原文阅读:【巨人肩膀社区·博客·分享】【Apache Doris】数据均衡问题排查指南
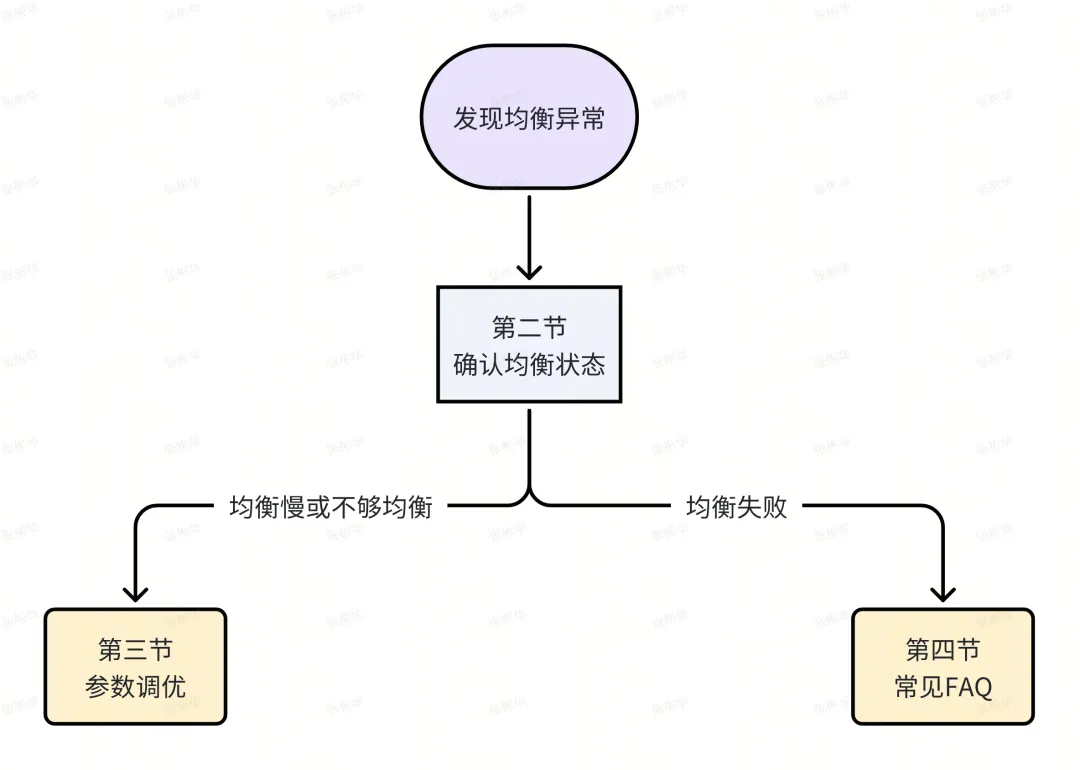
一、前提概要
当集群处于以下几种情况时,可参考本文进行问题排查。
•BE节点之间的数据不均
•单个BE节点上的多个磁盘之间的数据不均
•BE节点的上线和下线进度卡死(BE的tablet数量没有变化)
•在排查数据均衡问题之前,需要先确认FE的以下几个参数是否正确
--检查方式,mysql客户端登录进行查询
admin show frontend config like '%xxxx%';
--是否开启均衡,默认为false,代表开启均衡
disable_balance = false
--是否开启单个BE上的磁盘间均衡,默认为false,代表开启磁盘间均衡
disable_disk_balance = false
--是否开启colocate表的重新定位和平衡,默认为false
disable_colocate_balance = false
--是否开启副本修复和均衡调度,默认为false,代表开启
disable_tablet_scheduler = false
--当doris版本为2.0.4之后,对于单副本的数据,需要修改下方参数为true,默认为false
enable_disk_balance_for_single_replica
--修改命令
admin set frontend config("enable_disk_balance_for_single_replica"="true");
二、均衡状态检查
1. 均衡权重检查
查看方式有两种(例如使用fe web界面):
•登录FE的8030端口对应的web界面进行查看
•使用SQL语句进行查看
① web界面查看需要点击System=>cluster_balance
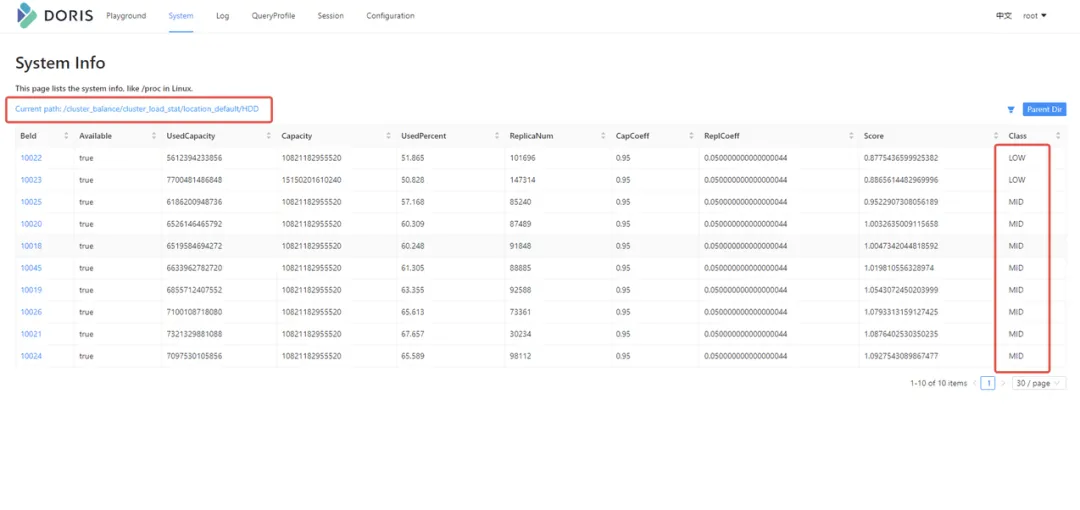
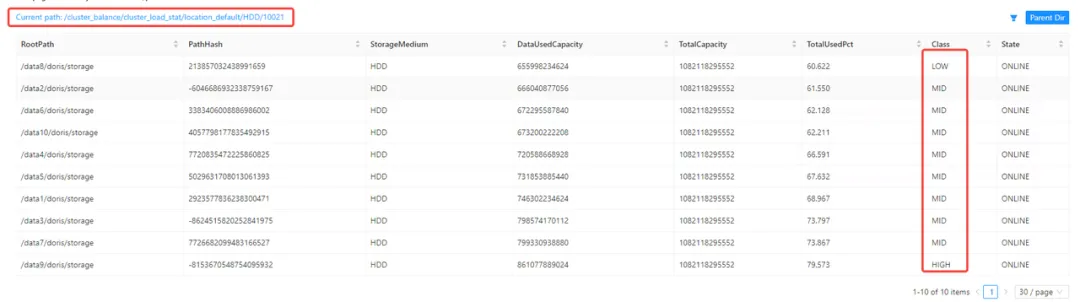
② SQL语句查看
show proc '/cluster_balance/cluster_load_stat/location_default/HDD'
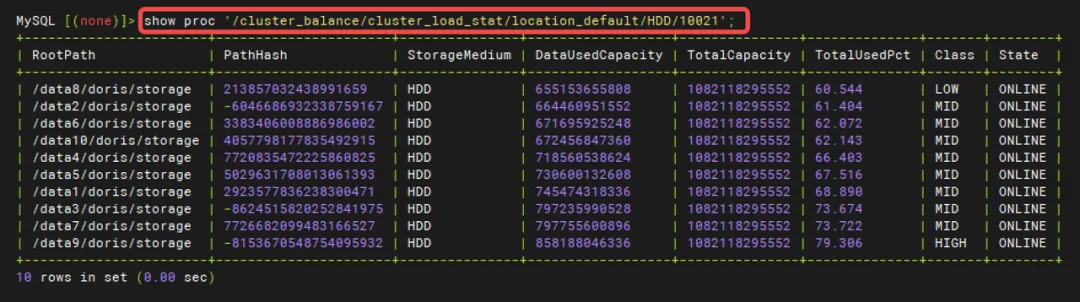
其中Class的等级分别为LOW/MID/HIGH,当Class均为MID时,代表当前集群的BE之间和单个BE的磁盘之间数据已均衡。均衡的权重可通过参数进行调整,详细参数见参数调优小节。
2. 均衡任务执行情况检查
① 查看当前正在执行的调度

当running任务正常,但是磁盘空间不下降,通常有两个原因
•均衡调度任务正常,需要清理下trash,均衡过程中的副本会被放入trash中。执行admin clean trash清理trash。
•均衡调度异常,查看均衡调度的历史信息,查看是否有报错。
② 查看均衡的历史记录信息
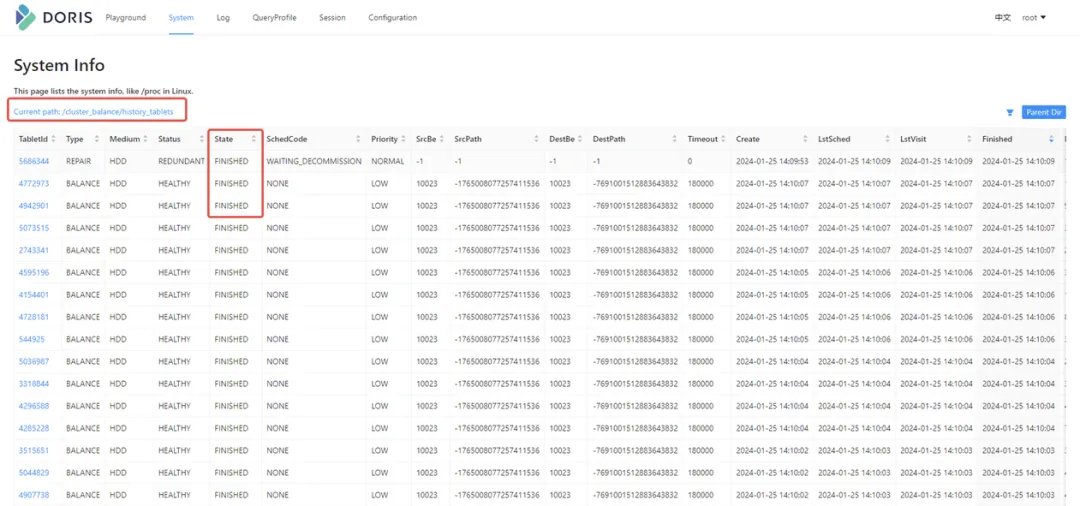
根据Finished进行排序,看是否有大量的CANCELLED状态。如果有,可以看最左边的ErrMsg日志。
或者通过搜索Master FE的日志grep "tablet schedule\|TableSch" fe.log|grep tablet_id
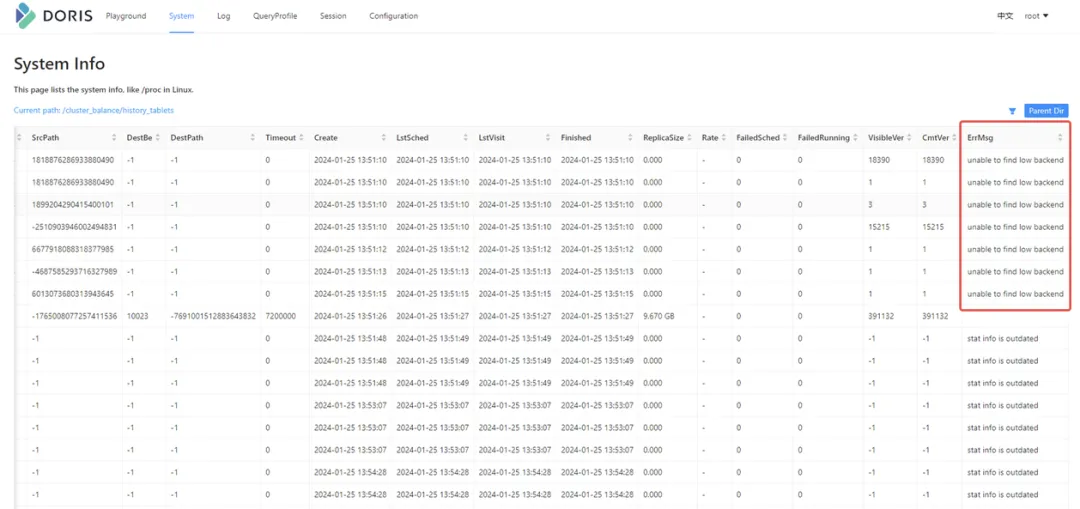
当均衡任务失败时,可以根据 常见FAQ 小节进行排查。
三、均衡参数调优
1. 数据不够均衡
① 参数讲解
balance_load_score_threshold 默认值 0.1
如果想让数据更加的均衡,可以适当调小该参数,触发均衡调度执行。
BE节点间判断:当BE节点的load score,与平均load score的差值的绝对值不超过10%时,认为该节点是均衡的。
磁盘间判断:当使用率不超过平均使用率的0.1*2时,认为该磁盘是均衡的。
backend_load_capacity_coeficient 默认值0.8
用于计算负载得分。
Score = UsedPercent / 平均UsedPercent * CapCoeff + ReplicaNum/平均ReplicaNum * ReplCoeff
其中ReplCoeff = 1 - CapCoeff。
我们可以通过调整该参数,决定让磁盘使用率更均衡,还是让tablet数目更加均衡。
该参数越大,磁盘使用率的相差会越小,参数越小,则tablet num相差越小。当CapCoeff=1时,无法均衡空tablet。
② 调优指南
当各BE之间均衡程度不满足要求时,可以将balance_load_score_threshold调小,backend_load_capacity_coeficient调大(建议小于1.0)
admin set frontend config ("balance_load_score_threshold" = "xx");
admin set frontend config ("backend_load_capacity_coeficient" = "xx");
调整后再通过第二节的方法检查数据均衡的状态,均衡调度任务是否被触发了。
想让tablet num相差变小时,可以将backend_load_capacity_coeficient调小,不小于0.5。
2. 均衡速度慢
单个均衡任务分为这几个步骤:
全量拷贝一个新tablet-->对新tablet进行增量拷贝-->对于冗余的tablet进行删除
均衡速度慢怎么排查?
•BE的IO是不是很高,可以通过iostat -x 1查看读写的IO延时是不是很高
•均衡的线程是不是太少,当磁盘IO良好时,可以通过参数进行调整,加快均衡速度
•
-- 要克隆的线程数be.conf
storage_medium_migrate_count = 6
-- 影响副本均衡的速度。在磁盘压力不大的情况下,可以通过调整该参数来加快副本均衡be.conf
clone_worker_count = 6
四、常见FAQ
1. 事务卡死导致无法均衡
均衡失败的报错,如下图所示
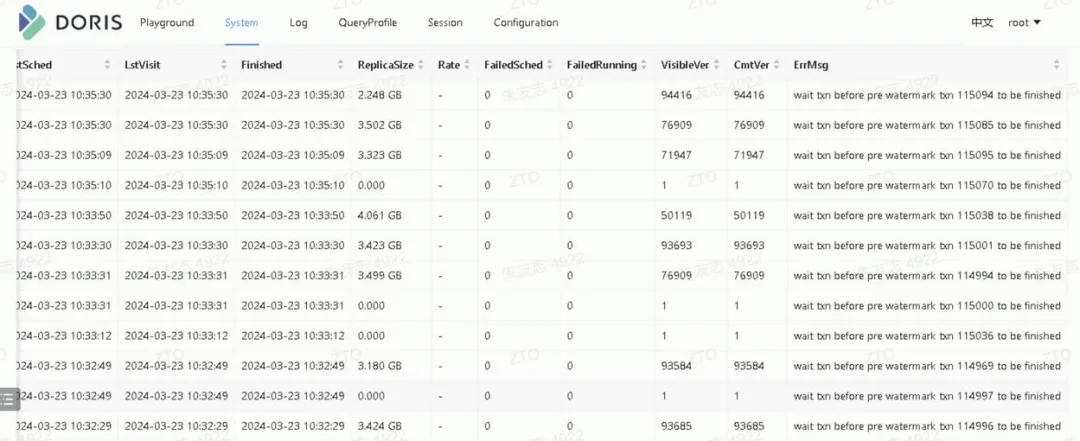
检查transaction面板:点击System => transaction
寻找running的事务,按照prepare time 进行正排序, 查看是不是事务prepare time时间很早,但是状态一直是prepare。符合条件的话,需要手动把对应的事务abort掉。
Abort 事务的方法
#根据事务id进行abort
curl -X PUT --location-trusted -u user:passwd -H "txn_id:18037" -H "txn_operation:abort" http://fe_host:http_port/api/{db}/{table}/stream_load2pc
#根据label进行abort
curl -X PUT --location-trusted -u user:passwd -H "label:55c8ffc9-1c40-4d51-b75e-f2265b3602ef" -H "txn_operation:abort" http://fe_host:http_port/api/{db}/{table}/stream_load2pc2. 单个BE上磁盘之间不均衡
均衡调度任务会优先BE之间进行均衡,当BE间均衡后,再进行单个BE间磁盘的均衡。当单个BE上某个磁盘使用率很高时,可以尝试如下调整:
调整balance_load_score_threshold参数,通过第二节方法查看均衡状态,保证BE的权重均为MID,但是单个BE的磁盘之间可以进行均衡调度。
在2.1之后的版本中,会增加MaxDisk的指标,如果MaxDisk出现了LOG/HIGH的权重,
表示最大磁盘使用率相差较大,需要马上紧急迁移。当紧急迁移完毕后,再进行正常非紧急的数据迁移。3. 磁盘被标记为坏盘
show backends检查
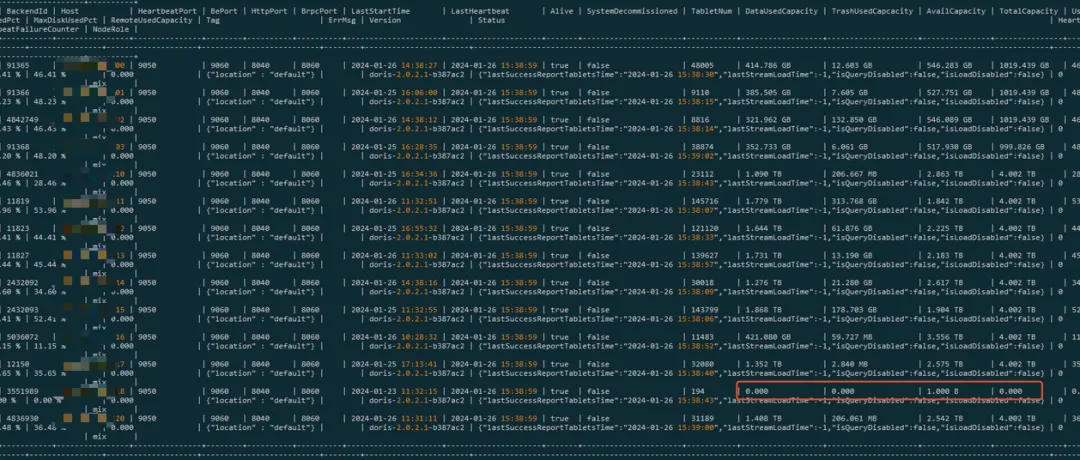
当对应BE节点的相关指标都为0时,表示磁盘不存在,或者被标记为bad,
通过命令 show proc "/backends/" 可以查看该BE 的磁盘情况。

如果State=OFFLINE,代表磁盘为bad
•确认be.conf中配置的路径是否异常,是不是升级或者其他操作导致对应磁盘路径不存在了
•路径存在,检查BE的日志。使用grep "IO Error" be.INFO.xxxx,或者直接grep "IO Error" be.INFO*|less,通常是因为磁盘写满了,fd的数目超过了设置,目录被删除等导致
恢复磁盘可用的步骤:
1. 查看conf/be_custom.conf 里是否有broken path,如果有删除;当然这个文件不一定有(比如当时fd数超了,会连这个文件都写不进去);
2. 重启BE节点。
4. tablet被标记为冷存
在冷热分层的场景下,满足条件的tablet会被标记为冷存,这些tablet不能在同BE的不同磁盘上迁移,但可以在BE之间迁移。
5. 表的replication allocation的tag与backend 的tag不匹配
数据的均衡只会在相同的tag中的相同storage medium上进行均衡,如果表的replication allocation的tag 跟它所在backend的tag不一样,或者backend不含有该表的storage medium ,那么也是无法均衡的。