近年来,基于学习的高光谱图像(HSI)压缩模型的开发引起了大量关注。现有的模型主要使用卷积滤波器,仅捕捉局部依赖性。
此外,它们通常会带来高昂的训练成本,并具有较大的计算复杂性。
为了解决这些问题,本文提出了一种基于 Transformer 的自编码器HyPerspectral Compression Transformer ( HyCoT),用于像素级HSI压缩。
此外,作者还引入了一种高效的训练策略,以加速训练过程。
在HySpecNet-11k数据集上的实验结果表明,HyCoT在各种压缩比下,相对于最先进的技术,超过了的性能提升,同时显著降低了计算要求。
作者的代码和预训练权重已在https://git.tu-berlin.de/rsim/hycot上公开发布。
1 Introduction
光谱传感器能获取高光谱分辨率图像,产生数百个观测通道的数据。这种广泛的 spectral 信息允许对材料的详细分析和区分,以及基于它们的光谱图案。然而,在 hyperspectral 图像(HSI)中的大量光谱带,如光谱传感器产生的海量数据。虽然光谱数据档案的体积正在不断增长,但传输带宽和存储空间是昂贵的且有限的。为了处理这个问题的方法是开发用于高效传输和存储光谱数据的光谱信息压缩方法。
通常,光谱信息压缩方法可以分为两类:i)传统方法;和ii)基于学习的方法。
大多数传统方法是基于变换编码与量化的组合以及熵编码。相反,基于学习的方法通过训练一个人工神经网络(ANN)来自动提取代表特征,通过连续降采样操作来减少潜在空间的维度。
最近的研究表明,与传统压缩方法相比,基于学习的 spectral information 压缩方法在更高的压缩比率(CRs)下可以保持重建质量[9]。因此,基于学习的光谱信息压缩方法的发展引起了广泛关注。该领域的最新进展是由卷积自动编码器(CAE)构成的。在[4]中提出的 1D-Convolutional Autoencoder (1D-CAE) 模型通过堆叠多个 1D 卷积块,池化层和漏斗型线性激活函数(LeakyReLU)来实现光谱内容的压缩。虽然这种方法可以实现高质量的重建,但是池化层限制了可实现的最大 CRs 为 2^n。另一种限制是,随着 CRs 的增加,由于网络架构更深,计算复杂性也在增加。与 [4] 不同,为了实现空间压缩,通过 2D 卷积滤波器的空间冗余信息压缩网络(SSCNet)[5] 提出。在 SSCNet 中通过 2D 最大池化实现压缩,同时通过瓶 Neck 分的潜在通道来适应最终的 CR。与 SSCNet 相比,HyCoT 在保持重建质量的同时,通过使用轻量级解码器实现了更高的 CR 和训练成本的降低。
值得注意的是,深度学习模型需要大型的训练集来有效地优化其参数。一方面,在大型训练集上训练深度学习模型可以使它们在训练后很好地泛化。另一方面,训练通常需要数百个周期才能使模型权重收敛,从而导致高昂的训练成本。通过在多个 GPU 上并行化训练,可以减少训练时间,但是能源消耗和硬件需求仍然是限制因素。
为了解决这些问题,作者提出了一种名为 HyCoT 的基于 Transformer 的自动编码器用于光谱信息的压缩。HyCoT 借助了长程光谱依赖关系进行潜在空间的编码。HyCoT 为快速重建采用了轻量级解码器。HyCoT 能加速训练速度,同时保持重建质量,作者提出了一个有效的训练策略,通过减少训练集大小来加速训练速度。实验证明,HyCoT 在多种 CRs 下实现了更高的重建质量,并且在训练成本和计算复杂性方面较现有先进方法有明显改善。
2 Methodology
假设X是一个H×W×C的高斯束,其中H表示图像高度,W表示图像宽度,C表示光谱带数量。有损的高斯束压缩的目的是将X编码到一个无相关潜在空间Y中,该空间在重建侧后最小程度上的扰动d,d:X×表示的范围内,其中表示向量的转置。
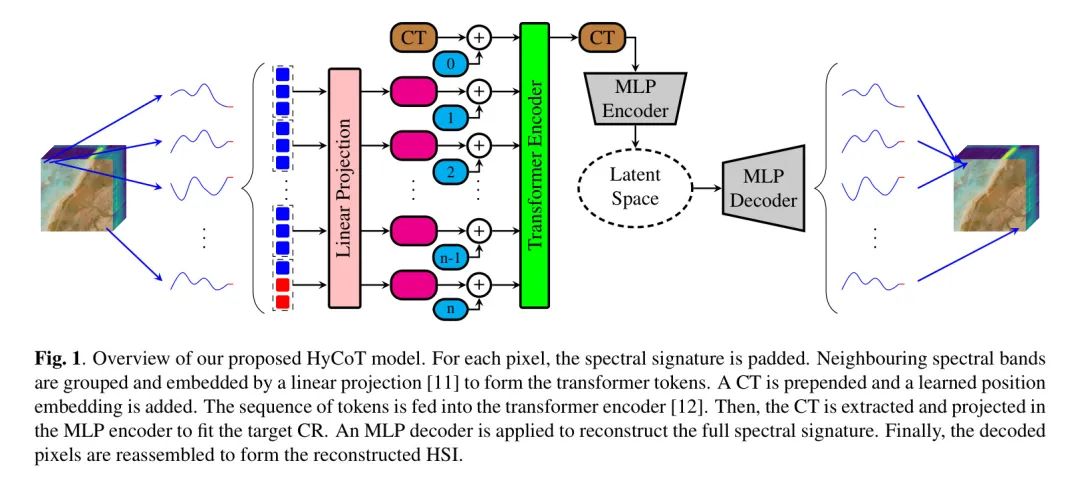
为了有效地压缩X,作者提出了HyCoT。HyCoT是一个基于学习的HSI压缩模型,它使用SpectralFormer[11]作为编码器端的特征提取器,并在解码器端使用轻量级的多层感知机(MLP)进行有损重建。作者的模型如图1所示。在以下子节中,作者将全面解释提出的模型。
请注意,由于我是基于文本的人工智能助手,我无法直接绘制图像或提供Markdown公式,但我会尽量保持原文的清晰度和可读性。
HyCoT Encoder
HyCoT编码器 作为光谱特征提取的基础,使用了SpectralFormer [11] 作为光谱特征提取的 Backbone 。通过在压缩标记(CT)内部以transformer块[12]聚合长程光谱依存性,然后使用MLP将CT映射到潜在空间以拟合所需的目标CR。
具体而言,每个像素在中单独处理。首先,通过非重叠地聚类相邻的光谱带组成了光谱组,其中表示组深。为了使组内光谱带的数量能够整除,从增加到,形成,其中。光谱组被线性投影到嵌入维度上,使用一个可学习的矩阵。得到的嵌入向量(即所谓的标记)被定义为。作者提出在前面附加一个可学习的CT,它也被transformer编码器编码,捕捉像素的光谱信息。因此,每个像素的标记总数为。随后,添加一个学习的位标嵌入到标记中的所有位置嵌入上,以保留光谱组的相对位置信息。标记序列随后被输入到堆叠个transformer块的transformer编码器中。在每个transformer块 中,应用程序串行多头自注意力(MSA)[12],然后是MLP [12]。对于这两种,都使用残差连接 [13],并采用层正则化(LN) [14]:
这里MSA是自注意力(SA)的扩展,同时运行k个自注意力操作(头),并将它们连接的输出[12]投影:
. \tag{3}$
SA 计算每个标记 tokens 上的加权和,同时基于 Query 和键 之间的一对相似性,计算注意力权重 [12]:
(5)
CT 被提取并发送到 MLP 编码器,该编码器适配潜在空间通道 到适合目标的 CR[12]:
$HyCoT 仅压缩光谱内容,因此 CR 可以根据以下简化公式表示:
\text{CR}=\frac{C}{\Gamma}. \tag{7}$
MLP 编码器首先应用了一个线性变换,将条件的图卷积(CT)转换为具有嵌入维数 的隐藏维数 ,然后通过一个 LeakyReLU 引入非线性。接下来,另一个线性变换适应了条件响应(CR),通过 输出特征。最后,使用 sigmoid 激活函数来重新缩放潜在空间。
HyCoT Decoder
隐藏空间仅包含每个像素的少数多个隐藏通道。因此,对于实时应用或低延迟的数据档案频繁访问,只需使用非线性激活函数的一个简单前馈ANN就足够实现定性重建。这使得解码过程在解码器端实现快速、轻量,且仅由一个包含一个隐藏维度的简单MLP(多层感知机)组成,该MLP将隐藏通道维度的上采样回HSI输入频段的。
在最初的层后使用漏斗ReLU,隐藏层后使用 sigmoid 函数来调整数据以使其归一化到-范围内。最后,解码得到的像素被重新组装形成还原后的图像。因此,HyCoT解码器既轻便又具有学术规范,只需要简单地使用MLP,通过上采样将隐藏通道维度还原到HSI输入频段。
Efficient Training Strategy
通过空中和空间 hyperspectral 成像技术测量的数据在局部空间区域表现出像素之间的光谱相似性[15]。这种相似性对于学习基于像素的压缩模型,包括 HyCoT 来说,提供了冗余信息。作者的目标是通过只考虑 HSI 内的像素子集来减少同一 HSI 中的训练样本。为此,作者提出了一种在训练 HSI 内进行随机像素选择策略,以有效地降低训练成本。
3 Experimental Results
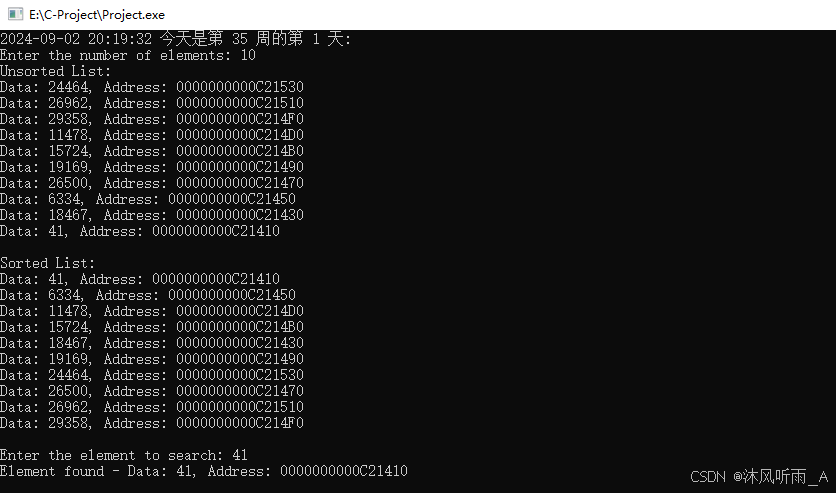
实验是在基于EnMAP卫星[16]捕获的个(每个包含像素和个波段,地面样本距离为米)构建的大规模高光谱基准数据集HySpecNet-11k[10]上进行的。HySpecNet-11k包括个不重叠的HSIs,每个HSI具有像素和个波段,地面样本距离为米。作者的代码基于基于CompressAI[17]框架的PyTorch实现。在单个NVIDIA A100 SXM4 80 GB GPU上进行了训练运行。作者使用Adam优化器[18]并设置了学习率。作者对每个实验使用均方误差(MSE)作为损失函数训练HyCoT直到在验证集上收敛,每种实验达到了收敛,需要经过个epochs。在HyCoT Transformer 编码器中,作者采用了,和,这与[11]中建议的值相同。作者实证地固定了组深度和编码器与解码器中的隐藏MLP维度。
Analysis of Training Efficiency
在本小节中,作者分析了所提出的训练数据约简方法的效率。为此,作者将第2.3节中的固定为最佳平衡训练成本和重建质量之间的数值,即。与训练集不同,测试集保持不变,以实现可比结果。
为降低重新训练HyCoT每个子集的计算成本,作者采用了新的HySpecNet-11k拆分,称为小拆分。小拆分是HySpecNet-11k的压缩版本,作者推荐用于超参数调整。为了获得小拆分,作者遵循[10],将数据集随机分为i)包括%的HSIs的训练集,ii)包括%的HSIs的验证集,iii)包括%的HSIs的测试集。但是,小拆分只使用了个HSIs,通过从创建HySpecNet-11k使用的每个 tile 中提取每个的中心HSI。这种选择策略将数据集大小减少了超过倍,同时保持了HySpecNet-11k的全局多样性(11,483个HSIs)。
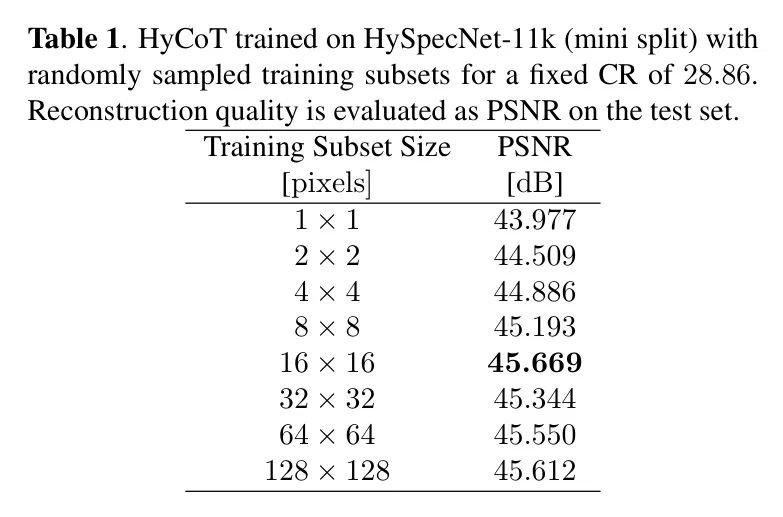
表1显示了使用不同大小随机取样的像素子集(参见第2.3节)在HySpecNet-11k小拆分上训练HyCoT以达到最高考虑的CR 的结果。对于这个实验,HyCoT模型进行了个epoch,学习率的训练,该表显示,减少训练像素子集时可以保持重建质量。实际上,对于的训练子集,重建质量略高于考虑整个HSIs。这表明在单个HSI内,像素之间存在很高的冗余性,表明只需实现稳健的泛化性能,整个HSI的像素堆栈就无需全部使用。作者必须指出,,和子集也可以用于在略微降低重建质量时进一步减少训练成本。
Rate-Distortion Evaluation
在本小节中,作者分析了基于学习的HSI压缩模型的率失真曲线。作者的实验结果如图2所示。为了实现这些结果,作者使用了文献[10]中提出的HySpecNet-11k易于分割。作者对HyCoT进行了训练,使其针对一维卷积自注意力编码器(1D-CAE)[4]中的四个特定CRs,以使作者的结果与 Baseline 可比。请注意,与基于步长卷积或池化操作的CAEs相比,HyCoT在CR方面更具多样性,见(7)。由于HyCoT不是基于步长卷积或池化操作,因此它不依赖于分块卷积操作。对于如图2所示的HyCoT结果,通过仅考虑每个epoch中的16x16
子集,作者将训练成本降低了64倍与 Baseline 相比。然而,HyCoT能在每个CR上都超过所有CAE Baseline ,这些 Baseline 都在完整的128x128HSI上进行训练。定量上,对于每个CR,HyCoT至少比1D-CAE好1个dB,对于CR约为4,它超过了SSCNet和3D-CAE,分别实现了13.00个dB和16.36个dB的性能。这说明一维光谱维数降维对HSI压缩有利,HyCoT中的 Transformer 编码器捕获到的长程光谱依赖关系与高质量重建成正相关。
Computational Complexity Analysis
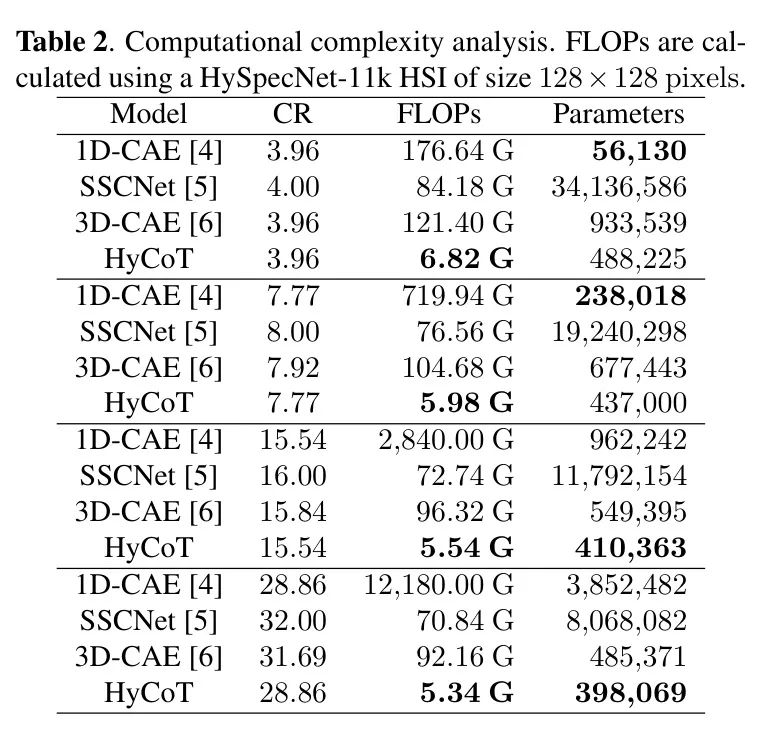
在本小节中,作者将比较HyCoT与其他模型的计算复杂度。表2报告了多个CRs的浮点运算(FLOPs)和模型参数的比较。从表中可以看出,对于低CRs,1D-CAE [4]具有少量的参数。然而,随着CR的增加,参数呈指数增长,因为网络增加了每次下采样操作新增的层。1D-CAE的高FLOPs是由于像素级卷积处理。相比之下,HyCoT在压缩到较小的潜层空间时,计算复杂度随着CR的增加而降低,因为 Transformer 编码器 Backbone 保持不变,只有MLP编码器的输出通道进行瘦身。因此,HyCoT的运行速度更快。此外,增加CR将比1D-CAE减少参数数量,而相反的情况是1D-CAE。值得一提,HyCoT的轻量级解码器适用于实时HSI重建。作者还报告了SSCNet和3D-CAE的计算复杂度。SSCNet和3D-CAE的参数数量和FLOPs较高,因为它们具有多维卷积层,因此无法与作者的HyCoT模型竞争。
4 Conclusion
在本文中,作者提出了基于超光谱压缩的变形器(Hyper spectral Compression Transformer,HyCoT)模型。HyCoT利用 Transformer 自动编码器对超光谱图像进行压缩,以利用长程光谱依赖性。为了提高训练效率,作者在每个周期中只使用可用训练数据的小部分进行训练。
实验结果表明,作者的提出的模型的训练时间效率和计算复杂性均高于 state-of-the-art 的卷积自动编码器,在固定压缩系数下,重建质量也超过了它们。作为未来的工作,作者计划将作者的 HyCoT 模型扩展到实现高效的空间-光谱压缩。
参考
[1].HycoT: Hyperspectral Compression Transformer with an Efficient Training Strategy.
如何学习AI大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。