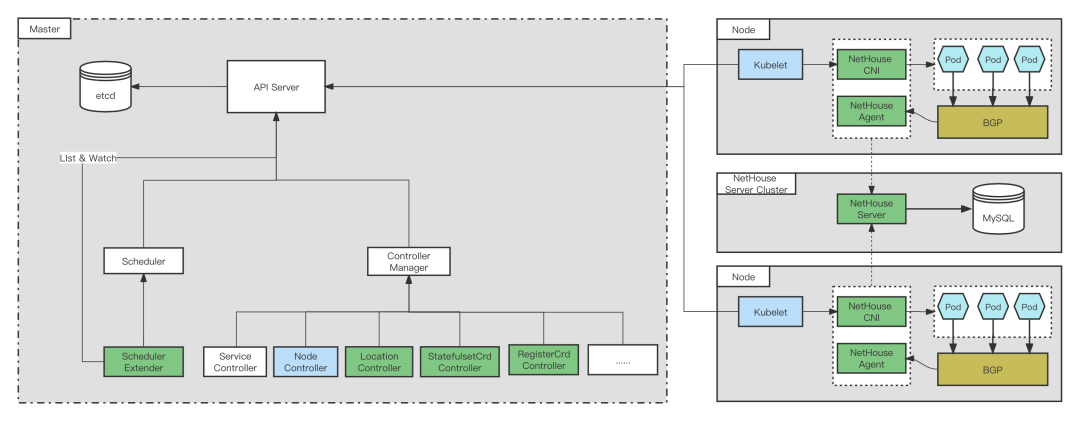
为了固定IP,自研了LocationController,StatefulSetController,ResitorController,NetHouse,扩展了Scheduler(SchedulerExtender),修改Kubelet,NodeController等源码。
Kubelet根据Pod的annotation,在有使用固定的需求时,创建Pod的时候需要打上对应的annotation,然后kubelet会打到创建的sandbox container的label里。调用cni接口申请网络时传参加入保留IP标识的标示,网络侧返回保留的Pod IP。当Pod删除时候,从sandbox container拿出这个信息,调用cni接口时,传入ns、podname和保留IP标识的标示,从而通知到网络该IP要保留。
SchedulerExtender调度模块获取缓存的Location CRD,进行调度,当有Pod需要调度会进行检查是否有IP保持不变的annotation,如果有检查是否有同名的Location CRD,如果有Location CRD,说明之前进行IP保持不变,在获取networkzone,返回符合networkzone条件的Node列表,如果没有Location CRD,说明是初次调度,返回所有满足条件的Node列表。SchedulerExtender的Controller模块负责创建和更新Location CRD。
LocationController watch location的add/update/delete事件,如果这个location的deletiontimestamp不为空(使用Finalizers机制,创建Location的时候加上Finalizer),如果此Location对应的Pod已经删除或者处于pending状态未分配IP,则调用NetHouse的api释放该Pod的固定IP,然后update当前Location将Finalizer去除(去掉Finalizer后,当前location会自动被ApiServer删除),update失败则将此Location放入RatelimitedQueue;否则将此Location放入RatelimitedQueue,等待下次Reconcile检查。
为了防止删除跑路,线上容器提供回收站功能,容器下线并不会真正下线会在回收站保留3天,3天后再彻底删除。
容器隔离
资源隔离
容器的核心技术是Cgroup+Namespace,Cgroup是Linux内核提供的一个特性,用于限制和隔离一组进程对系统资源的使用,能限制CPU,Memory,Net等,目前在OPPO生产环境主要为Cgroup V1的版本,Cgroup V1可以限制进程读写的 IOPS 和吞吐量,但它只能对 Direct I/O 的文件读写进行限速,对 Buffered I/O 的文件读写无法限制。Buffered I/O 指会经过 PageCache 然后再写入到存储设备中。这里面的 Buffered 的含义跟内存中 buffer cache 不同,这里的 Buffered 含义相当于内存中的buffer cache+page cache。像Kafka,RocketMQ,Elasticsearch这种中间件重度依赖底层操作系统提供的PageCahe功能,因此在中间件使用的容器上并没有做实际的IO限速,IO打满宿主机磁盘影响其上其它服务也时有发生。目前主要靠划分独立资源池来解决,将资源池划分为通用型,内存型,IO密集型等,分别部署像ZK,Redis,MQ/ES等中间件。后期考虑对强管控的中间件集群提供Kata Container虚拟机级别的隔离。
视图隔离
容器中的执行top、free等命令展示出来的CPU,内存等信息是从/proc目录中的相关文件里读取出来的。而容器并没有对/proc,/sys等文件系统做隔离,因此容器中读取出来的CPU和内存的信息是宿主机的信息,与容器实际分配和限制的资源量不同 。
/proc/cpuinfo
/proc/diskstats
/proc/meminfo
/proc/stat
/proc/swaps
/proc/uptime
为了实现让容器内部的资源视图更像虚拟机,使得应用程序可以拿到真实的CPU和内存信息,就需要通过文件挂载的方式将cgroup的真实的容器资源信息挂载到容器内/proc下的文件,使得容器内执行top、free等命令时可以拿到真实的CPU和内存信息。我们的做法也是像社区一样利用的lxcfs来提供容器中资源的可见性。lxcfs 是一个开源的FUSE(用户态文件系统)实现来支持LXC容器,它也可以支持Docker容器。架构如下
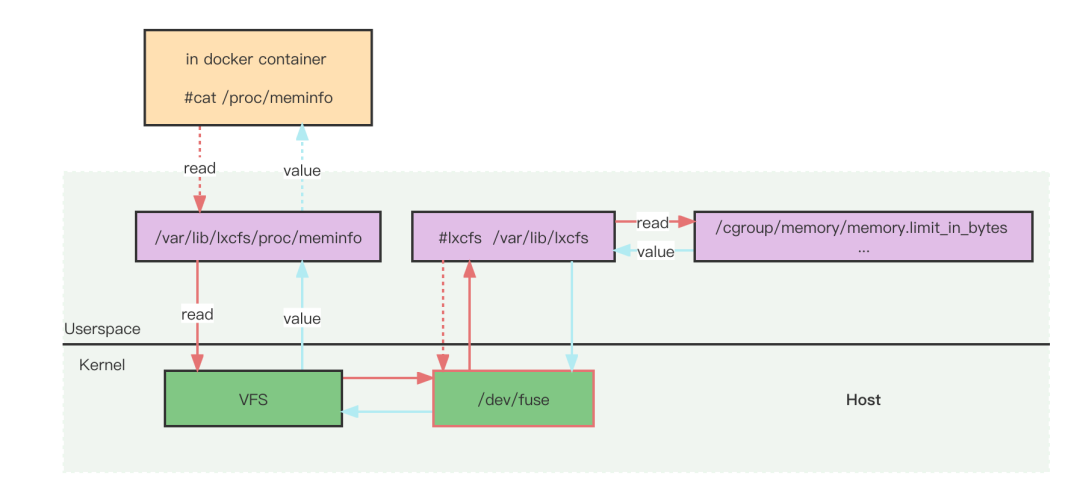
比如,把宿主机的 /var/lib/lxcfs/proc/memoinfo 文件挂载到Docker容的/proc/meminfo位置后。容器中进程读取相应文件内容时,LXCFS的FUSE实现会从容器对应的Cgroup中读取正确的内存限制。从而使得应用获得正确的资源约束设定。
部署集群
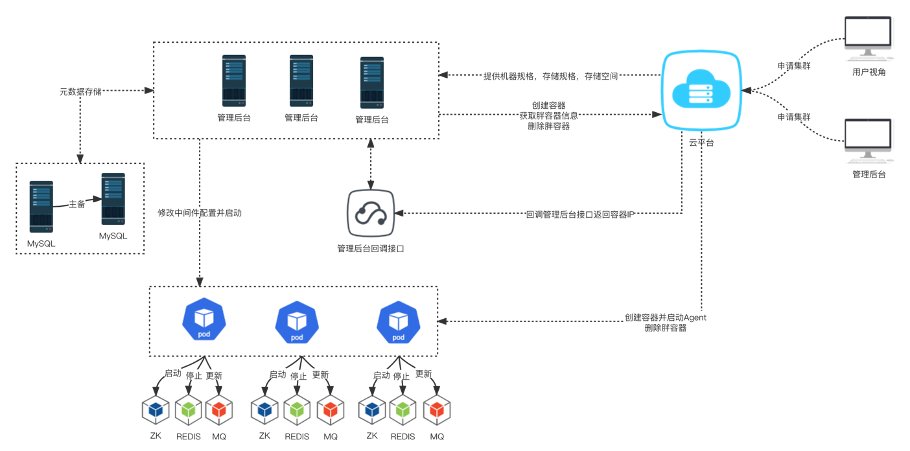
容器化前,业务申请申请中间件集群流程,需业务研发邮件到业务运维,业务运维向资源交互组申请物理机,中间件运维将物理机装好Agent,再通过PaaS平台进行部署。
容器化后,业务侧直接选择好机器规格,存储类型,存储空间,实例数量,然后统一从OPPO云入口进行中间件的申请,中间件侧会通过K8S的admission webhook对接自研的配额系统,预先校验业务配额是否充足,容器资源是否充足。将资源校验前置校验目的为防止创建时,资源不足,容器没有创建成功一直Pending的情况。并且创建容器会使用中间件定制的镜像,其中包含中间件安装包,agent,堡垒机等预制服务,预制服务随容器的启动自动拉起。中间件侧调用创建容器接口会传入一个回调地址,每创建成功一个容器会回调一次地址。在中间件侧需保证回调的幂等,同时容器创建成功会自动拉起中间件的agent,后续整个集群的部署,启停,更新,配置修改,都是通过内置agent进行。接口幂等,部署的逻辑等代码均在中间件侧,若资源校验通过,但部署过程中没有资源或部署过程中异常中断,中间件侧还需提供重试逻辑功能,最终集群创建成功会自动设置建议的监控阈值并自动接入中间件监控。
优点不用关心底层K8S相关的细节,缺点在需中间件侧提供类似Reconcile,接口幂等功能,并且在高度定制固定IP的环境,容器故障并不会主动漂移和重建,因此就衍生出了中间件侧故障自愈的平台。
监控告警
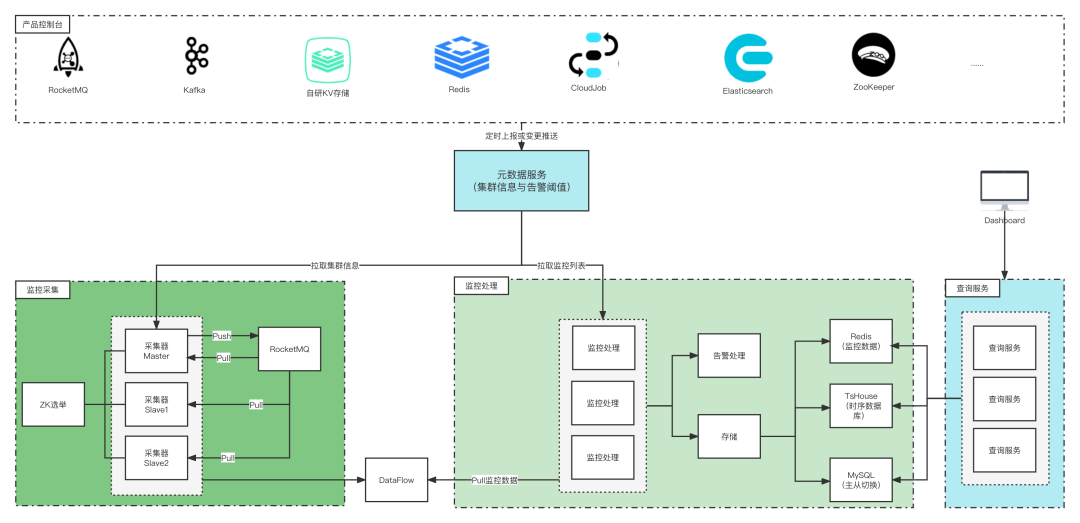
中间件监控分四个组件,监控采集器,告警处理器,元数据服务,监控查询服务。
元数据服务:中间件产品会定时将集群元数据与集群告警阈值上报到中间件元数据服务。同时一旦集群元数据或告警信息有变动也会主动推送到元数据服务。
监控采集器:监控采集侧周期性的拉取集群元信息生成监控任务投递到RocketMQ(监控采集器通过ZK进行选主只有Master才能生成监控任务),监控采集分集群分布式采集监控任务,将结果Source自研高性能数据流处理DataFlow。
监控处理器:监控处理侧周期性拉取集群告警阈值,消费DataFlow 进行告警阈值判断,超过阈值则通过统一告警进行邮件,短信发送,并将采集结果Sink到ES,Redis,MySQL,自研时序数据库。
监控查询服务:提供中间件应用,容器,以及宿主机的监控查询,在中间件集群详情,则通过该服务进行监控dashboard展示。
缺点在集中式采集,采集器,处理器占用较多资源,并且集群之间采集有一定影响。
故障自愈
中间件内部自研了一套针对中间件告警事件的自动化运维平台,整体故障自愈的流程如下:
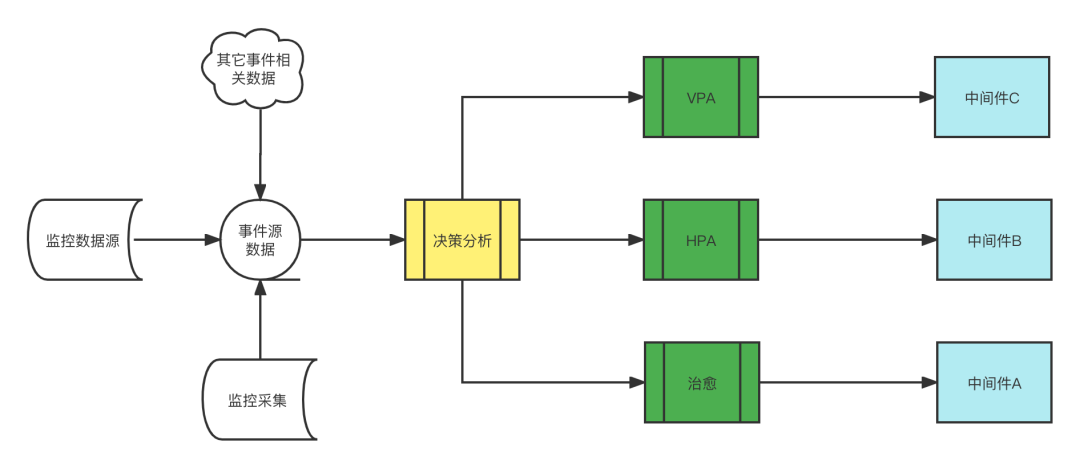
自动化运维平台通过监控值与决策分析,判断事件是否是治愈事件(eg:实例故障),HPA事件(eg:性能不足),VPA事件(eg:空间不足),最终调用各个中间件产品的上述事件的接口去完成相应的实例重启,原IP重建,水平扩容,垂直扩缩,没有利用K8S原生故障自愈特性,目前基本能做到2分钟内实例的故障自愈。这里重点讲一下实例的故障自愈,中间件监控采集周期为30秒,连续3次(可配置)判断故障即90秒,就会触发故障治愈的事件,治愈事件的流程先判断中间件应用的实例故障,尝试Ping 容器是否能通,并从监控获取容器和宿主机的监控状态,若仅中间件实例故障则重新拉起实例,若容器故障则强制重启容器,若宿主机故障则原IP重建,重建成功后则调用各个中间件部署接口部署实例,重新写入配置并启动。原IP重建并不会保存原有数据,所以像ZK,ES,MQ,Redis需通过主从关系重新同步Master的数据。
使用域名化
中间件已全面域名化,业务通过域名使用各个中间件集群,以下以Redis哨兵集群为例
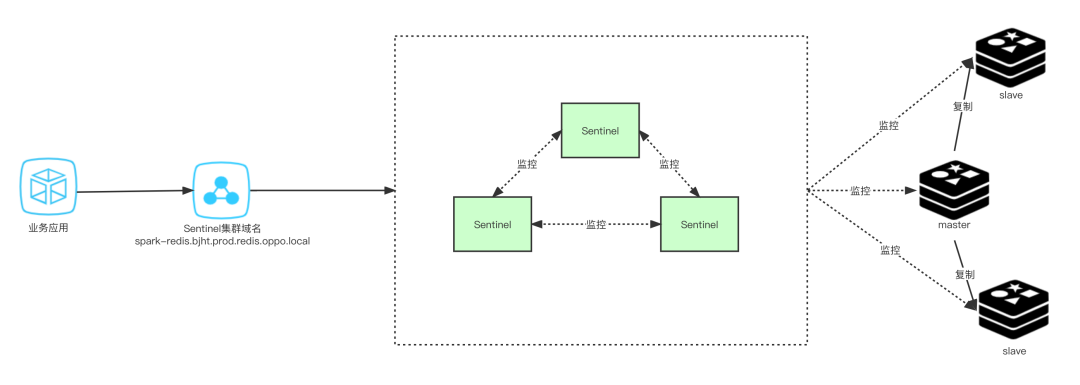
业务侧的配置,仅配置Sentinel集群的域名即可,当容器所在宿主机宕机,中间件侧会自动根据自动化运维进行原IP重建,但数据面需要通过各个中间件自身的高可用去保证重建实例的数据恢复,比如当Master宕机,Slave提升为新Master,原IP重建后的老Master将以Slave方式接入到集群,重新全量同步数据。
云原生化
云原生化主要从Operator,统一内核,存算分离,Serverless,Service Mesh等几个方面去讲。
Operator化
Operator作为解决复杂应用容器化的一种思路,通过将专业领域知识注入K8S完成对复杂有状态应用的自动部署和管理。不同的中间件如Redis、ZooKeeper等,其部署,扩缩容、备份方法各有区别,Operator针对这些复杂的场景进行专业的处理。简单理解,Operator=CRD+Controller,CRD完成资源的定义,Controller监听CRD的CRUD事件根据业务逻辑进行自定义处理。
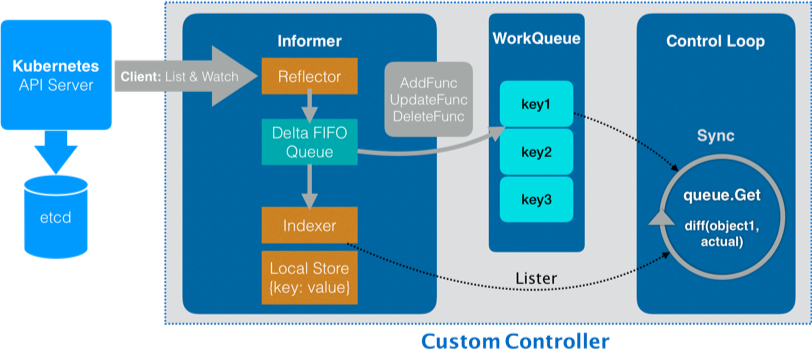
简述一下Controller工作原理,主要使用到 Informer和workqueue两个核心组件。Controller可以有一个或多个informer来跟踪某一个resource。Informter跟API server保持通讯获取资源的最新状态并更新到本地的cache中,一旦跟踪的资源有变化,informer就会调用callback。把关心的变更的Object放到workqueue里面。然后woker执行真正的业务逻辑,计算和比较workerqueue里items的当前状态和期望状态的差别,然后通过client-go向API server发送请求,直到驱动这个集群向用户要求的状态演化。
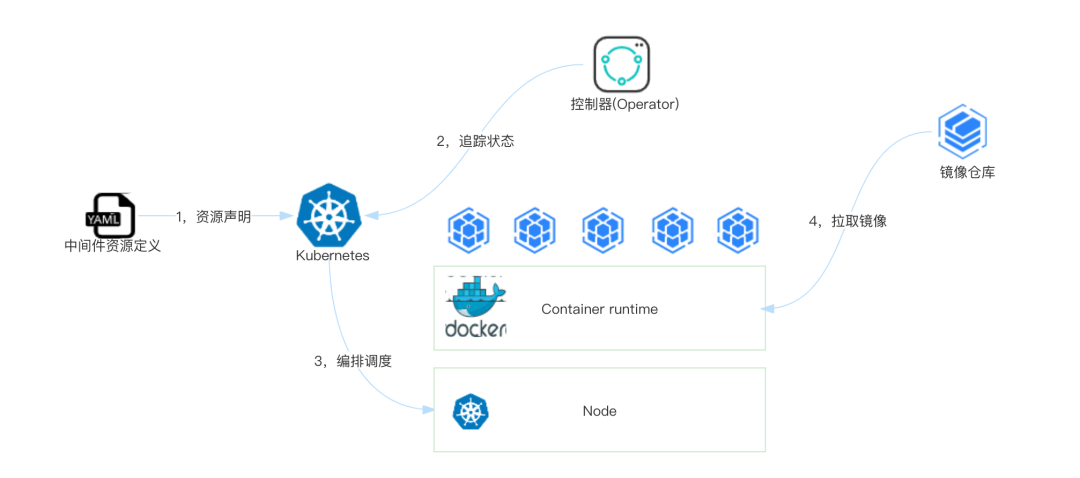
在OPPO内部大部分中间件都已支持基于Operator的方式进行集群部署,运维,将相关代码化到Operator,并利用K8S强大的抽象来管理中间件的应用。
在部署和扩缩容方式上,中间件产品侧直接通过Operator与K8S的对象进行交互,不在基于Agent的部署方式。将部署逻辑,扩缩容逻辑下沉到Operator,资源占用更少,维护成本低。
配置修改,原有的方式是通过随着容器启动的Agent的进行配置文件的下发,Operator后则,通过ConfigMap进行配置的下发,利用K8S的能力,保证配置应用集群的所有实例。
可观测则从原的集中式采集改为exporter的方式进行分布式采集,防止了漏采,减少了像集中式采集集群之间的影响,日志和监控则复用容器化日志和监控组件。
使用方式则全面提供集群域名和实例域名供业务选择使用,集群的Service域名,Pod域名与公司内部DNS打通,业务可在非K8S环境使用云原生中间件。在中间件集群内部通讯也是通过Pod的域名进行的,保证容器重建后,配置不需修改。
无缝升级,利用K8S的Deployment管理Operator,自运维,利用K8S故障自愈特性,深度洞察,Operator提供Exporter可清晰查看Operator的各个Metric指标。
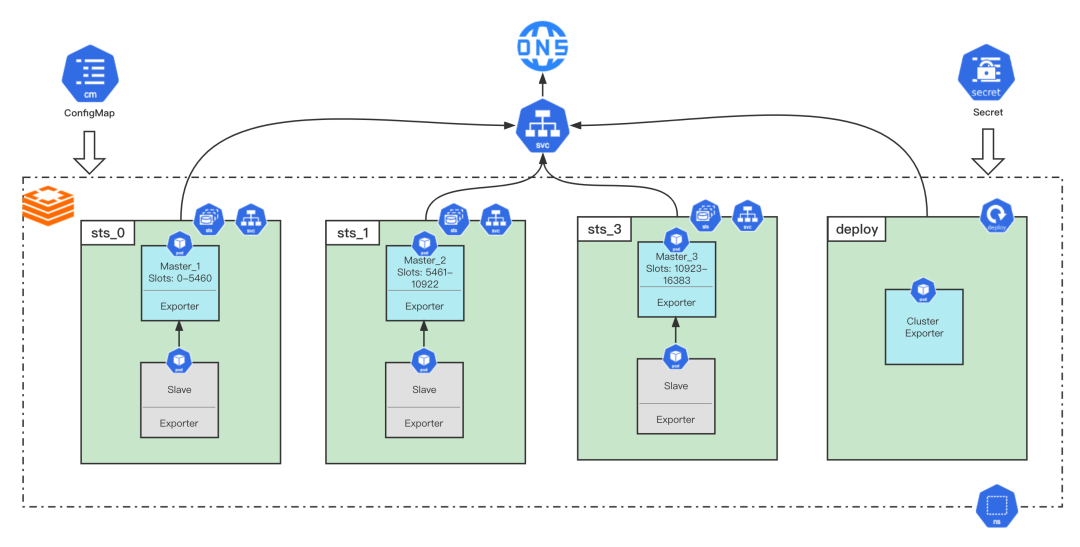
举一个部署一个3个分片的RedisCluster集群例子,每个分片部署一个Statefulset,并配置Pod反亲和性,保证分片主从节点不被调度在同一主机上,配合扩展的Scheduler-extender,保证一个RedisCluster集群不能超过一半的Master节点在同一台物理机,使用Configmap为所有Redis Pod注入配置文件,使用Secret保存Redis密码,每一个sts一个Service,同时每个集群维度一个Service,在创建每个Redis实例时,会以Sidecar的方式提供实例的exporter用于采集该实例监控,同时会额外创建一个Pod用于采集集群级别的监控,并提供集群级别的exporter,Service域名和Pod域名都注册公司到DNS,业务可以在K8S集群内外都可以通过集群的Service域名进行访问。
监控告警
基于Operator方式部署中间件后监控流程也有所变化如下图:
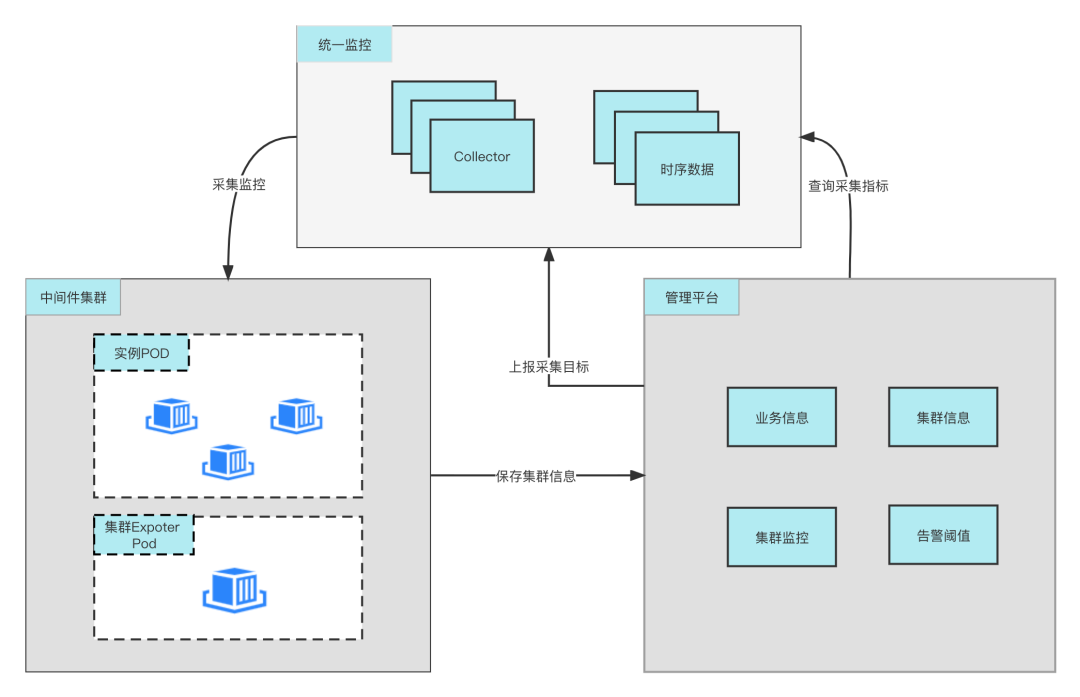
通过Operator创建成功集群后会将实例IP与实例域名,集群Exporter IP与其域名保存到中间件管理平台,中间件管理平台汇聚业务信息,集群信息,告警阈值等上报到统一监控,统一监控根据上报采集目标进行周期性采集并将结果保存在时序数据库,再根据告警阈值与业务信息进行定向监控告警。中间件侧集群详情监控Dashboard则查询时序数据库进行监控值展示。
未来展望
1.统一内核
以消息中间为例,整体演进架构图如下,当然这也只是一个参考,起一个抛砖引玉的作用
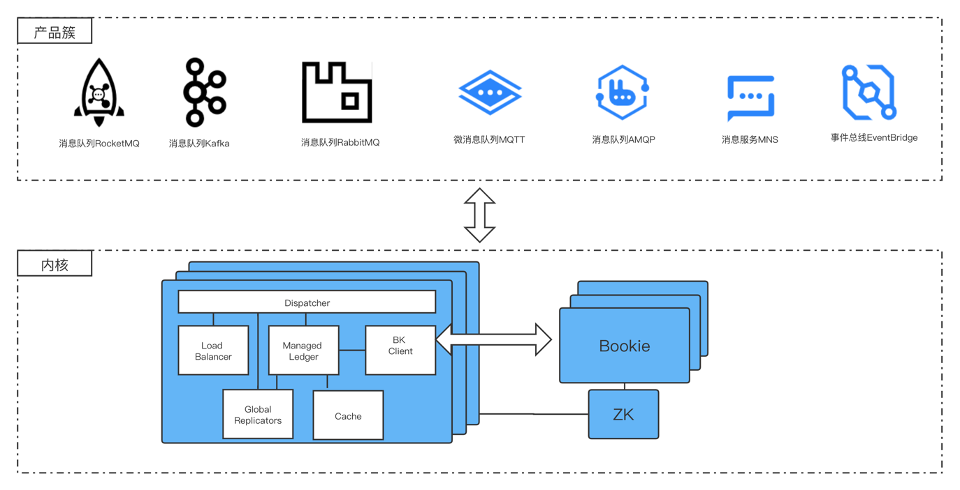
在协议层,我们支持各种主流消息队列协议,降低业务的接入成本,业务可以用自己熟悉的MQ的客户端进行消息发送消费,在内核侧我们可以用像Pulsar的天生支持存算分离,多租户,跨机房复制,函数计算的内核。
2.存算分离
对接公司的共享块存储与文件存储,大部分中间件都有写PageCache,若要使用共享块存储会在写PageCache需改成DriectIO,需做比较大的改造。因此在我们更倾向于共享文件存储,由存储侧保证数据的高可用,中间件侧通过减少副本数量提升中间件写入性能。
3.Serverless化
Serverless的核心理念是"按需",中间件在Serverless化主要是从以下维度进行按需的
l根据业务的规模进行自动化扩缩容实例规格、队列数、分片数等逻辑资源
l根据服务端负载自动化扩缩容计算,存储等物理机资源
逻辑资源按需扩缩容
在业务侧,更关心的中间件的实例提供的逻辑资源是否充足,比如申请的MQ的队列数量是否满足扩展性需求,ES的索引的分片是否满足读写性能。比如业务使用MQ根据分布的消费者的数量规模,对逻辑队列进行动态的调整,用户使用中间件完全不需进行容量评估。
物理资源按需扩缩容
在服务提供侧,则根据服务端实例的CPU,内存,磁盘等进行自动化扩容中间件实例的数量;比如在缩容ES的实例时直接通过exclude命令,将所在实例的分片迁移到剩下节点,这样就可以平滑缩容到该节点,像RocketMQ可能会比较麻烦,在缩容实例需在存储则支持多个CommitLog。
整合内部FaaS平台,特别是像定时作业调度,非常适合用Serverless用完即销毁。
4.Service Mesh化
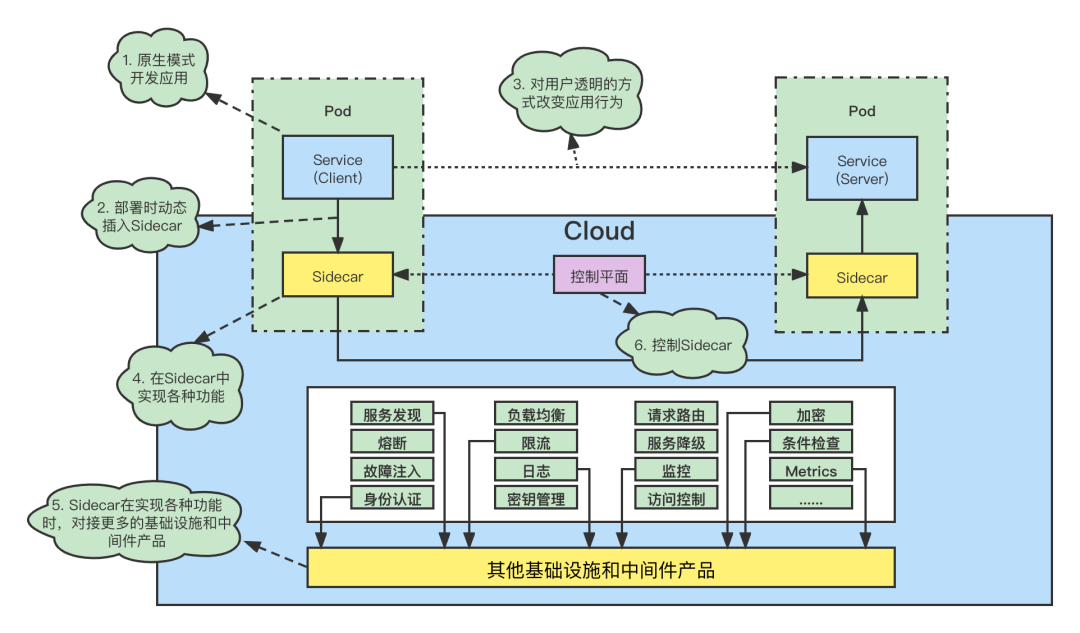
Service Mesh 主要是为了解决微服务架构的网络问题,将服务之间的通讯问题从业务进程中进行剥离,让业务方更加专注于自身的业务逻辑。中间件Mesh化将中间件富客户端能力下沉至 Sidecar ,将服务发现、服务治理、负载均衡、流量监控、加密等职责与业务逻辑隔离,在运行时完成透明组装,同时提供细粒度的灰度,全链路信息透传,故障注入和治理等能力。

往
期
推
荐
Linux内存管理中锁使用分析及典型优化案例总结
一文读懂高通GPU驱动渲染流程
2024年Arm最新处理器架构分析——X925和A725