首发公众号:赵侠客
引言
在数据库表结构设计中,一对多(1:N)关系的处理是非常常见需求,如一个用户有多个分类或角色。传统关系型数据库表设计方式通常要包括三张表:用户表、分类表、以及用户与分类之间的关联关系表,主要是通过关系表来存储一对多的关系。虽然这种表结构设计符合数据库设计种的范式要求,但是在进行分类查询时往往需要执行复杂的关联查询,这会对性能造成影响,对开发人员SQL水平要求较高并且需要经常的优化慢SQL,同时也会增加未来对数据库分库分表时的复杂度。为了解决这个问题,本文提出了一种改进性的单表设计方案,通过对表添加全文索引,可以更简单地通过单表解决一对多的关系,避免关联查询,并减少对数据库结构的依赖,实现更高效、简单的数据库查询。
二、传统表设计
一对多(1:N)的关系就指一个表中的记录可以与另一个表中的多个记录相关联,常见的场景有用户分类、文章打标签、用户角色等,这种应用场景有一个特点:1的数据量往往远远大于N的数据量,这里我们拿最常见的用户分类应用场景为例看看传统表结构是怎么设计。
2.1、创建分类表
针对用户分类场景首先我们需要创建一张分类表user_type,存储用户的分类信息
CREATE TABLE `user_type` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '自增主键',
`type_name` varchar(200) NOT NULL DEFAULT '' COMMENT '用户分类名',
PRIMARY KEY (`id`) USING BTREE
) ENGINE=InnoDB COMMENT='用户分类'
插入测试数据 :
INSERT INTO `user_type`(`id`, `type_name`) VALUES (1, '90后');
INSERT INTO `user_type`(`id`, `type_name`) VALUES (2, 'JAVA开发');
INSERT INTO `user_type`(`id`, `type_name`) VALUES (3, '程序员');
INSERT INTO `user_type`(`id`, `type_name`) VALUES (4, '前端');
INSERT INTO `user_type`(`id`, `type_name`) VALUES (5, '后端');
INSERT INTO `user_type`(`id`, `type_name`) VALUES (6, '测试');
INSERT INTO `user_type`(`id`, `type_name`) VALUES (7, 'HR');
INSERT INTO `user_type`(`id`, `type_name`) VALUES (8, '80后');
INSERT INTO `user_type`(`id`, `type_name`) VALUES (9, '富二代');
2.2、创建用户名
然后我们需要创建一张用户表存储用户信息,数据库设计的第一范式要求每个字段都是不可再分的原子值。所有字段值必须是单一的,不可拆分的。
CREATE TABLE `user` (
`id` bigint(255) NOT NULL AUTO_INCREMENT,
`user_name` varchar(200) NOT NULL DEFAULT '' COMMENT '用户名',
PRIMARY KEY (`id`) USING BTREE
) ENGINE=InnoDB COMMENT='用户表'
插入测试数据 :
INSERT INTO `user`(`id`, `user_name`) VALUES (1, '赵侠客');
INSERT INTO `user`(`id`, `user_name`) VALUES (2, '赵云');
INSERT INTO `user`(`id`, `user_name`) VALUES (3, '马超');
INSERT INTO `user`(`id`, `user_name`) VALUES (4, '刘备');
INSERT INTO `user`(`id`, `user_name`) VALUES (5, '关羽');
INSERT INTO `user`(`id`, `user_name`) VALUES (6, '张飞');
INSERT INTO `user`(`id`, `user_name`) VALUES (7, '曹操');
INSERT INTO `user`(`id`, `user_name`) VALUES (8, '马云');
INSERT INTO `user`(`id`, `user_name`) VALUES (9, '子龙');
2.3、创建用户分类关系表
在关系型数据库设计中当一个用户有多个分类时我们需要创建一个关联关系表用于记录用户与分类的关系:
CREATE TABLE `user_type_relation` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '自增主键',
`user_id` bigint(24) NOT NULL COMMENT '用户ID',
`type_id` bigint(24) NOT NULL COMMENT '用户分类ID',
PRIMARY KEY (`id`) USING BTREE,
KEY `indx_user_id` (`user_id`) USING BTREE
) ENGINE=InnoDB COMMENT='用户分类关联表'
添加用户分类数据 :
INSERT INTO `user_type_relation`(`id`, `user_id`, `type_id`) VALUES (1, 1, 1);
INSERT INTO `user_type_relation`(`id`, `user_id`, `type_id`) VALUES (2, 1, 2);
INSERT INTO `user_type_relation`(`id`, `user_id`, `type_id`) VALUES (3, 1, 3);
INSERT INTO `user_type_relation`(`id`, `user_id`, `type_id`) VALUES (4, 2, 1);
INSERT INTO `user_type_relation`(`id`, `user_id`, `type_id`) VALUES (5, 2, 3);
INSERT INTO `user_type_relation`(`id`, `user_id`, `type_id`) VALUES (6, 2, 4);
INSERT INTO `user_type_relation`(`id`, `user_id`, `type_id`) VALUES (7, 2, 5);
2.4、查询
有了上述三张表后,基本上所有的查询需求我们都可以通过复杂的关联查询查出来的,如以以几个查询需求:
90后不是富二代的JAVA程序员
90后的type_id=1,JAVA程序员的type_id=2,富二代的type_id=9,使用关联查询SQL为:
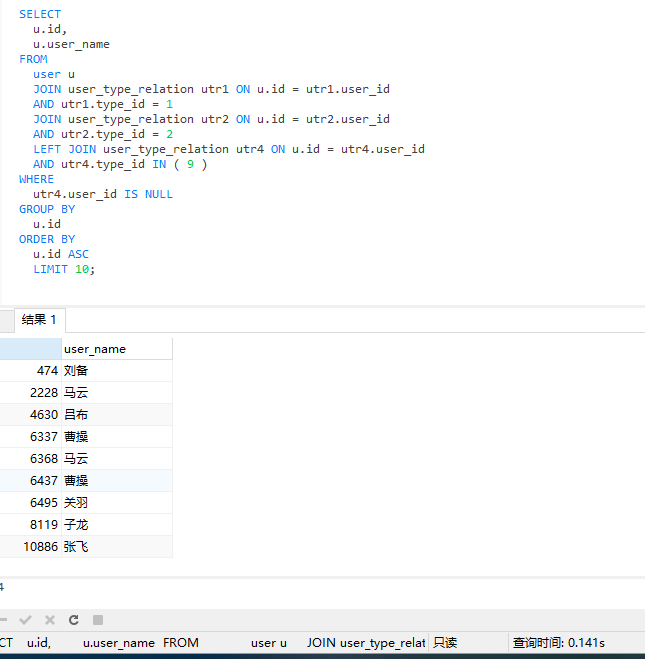
查询用户:
SELECT
u.id,
u.user_name
FROM
USER u
JOIN user_type_relation utr1 ON u.id = utr1.user_id
AND utr1.type_id = 1
JOIN user_type_relation utr2 ON u.id = utr2.user_id
AND utr2.type_id = 2
LEFT JOIN user_type_relation utr4 ON u.id = utr4.user_id
AND utr4.type_id IN ( 9 )
WHERE
utr4.user_id IS NULL
GROUP BY
u.id
ORDER BY
u.id ASC
LIMIT 10;
我在1C1G的个人测试服务器上生成了100条分类,10万条用户数据,每个用户有三个分类,这条SQL耗时0.141S
查询用户总量:
SELECT
COUNT(DISTINCT u.id) AS result_count
FROM
user u
JOIN user_type_relation utr1 ON u.id = utr1.user_id
AND utr1.type_id = 1
JOIN user_type_relation utr2 ON u.id = utr2.user_id
AND utr2.type_id = 2
LEFT JOIN user_type_relation utr4 ON u.id = utr4.user_id
AND utr4.type_id IN (9)
WHERE
utr4.user_id IS NULL;
用户数量统计耗时0.178s:

不是富二代的90后和JAVA程序员
查询用户:
SELECT
u.id,u.user_name
FROM
user u
LEFT JOIN user_type_relation utr ON u.id = utr.user_id
WHERE
utr.type_id IN ( 1, 2 )
AND utr.type_id NOT IN ( 9 )
GROUP BY
u.id
ORDER BY
u.id ASC
LIMIT 10
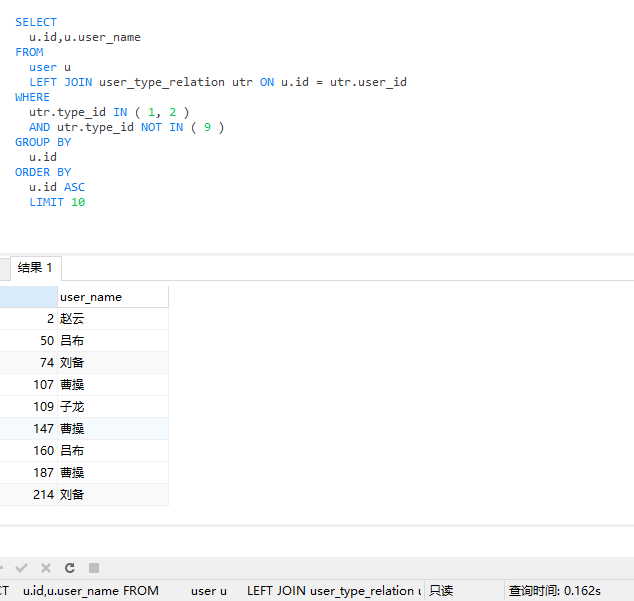
查询用户总量:
SELECT
COUNT(DISTINCT u.id)
FROM
user u
LEFT JOIN user_type_relation utr ON u.id = utr.user_id
WHERE
utr.type_id IN ( 1, 2 )
AND utr.type_id NOT IN ( 9 )

三、基于全文索引表结构设计
3.1、全文索引
说到全文索引大都数人第一时间想到的可能是ElasticSearch,主要是通过分词后建立倒排序索引完成对自然语言的搜索。在Mysql中也是支持全文索引的,这里简单介绍一下Mysql的全文索引,后面可以新写一篇专门介绍如何使用Mysql全文索引,Mysql中全文索引主要支持以下两种分词器:
默认分词(自然语言分词)
默认分词器基于空格、标点符号、停止词的来分隔单词,主要针对英文按单词分词,对中文这种没有空格的语言就难搞。
使用方法:
CREATE FULLTEXT INDEX idx_content ON articles(content);
或
ALTER TABLE articles ADD FULLTEXT INDEX idx_content(content);
ngram分词
ngram分词器将文本分解成所有可能的连续字符子串(n-gram),其中n是一个指定的数字,表示子串的长度。它不会区分单词边界,因此适用于没有明确单词分隔符的语言,如中文、日文和韩文。它为每个n-gram创建索引条目,可以用于执行全文搜索。它适用于中文、日文、韩文等不使用空格分隔单词的语言。适用于需要按字符序列进行搜索的场景。
Mysql默认ngram分词器的长度为2:
查询默认ngram分词器的长度:
show VARIABLES like 'ngram_token_size'
SET GLOBAL ngram_token_size = 2;
使用方法:
ALTER TABLE `test_user`
ADD FULLTEXT INDEX `idx_user_type` (`user_type`) WITH PARSER ngram
MySQL 全文索引支持三种查询模式:
1. 布尔模式(IN BOOLEAN MODE);
select * from test_user where MATCH (user_type) against ('+01' in Boolean MODE);
常见的Boolea匹配模式有:
- +操作、必须出现
- -操作、必须不出现
- ~操作、负相关性
- >操作、增加相关性
- <操作、减少相关性
- *操作、(通配符)
- “”、短语查询
- 小括号、分组查询
- 空格、多个关键词
2. 自然语言模式(NATURAL LANGUAGE MODE);
select * from test_user where MATCH (user_type) against ('01' IN NATURAL LANGUAGE MODE);
3. 查询拓展(QUERY EXPANSION);
SELECT *
FROM your_table
WHERE MATCH(your_column) AGAINST('+your_search_query' WITH QUERY EXPANSION);
本文主要使用ngram分词+布尔模式查询
3.2、添加编码字段
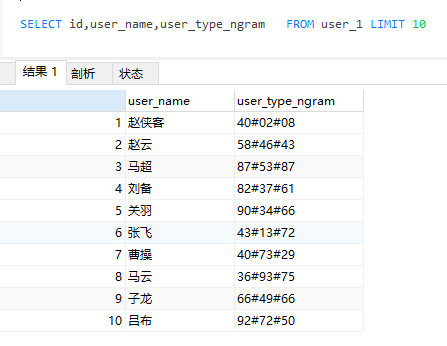
为了使用单表可以查出关联的数据我们需要对用户表添加一个字段user_type_ngram记录用户的分类,然后对用户的分类进行编码,如用户ID=1的赵侠客有type_id=40、2、8三个分类,我们将user_type_ngram编码40#02#08,因为ngram默认长度为2,所以2和8必需要编码成2位长度02和08后才能被分词搜索出来。
ALTER TABLE user
ADD COLUMN `user_type_ngram` varchar(255) NOT NULL DEFAULT '' COMMENT '用户分类编码' ;
3.3、添加全文索引
当添加user_type_ngram字段后我们需要对该字段添加一个全文索引,指定分词器类型为ngram:
ALTER TABLE `user`
ADD FULLTEXT INDEX `idx_user_type_ngram` (`user_type_ngram`) WITH PARSER ngram;
3.4、查询
有了idx_user_type_ngram这个全文索引后我们就可以使用单表完成各种多表关联查询的需要了
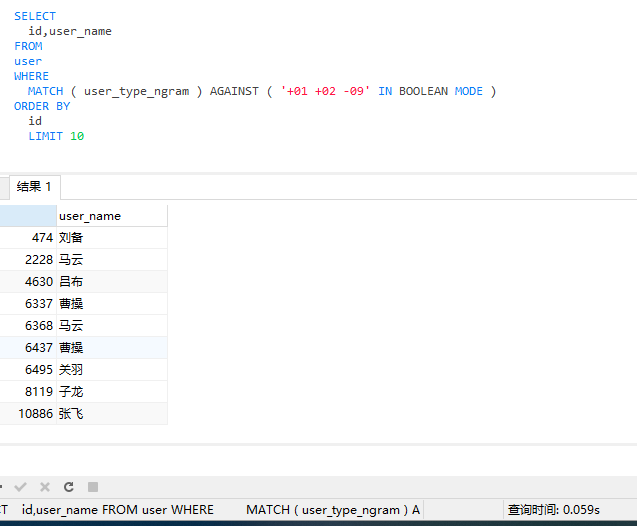
90后不是富二代的JAVA程序员
这条需求就是查询用户分类ID必需有1和2并且不能有9,我们使用全文索引的布尔模式为:(+01 +02 -09)
SELECT
id,user_name
FROM
user
WHERE
MATCH ( user_type_ngram ) AGAINST ( '+01 +02 -09' IN BOOLEAN MODE )
ORDER BY
id
LIMIT 10
因为使用了全文索引,查询速度也是非常快的,在机器非常差的情况下耗时0.059S,比使用多表关联查询耗时0.141S快了1倍多。
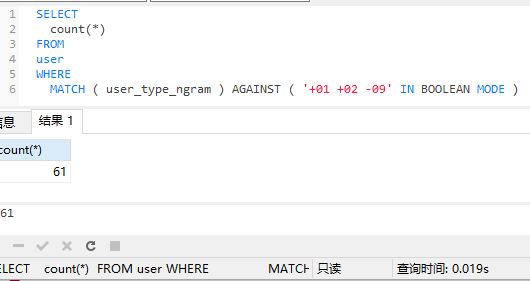
统计用户数量:
SELECT
count(*) AS user_cout
FROM
user
WHERE
MATCH ( user_type_ngram ) AGAINST ( '+01 +02 -09' IN BOOLEAN MODE )
耗时:0.019s比关联查询0.178快了一个数量级
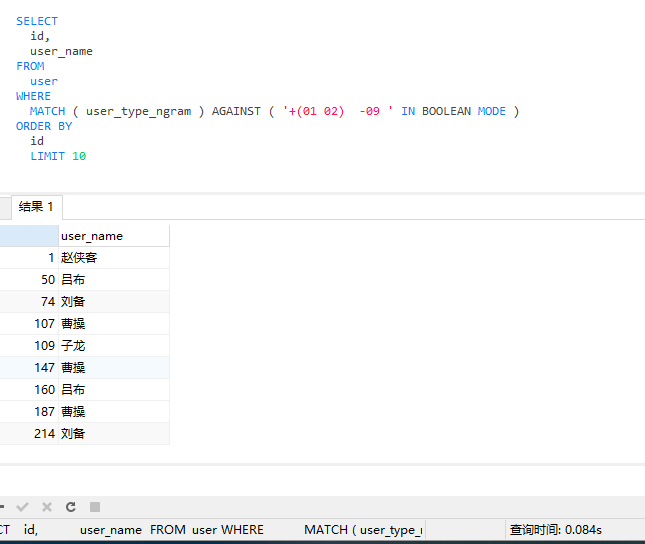
不是富二代的90后和JAVA程序员
这里要查出90后或者是JAVA程序员可以用+(01 02) 然后去除富二代用 -09
SELECT
id,
user_name
FROM
user
WHERE
MATCH ( user_type_ngram ) AGAINST ( '+(01 02) -09 ' IN BOOLEAN MODE )
ORDER BY
id
LIMIT 10
可以看出这条SQL耗时0.084S比使用关联查询的0.162s也是快了一倍
统计数量:
SELECT
count(*)
FROM
user
WHERE
MATCH ( user_type_ngram ) AGAINST ( '+(01 02) -09 ' IN BOOLEAN MODE )
耗时0.025S比关联查询数量统计0.148ms快了一个数量级

总结
本文介绍了基于Mysql文本索引使用单表查询解决在关系型数据一对多的应用场景下使用多表设计导致关联查询SQL变复杂、查询性能变慢的问题,这种设计主要有以下优点和缺点:
优点:
- 查询简单、几乎所有的查询都可以走单表,通过Boolean匹配可以很简单的实现以前联合多表的复杂查询
- 提升性能、使用了全文索引+单表在查询性能上比单表要快很多
- 数据一致性、全文索引是Mysql本身就支持的一种索引类型,不需将数据同步到像ElastiSearch这样的数据库,还要解决数据一致性的问题
缺点:
- 索引空间变大、因为要创建倒排序索引所以索引空间会大大增加
- 影响更新字段性能、更新字段后对应的倒排索引也需要更新这会对更新性能产生一定的影响
- 字段类型修改、不像ElastiSearch字段类型不可修改,MySQL中是可以修改的,但是创建全文索引后修改字段类型,全文索引中是不会立刻更新的,全量更新全文索引需要耗费大量性能