一、基础任务

大模型在浮点数大小比较上表现不佳,直接询问大模型浮点数大小往往会出现错误,而通过设定适当的提示词可以引导大模型生成正确的答案。提示工程是指设计和优化输入提示(prompts)的过程,这些提示用于指导大模型生成期望的输出或行为。清晰、具体且针对性的指令,能够让模型更有效地理解和执行任务,从而提高模型的性能和用户体验。
1. 常用提示方法
(1) 零样本和少样本提示
零样本提示(few shot prompting)和少样本提示(few shot prompting)是最简单的提示技术。
在零样本提示中,用户直接输入问题,由大模型生成答案。这也是我们日常使用最多的提示方法。
question: Your question
answer:在少样本提示中,用户首先给出一些类似的问答对例子,再输入要解决的问题。一般来说,问答对例子数量在3-8个左右。
question: Example question
answer: Example answer
……
question: Your question
answer:(2) CoT(Chain of Thought)
CoT是一种改进的提示技术,能够显著提高大模型回答问题的准确性,分为零样本CoT和少样本CoT提示。
在零样本CoT提示中,用户直接输入自己的问题,并在最后加上"Let's think step by step"引导大模型一步一步生成中间步骤,最后得到答案。
question: Your question. Let's think step by step.
answer:在少样本CoT提示中,用户首先给出<问题,思维链,答案>例子,再给出自己的问题。其中思维链表示中间推理步骤。
question: Example question. Let's think step by step.
answer: Reasoning steps. Example answer.
……
question:Your question. Let's think step by step.
answer:(3) LangGPT
为了帮助用户快速构建高效提示词,LangGPT定义了一套提示词模板,用户可以结合自己的任务来修改模板,从而构建高效的提示词。具体地,LangGPT定义了提示词需要包含的若干模块,包括概要、限制、目标、流程等,每个模块分别描述大模型需要满足的要求。用户只需根据自己的需求组合和修改这些模块,即可完成提示词构建。一个空白的LangGPT提示词模板如下:
# Role: {}
## Profile
- author: LangGPT
- version: 1.0
- language: {中文/英文}
- description: {}
## Skills
{}
## Background(可选项):
## Goals(可选项):
## OutputFormat(可选项):
## Constraints
{}
## Workflows
{}
## Initialization
{}2. 基础任务实践
(1)环境配置
我们需要创建Python环境并安装相关库:
# 创建虚拟环境
conda create -n langgpt python=3.10 -y
conda activate langgpt
# 安装一些必要的库
conda install pytorch==2.1.2 torchvision==0.16.2 torchaudio==2.1.2 pytorch-cuda=12.1 -c pytorch -c nvidia -y
# 安装其他依赖
pip install transformers==4.43.3
pip install streamlit==1.37.0
pip install huggingface_hub==0.24.3
pip install openai==1.37.1
pip install lmdeploy==0.5.2安装linux软件依赖:
apt-get install tmux创建项目文件夹:
## 创建路径
mkdir langgpt
## 进入项目路径
cd langgpt(2) 模型部署
接下来我们需要将internlm2-chat-1.8b模型部署为openai格式server。由于服务需要持续运行,需要将进程维持在后台,所以这里使用tmux软件创建新的命令窗口:
tmux new -t langgpt然后使用LMDeploy进行部署,只需一行代码即可部署模型API服务:
CUDA_VISIBLE_DEVICES=0 lmdeploy serve api_server /share/new_models/Shanghai_AI_Laboratory/internlm2-chat-1_8b --server-port 23333 --api-keys internlm2部署效果如下:

随后可以通过代码测试是否部署成功:
from openai import OpenAI
client = OpenAI(
api_key = "internlm2",
base_url = "http://0.0.0.0:23333/v1"
)
response = client.chat.completions.create(
model=client.models.list().data[0].id,
messages=[
{"role": "system", "content": "请介绍一下你自己"}
]
)
print(response.choices[0].message.content)效果如下:

为了简化调用,可以进一步进行图形化界面调用,创建UI应用。InternLM部署完成后,可利用提供的chat_ui.py创建图形化界面。首先从github克隆项目:
git clone https://github.com/InternLM/Tutorial.git进入项目所在路径并运行脚本部署streamlit应用:
cd Tutorial/tools
python -m streamlit run chat_ui.py随后将端口映射到本地并在浏览器页面打开。点击开启新对话后即可发起对话。
(3) 浮点数大小比较
这里可以测试模型是否能够进行浮点大小比较:

可以看到,模型输出了错误的答案。接下来我们编写LangGPT提示模板:
# Role: 数学专家
## Profile
- author: LangGPT
- version: 1.0
- language: 中文
- description: 能够解决任意数值大小比较问题的数学专家。
## Skills
- 理解并执行数值大小比较规则。
- 比较整数和小数的大小。
- 按照十分位、百分位、千分位、万分位等顺序比较小数部分。
## Examples
- 1.8大于1.75
- 1.8小于1.85
- 1.8大于1.54
- 1.1小于1.51
- 3.5大于3.12
## Background
在进行数值大小比较时,需要遵循特定的比较规则,特别是当涉及到小数时。
## Goals
- 接收两个数值进行比较。
- 返回比较结果,明确哪个数值更大或两者相等。
## OutputFormat
- 输出格式为:'数值A {大于/小于/等于} 数值B'
## Constraints
- 输入数值必须为有效的整数或小数。
- 比较结果仅限于'大于'、'小于'或'等于'。
## Workflows
1. 接收两个待比较的数值。
2. 判断两个数值的类型(整数或小数)。
3. 如果是整数,直接比较大小。
4. 如果是小数,先比较整数部分,若整数部分相同,则依次比较小数部分的十分位、百分位、千分位、万分位等。
5. 输出比较结果。将以上模板填入system prompt区域, 并开启新对话输入问题:

模型成功完成了数值大小比较任务。
二、进阶任务

我们基于GSM8K数据集进行零样本CoT、少样本CoT和LangGPT提示工程评测,使用的模型为Internlm2.5-chat-7b,运行至少需要24GB显存。
1. OpenCompass介绍
OpenCompass是由上海人工智能实验室研发的开源、高效、全面的大模型评测体系及开放平台,支持各种大模型的一站式评测。OpenCompass的中文文档位于OpenCompass司南。
(1) 环境配置
首先创建Python环境并安装基础依赖:
conda create --name opencompass python=3.10 pytorch torchvision pytorch-cuda -c nvidia -c pytorch -y
conda activate opencompass随后在/root目录下克隆OpenCompass项目并安装:
git clone https://github.com/open-compass/opencompass.git
cd opencompass
pip install -e .为了进行GSM8K数据集评测,我们需要下载OpenCompass数据集。在 OpenCompass 项目根目录下运行下面命令,将数据集准备至${OpenCompass}/data目录下:
wget https://github.com/open-compass/opencompass/releases/download/0.2.2.rc1/OpenCompassData-core-20240207.zip
unzip OpenCompassData-core-20240207.zip至此,OpenCompass的基本环境就搭建完了。
(2) 数据集配置
数据集配置是评测过程中非常重要的一步。所有的数据集配置文件都位于${OpenCompass}/configs/datasets 目录下。目录下的gsm8k文件夹即包含了对于gsm8k的数据配置文件。
configs/datasets/
├── agieval
├── apps
├── ARC_c
├── ...
├── CLUE_afqmc # 数据集
│ ├── CLUE_afqmc_gen_901306.py # 不同版本数据集配置文件
│ ├── CLUE_afqmc_gen.py
│ ├── CLUE_afqmc_ppl_378c5b.py
│ ├── CLUE_afqmc_ppl_6507d7.py
│ ├── CLUE_afqmc_ppl_7b0c1e.py
│ └── CLUE_afqmc_ppl.py
├── ...
├── XLSum
├── Xsum
└── z_bench其中,数据集配置命名方式为数据集名称_评测方式_版本号.py
我们分别需要评测零样本CoT、少样本CoT、LangGPT三种提示的效果。下面给出这三种提示的模板:
- 零样本CoT
gsm8k_infer_cfg = dict(
prompt_template=dict(
type=PromptTemplate,
template=dict(
round=[
dict(role='HUMAN', prompt='{question}\nPlease reason step by step, and put your final answer within \\boxed{}.'),
],
),
),
retriever=dict(type=ZeroRetriever),
inferencer=dict(type=GenInferencer, max_out_len=512),
)- 少样本CoT
gsm8k_infer_cfg = dict(
prompt_template=dict(
type=PromptTemplate,
template=dict(
round=[
dict(role='HUMAN', prompt="Question: Angelo and Melanie want to plan how many hours over the next week they should study together for their test next week. They have 2 chapters of their textbook to study and 4 worksheets to memorize. They figure out that they should dedicate 3 hours to each chapter of their textbook and 1.5 hours for each worksheet. If they plan to study no more than 4 hours each day, how many days should they plan to study total over the next week if they take a 10-minute break every hour, include 3 10-minute snack breaks each day, and 30 minutes for lunch each day?\nLet's think step by step\nAnswer:"),
dict(role='BOT', prompt='Angelo and Melanie think they should dedicate 3 hours to each of the 2 chapters, 3 hours x 2 chapters = 6 hours total.\nFor the worksheets they plan to dedicate 1.5 hours for each worksheet, 1.5 hours x 4 worksheets = 6 hours total.\nAngelo and Melanie need to start with planning 12 hours to study, at 4 hours a day, 12 / 4 = 3 days.\nHowever, they need to include time for breaks and lunch. Every hour they want to include a 10-minute break, so 12 total hours x 10 minutes = 120 extra minutes for breaks.\nThey also want to include 3 10-minute snack breaks, 3 x 10 minutes = 30 minutes.\nAnd they want to include 30 minutes for lunch each day, so 120 minutes for breaks + 30 minutes for snack breaks + 30 minutes for lunch = 180 minutes, or 180 / 60 minutes per hour = 3 extra hours.\nSo Angelo and Melanie want to plan 12 hours to study + 3 hours of breaks = 15 hours total.\nThey want to study no more than 4 hours each day, 15 hours / 4 hours each day = 3.75\nThey will need to plan to study 4 days to allow for all the time they need.\nThe answer is 4\n'),
dict(role='HUMAN', prompt="Question: Mark's basketball team scores 25 2 pointers, 8 3 pointers and 10 free throws. Their opponents score double the 2 pointers but half the 3 pointers and free throws. What's the total number of points scored by both teams added together?\nLet's think step by step\nAnswer:"),
dict(role='BOT', prompt="Mark's team scores 25 2 pointers, meaning they scored 25*2= 50 points in 2 pointers.\nHis team also scores 6 3 pointers, meaning they scored 8*3= 24 points in 3 pointers\nThey scored 10 free throws, and free throws count as one point so they scored 10*1=10 points in free throws.\nAll together his team scored 50+24+10= 84 points\nMark's opponents scored double his team's number of 2 pointers, meaning they scored 50*2=100 points in 2 pointers.\nHis opponents scored half his team's number of 3 pointers, meaning they scored 24/2= 12 points in 3 pointers.\nThey also scored half Mark's team's points in free throws, meaning they scored 10/2=5 points in free throws.\nAll together Mark's opponents scored 100+12+5=117 points\nThe total score for the game is both team's scores added together, so it is 84+117=201 points\nThe answer is 201\n"),
dict(role='HUMAN', prompt="Question: Bella has two times as many marbles as frisbees. She also has 20 more frisbees than deck cards. If she buys 2/5 times more of each item, what would be the total number of the items she will have if she currently has 60 marbles?\nLet's think step by step\nAnswer:"),
dict(role='BOT', prompt="When Bella buys 2/5 times more marbles, she'll have increased the number of marbles by 2/5*60 = 24\nThe total number of marbles she'll have is 60+24 = 84\nIf Bella currently has 60 marbles, and she has two times as many marbles as frisbees, she has 60/2 = 30 frisbees.\nIf Bella buys 2/5 times more frisbees, she'll have 2/5*30 = 12 more frisbees.\nThe total number of frisbees she'll have will increase to 30+12 = 42\nBella also has 20 more frisbees than deck cards, meaning she has 30-20 = 10 deck cards\nIf she buys 2/5 times more deck cards, she'll have 2/5*10 = 4 more deck cards.\nThe total number of deck cards she'll have is 10+4 = 14\nTogether, Bella will have a total of 14+42+84 = 140 items\nThe answer is 140\n"),
dict(role='HUMAN', prompt="Question: A group of 4 fruit baskets contains 9 apples, 15 oranges, and 14 bananas in the first three baskets and 2 less of each fruit in the fourth basket. How many fruits are there?\nLet's think step by step\nAnswer:"),
dict(role='BOT', prompt='For the first three baskets, the number of apples and oranges in one basket is 9+15=24\nIn total, together with bananas, the number of fruits in one basket is 24+14=38 for the first three baskets.\nSince there are three baskets each having 38 fruits, there are 3*38=114 fruits in the first three baskets.\nThe number of apples in the fourth basket is 9-2=7\nThere are also 15-2=13 oranges in the fourth basket\nThe combined number of oranges and apples in the fourth basket is 13+7=20\nThe fourth basket also contains 14-2=12 bananas.\nIn total, the fourth basket has 20+12=32 fruits.\nThe four baskets together have 32+114=146 fruits.\nThe answer is 146\n'),
dict(role='HUMAN', prompt="Question: {question}\nLet's think step by step\nAnswer:"),
],
)),
retriever=dict(type=ZeroRetriever),
inferencer=dict(type=GenInferencer, max_out_len=512))- LangGPT
gsm8k_infer_cfg = dict(
prompt_template=dict(
type=PromptTemplate,
template=dict(
begin=[
dict(role='SYSTEM',fallback_role='HUMAN', prompt="""
# Role: MathExpert
## Profile
- author: LangGPT
- version: 1.0
- language: 英文
- description: An AI math expert capable of solving a wide range of mathematical problems, including algebra, calculus, geometry, and statistics.
## Skills
- Solving algebraic equations and inequalities.
- Solving mathematical problems in real-life applications.
- Interpreting and manipulating statistical data.
## Background
The MathExpert is designed for students, educators, and anyone who needs assistance with mathematical concepts and problem-solving.
## Goals
- To provide accurate and clear solutions to math problems.
- To explain mathematical concepts in an understandable way.
- To assist in the learning and mastery of mathematical subjects.
## OutputFormat
- The solution to the math problem presented in a step-by-step format.
- Explanations of the concepts used in the solution.
- Visual aids (where applicable) to illustrate the problem and solution.
## Constraints
- The math problems should be within the scope of high school and undergraduate level mathematics.
- The AI will not perform real-time calculations or data analysis that requires external data sources.
## Workflows
1. User presents a math problem or asks for an explanation of a mathematical concept.
2. MathExpert analyzes the problem and determines the appropriate approach to solve it.
3. MathExpert provides a step-by-step solution, including explanations.
## Initialization
- Please present your mathematical problem.
"""),
],
round=[
dict(role='HUMAN', prompt="Question: Angelo and Melanie want to plan how many hours over the next week they should study together for their test next week. They have 2 chapters of their textbook to study and 4 worksheets to memorize. They figure out that they should dedicate 3 hours to each chapter of their textbook and 1.5 hours for each worksheet. If they plan to study no more than 4 hours each day, how many days should they plan to study total over the next week if they take a 10-minute break every hour, include 3 10-minute snack breaks each day, and 30 minutes for lunch each day?\nLet's think step by step\nAnswer:"),
dict(role='BOT', prompt='Angelo and Melanie think they should dedicate 3 hours to each of the 2 chapters, 3 hours x 2 chapters = 6 hours total.\nFor the worksheets they plan to dedicate 1.5 hours for each worksheet, 1.5 hours x 4 worksheets = 6 hours total.\nAngelo and Melanie need to start with planning 12 hours to study, at 4 hours a day, 12 / 4 = 3 days.\nHowever, they need to include time for breaks and lunch. Every hour they want to include a 10-minute break, so 12 total hours x 10 minutes = 120 extra minutes for breaks.\nThey also want to include 3 10-minute snack breaks, 3 x 10 minutes = 30 minutes.\nAnd they want to include 30 minutes for lunch each day, so 120 minutes for breaks + 30 minutes for snack breaks + 30 minutes for lunch = 180 minutes, or 180 / 60 minutes per hour = 3 extra hours.\nSo Angelo and Melanie want to plan 12 hours to study + 3 hours of breaks = 15 hours total.\nThey want to study no more than 4 hours each day, 15 hours / 4 hours each day = 3.75\nThey will need to plan to study 4 days to allow for all the time they need.\nThe answer is 4\n'),
dict(role='HUMAN', prompt="Question: Mark's basketball team scores 25 2 pointers, 8 3 pointers and 10 free throws. Their opponents score double the 2 pointers but half the 3 pointers and free throws. What's the total number of points scored by both teams added together?\nLet's think step by step\nAnswer:"),
dict(role='BOT', prompt="Mark's team scores 25 2 pointers, meaning they scored 25*2= 50 points in 2 pointers.\nHis team also scores 6 3 pointers, meaning they scored 8*3= 24 points in 3 pointers\nThey scored 10 free throws, and free throws count as one point so they scored 10*1=10 points in free throws.\nAll together his team scored 50+24+10= 84 points\nMark's opponents scored double his team's number of 2 pointers, meaning they scored 50*2=100 points in 2 pointers.\nHis opponents scored half his team's number of 3 pointers, meaning they scored 24/2= 12 points in 3 pointers.\nThey also scored half Mark's team's points in free throws, meaning they scored 10/2=5 points in free throws.\nAll together Mark's opponents scored 100+12+5=117 points\nThe total score for the game is both team's scores added together, so it is 84+117=201 points\nThe answer is 201\n"),
dict(role='HUMAN', prompt="Question: Bella has two times as many marbles as frisbees. She also has 20 more frisbees than deck cards. If she buys 2/5 times more of each item, what would be the total number of the items she will have if she currently has 60 marbles?\nLet's think step by step\nAnswer:"),
dict(role='BOT', prompt="When Bella buys 2/5 times more marbles, she'll have increased the number of marbles by 2/5*60 = 24\nThe total number of marbles she'll have is 60+24 = 84\nIf Bella currently has 60 marbles, and she has two times as many marbles as frisbees, she has 60/2 = 30 frisbees.\nIf Bella buys 2/5 times more frisbees, she'll have 2/5*30 = 12 more frisbees.\nThe total number of frisbees she'll have will increase to 30+12 = 42\nBella also has 20 more frisbees than deck cards, meaning she has 30-20 = 10 deck cards\nIf she buys 2/5 times more deck cards, she'll have 2/5*10 = 4 more deck cards.\nThe total number of deck cards she'll have is 10+4 = 14\nTogether, Bella will have a total of 14+42+84 = 140 items\nThe answer is 140\n"),
dict(role='HUMAN', prompt="Question: A group of 4 fruit baskets contains 9 apples, 15 oranges, and 14 bananas in the first three baskets and 2 less of each fruit in the fourth basket. How many fruits are there?\nLet's think step by step\nAnswer:"),
dict(role='BOT', prompt='For the first three baskets, the number of apples and oranges in one basket is 9+15=24\nIn total, together with bananas, the number of fruits in one basket is 24+14=38 for the first three baskets.\nSince there are three baskets each having 38 fruits, there are 3*38=114 fruits in the first three baskets.\nThe number of apples in the fourth basket is 9-2=7\nThere are also 15-2=13 oranges in the fourth basket\nThe combined number of oranges and apples in the fourth basket is 13+7=20\nThe fourth basket also contains 14-2=12 bananas.\nIn total, the fourth basket has 20+12=32 fruits.\nThe four baskets together have 32+114=146 fruits.\nThe answer is 146\n'),
dict(
role='HUMAN', prompt="Question: {question}\nLet's think step by step\nAnswer:"),
],
)),
retriever=dict(type=ZeroRetriever),
inferencer=dict(type=GenInferencer, max_out_len=512))其中,retriever参数指定不进行检索,inferencer指定进行推理生成,并限制最大长度。LangGPT提示作为system prompt。
以上三种提示方法仅在推理配置部分不同,其余配置均相同。 其余部分代码如下:
# gsm8k_gen_0806.py 数据集配置文件(gsm8k_infer_cfg为以上需要评测的提示词配置)
from opencompass.openicl.icl_prompt_template import PromptTemplate
from opencompass.openicl.icl_retriever import ZeroRetriever
from opencompass.openicl.icl_inferencer import GenInferencer
from opencompass.datasets import GSM8KDataset, gsm8k_postprocess, gsm8k_dataset_postprocess, Gsm8kEvaluator
# 数据集输入字段为question,输出字段为answer
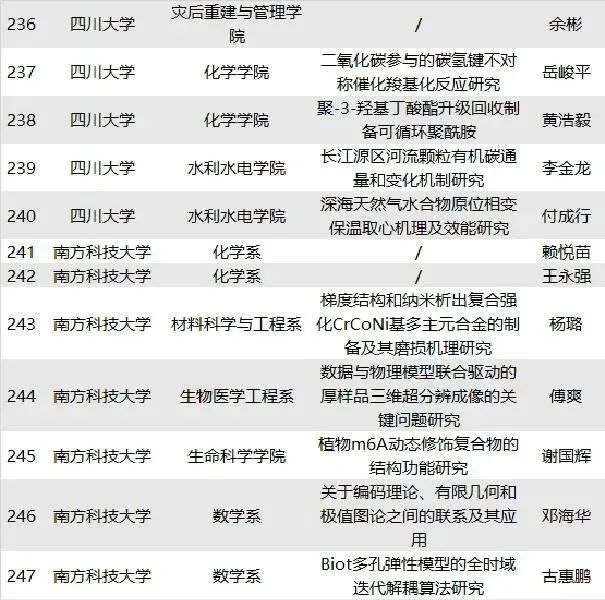
gsm8k_reader_cfg = dict(input_columns=['question'], output_column='answer')
# 推理配置
gsm8k_infer_cfg =
# 数据集总配置
gsm8k_datasets = [
dict(
abbr='gsm8k', # 简称
type=GSM8KDataset,
path='opencompass/gsm8k',
reader_cfg=gsm8k_reader_cfg,
infer_cfg=gsm8k_infer_cfg,
eval_cfg=gsm8k_eval_cfg)
](3) 评测配置
我们需要定义评测配置文件。所有的评测配置文件都位于${OpenCompass}/configs/ 目录下。对于自定义评测任务,我们需要新建评测文件,并定义models和datasets变量。其中datasets变量可以直接从第(2)部分的数据集配置文件导入gsm8k_datasets。
我们使用LMDeploy来部署本地模型,因此使用的模型类型为TurboMindModel 。此外,我们简单介绍一下OpenCompass中模型侧的Meta Template。在 LLM 的 Supervised Fine-Tuning (SFT) 过程中,我们常常会根据实际的要求往对话内注入一些预定义的字符串,以求模型能按照一定的要求输出内容。因此,我们需要针对不同模型指定不同的解析模板。其中,Internlm2.5-chat-7b的解析模板示例如下:

如图,Internlm2.5-chat-7b的解析模板会在对话最开始添加<s>词元,在每轮对话开始前加入<im_start>,并加入对应角色。在每轮对话结束后加入<im_end>。因此我们可以尝试加入meta_template 解析模板,以得到符合指令微调阶段的输入。
我们定义的meta template如下:
internlm2_meta_template = dict(
begin='<s>',
reserved_roles=[dict(role='SYSTEM', begin='<|im_start|>system\n', end='<im_end>\n'),],
round=[
dict(role='HUMAN', begin='<|im_start|>user\n', end='<|im_end|>\n'),
dict(role='BOT', begin='<|im_start|>assistant\n', end='<|im_end|>\n', generate=True),
],
eos_token_id=92542
) 于是,整体配置文件样例如下:
# eval.py
from mmengine.config import read_base
from opencompass.models.turbomind import TurboMindModel
# 导入前面定义的数据集配置
with read_base():
# choose a list of datasets
from .datasets.gsm8k.gsm8k_gen_1d7fe4 import gsm8k_datasets
# and output the results in a chosen format
from .summarizers.medium import summarizer
# 定义评测数据集
datasets = gsm8k_datasets
internlm2_meta_template = dict(
begin='<s>',
reserved_roles=[dict(role='SYSTEM', begin='<|im_start|>system\n', end='<im_end>\n'),],
round=[
dict(role='HUMAN', begin='<|im_start|>user\n', end='<|im_end|>\n'),
dict(role='BOT', begin='<|im_start|>assistant\n', end='<|im_end|>\n', generate=True),
],
eos_token_id=92542
)
# config for internlm-20b model
internlm_7b = dict(
type=TurboMindModel,
abbr='internlm-7b-chat-langgpt',
path="internlm/internlm2_5-7b-chat", # 注意路径与huggingface保持一致
engine_config=dict(session_len=2048,
max_batch_size=32,
rope_scaling_factor=1.0),
gen_config=dict(top_k=1, top_p=0.8,
temperature=1.0,
max_new_tokens=100),
meta_template=internlm2_meta_template, # 如果不使用解析模板,可以删除这行
max_out_len=100,
max_seq_len=2048,
batch_size=8,
concurrency=8,
run_cfg=dict(num_gpus=1, num_procs=1),
end_str='<im_end>'
)
# 定义评测模型
models = [internlm_7b]以上为少样本CoT评测数据集评测文件,可以进一步加入零样本CoT、LangGPT数据集配置。
至此,我们的评测文件已经全部建立完毕。
2. 提示词评测
(1) 运行评测
目前OpenCompass还存在一些环境冲突,在评测开始前,我们需要设定环境变量:
export MKL_SERVICE_FORCE_INTEL=1在OpenCompass根目录下运行命令:
python run.py configs/eval.py(2) 评测结果
我们分别评测了少样本CoT、零样本CoT、LangGPT三种提示的效果。结果如下:
| 使用meta template | 零样本CoT | 少样本CoT | LangGPT |
|---|---|---|---|
| 是 | 23.8 | 34.8 | 81.5 |
| 否 | 34.6 | 81.6 | 55.9 |
令人意外的是,meta template提升了LangGPT的准确率,却降低了零样本和少样本CoT的准确率。其中,少样本CoT达到了最高的准确率81.6%,LangGPT也实现了相当的性能。