前言
这篇文章将用三个版本的归并排序,为大家分析使用协程排序的时间开销(被排序的切片长度由128到1000w)
本期demo地址:https://github.com/BaiZe1998/go-learning
往期视频讲解 📺:B站:白泽talk,公众号:白泽talk

认为并发总是更快
- 线程:OS 调度的基本单位,用于调度到 CPU 上执行,线程的切换是一个高昂的操作,因为要求将当前 CPU 中运行态的线程上下文保存,切换到可执行态,同时调度一个可执行态的线程到 CPU 中执行。
- 协程:线程由 OS 上下文切换 CPU 内核,而 Goroutine 则由 Go 运行时上下文切换协程。Go 协程占用内存比线程少(2KB/2MB),协程的上下文切换比线程快80~90%。
🌟 GMP 模型:
- G:Goroutine
- 执行态:被调度到 M 上执行
- 可执行态:等待被调度
- 等待态:因为一些原因被阻塞
- M:OS thread
- P:CPU core
- 每个 P 有一个本地 G 队列(任务队列)
- 所有 P 有一个公共 G 队列(任务队列)
协程调度规则:每一个 OS 线程(M)被调度到 P 上执行,然后每一个 G 运行在 M 上。
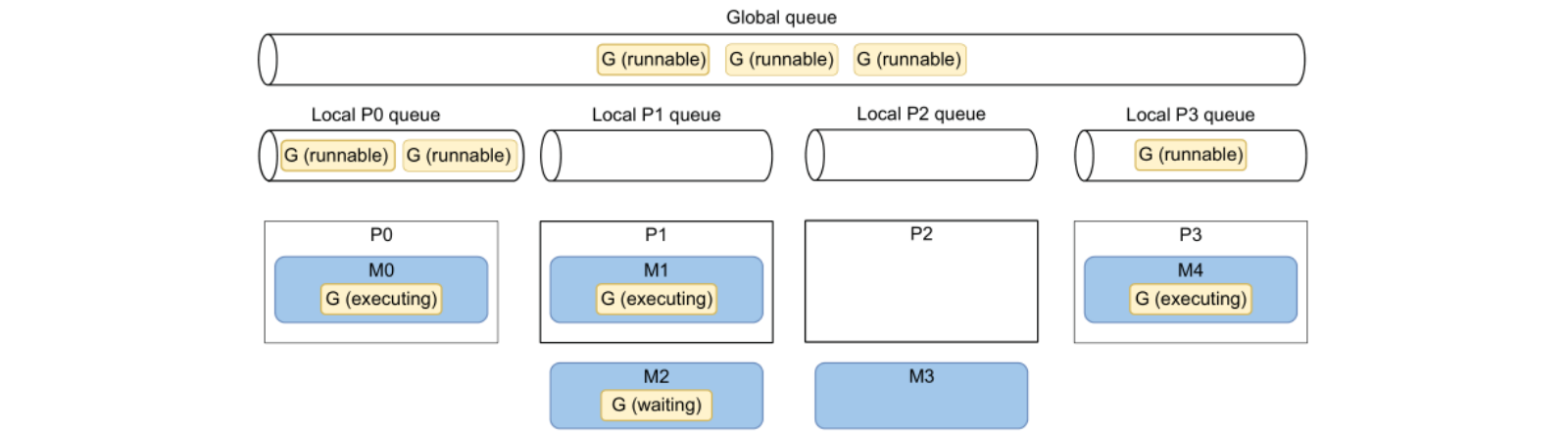
🌟 上图中展示了一个4核 CPU 的机器调度 Go 协程的场景:
此时 P2 正在闲置因为 M3 执行完毕释放了对 P2 的占用,虽然 P2 的 Local queue 中已经空了,没有 G 可以调度执行,但是每隔一定时间,Go runtime 会去 Global queue 和其他 P 的 local queue 偷取一些 G 用于调度执行(当前存在6个可执行的G)。
特别的,在 Go1.14 之前,Go 协程的调度是合作形式的,因此 Go 协程发生切换的只会因为阻塞等待(IO/channel/mutex等),但 Go1.14 之后,运行时间超过 10ms 的协程会被标记为可抢占,可以被其他协程抢占 P 的执行。
归并案例
🌟 为了印证有时候多协程并不一定会提高性能,这里以归并排序为例举三个例子:
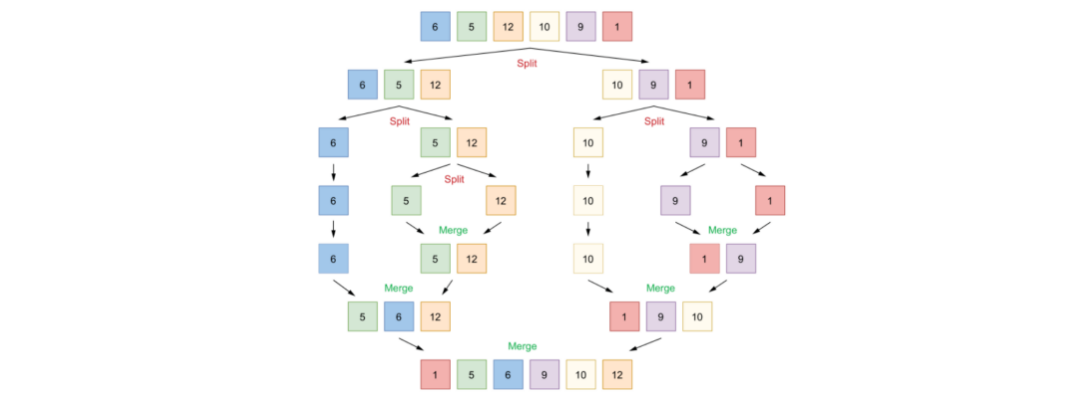
主函数:
func main() {
size := []int{128, 512, 1024, 2048, 100000, 1000000, 10000000}
sortVersion := []struct {
name string
sort func([]int)
}{
{"Mergesort V1", SequentialMergesortV1},
{"Mergesort V2", SequentialMergesortV2},
{"Mergesort V3", SequentialMergesortV3},
}
for _, s := range size {
fmt.Printf("Testing Size: %d\n", s)
o := GenerateSlice(s)
for _, v := range sortVersion {
s := make([]int, len(o))
copy(s, o)
start := time.Now()
v.sort(s)
elapsed := time.Since(start)
fmt.Printf("%s: %s\n", v.name, elapsed)
}
fmt.Println()
}
}
v1的实现:
func sequentialMergesort(s []int) {
if len(s) <= 1 {
return
}
middle := len(s) / 2
sequentialMergesort(s[:middle])
sequentialMergesort(s[middle:])
merge(s, middle)
}
func merge(s []int, middle int) {
// ...
}
v2的实现:
func SequentialMergesortV2(s []int) {
if len(s) <= 1 {
return
}
middle := len(s) / 2
var wg sync.WaitGroup
wg.Add(2)
go func() {
defer wg.Done()
SequentialMergesortV2(s[:middle])
}()
go func() {
defer wg.Done()
SequentialMergesortV2(s[middle:])
}()
wg.Wait()
Merge(s, middle)
}
v3的实现:
const max = 2048
func SequentialMergesortV3(s []int) {
if len(s) <= 1 {
return
}
if len(s) < max {
SequentialMergesortV1(s)
} else {
middle := len(s) / 2
var wg sync.WaitGroup
wg.Add(2)
go func() {
defer wg.Done()
SequentialMergesortV3(s[:middle])
}()
go func() {
defer wg.Done()
SequentialMergesortV3(s[middle:])
}()
wg.Wait()
Merge(s, middle)
}
}
耗时对比:
Testing Size: 128
Mergesort V1: 10.583µs
Mergesort V2: 211.25µs
Mergesort V3: 7.5µs
Testing Size: 512
Mergesort V1: 34.208µs
Mergesort V2: 500.666µs
Mergesort V3: 60.291µs
Testing Size: 1024
Mergesort V1: 48.666µs
Mergesort V2: 643.583µs
Mergesort V3: 47.084µs
Testing Size: 2048
Mergesort V1: 94.666µs
Mergesort V2: 786.125µs
Mergesort V3: 77.667µs
Testing Size: 100000
Mergesort V1: 6.810917ms
Mergesort V2: 58.148291ms
Mergesort V3: 4.219375ms
Testing Size: 1000000
Mergesort V1: 62.053875ms
Mergesort V2: 558.586458ms
Mergesort V3: 37.99375ms
Testing Size: 10000000
Mergesort V1: 632.3875ms
Mergesort V2: 5.764997041s
Mergesort V3: 388.343584ms
由于创建协程和调度协程本身也有开销,第二种情况无论多少个元素都使用协程去进行并行排序,导致归并很少的元素也需要创建协程和调度,开销比排序更多,导致性能还比不上第一种顺序归并。
特别在切片长度为1000w的时候,基于v2创建的协程数量共计百万。
而在本台电脑上,经过调试第三种方式可以获得比第一种方式更优的性能,因为它在元素大于2048个的时候,选择并行排序,而少于则使用顺序排序。但是2048是一个魔法数,不同电脑上可能不同。这里这是为了证明,完全依赖并发/并行的机制,并不一定会提高性能,需要注意协程本身的开销。
小结
可以克隆项目之后,使用协程池写一个归并排序,进一步比较内存消耗。


![World of Warcraft [CLASSIC][80][Grandel] Call to Arms: Arathi Basin](https://i-blog.csdnimg.cn/direct/0c0ef27243f348fb9ba635b2cc0f7044.png)