一个2020年的工作我现在才来学习并总结它的原理,颇有种“时过境迁”的感觉。这篇总结是基于NeRF原文 NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis 阅读理解后写的,作用是以后如果记不太清了可以回忆。
目的&应用
先说一下NeRF这个架构的功能是什么。它的主要功能是进行新视角的合成:给定若干张不同视角的同一物体或场景的图片(已知相机参数和位姿),训练一个神经网络来隐式地学习物体的三维表征,然后对于新的视角进行图片合成。因为它是隐式的表示,所以并不能直接重建为三维模型,后面也有一些工作是研究怎么去进行显示三维重建的。
原理
NeRF的意思是 Neural Radiance Fields,可以翻译成“神经辐射场”,辐射场在物理上的意义是去描述空间中光照强度的分布,也就是空间中某一点在某一方向发射或接受的光强;在数学上的形式一般是一个五维空间上的函数
f
:
R
5
→
R
n
f:R^5 \rightarrow R^n
f:R5→Rn ,5维包括了空间中的位置(3维)和空间中的方向(2维)。而Neural顾名思义就是表示神经网络,所以NeRF从名字来解释就是用神经网络去拟合一个辐射场函数
f
:
(
x
,
y
,
z
,
θ
,
ϕ
)
→
(
r
,
g
,
b
,
σ
)
或
f
:
(
x
,
d
)
→
(
c
,
σ
)
f:(x,y,z,\theta,\phi)\rightarrow (r,g,b,\sigma) \ \ 或 \ \ f:(\mathbf{x},\mathbf{d})\rightarrow (\mathbf{c},\sigma)
f:(x,y,z,θ,ϕ)→(r,g,b,σ) 或 f:(x,d)→(c,σ)
这个神经网络的输入是空间中某一点的坐标以及视角方向,输出是颜色和密度。输入很好理解,就不详细说了,主要比较难理解的概念是这个密度。从物理角度来说,密度可以表示物质的集中程度或稠密程度,可以用来描述空间中物质或内容的分布情况,高密度的部分表示有物质存在,比如物体表面或内部,意味着该部分对光线的吸收或散射较强;而低密度的部分则相反,光线可以更自由地通过。
从体渲染的角度来说,密度会影响体渲染积分的过程。
普通渲染管线大致流程是:顶点投影、光栅化、片段处理,当然还包括深度测试、alpha混合等,这都是很熟悉的概念了。光线追踪是从相机射出一条光线,模拟光线的反射折射等,对路径上碰到的颜色进行混合。这两种渲染方式主要常用于Mesh这种矢量形式的场景。而对于体积数据则更适合用体渲染:从相机出发向每个像素点发射光线,对光线路径上的颜色和密度进行积分
C
(
r
)
=
∫
t
n
t
f
T
(
t
)
⋅
σ
(
r
(
t
)
)
⋅
c
(
r
(
t
)
)
d
t
C(\mathbf{r})=\int_{t_n}^{t_f}T(t)\cdot\sigma(\mathbf{r}(t))\cdot\mathbf{c}(\mathbf{r}(t)) dt
C(r)=∫tntfT(t)⋅σ(r(t))⋅c(r(t))dt
其中
T
(
t
)
T(t)
T(t)是累积的透射率,
σ
\sigma
σ和
c
\textbf{c}
c是密度和颜色,其中累积的透射率通过以下公式计算
T
(
t
)
=
exp
(
−
∫
t
n
t
σ
(
r
(
s
)
)
d
s
)
T(t)=\exp(-\int_{t_n}^t\sigma(\mathbf{r}(s))ds)
T(t)=exp(−∫tntσ(r(s))ds)
这个体渲染的公式其实很好理解,对于光线路径上的点,它的密度越大,且光线在这点的透射率越大,这一点的颜色对最终颜色(积分)的贡献就越大;而这一点的光线透射率,就是
e
−
(
在这一点之前的密度积分
)
∈
(
0
,
1
)
e^{-(在这一点之前的密度积分)}\in(0,1)
e−(在这一点之前的密度积分)∈(0,1),之前的密度积分越大,透射率越小。
因此NeRF实际上就是学习一个神经网络去对空间每个点和方向预测一个颜色和密度,然后对于新的视角,也就是新的观测点或者相机,用体渲染来计算每个像素的颜色值,以此得到新视角的合成图片。
神经网络结构
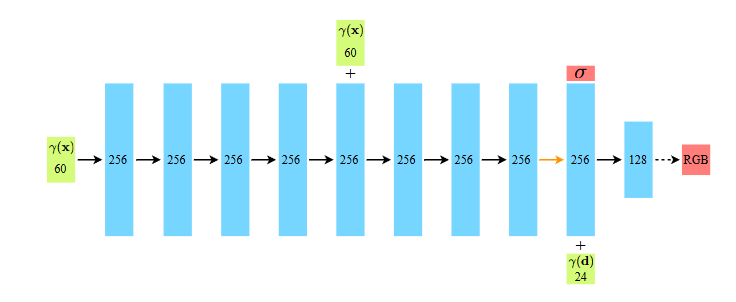
NeRF的神经网络结构就是简单的MLP模型,每一层之间都是全连接层+ReLU,并添加了一个残差连接。其中有几个要注意的点:
空间中每个点的密度 σ \sigma σ应该是场景固有属性,与光照、视角这些变量无关,因此MLP一开始的输入只有坐标,在预测完密度之后,才拼接视角进行后面颜色的预测。
神经网络偏向于学习低频信息,或者说,网络很难学习到低维域的高频信息,因此论文将输入映射到高维空间后再输入MLP
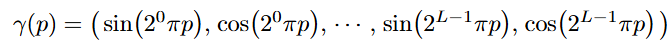
对于每个分量先正则化到[-1, 1]后再使用上述公式。其实这个映射是傅里叶特征(Fourier Features)的一种特殊形式,参考 Fourier Features Let Networks Learn High Frequency Functions in Low Dimensional Domains。通过将低维输入映射到高维空间来更好地学习高频信息,一般针对的是基于点输入的神经网络,像NeRF或者DeepSDF这种就很适用。
体渲染
前面提到了体渲染在光线路径上的积分公式,以及有了一个输入输出适用于体渲染的神经网络,直接计算积分很难,需要转化为离散的求积公式,也就是对光线离散点求和来近似积分:
C
(
r
)
=
∑
i
=
1
N
T
i
(
1
−
exp
(
−
σ
i
δ
i
)
)
c
i
,
where
T
i
=
exp
(
−
∑
j
=
1
i
−
1
σ
j
δ
j
)
C(\mathbf{r})=\sum_{i=1}^N T_i(1-\exp(-\sigma_i\delta_i))\mathbf{c}_i, \ \ \text{where} \ T_i=\exp(-\sum_{j=1}^{i-1}\sigma_j\delta_j)
C(r)=i=1∑NTi(1−exp(−σiδi))ci, where Ti=exp(−j=1∑i−1σjδj)
其中
δ
i
=
t
i
+
1
−
t
i
\delta_i=t_{i+1}-t_i
δi=ti+1−ti,表示相邻采样点之间的距离。实际上透射率
T
i
+
1
=
T
i
⋅
exp
(
−
σ
i
δ
i
)
T_{i+1}=T_i \cdot \exp(-\sigma_i\delta_i)
Ti+1=Ti⋅exp(−σiδi),表示每经过一小节透射率都要乘一个透射系数
exp
(
−
σ
i
δ
i
)
\exp(-\sigma_i\delta_i)
exp(−σiδi),这个透射系数中当密度为0时透射系数为1,表示光线完全通过,当密度趋于无穷时投射系数趋于0,而
σ
i
δ
i
\sigma_i\delta_i
σiδi就是近似的一小节的密度,被称为光学厚度。
因此公式里的 T i T_i Ti表示到第i小节时剩余的光线强度, ( 1 − exp ( − σ i δ i ) ) (1-\exp(-\sigma_i\delta_i)) (1−exp(−σiδi))表示该小节的颜色贡献,可以理解为 exp ( − σ i δ i ) \exp(-\sigma_i\delta_i) exp(−σiδi)这一比例的光透射过去了,剩下的比例变成颜色贡献,物理意义就是散射。其实从连续形式的积分去离散化应该是能直接推出来的,但我不会推,只会解释结果的每一部分有什么意义。
另外,整个体渲染的计算过程都可以形式化的书写出来,是可微分的。
还有一个问题就是该如何在光线上进行采样,如果按照数量N平均采样,可能很多空的地方都是对训练没有用的,因此论文使用了一种“粗+细”的方式,即使用两个相同的网络,先用粗网络平均采样之后,根据每个点的 ( 1 − exp ( − σ i δ i ) ) (1-\exp(-\sigma_i\delta_i)) (1−exp(−σiδi))划分权重,在细网络中对权重大的部分进行细分,以此提高训练效率。
训练
数据集就是对同一个场景的多视角图片,并且有相机位姿和参数。把所有像素点放在一起作为训练集,每个batch选若干个像素点参与训练,粗细网络的结果都参与梯度下降的优化过程,Loss为
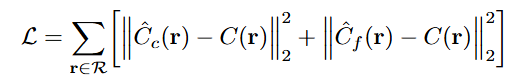
训练完之后的新视角合成只用细网络。
根据论文的描述, N c = 64 , N f = 128 N_c=64,N_f=128 Nc=64,Nf=128,batch_size为4096,100-300k个迭代数量,在一块V100上大概需要1-2天的训练时间。












![[Linux] 权限](https://i-blog.csdnimg.cn/direct/edbba5bbe0bd4fc59885614068aa03af.png)





