前言
随着"信创"的东风吹遍大江南北,各家公司都开始了国产化的适配道路。zStorage团队当然也没有缺席,去年我们适配了华为的鲲鹏架构,整体性能水平达到了Intel架构的70%以上。今年我们开始着力于海光CPU架构的适配。与鲲鹏架构相比,海光的适配难度相对更小。因为海光也是x86架构,海光CPU通过与AMD的合作,获得了ZEN1架构和X86指令集的永久使用权,并且在此基础上开发了7、5、3系列处理器,分别定位于高、中、低档服务器市场。所以zStorage对于海光CPU架构的适配,主要问题不在于编译以及基本功能上,而是在于性能调优。本文打算记录zStorage在海光服务器上的性能调优过程中遇到的问题和解决方法。

调优过程
解决不能正常运行的问题
虽说海光也是x86架构,不过我们所使用的这套服务器的CPU是Hygon C86 7360 24-core Processor,并不支持AVX512等指令集。所以我们首先在海光服务器上重新编译了zStorage,解决了指令集不兼容的问题。此外还存在一个比较大的软件部署上的问题。在Intel服务器上,zStorage支持1个或者2个NUMA nodes的情况,并且2 NUMA nodes作为标准部署环境。其中ChunkServer(简称CS)运行在NUMA node 0上,FrontEnd(简称FE)运行在NUMA node 1上,这样按照NUMA亲和性部署,zStorage具有最佳的性能表现。(注:CS和FE是IO路径上的两个主要进程,直接关系到IO的性能。)
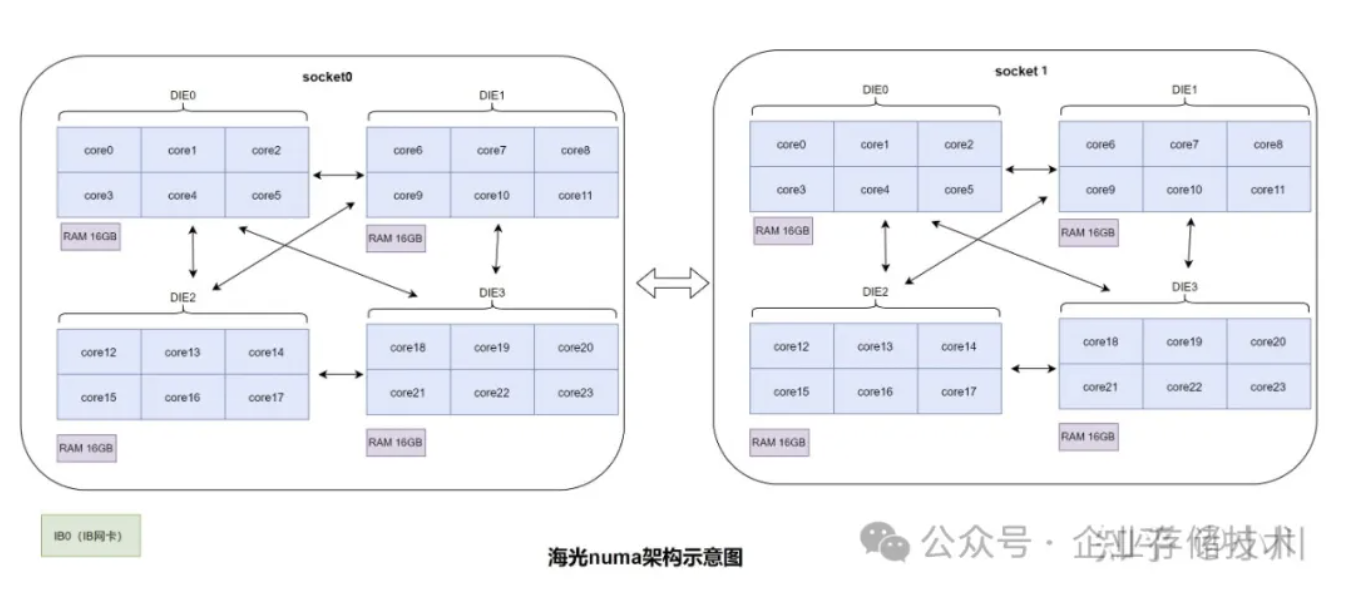
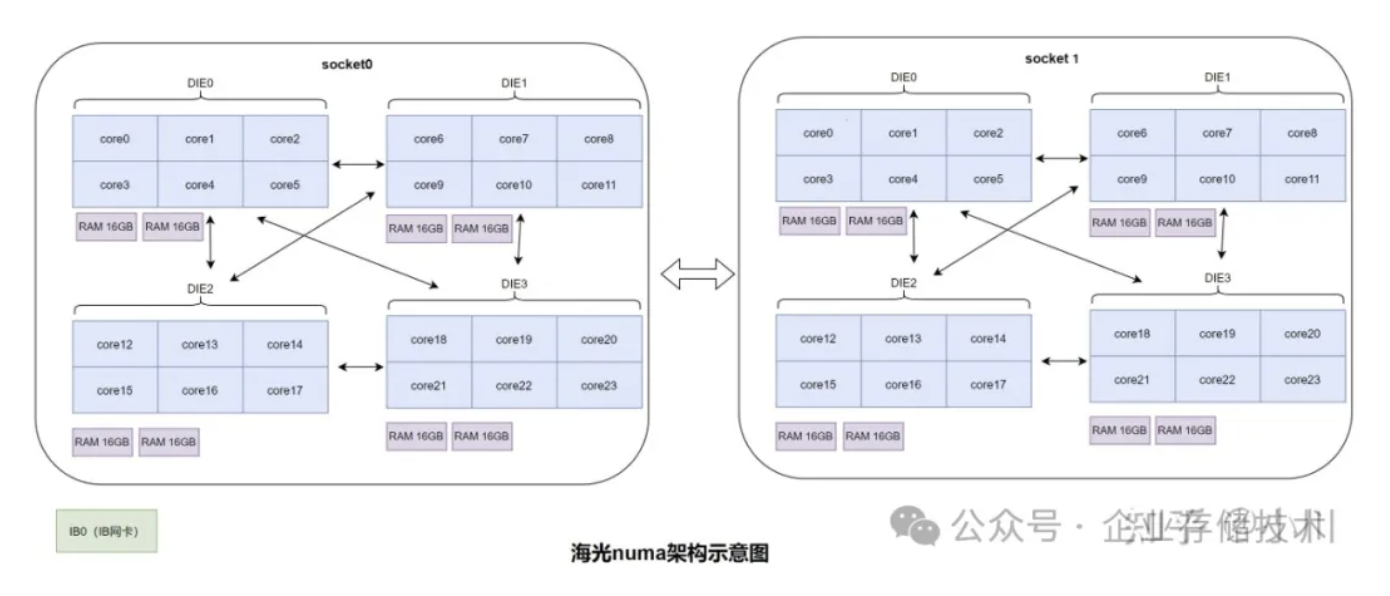
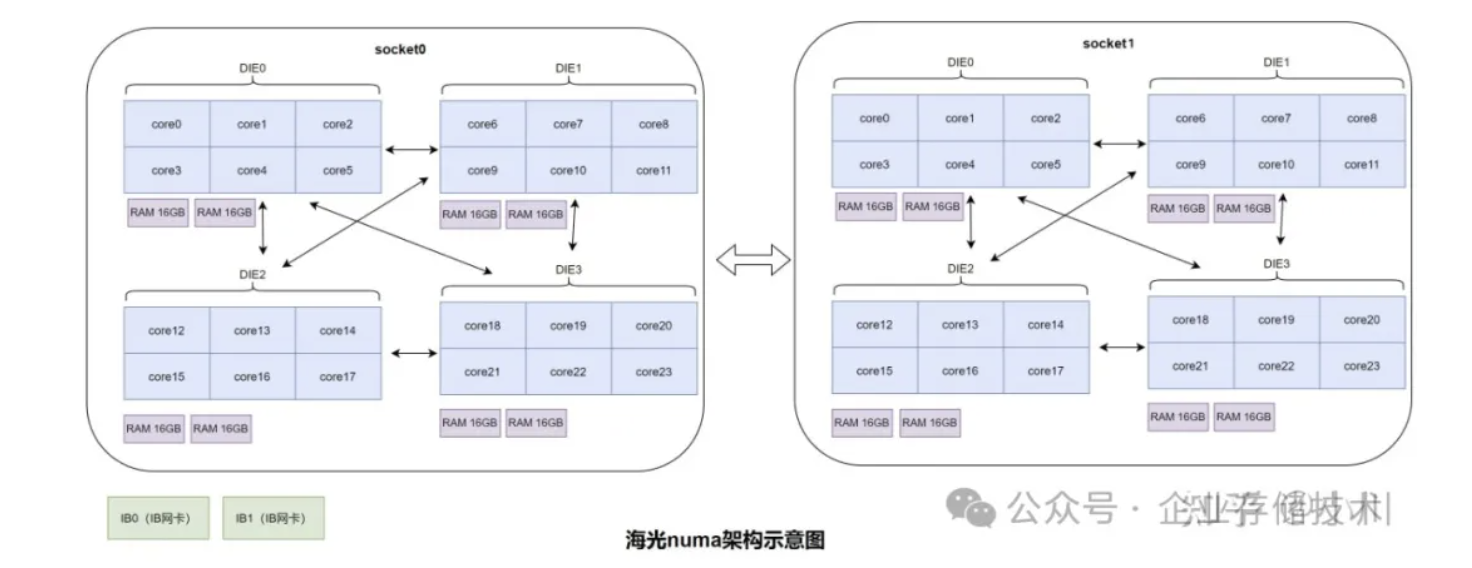
海光服务器上有两个socket,分别插了一个CPU。每个socket内部又被分为了4个DIE,所以在操作系统看来一共是8个NUMA nodes。每个NUMA node(或DIE)上有1根16GB内存。zStorage默认的2 NUMA nodes的部署方式,只能利用两个NUMA nodes的内存,由于不能充分使用多NUMA nodes的内存,达不到最佳性能部署的要求。
那么在不改软件代码的情况下,要么增加至16根内存条,这样可以达到开启2 NUMA nodes模式的条件;要么关闭NUMA模式,将所有资源聚合为单个NUMA node。为了能够快速将zStorage运行起来,关闭NUMA,使用单个NUMA node是最快的选择。
单NUMA node的性能问题
将多NUMA nodes的资源聚合为单个NUMA node的方式存在天然的性能问题。通过修改BIOS设置关闭NUMA模式,并开启内存交织访问,这种模式下,操作系统只会看见一个NUMA node。实际上会出现任何一个CPU核访问内存时,不会只访问本DIE之内的内存,而是会跨越DIE和socket交叉访问内存。这种模式下,标准性能测试(4k 7:3随机混合读写),仅为Intel架构25%的性能水平。所以还是得寻求多NUMA nodes的支持,以达到最优性能。
内存带宽基准性能测试
跨越NUMA node访问内存,性能不友好,但这仅是一个比较模糊的结论,不直观。到底跨越NUMA node性能会差到什么程度,确是没有一个定量的参考。因此,我在Intel服务器上进行了一个内存带宽的基准性能测试。(详细解读,请参考:《分布式存储性能调优 - sysbench内存带宽测试详解》《》9586190)
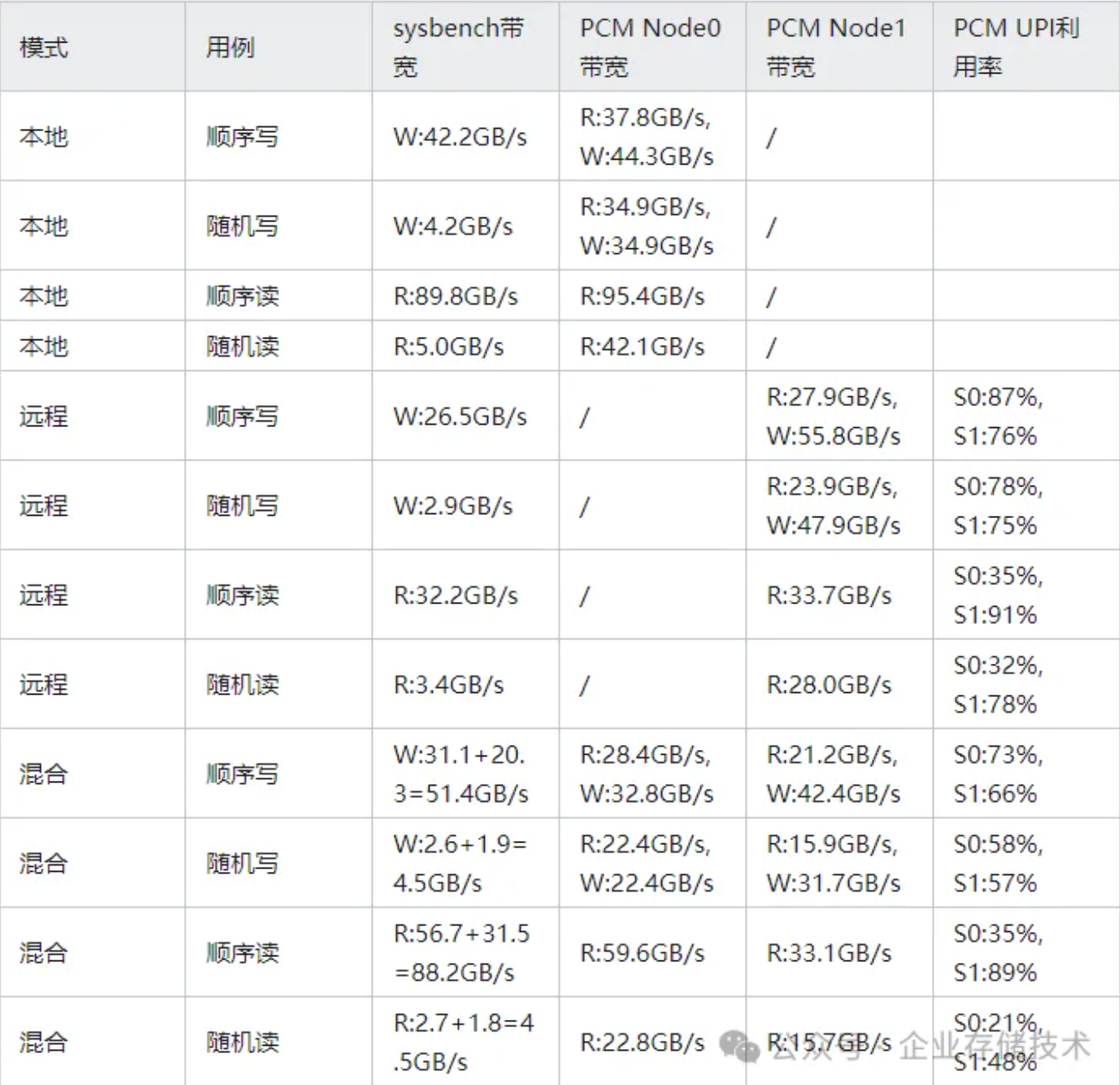
有了这个数据之后,对于内存带宽的真实表现,算是有了一个定量的参考。后续在海光服务器上,如果怀疑是内存带宽问题,那么可以用同样的方法,做对比测试验证。
增加内存条,开启2 NUMA nodes
在适配多NUMA nodes之前,了解zStorage在海光服务器上的最佳性能是有必要的。因此,通过将每个存储节点再增加8根内存条,然后在BIOS中设置内存在DIE间交织,即可开启2 NUMA nodes模式。这种模式下,CPU核会在socket内的4个DIE间交叉访问内存,但是不会跨越socket访问内存。简单验证了下内存带宽性能,相比Intel的测试数据,没有明显的差距,内存方面的瓶颈认为已经排除了。
实验1:ChunkServer(简称CS)绑定到NUMA node 0,使用20个逻辑核(10个物理核);FrontEnd(简称FE)绑定到NUMA node 1,使用8个逻辑核(4个物理核)。按照这个方式测试了基准性能,只有intel架构的33%,未达到预期。
实验2:将CS和FE都绑定到NUMA node 0上,CS使用17个核心,FE使用7个核心,共使用24个物理核。这块CPU上有24个物理核,48个逻辑核,在选择这24个逻辑核的时候,从每个物理核上挑一个逻辑核,确保充分发挥出CPU的性能。这种绑核方式IOPS达到了intel架构的48%。
这两个实验说明zStorage在海光服务器上,使用两个socket存在性能问题,原因暂时未知。(这里没有直接使用全部的逻辑核心,是为了保证性能测试和标准20+8的绑核模式一致。)
模块时延分析,增加IB卡
利用zStorage内置的时延分析工具(z_trace)分析模块时延,发现主要的瓶颈在于网络通信RPC模块。下发IO负载的同时,使用IB工具测试IB网络的时延,发现时延很高,说明确实是网络达到了瓶颈。停掉zStorage的进程,单独测试IB卡,发现双向带宽只有11GB/s,而同样的测试在Intel服务器上可以达到22GB/s。
继续分析发现海光服务器的PCI插槽带宽相比Intel要差。所以下一步继续加硬件,每个节点增加一张IB卡。增加IB卡以后,效果立竿见影,IOPS达到了Intel架构的62%,这个数据也不是那么难看了,毕竟国产服务器还得给它一些时间成长。
62%相比于刚开始的25%,确实看起来舒服多了。通过增加内存条来提升性能,至少可以作为一个保底方案。但是加内存的方式,性价比不那么高。最具性价比的方法是zStorage可以有效利用8个NUMA nodes的内存和CPU,达到理想的性能。
多NUMA nodes内存分配适配问题
关于多NUMA nodes适配的问题,适配的目标是CS以及FE可以从多个NUMA nodes分配内存。关于内存分配不兼容多NUMA nodes的模块,主要有两个:1)PAGE模块,即以4KB为单位的一个内存池;2)ZRPC通信模块,即存储节点之间RPC通信模块。这两个模块的改造难度不算大,两个星期之内我们便完成了改造。(这里不详细介绍改了些什么问题,因为改造的内容与性能调优关系不大。)改造之后,zStorage可以支持2个以上的NUMA nodes的情况,当然海光的8 NUMA nodes的情况也支持。
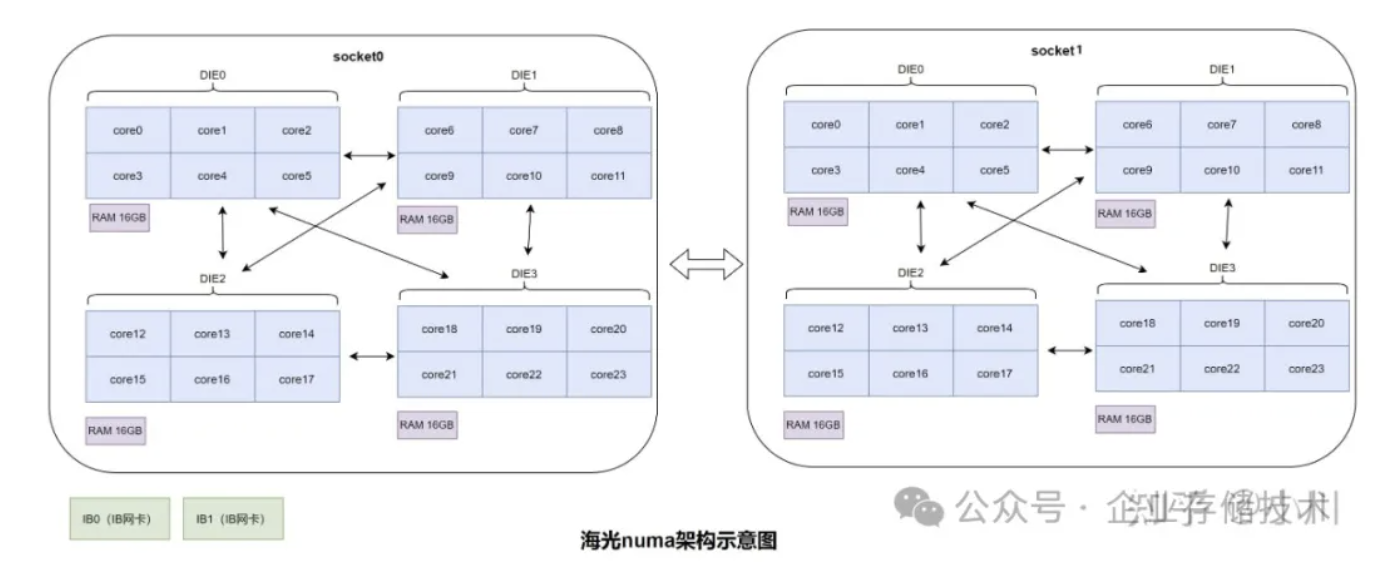
多NUMA nodes的硬件架构如上,保留两张IB卡,并还原到8根内存条。(注:为了链路冗余,使用双IB卡是标准做法,所以这里没有还原为单张IB卡。)
多numa nodes部署性能测试
解决掉上述问题以后,便进入了正题,验证多NUMA nodes适配以后的性能如何。海光服务器上有两个socket,分别插了一个CPU。每个socket内部又被分为了4个DIE,所以在操作系统看来一共是8个NUMA nodes。CPU核访问本DIE的内存性能最好,其次是访问本socket的内存性能,最差的是访问远程socket的内存性能。
针对8个NUMA nodes,zStorage是这样部署的:CS内存和CPU都绑定到Socket 0上的4个NUMA nodes;FE内存和CPU都绑定到Socket 1上的前2个NUMA nodes上。按照这个部署方式进行了基准性能测试,达到了intel架构的33%。相比于单NUMA node为25%,看起来有一些进步,但仍然不够理想。
DPDK最大NUMA nodes数量问题
通过观察各个NUMA nodes上的内存使用情况,发现了一个比较重要的问题:FE的内存并未从指定的两个NUMA nodes上分配,而是从CS所在的NUMA nodes进行了分配。这就意味着FE的内存访问效率处于最差的一种情况,不仅仅是跨越socket做内存访问,而且还会和CS竞争内存带宽资源。
通过分析DPDK源代码,我们发现RTE_MAX_NUMA_NODES在我们的代码环境被设置为4。DPDK在分配内存的时候,例如指定的NUMA node为5,由于RTE_MAX_NUMA_NODES为4,所以找不到NUMA node 5的内存池。因此,DPDK便从前4个NUMA nodes上去分配内存。这导致了FE并未从指定的NUMA node上分配内存的情况。DPDK处理这段逻辑的关键代码如图所示。
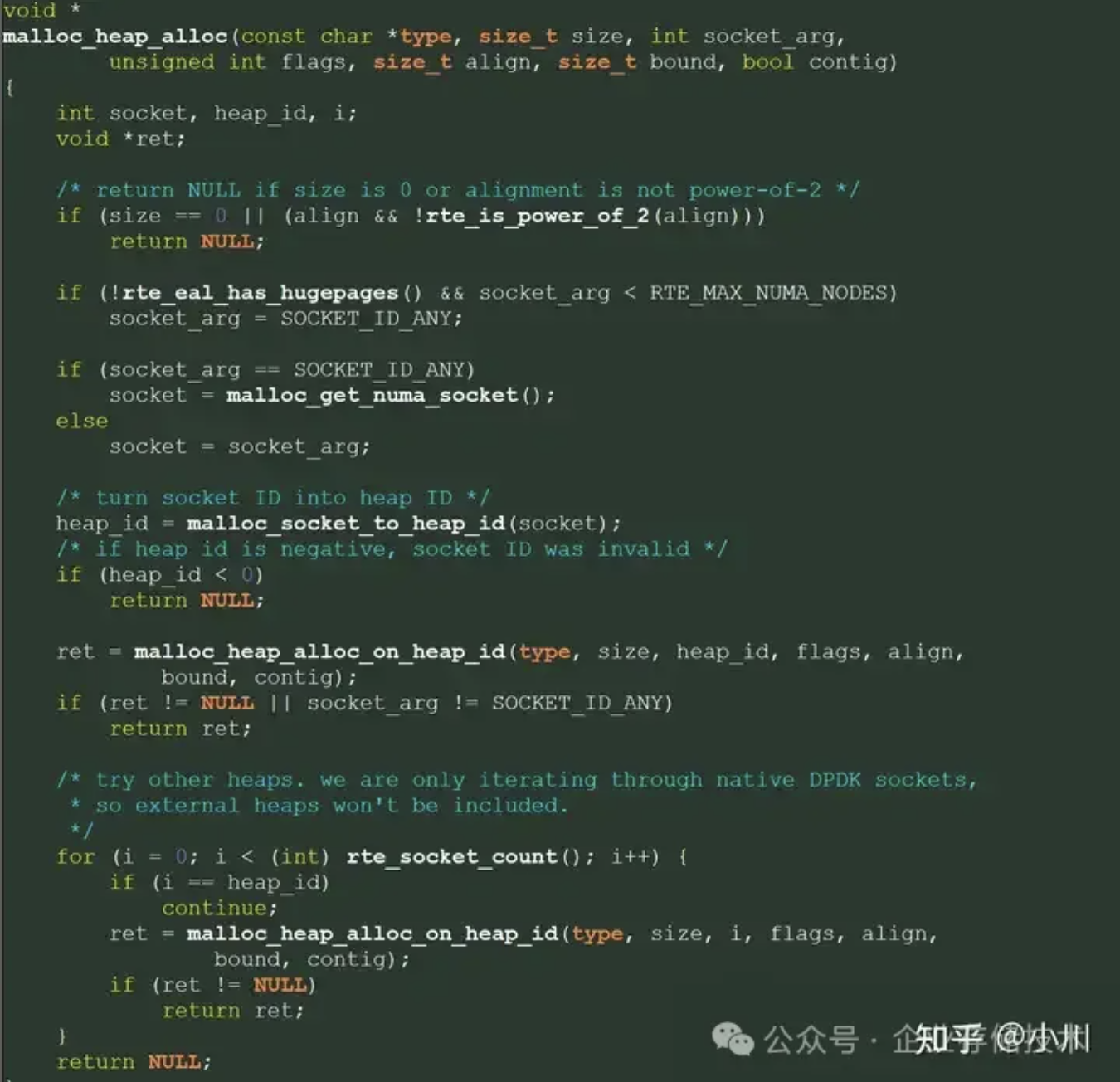
解决这个问题很简单,只需要将这个宏改为8即可。解决问题后,再次编译部署zStorage,FE的内存正常地从4-5号(NUMA node编号从0开始)NUMA nodes上分配了。再次进行基准性能测试,IOPS达到了intel架构的41%。
这个问题也是前面提到的使用两个socket部署性能问题的主要原因之一。
多NUMA nodes的优化绑核方式
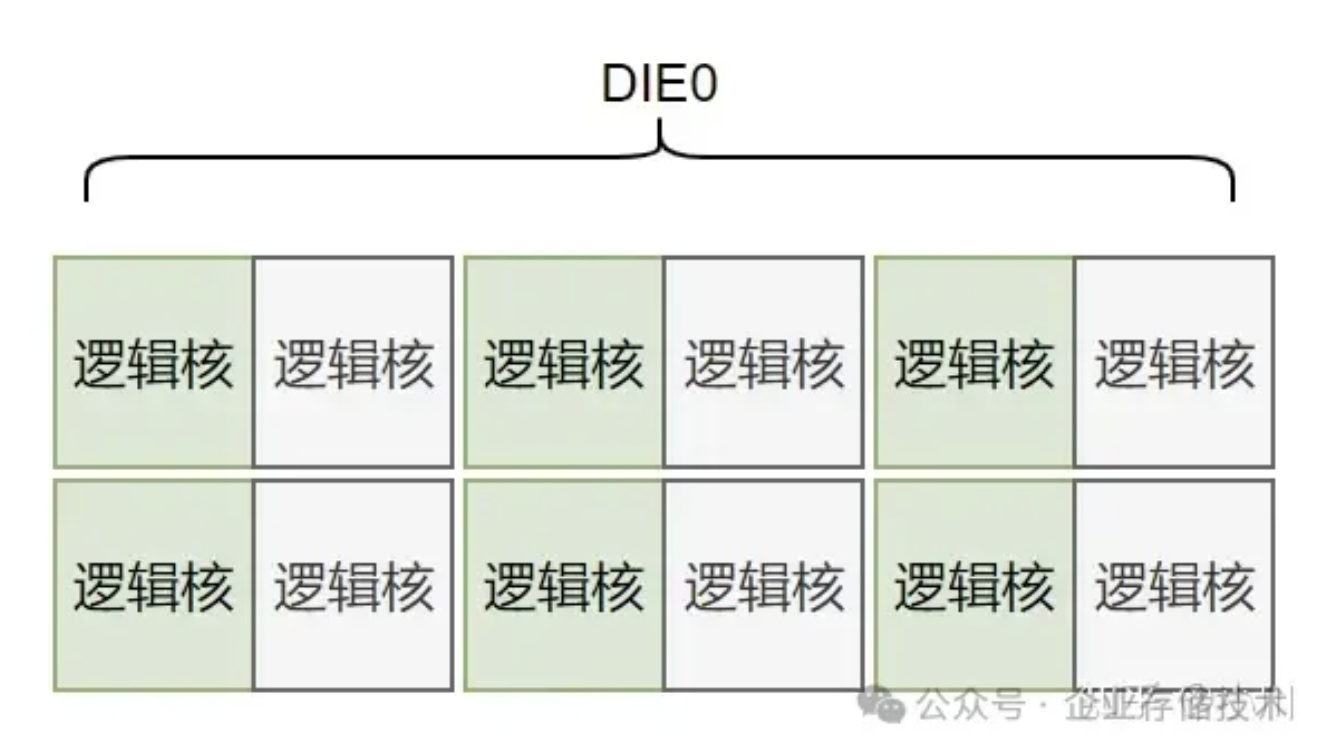
优化绑核方式,即从每个物理核上选一个逻辑核(图中绿色所示),使得CS和FE达到直接使用物理核的效果。这种优化绑核方式,IOPS达到了intel架构的53%。虽然相比于16根内存条,2 NUMA nodes的模式还是要差一些,但相比于开始的25%来说提升已经很大了。这种方式已经非常具有性价比了。(为什么不关闭超线程呢?因为BIOS开启性能模式后,无法关闭超线程。)
待继续完成的优化
本文介绍了zStorage在海光架构上第一阶段的优化效果,后续还会继续第二阶段的优化,届时会将优化的经验和思路分享出来。
第二阶段的优化,可能包括以下这两个主要的点:
1)CPU和内存访问的亲和性问题,即尽量做到不跨DIE访问内存。
2)FE的内存分配在NUMA nodes之间均衡的问题等。
结语
此次海光服务器上的性能调优,从最低为intel架构的25%达到了最高的62%,提升幅度很大。主要的问题在于:
1)PCI插槽带宽问题,导致的IB卡带宽问题;
2)内存条不足,无法开启2 NUMA nodes模式;
3)DPDK最大NUMA nodes限制问题,导致内存带宽竞争问题;
4)CPU内存访问的亲和性问题。