文章目录
- 一、函数概念
- 1、函数介绍
- 2、函数的定义
- 3、函数的调用
- 4、函数说明文档
- 5、函数嵌套调用
- 6、变量作用域
- 1)局部变量
- 2)全局变量
- 3)声明全局变量
- 二、数据容器入门
- 1、列表 (list)
- 1) 列表的定义
- 2) 调用列表元素
- 3) 列表的方法
- 4) 列表的特点
- 5) 列表的遍历 (迭代)
- 6) 列表的乘法创建
- 2、元组 (tuple)
- 1) 元组的定义
- 2) 元组的操作(方法)
- 3、字符串 (str)
- 1) 定义:
- 2) 字符串操作方法
- 对 input() 输入字符串的格式化方案
- 4、序列的切片操作
- 5、集合 (set)
- 1、集合的定义
- 2、集合的操作方法
- 6、字典 (dict)
- 1、字典的定义
- 2、字典的嵌套
- 3、字典的方法
- 4、字典的遍历(迭代)
- 7、数据容器分类总结
- 8、数据容器的通用操作
- 1) 遍历(迭代)元素
- 2) 统计元素
- 3) 容器的通用转换功能
- 4) 排序元素
- 三、函数进阶
- 1、函数多返回值
- 2、函数的多种传参方式
- 3、匿名参数
- 1) 函数作为参数传递
- 2) lambda 匿名函数
- 4、PEP 8 风格指南
大家好,我是技术界的小萌新,今天要和大家分享一些干货。在阅读之前请先点赞👍,给我一点鼓励吧!这对我来说很重要 (*^▽^*)
一、函数概念
1、函数介绍
函数:提前定义好的,用于实现 重复功能的代码段,对于算法的 封装。
优点:减少重复性代码、提高开发效率、提高程序运行速度。
2、函数的定义
def 函数名(传入形式参数):
函数体
return 返回值
- 不写 return 返回值,默认返回 None 特殊字面量,其类型为:<class ‘NoneType’>,意为空、无实际意义。
- 等于 C 语言的 return 0。
None 的应用场景
- 用在函数无返回值上
- 用在 if 判断中, None 等于 False,即
if not None: - 用在声明无内容变量上,定义变量,但不需要有变量具体值,可用 None 代替。
name = None - 函数定义时若无
return返回值,只是为了实现功能,则调用的函数默认返回None。
3、函数的调用
函数先定义、再调用 函数名(实际参数可省)
形参:形参是函数定义时使用的占位符,用于接收调用时传入的值。形参的值在函数调用时由实参提供。
实参:实参是函数调用时实际传递给函数形参的值。实参可以是常量、变量、表达式,
区别:
- 定义位置:形参定义在函数的头部,作为函数的一部分;实参则是在函数调用时提供。
- 存在时间:形参只在函数定义时存在,而实参在函数调用时才存在。
- 作用:形参用于接收数据,实参用于提供数据。
- 数据传递:形参可以接收来自实参的数据,但形参的修改通常不会影响实参(除非是可变对象作为实参)。
- 作用域:形参的 作用域仅限于函数内部,而实参的作用域可以是 函数外部的任何地方。
- 对应关系:函数中形参数量不限,用 “,” 隔开,传入的实参必须与形参一一对应。
4、函数说明文档
定义函数,撰写说明文档,说明函数功能,鼠标悬停函数显示说明。
def doc(x,y):
"""
doc 函数说明
:parameter x: 形参 x 用于 ···
:param y: 形参 y 用于 ···
:return: 返回值的说明 ···
"""
test=x+y
print(test)
return test
doc(5,6)
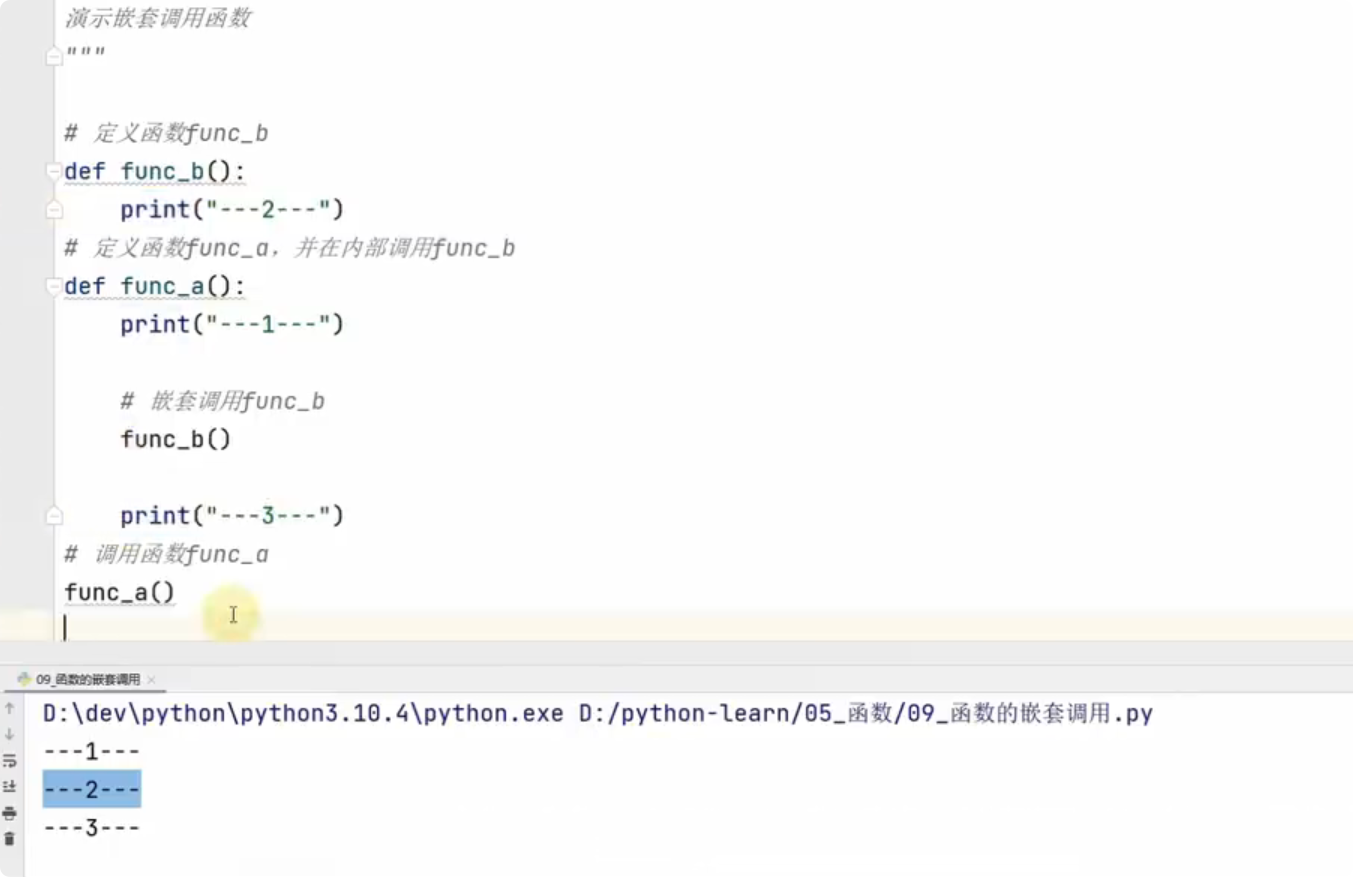
5、函数嵌套调用
Python 中的函数可以先使用,再调用,沒有任何顺序要求,不像 C 必须先定义函数再调用。在 Python中,“先行声明”(Forward Declaration)通常指的是在函数或类被实际定义之前引用它们,因为 Python是一种动态类型的语言,它使用不同的机制来处理函数和类的引用。函数的嵌套调用方式如下:
6、变量作用域
1)局部变量
- 局部变量是在函数内部定义的变量,它的作用域仅限于该函数内部。
- 一旦函数执行完毕,局部变量就会被销毁,它们无法在函数外部被访问。
- 局部变量的生命周期仅限于函数的执行过程。
2)全局变量
- 全局变量是在函数外部定义的变量,它的作用域是整个程序。
- 全局变量可以在程序的任何地方被访问和修改,包括在函数内部。
- 只要程序在运行,全局变量就会一直存在,直到程序结束。
区别:
- 作用域:局部变量的作用域限于定义它们的函数内部,而全局变量的作用域是整个程序。
- 生命周期:局部变量只在函数执行期间存在,函数执行完毕后就会被销毁;全局变量则在程序运行期间一直存在。
- 访问性:局部变量只能在其定义的函数内部被访问,而全局变量可以在任何地方被访问。
- 修改权限:在函数内部定义全局变量需要使用
global关键字,否则对全局变量的修改不会反映到函数外部。
3)声明全局变量
关键字:global variable   声明时不能进行赋值。
用途:在函数内部声明全局变量,或者统一在代码开头声明全局变量,统一管理。
二、数据容器入门
Python 中的 数据容器:一种可以容纳多份数据的数据类型,容纳的每一份数据称之为 1 个元素,每一个元素,可以是任意类型的数据,如字符串、int、float、complex、bool)。
数据容器根据特点不同,分为:列表 list、元组 tuple、字符串 str、集合 set (of)、字典 dict。
- 是否支持重复元素
- 是否可以修改
- 是否有序等
1、列表 (list)
1) 列表的定义
列表中元素的数据类型不受限制,可以是任何类型,元素可重复。
基本语法:
# 字面量
[元素1, 元素2, 元素3]
# 定义列表变量
列表变量名称 = [元素1, 元素2, 元素3]
# 定义空列表
变量名 = []
变量名 = list()
提醒:
- 列表可以一次存储多个数据,且 可以为 不同的数据类型,支持多个 列表嵌套。
2) 调用列表元素
① 列表的下标(索引):从左向右 0, 1, 2, 3, 4 五个元素,从 0 计数; list[0]
② 列表的下标(索引)- 反向:从右向左 -5, -4, -3, -2, -1,从 -1 计数; list[-1]
③ 嵌套列表的下标索引:list[0][-1]
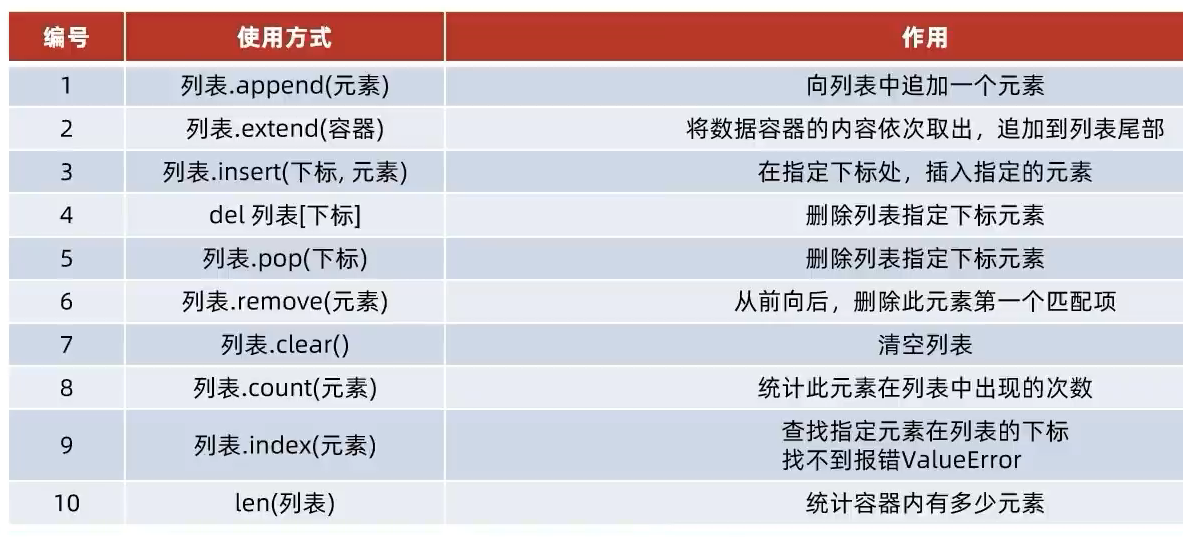
3) 列表的方法
列表方法:列表的一系列功能,增删改查元素等。
类 (class) 的简单介绍: 类似 C 中结构体,一系列函数的集合,函数此时称之为方法。
Python 中的类是一种用于创建和管理对象的结构,它允许将数据和功能组织在一起。使用类可以创建具有相同属性和方法的对象。
类的创建过程:定义类 --> 添加属性 --> 定义方法 --> 创建对象,实例化 --> 访问属性并调用方法,使用 . 操作符来访问对象的属性及方法。
函数的使用:num = add(1,2)
方法的使用:student = Student() # 创建类的一个新实例
num = student.add(1,2) # 用点调用类对象的方法
my_list = ["string", 66, 3.1415926]
# *************** 增 ***************
# 1. 插入 列表元素于指定下标处:
# 倒序插入存在问题,指定下标会插入到 下标-1 位置
my_list.insert(-1,"888") # (索引,对象)
print ("my_list 的 888 插入后是:\t\t\t\t",my_list)
# 2. 追加 单个列表元素、或单个列表、对象 于列表尾部当做被追加列的一个元素:
my_list.append([1,2,3])
print ("my_list 被追加 单个 元素后是:\t\t\t",my_list)
# 3. 追加 单个对象 (数据容器序列,或其字面量的元素逐个取出再进行追加) 的每个元素到另一个列表尾部:
my_list.extend(["元素2","元素3"])
print ("my_list 被追加 新序列 是:\t\t\t\t",my_list)
my_list[3:]=[1,2,3],[4,5,6] # 赋值时可 [4:] 进行序列切片后元素的修改(该下标处有元素则修改,无则赋值添加)。
print("\t\t\t\t\t\t\t\t\t", my_list)
# *************** 删 ***************
# 1. 删除 指定下标的列表元素:
del my_list[0] # 可 [0:] 遍历(迭代)删除后续所有元素
my_list.pop(0) # 删掉的元素还能作为返回值被得到:
print ("my_list 被删除 2 个首元素后是:\t\t\t",my_list)
# 2. 删除 元素在列表从前往后的第一个匹配项: 函数无返回值,所以返回 None
my_list.remove("888")
print ("my_list 被删除 匹配元素后是:\t\t\t",my_list)
# 3. 删除 列表所有元素:
my_list.clear()
print ("my_list 被删除所有元素后:\t\t\t\t",my_list)
my_list = ["string", 66, 3.1415926, [1, 1, 2, 3, 5]]
# *************** 改 ***************
# 1. 修改 特定下标索引的列表元素:
my_list[0]="666"
print ("my_list 的 66 修改后是:\t\t\t\t",my_list[1])
# *************** 查 ***************
# 1. 列表元素下标的索引查询功能(方法):
# 语法:列表.index(元素);返回:元素的下标索引值
my_list.index(66)
print ("my_list 的 66 下标是:\t\t\t\t",my_list.index(66))
# *************** 统计 ***************
# 1. 统计某元素在列表内的个数: 统计嵌套列表中的元素则表明该列表的位置下标索引即可。
my_list[3].count(1)
print("my_list[3] 中的 元素1 个数是:\t\t\t",my_list[3].count(1))
# 2. 统计列表中所有元素的数量:无法统计嵌套列表中的元素数量,需制定嵌套列表下标, 如[1][2]。
len(my_list)
print("\t\t\t\t\t\t\t\t\t", my_list)
print("my_list 中的 元素总数是:\t\t\t\t",len(my_list))
4) 列表的特点
- 容纳元素数量很大 (上限 2**63-1)
- 存储的数据(元素)特点为 有序存储(下标索引)、 可重复存在、容纳的数据可以是 任意类型(混装)。
5) 列表的遍历 (迭代)
普通列表元素通过 while index < len(list): --> index += 1 或 for i in list来遍历(迭代)每一个元素。
多个嵌套列表则需要通过定义 辅助函数进行判断每一个元素是否为列表类型,是的话则进行递归执行。
for、while 遍历区别:for 更简单,while 更灵活,for 用于只需要遍历依次取出数据容器中元素的场景,while 用于自定义遍历方式、或以其他算法取出数据容器中元素的场景。如正序遍历取出、倒序遍历取出、随机遍历取出等。
def flatten_and_print(nested_list):
"""
将 嵌套列表(nested_list) 展平(flatten) 并打印所有元素。
该函数递归地处理嵌套列表,将其中的所有非列表元素打印出来。
如果元素是一个列表,则对该列表递归调用自身;如果不是列表,则直接打印该元素。
参数:
nested_list -- 一个可能包含其他列表的列表
返回值:
无
"""
for element in nested_list:
if isinstance(element, list):
# 如果当前元素是列表,递归调用 flatten_and_print
flatten_and_print(element)
else:
# 打印非列表元素,使用空格分隔
print(element, end=' ')
# 定义一个测试列表,包含多个层级的嵌套
test = [1, 2, 3, [4, 5], [6, 7, [8, 9, [10, 11, [12, 13, [14, 15]]]]]]
# 直接调用函数进行打印
flatten_and_print(test)
打印:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
6) 列表的乘法创建
列表可以用乘法的形式,来创建多个相同列表元素组成的列表。如下:
ins = [1, 2] * (3)
print(ins)
ins[0] = 5
print(ins)
输出:
[1, 2, 1, 2, 1, 2]
ins = [[1, 2, [5, 6]], [3, 4, [7, 8]]] * (3)
print(ins)
ins[0][2][0] = 9
print(ins)
输出:
[[1, 2, [5, 6]], [3, 4, [7, 8]], [1, 2, [5, 6]], [3, 4, [7, 8]], [1, 2, [5, 6]], [3, 4, [7, 8]]]
[[1, 2, [9, 6]], [3, 4, [7, 8]], [1, 2, [9, 6]], [3, 4, [7, 8]], [1, 2, [9, 6]], [3, 4, [7, 8]]]
对于一维数组来说,每一个整数的列表元素都是不可变、不可再分对象,所以修改一个值也不会影响到其他值,它们是独立的对象。但是对于多维数组来说,修改任意一个 “嵌套列表” 内的元素,都会修改所有嵌套列表该下标的元素值,因为它们用列表乘法复制时,指向了同一个对象。
Python 列表的复制机制是:当你使用列表乘法 [x] * n 来创建一个新列表时,实际上是创建了一个包含 n 个相同引用的列表。这意味着所有列表元素都指向同一个对象。这种行为在多维列表中尤为明显,因为内层列表的所有引用都指向同一个列表。
解决方案: 使用列表推导式创建独立的嵌套列表元素,对于嵌套列表的创建,不能用 列表乘法。
ins = [[1, 1], [2, 2]] * (4) # 先创建出 4 个相同引用的嵌套列表。
print(ins)
ins = [item[:] for item in ins] # 重新遍历一边列表的每一个嵌套列表对象,对嵌套列表中的元素进行迭代切片,
# 取出的多个元素形成了一个列表,在列表推导式创建出的新列表中作为一个个嵌套 列表对象。
print(ins)
ins[0][0] = 6
ins[1][1] = 9 # 实现了嵌套列表间的引用分离,由此可以分别赋值而不会影响所有嵌套列表。
print(ins)
打印:
[[1, 1], [2, 2], [1, 1], [2, 2], [1, 1], [2, 2], [1, 1], [2, 2]]
[[1, 1], [2, 2], [1, 1], [2, 2], [1, 1], [2, 2], [1, 1], [2, 2]]
[[6, 1], [2, 9], [1, 1], [2, 2], [1, 1], [2, 2], [1, 1], [2, 2]]
2、元组 (tuple)
1) 元组的定义
元组内的数据一旦定义就不可修改,相当于只读的 list。
# 字面量
(元素1, 元素2, 元素3)
(元素4,)
# 定义列表变量
列表变量名称 = (元素1, 元素2, 元素3)
# 定义空列表
变量名 = ()
变量名 = tuple()
ins = ("元素4")
print(type(ins), ins)
打印:
<class 'str'> 元素4
注意:
tuple_a = ("instance",)
- 注意元组内只有一个数据时,需要加 “,” 逗号。否则定义的该变量会变为 字符串 数据类型,而非元组。
2) 元组的操作(方法)
my_list = ["string", 66, 66, 3.1415926]
# *************** 查 ***************
# 1. 查询元组中指定 元素 的下标索引:
index = my_list.index(66)
print("第一个 66 的索引为:\t\t ", index)
# *************** 统计 ***************
# 1. 统计元组中指定 元素 存在的数量:
num = my_list.count(66)
print("66 数据的数量有:\t\t\t\t", num)
# 2. 统计元组中所有 元素 的数量:
length = len(my_list)
print("该元组所有数据(元素)的数量有:\t", length)
提醒:
元组的遍历(迭代)方式同上使用 while、for。元组中的对象不可修改,但是@r元组中对象为列表可以被修改@@。
需要修改元组时,转换为列表修改后再转换为元组。
3、字符串 (str)
1) 定义:
字符串是字符的容器,一个字符串可以存放任意数量的字符。
同列表,不同的是:a. 只允许存放字符;b. 不可以修改字符串的值(字符)。
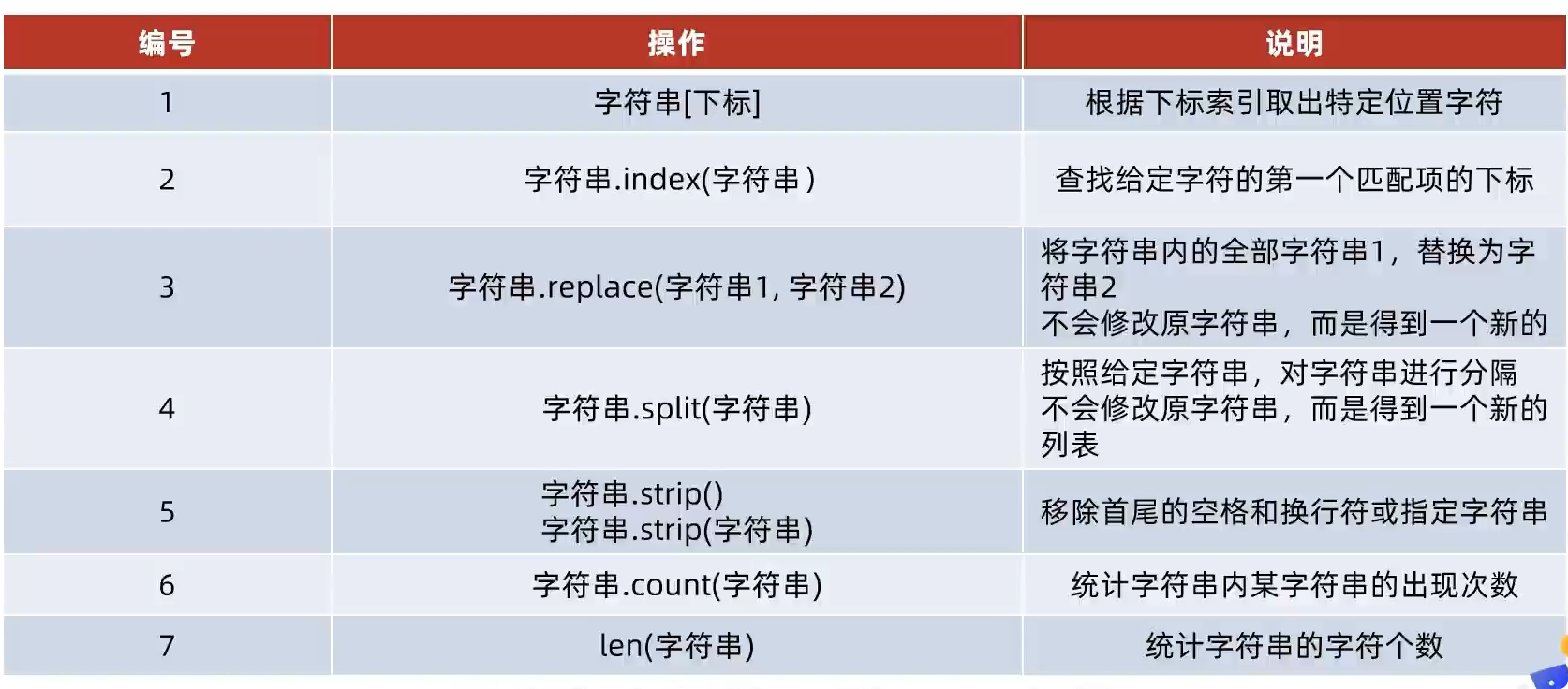
2) 字符串操作方法
str = "string"
# index 方法,查询字符索引:
value = str.index("s")
print(value)
# replace 方法:修改所有相同字符,到另一个字符,并非修改字符串本身,而是得到了一个新字符串,并返回给其他对象、变量。
value = str.replace("string","string is string")
print(type(value),value)
# split 方法,字符串的分割:按照指定的分隔符,将字符串划分为多个字符串,并存入列表对象中,返回列表对象。
# 原来的字符串并不修改。
# 当 separator 默认分隔符为 None 时,默认分割所有空白字符并丢弃,包括包括空格、制表符、换行符\n、回车符\r、换页符\f、垂直制表符\v等。
value1 = value.split()
print(type(value1),value1)
# strip (剥夺字符) 方法:字符串的规整操作(默认去除前后任何形式空格,可指定字符串)。返回去除字符后的结果。
# 逻辑:遍历输入参数的字符列表,匹配到字符串首、尾字符则去除,开启新的遍历,直到无匹配项。
value = " string "
print(value.strip(" "))
print(value)
value = "xX string Xx"
print(value.strip("xX")) # 传入的参数为字符串则匹配字符列表 "x","X" 。strip([chars])。
value = "xXstringxX"
print("xXstringxX".strip("..X..x..")) # 输出:string。
# count 方法:统计字符串中 字符 出现的 次数。
value = str.count("g")
print(value)
# len 方法: 统计字符串的 字符 长度。
value = len(str)
print(type(value),value)
对 input() 输入字符串的格式化方案
参考博客:Python基础之map()函数_map(int,input().split())-CSDN博客
map()函数是会根据提供的对指定可迭代对象(数据容器序列)中的每个元素输入到函数中,进行运算,得到函数返回运算结果的迭代器。如果函数有多个形参,则需要一一传入对应个数的序列。
a=map(int,input().split())分析:
map(int,input().split())将输入的字符串input.split()以默认的空格分割,int 函数将其转化为整型数据,map()函数将输入的多个数据的结果生成一个迭代器 a,迭代器顾名思义就是可迭代的对象经过对应的函数处理之后得到的结果封装在 a 里面。迭代器的结果可以通过list(a)打印出来:
a = map(int,input().split())
print(type(a), a)
print(list(a))
print(list(a))
输入:
1 2 3 4 5
输出:
<class 'map'> <map object at 0x00000197EBDA16C0> # 迭代器的内存地址
[1, 2, 3, 4, 5] # a 迭代器的迭代结果列表需要进行迭代得到。
[] # a 迭代器迭代完毕后不能再次迭代。
迭代器的结果 list(a), tuple(a), set(a),如果不进行保存,那么再次使用 list(a), tuple(a), set(a)的时候,他们的值会为空(就相当于一个容器a,将里面的液体到倒出来了,再次想倒出来些就没有了)。如果想要将这些结果保存起来,可以分别这些值赋值给一个变量,那么再次使用的时候,可以用的时候就可以调用到(就相当于将倒出来的液体存在另外一个地方,用的时候可以拿出来)。
有规律的 int、str 字符串的输入格式化:
# 初始化一个字符串,包含一系列用空格和/分隔的数据,用于后续处理
input_str = "1/Y 2/N 3/Y 4/N 5/Y"
# 方式 1 :
# 使用列表推导式,先按空格分割,再对每个结果按/分割
# 使用三元表达式,将其中的数字字符串转换为整型,非数字字符串保持原样
input_list1 = [[int(s2) if s2.isdigit() else s2 for s2 in s1.split("/")] for s1 in input_str.split()]
# 输出经过两次分割并转换整型后的列表
print("两次连续分割:", input_list1)
# 方式 2 :
# 再次处理字符串,但这次是一次性完成两次分割和转换的操作
# 先按空格分割,再对每个结果按/分割,并进行相应的类型转换
input_list2 = [int(s2) if s2.isdigit() else s2 for s1 in input_str.split() for s2 in s1.split("/")]
# 输出经过优化后的分割和转换结果
print("两次连续分割:", input_list2)
# 对方式 2 结果进行查看:
index = 0
while index < len(input_list2):
if (index+1) % 2 == 0:
print(" 字符串", input_list2[index])
else:
print(input_list2[index],end=" ")
index += 1
输入:
1/Y 2/N 3/Y 4/N 5/Y
输出:
两次连续分割: [[1, 'Y'], [2, 'N'], [3, 'Y'], [4, 'N'], [5, 'Y']]
两次连续分割: [1, 'Y', 2, 'N', 3, 'Y', 4, 'N', 5, 'Y']
1 字符串 Y
2 字符串 N
3 字符串 Y
4 字符串 N
5 字符串 Y
提醒:
- 分割成二维数组,for 遍历一次,for 遍历第二维数组,if str.isdigit() 判断是否为数字,分别进行处理。
- 分割为一维数组,while 遍历下标,if (i+1) % 2 == 0 对字符串进行处理,else 对数字进行处理。
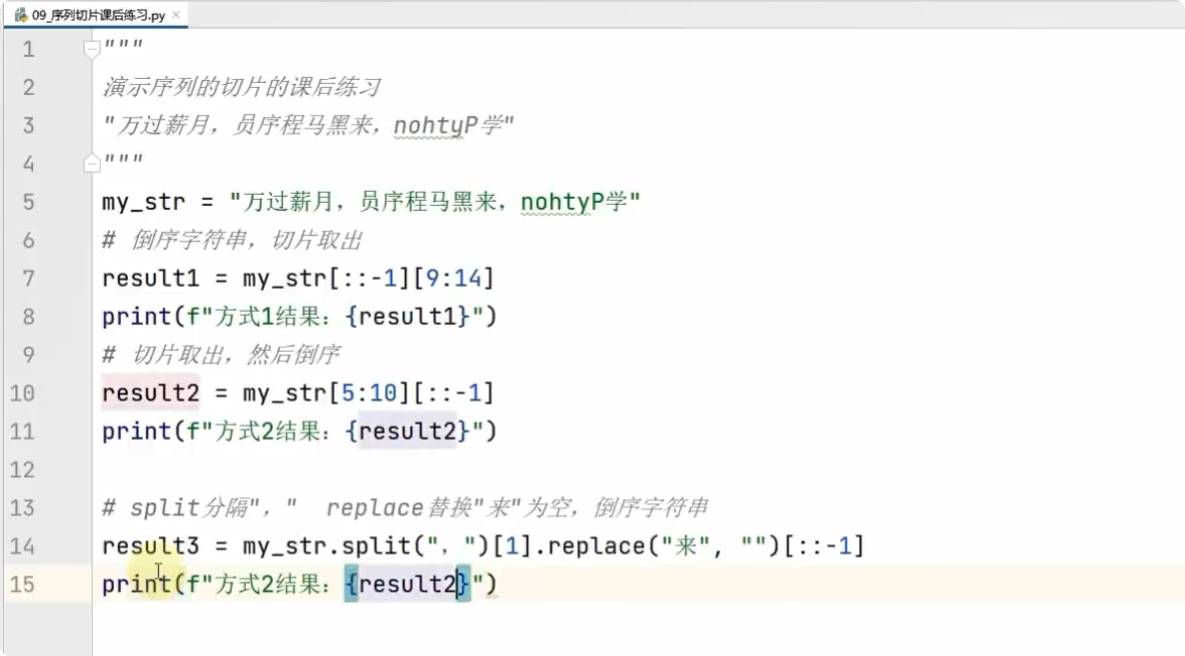
4、序列的切片操作
序列:指内容连续、有序,可使用下标索引的一类 数据容器,如 列表、元组、字符串。
切片:序列均支持切片操作,指从一个 序列中,取出一个 子序列。
语法: 序列[start_index:end_index:step] 即:开始下标:结束下标:步长
表示从序列中,从指定位置开始,依次取出元素,到指定位置结束,取出的新元素为一个个新序列。
提醒:
- 起始下标可留空,视作从头开始。
- 结束下标可留空,视作截取到结尾。截取范围永远是左闭右开的
[start:end)。- 步长为负数,所有下标也为负数,表示倒序取出元素。
样例:ins[:]、ins[0:]、ins[:5]、ins[::-1](序列翻转)、ins[-1::-2]
第一阶段-第六章-11-序列的切片课后练习讲解_哔哩哔哩_bilibili
5、集合 (set)
1、集合的定义
集合相比列表, 不支持重复性元素、且 无序。总结: 无序、 去重。
- 因为集合是无序的,所以不支持通过下标索引访问集合元素。所以只能使用 for 遍历(迭代) 集合。
# 字面量
{元素1, 元素2, 元素3}
# 定义列表变量
列表变量名称 = {元素1, 元素2, 元素3}
# 定义空列表
变量名 = set()
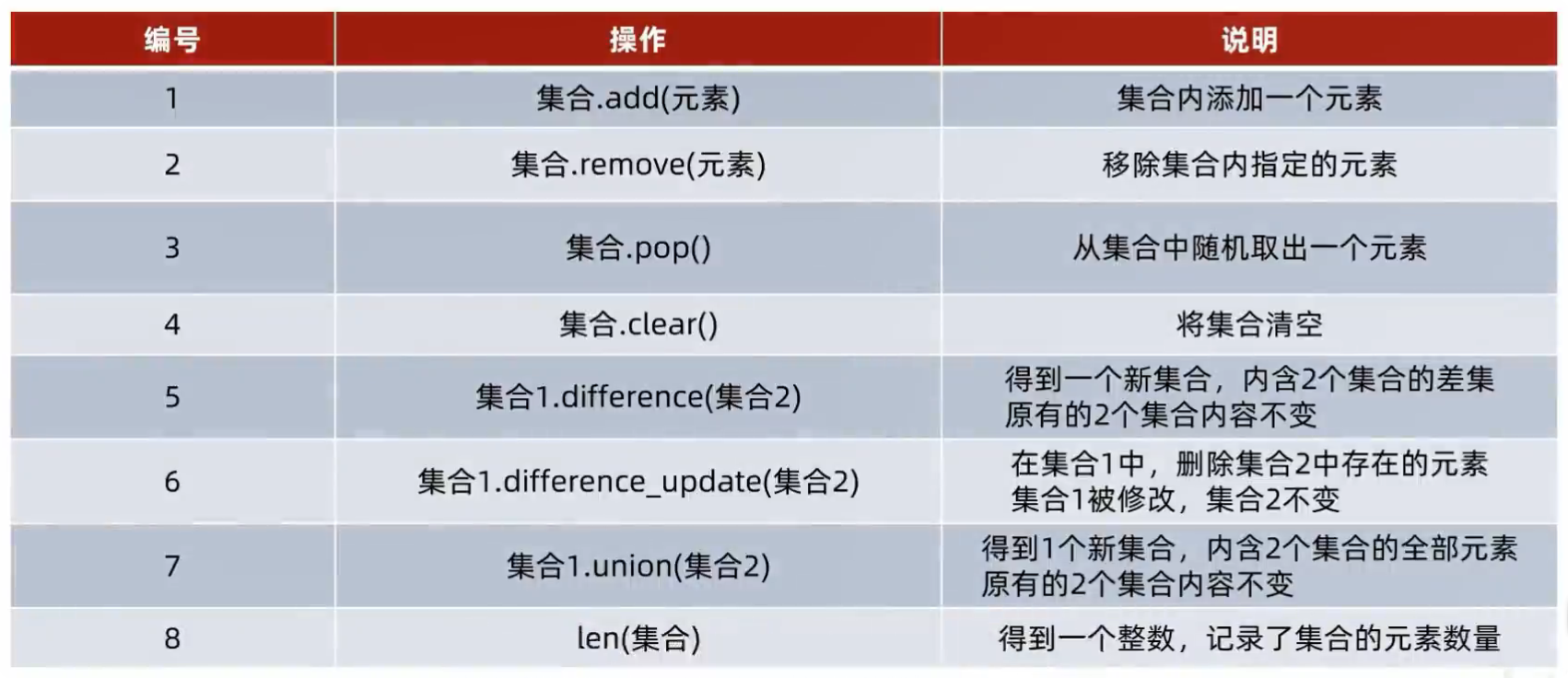
2、集合的操作方法
ins = {"str1","str2",3,4,True}
# 添加 不可重复元素 (对象):在集合中添加新元素。
ins.add("instance1")
print(ins)
# 删除(移除) 元素:对集合进行修改,无返回值。
ins.remove(True)
print(ins)
# 随机取出一个元素 在集合中:此时集合本身被修改,移除并返回这个元素。
value = ins.pop()
print(value,ins)
# 清空集合元素:
value = ins.clear()
print(value)
# 取出 2 个集合的差集,= 集合 1 - 集合12 的交集集, A - A∩B :结果:得到一个新集合,集合 1 和 集合 2 不变。
set1 = {1,2,3}
set2 = {1,5,6}
set3 = set1.difference(set2)
set4 = set1 - set2 # A - A∩B
print(set3,set4)
# 消除 2 个集合的差集(交集),同上:只是会修改原集合 1,因为是消除。
set3.difference_update(set4)
print(set3,set4)
# 合并 2 个集合(取并集),将 2 个集合合并为一个新集合 C = A ∪ B:结果:得到新集合,不修改原集合 1 和 2。
set3 = {1,4}
set4 = {2,3}
set5 = set3.union(set4) # (此方法 底层 默认升序排序)
print(set5)
6、字典 (dict)
1、字典的定义
同样使用 {},同 集合,不过存储的元素是 键值对 的形式,且 键名 key 不可重复。只有键名键值都拥有 ( 键值对 ) 才是一个完整的 元素 (对象)。
key 支持的数据类型是除字典外的任意数据类型。
注意:
定义、或赋值字典时,重复的 key 名,按顺序,后一个 键值 会覆盖前一个 键值 。
# 字典的字面量定义
{"key1": "value1", "key2": 2, "key3": None, 4: True}
# 定义空字典
dict1 = {}
dict2 = dict()
# 调用 value 键值 方式同列表等其他数据容器,不过 下标索引 换为了 “主键名”。
dict3 = {"key1": "value1", "key2": 2, "key3": None, 4: True}
print(dict3["key1"],dict3["key3"],dict3[4])
2、字典的嵌套
嵌套字典的定义 (写法):
dict_ins = {
"小明": {
"语文": 80,
"数学": 90,
"英语": 100,
}, "bool": {
1: ["True", "yes", "y"],
0: ["False", "no", "n"],
}
}
嵌套字典的调用:
print(dict_ins)
print(dict_ins["小明"]["语文"])
print(dict_ins["bool"][1])
3、字典的方法
① 新增/更新 字典元素(中的鍵值)
语法:dict_ins[key] = value 字典 key 不可重复,无则添加,有则更新。
② 删除 元素
语法:ins = dict_ins.pop(key) 取出被 pop() 推出的键值 vale,字典中删除此键值对。
③ 清空 元素
语法:dict_ins.clear()
④ 获取全部的 key : 获取字典的主键索引列表,用于字典的遍历(迭代)。
语法:ins = dict_ins.keys() keys() 返回的是 dict_keys 存储键名的类,需要用 list 转换为列表。
⑤ 统计 字典内的元素(键值对数量
语法:ins = dict_ins.len()
4、字典的遍历(迭代)
dict_ins = {
"小明": {
"语文": 80,
"数学": 90,
"英语": 100,
}, "bool": {
1: ["True", "yes", "y"],
0: ["False", "no", "n"],
}
}
# 遍历(迭代)字典方式1:通过 主键 key 索引,遍历(迭代)字典。keys 获取主键列表 需要通过 list() 转换为真正的列表
keys = dict_ins.keys() # 变为 主键名 的 另一种 list 类型。
keys = list(keys)
print(type(keys),keys)
for key in keys:
print(key,dict_ins[key])
# 方式2:直接循环字典对象。也能通过 for 获取 每一个主键名。
num = []
list_ins = []
for key in dict_ins:
num += key # 直接迭代相加字符串序列会是 一个个字符形成的列表。
list_ins.append(key)
print(key,dict_ins[key])
print(num)
print(list_ins) # 用 list.append() 才是正确做法
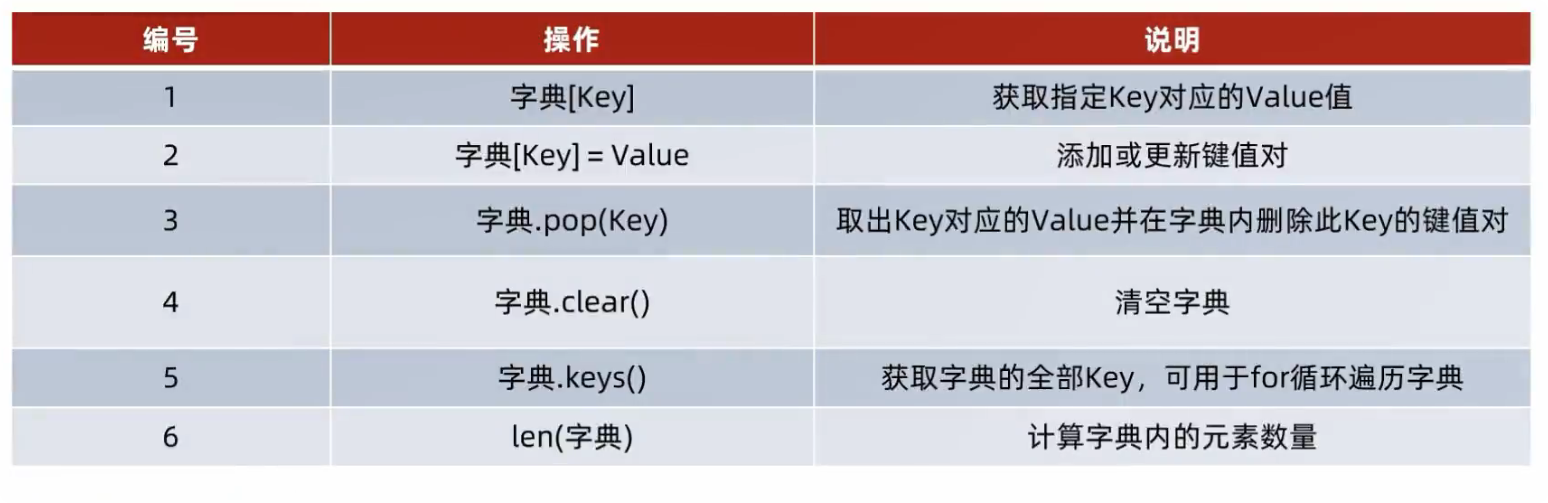
7、数据容器分类总结
8、数据容器的通用操作
1) 遍历(迭代)元素
五类数据容器都支持 for 遍历(迭代),但是只有 列表、元组、字符串 支持 while 遍历(迭代),集合、字典 不支持(因为元素无序,无下标索引)。
2) 统计元素
- len(): 统计容器内元素个数。
- min():统计容器内最小元素。
- max():统计容器内最大元素。
- 字符串元素、字典主键名 确定大小方法:通过比较 字符 的 ASCII 码。
- ord(“字符”) 可以查看字符的 ASCII 码。
3) 容器的通用转换功能
list(容器)、tuple(容器)、str(容器)、set(容器) 这些构造函数互相可转换,而 dict(容器) 与其他序列之间无法转换,因为无键值。
[!IMPORTANT]
特点 1:
tuple 与 list、set 互相转换,元素类型不变,元素属性变了(可修改、不可修改)。
特点 2:
str 转换为其他数据容器时,字符串以字符为元素,一一进行转换。
其他数据容器转 str,保留 print 打印容器时出现的 字符串,dict 键值对也保留住了。
dict 转换为其他容器时,抛弃 value 键值,只保留 主键名。
第一阶段-第六章-18-数据容器的通用操作_哔哩哔哩_bilibili
4) 排序元素
语法:sorted(序列,[reverse=True]) 默认升序,reverse 逆序的,开启 reverse 进行倒序排序。
警告:
dict 字典排序会损失 value 键值,保留主键名。
三、函数进阶
1、函数多返回值
return 对象:return 单个表达式对象,会退出函数,下面的 return 无法执行。
return 对象1, 对象2, 对象3:可直接返回多个返回值
接收 : x, y, z = function() 需要通过 多个变量接受返回值 。
2、函数的多种传参方式
形式参数类型、分类:
-
位置参数:调用函数时根据函数定义的 参数所处位置来传递参数。
-
关键字参数:函数调用时通过 “形参=值” 形式来传递参数。更清晰明了、清楚了参数的位置需要。
注意:
如果位置参数、关键字参数传参方式混用,则位置参数必须在关键字参数之前,全用关键字参数传参则无需求,因为参数传递有次序要求。

-
缺省参数 (default):定义函数时,对形参赋值,设置其默认参数,不传参时 默认使用 此 变量值。
def test(name, flag: bool = True)注意:
Python 规定在函数中 缺省形参的设置必须在其他形参之后。
-
不定长参数:也叫可变参数,使用场景:当调用函数时不确定需要传递多少参数时 (0也可) 使用。
-
① 位置传递的不定长:
def funcation(*args):传入的所有参数都会被args变量储存,会根据传递参数的位置合并为一个元组。args 为 元组类型。 -
② 关键字传递的不定长:
def funcation(**kwargs):传入参数不受限,传入的参数与参数值被保存为键值对形式的 字典,args 为 字典类型。
-
3、匿名参数
1) 函数作为参数传递
把函数当做参数传递到另一个函数中执行(传参函数将在此函数中被传参),可以将两个函数任务逻辑解耦,尤其在异步任务之间,提高代码的灵活性。这称之为 回调函数 (callback 召回,回调)。
函数作为参数传递的作用:进行逻辑的传递,而非数据的传递,函数运行时任何其他不同逻辑的回调函数都可被自定义并作为函数传入,供主函数传入数据使用。
如主函数通过调用不同的回调函数模块,可实现不同的功能。同父类实现顶层设计与子类继承与多态的例子。
# 简单的回调函数示例:
# 在这个例子中,async_operation 函数模拟了一个异步操作,它接收一个回调函数 handle_result 作为参数。当异步操作完成时,它调用 handle_result 并传递结果。
def async_task(callback):
print("任务开始执行。。。")
# 模拟耗时操作
time.sleep(1)
result = "完成"
print("任务执行完毕,结果为:", result)
# 调用回调函数并传入结果
callback(result)
def show_result(result):
print("得到结果:", result)
# 直接将函数作为参数传递给另一个函数
async_task(show_result)
在这个简化的例子中:
async_task函数模拟了一个异步任务,它接受一个名为callback的参数。show_result是一个回调函数,它将在async_task完成后被调用。- 我们没有使用任何额外的参数或复杂的逻辑,只关注于回调函数的使用。
- 调用
async_task(show_result)时,show_result作为参数传递给了async_task,然后在异步任务完成后被调用。
这个例子突出了回调函数的核心概念:一个函数(在这里是 show_result)被作为参数传递给另一个函数(在这里是 async_task),并在特定时刻(异步任务完成时)被调用。这种方式允许我们将处理结果的逻辑(回调函数)与执行任务的逻辑(异步任务)分离,提高了代码的模块化和灵活性。
2) lambda 匿名函数
-
def 关键字定义带有名称的函数
-
lambda 关键字定义匿名函数(无名称)
有名称函数可基于名称重复使用,无名称的匿名函数,只能临时使用一次。
- lambda 默认 return 返回该匿名函数处理后数值。
def fun(ins): value = ins(1, 2) print(value) fun(lambda x, y: x + y) # 作用,写逻辑比较简单,对于简单逻辑代码量少,简洁。
4、PEP 8 风格指南
PEP 8是 Python 的官方编码风格指南,它提供了关于如何编写清晰、可读性强的 Python 代码的指导。PEP 8 由 Python 社区广泛接受,并被许多项目和公司采用作为编码标准。如以下示例:
在Python社区中,PEP 8风格指南推荐使用以下命名约定:
- 类名应该使用帕斯卡命名法(PascalCase)。
- 函数名、变量名和非私有属性应该使用蛇形命名法(snake_case) 。
- 私有属性应该以下划线开头(例如 _snake_case)。
参考学习: PEP 8 – Python 代码风格指南中文版(一)_python pep8 中文-CSDN博客
文章到这里就结束了,希望我的分享能为你的技术之旅增添一抹亮色。如果你喜欢这篇文章,请点赞收藏支持我,给予我前行的动力!🚀











![[线程]单例模式 及 指令重排序](https://i-blog.csdnimg.cn/direct/1a35bcc19eac4c53b7b8bed255eeb5b9.png)





