数据结构:树形结构(树、堆)详解
- 一、树
- (一)树的性质
- (二)树的种类
- 二叉树
- 多叉树
- 满N叉树
- 完全N叉树
- (三)二叉树的实现
- 1、二叉树结构定义
- 2、二叉树功能实现
- (1)前序、中序、后序、层序遍历
- (2)二叉树结点个数
- (3) ⼆叉树叶⼦结点个数
- (4) 二叉树第k层结点个数
- (5)二叉树的深度/高度
- (6)⼆叉树查找值为x的结点
- (7)二叉树销毁
- (8)判断二叉树是否为完全二叉树
- 二、堆
- (一)堆的实现
- 1、堆的结构定义
- 2、堆的初始化
- 3、向上调整操作
- 4、向下调整操作
- 5、入堆操作
- 6、堆的扩容
- 7、出堆操作
- 8、堆的销毁
- 9、堆的判空、查看堆顶元素
- (二)哈夫曼编码实现
- 结束语
一、树
树的物理结构和逻辑结构上都是树形结构
(一)树的性质
• ⼦树是不相交的
• 除了根结点外,每个结点有且仅有⼀个⽗结点
• ⼀棵N个结点的树有N-1条边
(二)树的种类
树按照根节点的分支来分,可以分为二叉树和多叉树。
二叉树
二叉树(Binary Tree)
定义:每个节点最多有两个子节点的树结构。可以是空树,或者由一个根节点和左、右子树组成。
多叉树
多叉树(Multiway Tree)
定义:每个节点可以有多个子节点的树结构,节点子节点的数量没有限制。
树按照结点的特性来观察,又可以有满N叉树和完全N叉树
满N叉树
满N叉树是一种深度为K的二叉树,其中每一层的节点数都达到了该层能有的最大节点数。

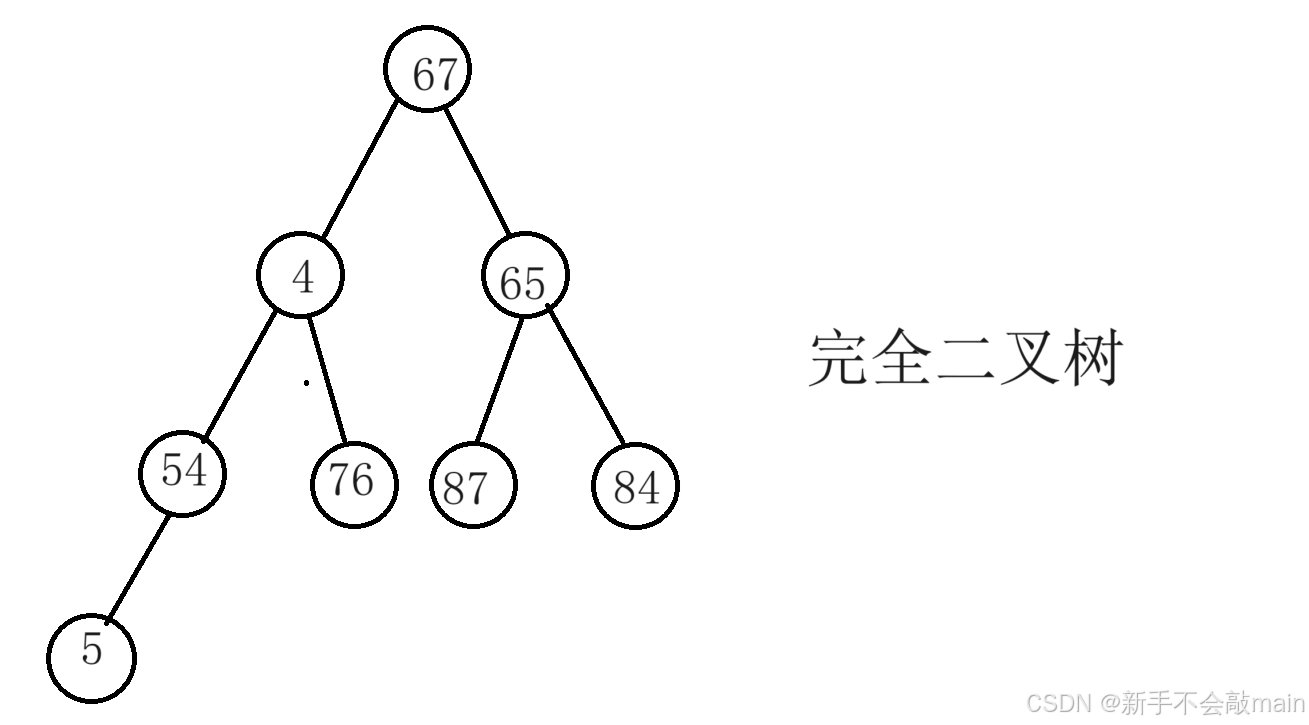
完全N叉树
除了最后一层外,每一层都被完全填满,并且最后一层所有节点都尽量靠左排列。
(三)二叉树的实现
1、二叉树结构定义
用 typedef 可以使得后面的使用范围更广
typedef int BTDataType;
typedef struct BinaryTreeNode
{
BTDataType data;
struct BinaryTreeNode* left;
struct BinaryTreeNode* right;
}BTNode;
2、二叉树功能实现
(1)前序、中序、后序、层序遍历
下面的层序遍历方式采用的是一层一层的处理方式
void PreOrder(BTNode* root) {
if (root == NULL) return;
printf("%d ", root->data);
PreOrder(root->left);
PreOrder(root->right);
return;
}
void InOrder(BTNode* root) {
if (root == NULL) return;
InOrder(root->left);
printf("%d ", root->data);
InOrder(root->right);
return;
}
void PostOrder(BTNode* root) {
if (root == NULL) return;
PostOrder(root->left);
PostOrder(root->right);
printf("%d ", root->data);
return;
}
void LevelOrder(BTNode* root) {
queue<BTNode*> q;
q.push(root);
while (!q.empty()) {
int num = q.size();
for (int i = 0; i < num; i++) {
BTNode* temp = q.front();
if(temp->left) q.push(temp->left);
if(temp->right) q.push(temp->right);
printf("%d ", temp->data);
q.pop();
}
printf("\n");
}
return;
}
(2)二叉树结点个数
两种方法都可以实现求结点个数,但是第二种需要另外创建变量接收返回值,因此第一种方式比较好
//方法一
int BinaryTreeSize(BTNode* root) {
if (root == NULL) return 0;
return 1 + BinaryTreeSize(root->left) +
BinaryTreeSize(root->right);
}
//方法二
void BinaryTreeSize(BTNode* root, int* psize) {
if (root == NULL) return;
if (root->left) {
(*psize)++;
BinaryTreeSize(root->left, psize);
}
if (root->right) {
(*psize)++;
BinaryTreeSize(root->right, psize);
}
return;
}
(3) ⼆叉树叶⼦结点个数
只需要统计叶子结点即可,和求普通结点个数相似
int BinaryTreeLeafSize(BTNode* root) {
if (root == NULL) return 0;
if (root->left == NULL && root->right == NULL) return 1;
return BinaryTreeLeafSize(root->left) + BinaryTreeLeafSize(root->right);
}
(4) 二叉树第k层结点个数
需要加一个二叉树层数的变量
int BinaryTreeLevelKSize(BTNode* root, int k) {
if (root == NULL) return 0;
if (k == 1) return 1;
return BinaryTreeLevelKSize(root->left, k - 1) + BinaryTreeLevelKSize(root->right, k - 1);
}
(5)二叉树的深度/高度
int BinaryTreeDepth(BTNode* root) {
if (root == NULL) return 0;
int a = BinaryTreeDepth(root->left);
int b = BinaryTreeDepth(root->right);
return (a > b ? a : b) + 1;
}
(6)⼆叉树查找值为x的结点
如果没有找到,不要忘记返回空
BTNode* BinaryTreeFind(BTNode* root, BTDataType x) {
if (root == NULL) return NULL;
if (root->data == x) return root;
BTNode* left = BinaryTreeFind(root->left, x);
if (left) return left;
BTNode* right = BinaryTreeFind(root->right, x);
if (right) return right;
return NULL;
}
(7)二叉树销毁
采用二级指针的方式传入,可以避免函数处理后在进行置空处理。
void BinaryTreeDestory(BTNode** root) {
if (*root == NULL) return;
BinaryTreeDestory(&((*root)->left));
BinaryTreeDestory(&((*root)->right));
free(*root);
*root = NULL;
return;
}
(8)判断二叉树是否为完全二叉树
这段代码是老夫目前想了许久,觉得很有不错的代码,先不考虑它的实现复杂度以及简洁程度,它实现的功能不错,可以将二叉树包括空结点放在队列之中,自己觉得很好,哈哈,也许你没看到这句,那我就放心了。
bool BinaryTreeComplete(BTNode* root) {
queue<BTNode*> q;
BinaryTreePushQueue(root, q);
while (!q.empty()) {
if (q.front() != NULL) q.pop();
else break;
}
while (!q.empty()) {
if (q.front() == NULL) q.pop();
else return false;
}
return true;
}
void BinaryTreePushQueue(BTNode* root, queue<BTNode*>& q) {
vector<vector<BTNode*>> v;
BinaryNodePushVector(root, v, 0);
for (int i = 0; i < v.size(); i++) {
for (auto x : v[i]) {
q.push(x);
}
}
return;
}
void BinaryNodePushVector(BTNode* root, vector<vector<BTNode*>>& v, int k) {
if (v.size() == k) v.push_back(vector<BTNode*>());
if (root == NULL) {
v[k].push_back(NULL); //如果不处理空结点,取消这步即可
return;
}
v[k].push_back(root);
BinaryNodePushVector(root->left, v, k + 1);
BinaryNodePushVector(root->right, v, k + 1);
return;
}
二、堆
堆的物理结构是一段连续空间,但是逻辑机构是树形结构
(一)堆的实现
1、堆的结构定义
下面通过宏函数来实现交换,可以使得交换简便,或者用指针也行。
typedef int HeapDataType;
typedef struct Heap {
HeapDataType* __data;
HeapDataType* data;
int count;
int capacity;
}Heap;
#define SWAP(a ,b){\
HeapDataType c = (a);\
(a) = (b);\
(b) = (c);\
}
2、堆的初始化
用偏移量的方式,节约了内存。
从数组下标为1开始分配结点,使得后面求父节点,左右孩子运算和逻辑更简单
void HeapInit(Heap* pHeap) {
assert(pHeap);
pHeap->__data = (HeapDataType*)malloc(sizeof(HeapDataType));
pHeap->data = pHeap->__data - 1;
pHeap->capacity = 1;
pHeap->count = 0;
return;
}
3、向上调整操作
可以使用递归或者是循环来实现向上调整
void Heap_UP_Update(Heap* pHeap, int i) {
assert(pHeap);
while (FATHER(i) >= 1 && pHeap->data[FATHER(i)] > pHeap->data[i]) {
SWAP(pHeap->data[FATHER(i)], pHeap->data[i]);
i = FATHER(i);
}
return;
}
void DG_Heap_UP_Update(Heap* pHeap, int i) {
assert(pHeap);
if (FATHER(i) < 1) return;
if (pHeap->data[FATHER(i)] > pHeap->data[i]) {
SWAP(pHeap->data[FATHER(i)], pHeap->data[i]);
i = FATHER(i);
DG_Heap_UP_Update(pHeap, i);
}
return;
}
4、向下调整操作
void Heap_DOWN_Update(Heap* pHeap, int i) {
assert(pHeap);
int size = pHeap->count - 1;
while (LEFT(i) <= size) {
int l = LEFT(i), r = RIGHT(i), ind = i;
if (pHeap->data[ind] > pHeap->data[l]) ind = l;
if (r <= size && pHeap->data[ind] > pHeap->data[r]) ind = r;
if (ind == i) break;
SWAP(pHeap->data[i], pHeap->data[ind]);
i = ind;
}
return;
}
5、入堆操作
void HeapPush(Heap* pHeap, HeapDataType x) {
assert(pHeap);
HeapCheckCapacity(pHeap);
pHeap->data[pHeap->count + 1] = x;
DG_Heap_UP_Update(pHeap, pHeap->count + 1);
pHeap->count += 1;
return;
}
6、堆的扩容
void HeapCheckCapacity(Heap* pHeap) {
assert(pHeap);
if (pHeap->capacity == pHeap->count) {
HeapDataType* temp = (HeapDataType*)realloc(pHeap->__data, 2 * pHeap->capacity * sizeof(HeapDataType));
if (!temp) {
perror("Heap Realloc Fail!");
exit(1);
}
pHeap->__data = temp;
pHeap->capacity *= 2;
}
return;
}
7、出堆操作
void HeapPop(Heap* pHeap) {
assert(pHeap);
assert(!HeapEmpty(pHeap));
pHeap->data[1] = pHeap->data[pHeap->count];
Heap_DOWN_Update(pHeap, 1);
pHeap->count -= 1;
return;
}
8、堆的销毁
void HeapDestroy(Heap* pHeap) {
assert(pHeap);
free(pHeap->__data);
pHeap->data = NULL;
pHeap->__data = NULL;
pHeap->capacity = 0;
pHeap->count = 0;
return;
}
9、堆的判空、查看堆顶元素
int HeapEmpty(Heap* pHeap) {
assert(pHeap);
return pHeap->count == 0;
}
HeapDataType HeapTop(Heap* pHeap) {
assert(!HeapEmpty(pHeap));
return pHeap->data[1];
}
(二)哈夫曼编码实现
#define _CRT_SECURE_NO_WARNINGS
#include<stdio.h>
#include<stdlib.h>
#include<time.h>
#include<string.h>
#include<algorithm>
#include<unordered_map>
#include<vector>
using namespace std;
#define FATHER(i) ((i) / 2)
#define LEFT(i) ((i) * 2)
#define RIGHT(i) ((i) * 2 + 1)
typedef struct Node {
char* c;
int freq;
struct Node* lchild, * rchild;
}Node;
template<typename T>
void Swap(T& a, T& b) {
T c = a;
a = b;
b = c;
return;
}
//void swap(Node* a, Node* b) {
// Node* c = a;
// a = b;
// b = c;
// return;
//}
Node* getNewNode(int freq,const char* c) {
Node* p = (Node*)malloc(sizeof(Node));
p->freq = freq;
p->c = _strdup(c);
p->lchild = p->rchild = NULL;
return p;
}
void clear(Node* root) {
if (root == NULL) return;
clear(root->lchild);
clear(root->rchild);
free(root);
return;
}
typedef struct heap {
Node** data, **__data;
int size, count;
}heap;
heap* initHeap(int n) {
heap* p = (heap*)malloc(sizeof(heap));
p->__data = (Node**)malloc(sizeof(Node*) * n);
p->data = p->__data - 1;
p->size = n;
p->count = 0;
return p;
}
int empty(heap* h) {
return h->count == 0;
}
int full(heap* h) {
return h->count == h->size;
}
Node* top(heap* h) {
if (empty(h)) return NULL;
return h->data[1];
}
//void up_update(Node** data, int i) {
// while (FATHER(i) >= 1) {
// int ind = i;
// if (data[i]->freq < data[FATHER(i)]->freq) {
// swap(data[i], data[FATHER(i)]);
// }
// if (ind == i) break;
// i = FATHER(i);
// }
// return;
//}
void up_update(Node** data, int i) {
while (i > 1 && data[i]->freq < data[FATHER(i)]->freq) {
Swap(data[i], data[FATHER(i)]);
i = FATHER(i);
}
return;
}
void down_update(Node** data, int i, int n) {
while (LEFT(i) <= n) {
int ind = i, l = LEFT(i), r = RIGHT(i);
if (data[i]->freq > data[l]->freq) ind = l;
if (RIGHT(i) <= n && data[r]->freq < data[ind]->freq) ind = r;
if (ind == i) break;
Swap(data[ind], data[i]);
i = ind;
}
return;
}
void push(heap* h, Node* node) {
if (full(h)) return;
h->count += 1;
h->data[h->count] = node;
up_update(h->data, h->count);
return;
}
void pop(heap* h) {
if (empty(h)) return;
h->data[1] = h->data[h->count];
h->count -= 1;
down_update(h->data, 1, h->count);
return;
}
void clearHeap(heap* h) {
if (h == NULL) return;
free(h->__data);
free(h);
return;
}
Node* build_huffman_tree(Node** nodeArr, int n) {
heap* h = initHeap(n);
for (int i = 0; i < n; i++) {
push(h, nodeArr[i]);
}
Node* node1, * node2;
int freq;
for (int i = 1; i < n; i++) {
node1 = top(h);
pop(h);
node2 = top(h);
pop(h);
freq = node1->freq + node2->freq;
Node* node3 = getNewNode(freq, "0");
node3->lchild = node1;
node3->rchild = node2;
push(h, node3);
}
return h->data[1];
}
void output(Node* root) {
if (root == NULL) return;
output(root->lchild);
//if (root->lchild == NULL && root->rchild == NULL)
printf("%s : %d\n", root->c, root->freq);
output(root->rchild);
return;
}
char charArr[100];
unordered_map<char*, char*> h;
void extract_huffman_code(Node* root, int i) {
charArr[i] = 0;
if (root->lchild == NULL && root->rchild == NULL) {
h[root->c] = _strdup(charArr);
return;
}
charArr[i - 1] = '0';
extract_huffman_code(root->lchild, i + 1);
charArr[i - 1] = '1';
extract_huffman_code(root->rchild, i + 1);
return;
}
int main() {
#define MAX_CHAR 26
//1.首先用一个数组读取相关字符串及其频率
Node** charArr = (Node**)malloc(sizeof(Node*)*MAX_CHAR);
char arr[10];
int freq;
for (int i = 0; i < MAX_CHAR;i++) {
scanf("%s%d", arr, &freq);
charArr[i] = getNewNode(freq, arr);
}
//2.建立哈夫曼树
Node* root = build_huffman_tree(charArr, MAX_CHAR);
//3.提取哈夫曼编码进入unordered_map
extract_huffman_code(root, 1);
//4.将unordered_map转换成vector排序,可以按照字典序输出编码
vector<pair<char*, char*>> v(h.begin(), h.end());
sort(v.begin(), v.end(), [&](const pair<char*, char*>& a, const pair<char*, char*>& b) {
return strcmp(a.first, b.first) < 0;
});
for (auto& x : v) {
printf("%s : %s\n", x.first, x.second);
}
return 0;
}
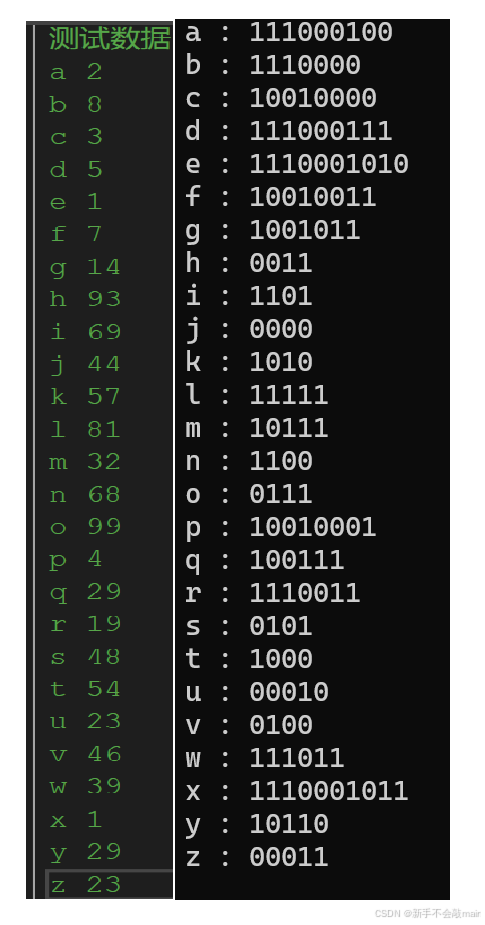
结束语
关注博主的专栏,博主会分享更多的数据结构知识!
🐾博主的数据结构专栏