[大模型 | 类案检索] Precedent-Enhanced Legal Judgment Prediction with LLM and Domain-Model Collaboration
key point
会议:EMNLP2023
贡献:提出了一个结合领域模型和大模型的先例增强的LJP框架,其实主要是用到的大模型,比较创新。
story
1. 文章的背景:LJP问题很重要,先例在判决的过程中也很重要。
2. 一个具体的研究问题:如何有效地利用先例信息来提高法律判决预测的准确性?
3. 别人是怎么做的:文中没有提到其他人用先例来指导判决预测,但其实是有的。
4. 别人的方法中存在什么问题:大模型难以处理有大量抽象标签的任务,而领域模型的理解能力有限。
5.别人的方法出现这些问题的原因是什么:大模型提示长度有限,领域模型天然比大模型缺乏对自然语言的理解能力。
6. 你发现了什么新的现象或者信息,并利用这一现象提出一个新的方法来避免前人的问题:LLMs 在理解复杂自然语言方面具有优势,而领域特定模型在处理特定任务方面效率高。
7. 你的方法里面真正的挑战是什么:如何有效地将 LLMs 和领域特定模型结合起来,利用先例信息提高 LJP 的准确性?
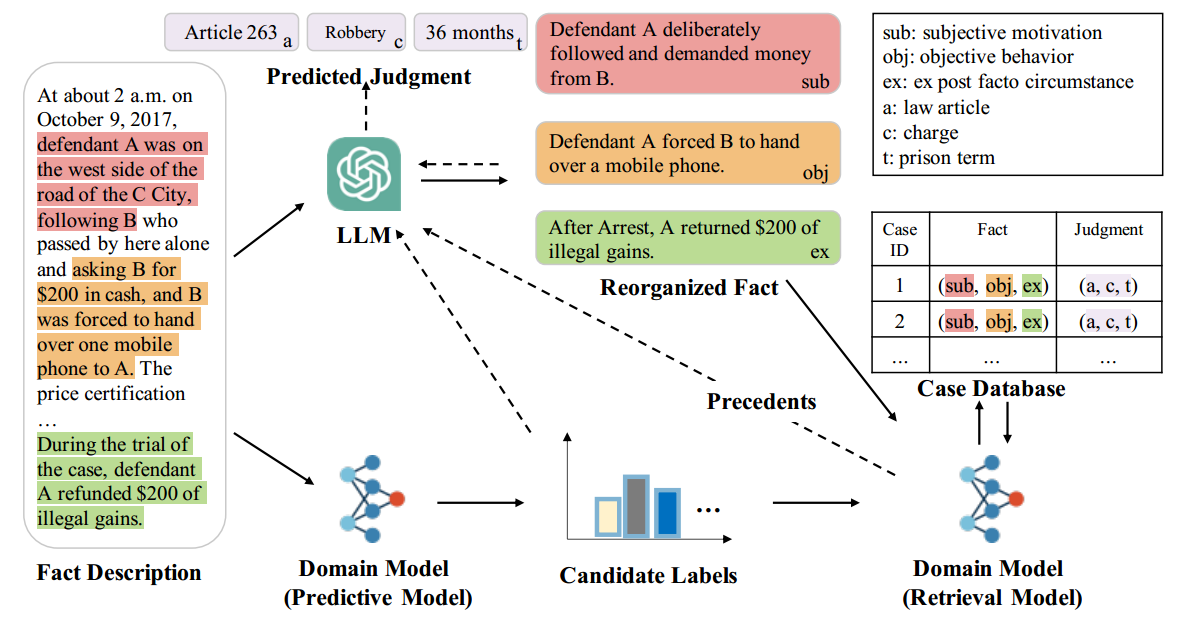
8. 为了克服挑战,你提出的具体的设计是什么:PLJP框架
具体设计:
- 案例数据库构建:
使用 LLMs 将案例事实描述重新组织为主观动机、客观行为和事后情况三个部分,缩短事实长度,方便检索先例。
- 法律判决预测:
预测模型:使用领域特定模型预测三个子任务(法律条文、罪名、刑期)的候选标签。
检索模型:使用领域特定模型根据重新组织的事实检索合适的先例。
LLMs:将给定案例与先例堆叠,通过上下文先例理解进行最终预测。
[对比学习 | 损失函数] Exploiting Contrastive Learning and Numerical Evidence for Confusing Legal Judgment Prediction
key point
本文提出了一种基于MoCo对比学习和弱监督数值证据进行易混淆的法律判决预测的框架,主要解决的是对文本或数字上仅有细微差别的易混淆案件做出判决结果的问题。
框架主要包含两部分:
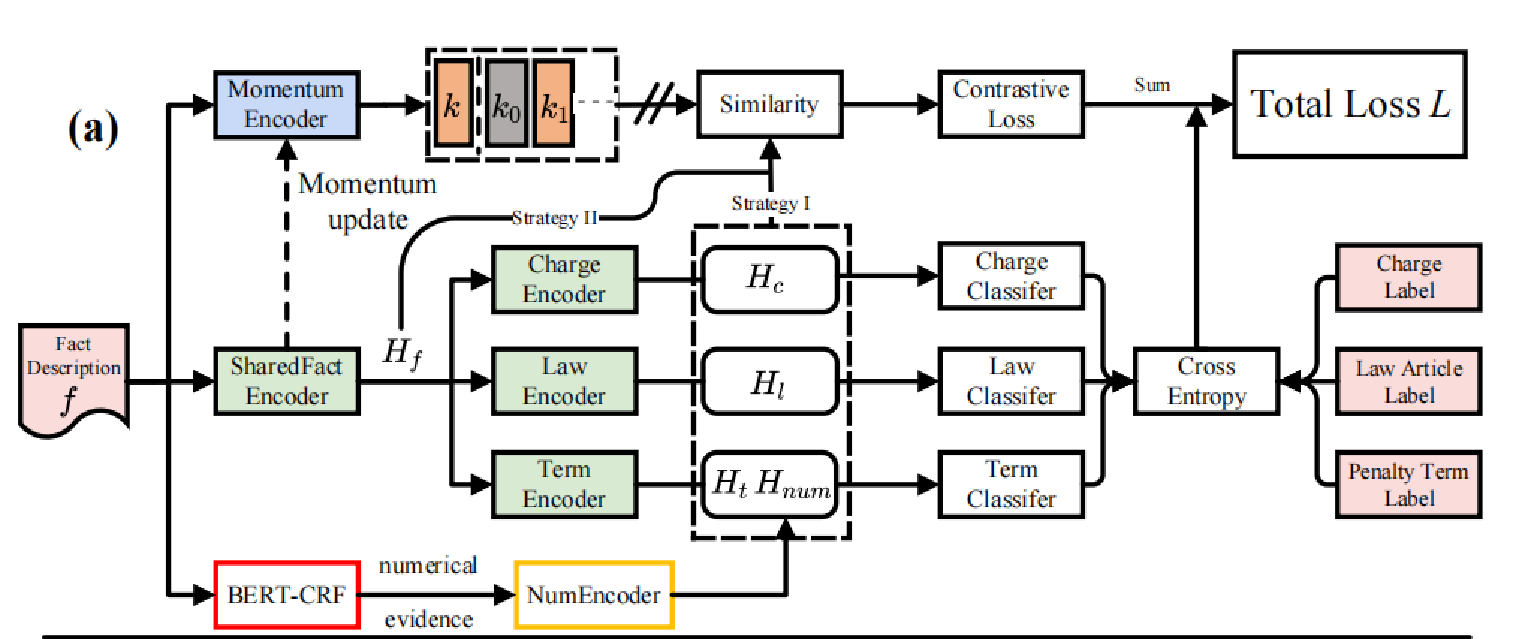
一是动量对比监督学习,引入了基于Moco的监督对比学习用于法律判决(LJP)和两种构建正例对的策略通过对比不同但是相近样本间的相似性与差异性;
二是弱监督数值证据提取,使用一个基于BERT-CRF的命名实体识别模型来从中提取犯罪总额作为数值证据利用法律文书中隐含的数值信息,为判决预测提供额外线索。
story
- 文章背景:LJP是很吸引人的课题,但是LJP模型的性能受到“混淆案件”的阻碍,这些案件之间只有细微的文本或数字差异,但具有完全不同的判决结果。
- 具体的研究问题:如何区分“混淆案件”,并准确预测其判决结果,特别是罪名和刑罚期限。
- 对于这个问题别人是怎么做的:包括手动标注区分性法律属性,通过GNN学习区分性表示,将事实描述分解成不同情况。
- 别人的方法中存在的问题:标准的交叉熵损失无法区分不同的错误分类,难以直接从事实描述中推导出精确的犯罪金额,这样会影响刑期的预测。
- 出现这些问题的原因是什么:损失函数的局限性,数据表示的局限性,没有利用好事实描述中的数值信息。
- 你发现了什么新的现象或信息,并利用这一现象提出一个新的方法来避免前人的问题:数值证据(例如犯罪金额)对于预测某些类型案件的刑罚期限至关重要。为了更好地利用数值证据,文章将犯罪金额的提取形式化为一个命名实体识别 (NER) 任务,并使用预训练的数字编码器模型来保持数值证据的数值意义。
- 你方法里真正的挑战是什么:首先,罪名的类别数量大,在mini-batch中找到足够的负例比较困难;其次,多任务学习中,任务之间会有矛盾,由于共享特征。
- 为了克服挑战,你提出的具体的设计是什么:引入 MoCo 基于监督对比学习,并使用大尺寸的动量更新队列来提供足够的负例。探索构建正例对的最佳策略,以避免多任务学习中的矛盾现象。
[多被告 | 自然语言推理] Multi-Defendant Legal Judgment Prediction via Hierarchical Reasoning
key point
基于层次推理的多被告判决预测,提出了一个名为HRN的层次推理网络和一个名为MultiLJP的中文LJP多被告刑事案件数据集。
拼接了近年提出的一些编码器解码器模型,但是工作量在于提出的那个数据集。
考虑了判案过程中会考虑的两个因素,一个是犯罪关系,另一个是量刑情况,进行了正向预测和反向验证。
发表于EMNLP2023。
introduction
- idea的背景:根据现在公布的法律判决来看,如今多被告判决预测需求很大。
- 一个具体的研究问题:多被告刑事案件事实描述中的多个被告之间有复杂的相互作用关系,如何更加精准地做出多被告判决预测是一个问题。
- 别人是怎么做的:早期是基于规则和机器学习,后来人们发现LJP三个任务存在依赖关系,用神经网络来做,后面还有利用知识图谱、标签信息和预训练语言模型的。
- 别人的方法中存在什么问题:多被告问题上表现差,以及可解释性差,多被告任务没有标准的数据集。
- 别人的方法出现这些问题的原因是什么:忽略了多个被告间复杂的相互作用关系,没有按照法官思维来构建模型。
- 本文发现了什么新的现象或者信息,并利用这一现象提出一个新的方法来避免前人的问题:
- 为了区分不同被告之间的不同判决结果,法官必须厘清被告之间的刑事关系,以确定被告是否具有相同的法律条款和指控,以及影响每个被告刑罚条款的量刑情况。根据这些中间推理结果,法官按照向前和向后的顺序确定并验证每个被告的判决结果(法律条款、指控和处罚条款)。向前预测和向后验证背后的动机源于法律推理的复杂性,其中证据和结论可以相互依存。
- 本文方法里面真正的挑战是什么:在多被告判决预测过程,如何模拟人类法官的司法逻辑,并对复杂的推理链进行建模。
- 为了克服挑战,作者提出的具体的设计是什么:
- 用层次推理链来模拟多被告判决过程,提出了层次推理网络(HRN)方法;
- 层次推理链分为两层:第一层用于从事实描述中识别被告间的关系和每个被告的量刑情况;第二层则分别使用前向预测和后向验证的方式,正序和逆序地根据前面得到的特征来逐一预测法条、罪名和刑期。
- 将推理链转化为Seq2Seq生成任务。
Method
简单介绍一下Hierarchical Reasoning Network (HRN) 模型的工作流程:
首先,将案件事实描述和被告信息输入给模型;
然后,模型根据输入确定犯罪关系和量刑情况;
接着,模型根据案件事实描述、特定被告的姓名、犯罪关系和量刑情况,预测法条、罪名和刑期,上述为前向预测,还需要用反向验证对三个结果逆序预测,确保预测的一致性。
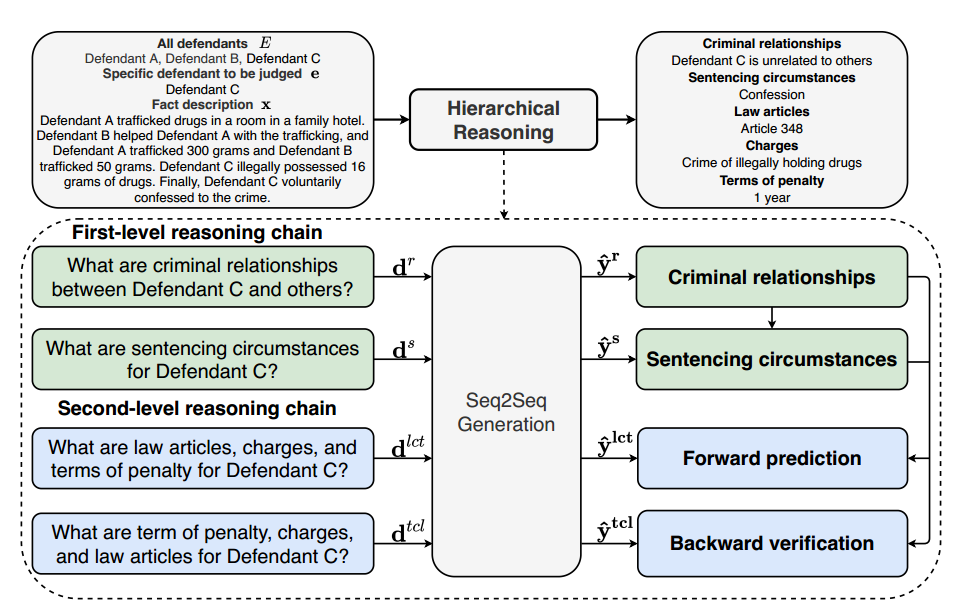
在这个过程中,模式使用的是Seq2Seq生成框架,对于超过编码器长度限制的事实描述,采用FID方法分割段落,结合编码器的多个段落表示来生成预测结果。
在测试阶段,模型使用贪婪解码策略生成前向和反向预测结果,并选择置信度最高的链作为最终预测。
[三段论 | 法院观点生成] Syllogistic Reasoning for Legal Judgment Analysis
key point
用于法律判决分析的三段论推理,构建了第一个三段论推理数据集,定义了四个相互关联的任务,以支持使用三段论推理最后得到判决预测结果。任务使用大模型完成。
也就是一个框架,这个框架首先用法条检索任务得到相关法条作为三段论推理的大前提,再用犯罪要素生成得到小前提,接着用法条解释生成根据大前提和小前提生成使用条款和相应的理由,最后由判决预测根据适用法条生成判决结果。
基于这个框架,作者构建了一个包含案件事实和四个任务生成结果的数据集,并且在四个大模型上进行了评测。
发表于EMNLP2023。
introduction
- 文章背景:大语言模型发展迅速,但是由于缺乏可靠的法律判决分析,人们不太信任模型生成的判决预测结果。
- 本文关注的一个具体的研究问题:如何提高法律判决的可靠度,或者信任度。
- 对于这个问题别人是怎么做的:其他研究者主要通过法律判断预测(LJP)和法院观点生成(CVG)来探索定制任务和数据集,提出有效的模型。这些方法主要集中在预测法律判断的结果,而没有提供详细的分析过程。
- 别人的方法存在什么问题:没有提供法律判决的详细分析过程,导致预测结果缺乏可信赖度,抑或者生成的理由不具有说服力,不能代表导致最终结果的整个分析过程。
- 别人的方法出现这些问题的原因是什么:现有的法律判决分析资源不足,没有依据法律推理规则来生成理由。
- 你发现了什么新的现象或者信息,并利用这一现象提出一个新的方法来避免前人的问题:本文发现了三段论推理在法律判决预测中的重要性。并提出了一个新的方法,即构建一个专门的三段论推理数据集,并使用大型语言模型进行深入分析。
- 你的方法里真正的挑战是什么:如何构建一个高质量、大规模的三段论数据集。
- 为了克服挑战,你提出的具体设计是什么:
- 定义了四个相互关联的任务:法条检索(AR)、犯罪要素生成(CEG)、法条解释生成(AIG)和法律判断预测(LJP)。
- 构建了第一个中文SLJA数据集,并通过法律背景的工人手动校正ChatGPT生成的结果,以确保数据集的质量。
- 选择了四种最先进的LLMs作为基准,进行了广泛的实验和深入分析,以评估三段论推理对LLMs性能的影响。
[刑期预测 | 法条感知] ML-LJP: Multi-Law Aware Legal Judgment Prediction
key point
这篇文章发表在SIGIR2023上,题目是多法条感知的法律判决预测,文章针对现在LJP任务中出现的刑期预测效果差的问题,提出了多法条感知的LJP模型,通过提取事实的特定标签和捕获多个法条之间的高阶相互作用来改进LJP模型。
story
- 文章背景:LJP任务是legal AI领域的一个非常重要的任务。
- 一个具体的问题:如何提高法律判决预测的性能,特别是刑期预测,同时考虑与指控和刑期相关的法律条款。
- 别人是怎么做的:早期是基于规则的数学方法,但是提取特征很麻烦,后来人们都用深度学习,大多数人都是把LJP的三个子任务当做三个单标签分类任务,Zhong第一次用拓扑学习对三个任务的依赖关系进行建模。Yue将事实描述分成不同的部分来进行预测,Xu用图蒸馏从标签中提取判别特征,Zhang等人使用对比学习来捕捉相似法条和罪名之间的细粒度差异。
- 别人的方法存在什么问题:没有充分模拟真实法律过程中法律条款之间的复杂交互作用,特别是没有考虑到不同法律条款对刑期判定的综合影响。
- 作者发现了什么新的现象或者信息,并利用这一现象提出一个新的方法来避免前人的问题:作者发现法律条款之间存在复杂的交互作用,这对刑期预测至关重要。因此,提出了一种新的多法条感知的法律判决预测方法(ML-LJP),通过将法律条款预测扩展为多标签分类任务,并使用图注意力网络(GAT)来学习多个法律条款之间的交互作用。
- 实现这个方法真正的挑战是什么:如何准确地从案件事实描述中提取与法律条款和指控相关的特征,并且如何有效地模拟法律条款之间的复杂交互作用。
- 为了克服挑战,作者提出的具体的设计是什么:
- 使用标签定义来转换事实描述的表示,生成标签特定的表示。
- 通过对比学习来区分不同标签定义中的相似内容。
- 应用图注意力网络(GAT)来学习多个法律条款之间的高阶交互作用。
- 设计了一种数字表示方法,以更好地定位和表示法律文本中的重要数字。
methodology
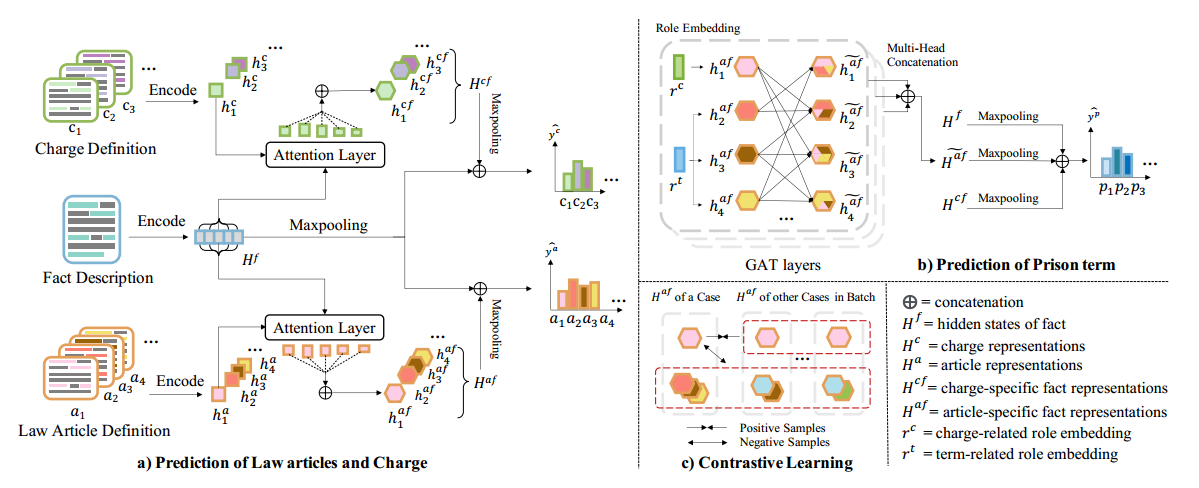
作者提出的ML-LJP模型如上图所示:
输入案件的事实描述后,用encoder转化为隐藏向量,在这个过程中作者设计了一种数字表示方法,将数字分割为尾数和指数,并结合数字后的单位进行编码,。
另外,模型还对法条和罪名的标签进行编码,获得向量表示,还是用标签定义作为query,对事实描述的隐藏向量进行attention操作,获取与特定法条或罪名标签相关的信息;
接着对标签特定事实表示和进行最大池化操作,结合全连接网络预测法条和罪名。
接下来进行刑期预测:
- 首先为不同类型的法律条款添加角色嵌入(role embedding)以区分它们在刑期预测中的作用。
- 使用图注意力网络(Graph Attention Network, GAT)来捕捉多个法律条款之间的高阶交互作用。
- 通过最大池化操作获取聚合的事实表示,然后结合全连接网络来预测刑期。
在模型中,还使用了对比学习来提高区分相似标签的能力。
[事件抽取 | 一致性约束] Legal Judgment Prediction via Event Extraction with Constraints
key point
基于约束和事件抽取的法律判决预测,发表于ACL2022。
主要贡献是,提出了利用事件抽取来解决LJP,首先为法律条文定义了一个分层结构,将法条整理成一个树状图,构建了一个带有事件标注的新LJP数据集,然后提出了一个在两种约束条件下联合学习LJP和事件抽取的模型,命名为EPM,这个模型优于baseline和SOTA。
story
- idea的背景:法律判决预测是一个很重要的任务。
- 一个具体的研究问题:如何提高法律判决预测的准确性。
- 别人是怎么做的:先前研究主要是使用机器学习分类、深度学习神经网络、注意力机制或者注入法律知识等方法来进行判决预测。
- 别人的方法中存在什么问题:这些方法通过共享参数在一个统一框架里联合学习三个子任务,只是利用子任务的预测结果作为辅助特征来相互影响,因此可能仍然预测不一致的结果。
- 别人的方法出现这些问题的原因是什么:过于依赖整体案件陈述而不是细粒度的事件信息,可能没有有效利用法条之间的层次结构和因果关系。
- 你发现了什么新的现象或者信息,并利用这一现象提出一个新的方法来避免前人的问题:研究发现,通过从案件事实中提取细粒度的关键事件信息,并基于这些信息进行预测,可以提高LJP的准确性。此外,利用法律条款之间的一致性约束可以确保预测结果的一致性。
- 你的方法里面真正的挑战是什么:真正的挑战在于如何有效地从法律文本中提取事件信息,并设计一个能够同时处理事件提取和法律判决预测的模型,同时还要确保跨任务约束得到满足。
- 为了克服挑战,你提出的具体的设计是什么:为了克服这些挑战,作者提出了一个基于事件的预测模型(Event-based Prediction Model, EPM),该模型通过以下设计来提高LJP的性能:
- 定义了法律事件的层次结构,并手动注释了一个新的LJP数据集以包含事件信息。
- 设计了输出约束来指导事件提取的学习过程。
- 引入了跨任务一致性约束,确保法律条款、指控和刑罚期限的预测结果相互一致。
- 通过实验验证了模型性能,证明了该方法在标准LJP数据集上超越了现有的SOTA模型。
methodology
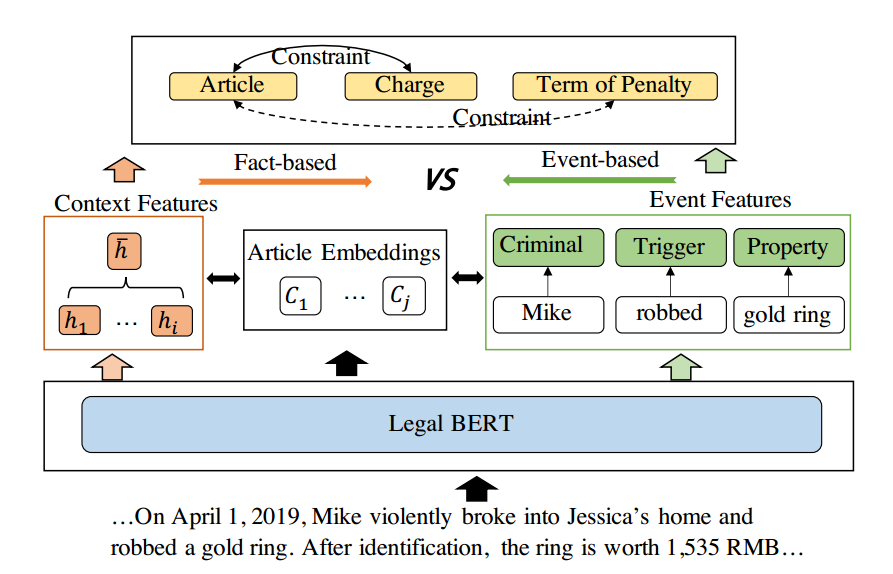
这张图显示了作者提出的baseline和EPM模型,baseline是左边的,首先用legal BERT将案件事实向量化,再平均池化提取出最重要的特征,然后和法条向量进行处理得到一个包含法律信息的案件事实特征,用来分别预测法条、罪名和刑期。右边是EPM模型,首先也是用legal BERT编码案件事实,然后通过事件抽取和LJP联合学习,得到最后的结果,结果之间也有约束。