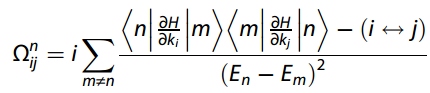1、问题背景
传统的训练Agent方法是在静态数据集上进行监督预训练,这种方式对于要求Agent能够自主的在动态环境中可进行复杂决策的能力存在不足。例如,要求Agent在web导航等动态设置中执行复杂决策。
现有的方式是用高质量数据进行微调来增强Agent在动态环境中的决策能力,但这往往会出现复合错误和有限的探测数据,最终导致结果不够理想。
2、提出方法
Agent Q 框架将蒙特卡洛树搜索(MCTS)和自我批评机制相结合,并采用DPO算法的非策略变体对Agent交互进行迭代微调。从而提升它们在复杂、多步推理任务中的泛化能力。
方法目标:设计了一个在动态交互环境中,允许智能体在自主经验和有限监督下进行改进的方法,采用的方式是将搜索和强化学习相结合的方式。
-
Web Agent
让Agent能够使用文档对象模型(DOM)去表示环境状态和活动空间,从而允许在复杂和现实的领域中进行部署。 -
强化学习用于LLM和Agent
(1)PPO算法由于其复杂性和需要大量来自模型的在线样本而具有挑战性,这存在潜在犯错的风险。
(2)Q-Learning和Q-transformer是为自回归Transformer模型设计的离线RL算法,因此可以在预先收集的数据集上安全地进行训练。但这两种方法还没有成功地应用到LLM上。虽然这些方法在token级别的马尔可夫决策过程已经成功地在步骤级别上制订了RL问题,并且这些想法最近已经扩展到了一般的设备控制Agent。但这些算法仍然具有很高的复杂性,并且需要辅助模型,例如值函数等。
因此,本文选用DPO算法,因为它简单且自然的适合基于树搜索的数据的分支。
采用DPO算法的动机:简单且自然的适合基于树搜索的数据的分支性质。
3、框架设计
1. Agent的构建
采用POMDP部分可观察马尔可夫决策过程来建模,POMDP = (O, S, A, T, R, 𝜇0, γ),其中O表示观测空间,S表示未观测的状态空间,A表示活动空间,T(st+1 | st, at)表示过度分布(在本例中是web浏览器的动态),R(s, a)是奖励函数,𝜇0是初始状态分布,γ是折现因子,将其设置为1。

-
POMDP是最适合建模web交互的框架,原因如下:(1)智能体在不熟悉的新环境需要探索才能定位任务目标,这与任务推理的元强化学习一致。(2)真实的web环境是动态的,每次执行Agent时都需要观察当前状态。
-
观测空间O:
由用户提供的指令或者浏览器页面信息组成。 -
活动空间A:
基于Agent历史记录h_t的组合,采用的基本方法是带有一些组建和初步规划步骤的ReAct(PlanReAct)。包含以下操作:- 规划(第一个动作):根据初始观察采用LLM规划步骤,生成一个顺序执行步骤规划 a1_plan。
- 推理(之后动作):然后,所有的动作都由一个思考动作组成,构成推理步骤 a1_tht。
- 环境活动:生成和浏览器的交互指令,这由一组有限的选项操作选项组成 a1_env。例如:CLICK、SCROLL、TYPE。
- 解释活动:对环境交互作用产生后,会提示模型对其活动进行解释 a1_expl。
在优化模型时,会考虑上述过程的联合似然函数。
对于第一步的操作,基于初始设置的历史信息h_1,结合规划、思考、环境活动和解释活动的似然函数:

对于后续的操作,删除了规划的似然函数,规划只在第一步活动中被使用,后续都是用思考进行动作组成。

- Agent状态空间S:
Web当前的状态,这一部分是不可观测的。由于LLM的上下文窗口有限,使用完整的Web轨迹(HTML内容、活动动作等)不切实际,因此采用h_t = (a_1, …, a_t-1, o_t)来表示,即所有的历史活动操作和当前浏览器的状态。之前构建的思考和解释活动会作为Agent的内在独白,来充分表示其状态和意图,记录的历史活动更加紧凑,更为连贯。
2. 根据反馈微调语言模型
采用DPO进行训练

From 𝑟 to 𝑞*: Your language model is secretly a q-function, 2024.中将该算法扩展到具有轨迹偏好的多回合设置中,本论文直接利用这一目标:

算法实际部署的一个瓶颈是在优化过程中需要参考模型𝜋_ref,这需要更多的计算资源。相反,在论文中,使用了off-policy重播缓冲区稍微修改了算法,该缓冲区聚合了轨迹数据以及生成动作的可能性。在优化步骤中,作者在数据生成(参考)密度下对轨迹元组和相应的似然进行采样,从而消除了对单独参考模型的需要。
3、Agent搜索模块
基于DPO进行监督训练具有改进意义,但论文在只使用DPO训练后,发现模型的错误大部分会出现在因贪婪搜索而陷入局部最优解,因此想到引入蒙特卡洛树搜索MCTS去解决这个问题,赋予Agent额外搜索的能力。
-
动作空间
与围棋等场景不同,Web环境中的动作空间是开放式和可变的,因此采用Base模型作为动作-建议分布,并且在每个节点(网页)上采样固定数量K个可能的动作。之后,再遍历下一个网页。

-
动作选择
动作选择阶段采用MCTS的上置信界限(UCB1)。使用base模型为每个动作生成一个反馈分数,然后要求base模型去对生成的动作进行排序。
论文中为多次迭代查询反馈模型,每次从列表中删除上一次迭代中选择的最佳操作,直到拥有所有操作的完整排名。然后,根据UCB1公式,选择要探索动作:

其中 N(h𝑡) 是状态 h𝑡 的访问频率,C_exp是一个探索常数。
- 扩展和反向传播
基于之前的部分,在浏览器环境中中选择并执行了一个动作后,达到一个新的节点。从选择的状态节点的轨迹开始,使用当前策略的展开轨迹,直至达到一个叶子节点。最后会返回一个奖励R,如果Agent执行成功,则R=1,否则为0。然后,会通过从叶子节点到根节点自下而上更新每个节点的值来反向传播这个奖励,公式如下所示:

其中, Q ( h t , a t i ) Q(h_t, a^i_t) Q(ht,ati) 是通过状态 h_t 来选择动作的 a_t 得到的平均奖励值, N ( h t , a t i ) N(h_t, a^i_t) N(ht,ati) 是搜索过程中访问该状态操作对的次数。通过反向传播,会更新这两个值。
- 用强化学习改善zero-shot性能
论文中将生成一个偏好对的数据集,其中包含{h𝑡,a𝑤𝑡,a𝑙𝑡},并确保这两个动作都被探索过。论文中在节点级别上优化DPO目标公式:

状态-行为值作为平均值:

其中, Q ~ ( h t , a t i ) \tilde{Q}(h_t, a^i_t) Q~(ht,ati)是通过MCTS反向传播的经验估计值, Q ^ ( h t , a t i ) \hat{Q}(h_t, a^i_t) Q^(ht,ati)是过程监督AI模型基于动作a_t排序的估计值。然后,在高于某个阈值 ∣ Q ( h t , a ω ) − Q ( h t , a t l ) ∣ ≥ θ t h r e s h o l d |Q(h_t, a^{\omega}) - Q(h_t, a_t^l)| ≥ \theta_{threshold} ∣Q(ht,aω)−Q(ht,atl)∣≥θthreshold 的动作对上作为偏好。
* MCTS引导DPO流程

4、实验设置
评测集:
(1)WebShop基准,一个模拟的电子商务平台。有一组12087个与定义任务,论文中将其分为11000个任务的训练集,用于Agent微调,1087个任务,用于zero-shot评估。
(2)OpenTable,一个现实世界的预订网站。
基座模型:xLAM-v0.1-r(基于Mixtral-8x7B-Instruct-v0.1模型在Agent应用数据上微调的模型)、Llama3-70B
对比方法:RFT强化学习微调、DPO、人类平均水平、人类专家水平
实验数据:WebShop:预订酒店数据集。OpenTable:相比于WebShop更为复杂, 牵扯到页面跳转等复杂操作。
5、实验效果
(1)WebShop

本次实验所有的基座模型都是xLAM-v0.1-r,采用DPO算法进行微调后效果较为明显,从28.6%到40.6%。DPO+BeamSearch对于DPO后没有明显的提升效果。采用AgentQ后,从28.6%到41.5%。仅使用MCTS效果甚至超过了微调的方式,到达了48.4%,说明Web交互环境中对于动作的选择是否能考虑到全局最优策略是对性能的提升具有很大帮助。当AgentQ和MCTS进行结合后,超过了人类平均水平(50%)达到了50.5%,但低于专家水平59.6%。
(2)OpenTable

使用GPT-4-V作为评估期,根据最终观察和动作历史对Agent的性能提供反馈信息,得到成功分数。模型将得到一个浓缩的轨迹执行历史和最终状态的屏幕截图,成功指标是0或1。

在真实网站环境中的实验结果中,xLAM模型成功率为0%,很大程度是因为在没有遵循用于实时网站的说明。上一个试验数据集WebShop由于简化了网站环境,而xLAM的训练集中可能含有部分相关数据,导致判定影响。
之后,均采用LlaMA-3 70B作为基座模型。RFT方法中使用了600个成功的操作轨迹进行了一轮RFT训练,成功率从18.6%到达67.2%。使用DPO方法成功率从18.6%到71.8%。采用AgentQ方式达到了81.7%。采用RFT+MCTS达到84.3%,这里注意到一点,这个试验数据集中中没有采用只用MCTS的方式,可能只用该方式对于这种真实环境下效果一般,而导致一般的原因则可能出现在更需要一些规划、动作和评判等推理能力的支持。当采用AgentQ+MCTS方法时候可以看出提升最明显, 达到95.4%。比只有AgentQ高出13.7%,比RFT+MCTS高出11.1%。
文中最后的探讨:
1、设计推理能力:Web Agent的核心挑战是推理能力弱,从而限制了agent的探索和搜索策略。采用单独的评论家模型对过程进行监督,并让其对可能的agent动作进行排序。
2、选择搜索算法:采用MCTS的原因是因为该方法在数学和代码推理任务重取得了成功,但在实时环境下可能会存在一些交互风险,例如:在网页上执行一些不可控的操作。对于未来探索更多的搜索算法很有意义,目前有一种前沿的方式是用元强化学习直接学习在推理任务中进行最佳搜索和探索。
3、zero-shot和搜索结果之间的差异:Large language monkeys: Scaling inference compute with repeated sampling 和 Scaling llm test-time compute optimally can be more effective than scaling model parameters 研究了这两个差异之间的权衡和影响。
4、线上的安全和交互:Agent在在线实时任务时,如果犯错,可能会造成难以修复或者你转的错误,特别是对安全至关重要的在线交易等产经。这限制了AgentQ可部署的应用场景,可能需要额外的安全评论家模型和人类的简单干预设置。